-
-
Homepage
-
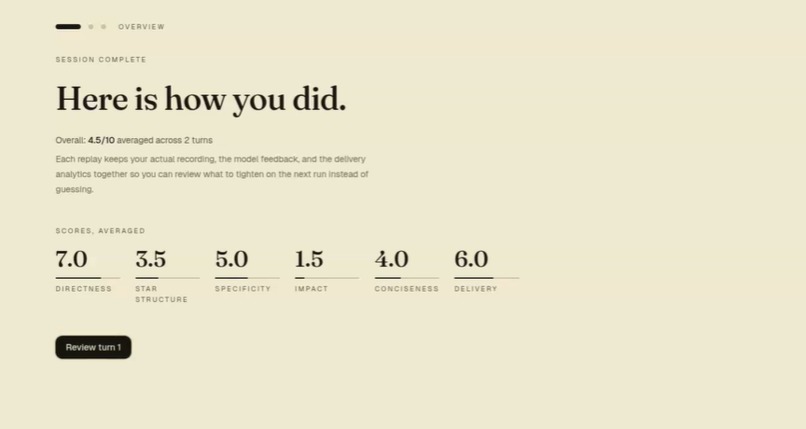
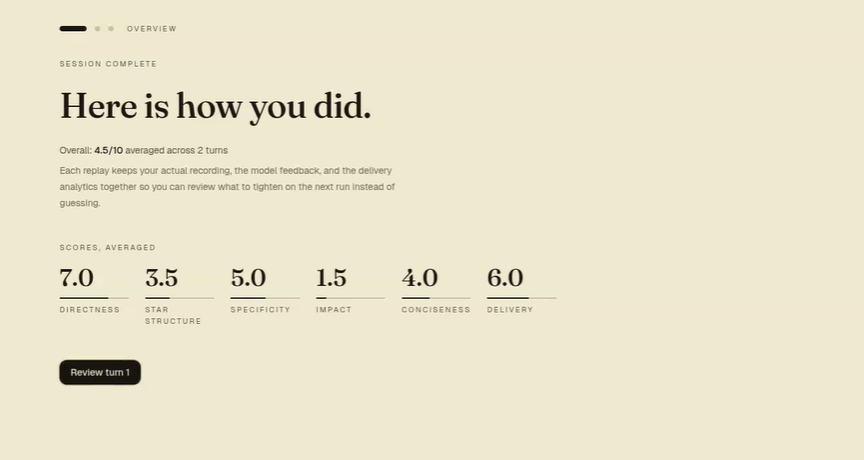
scores
-
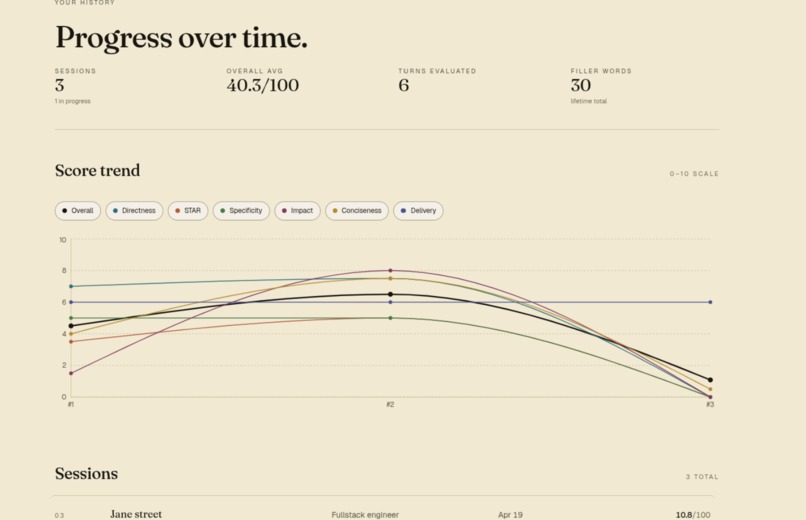
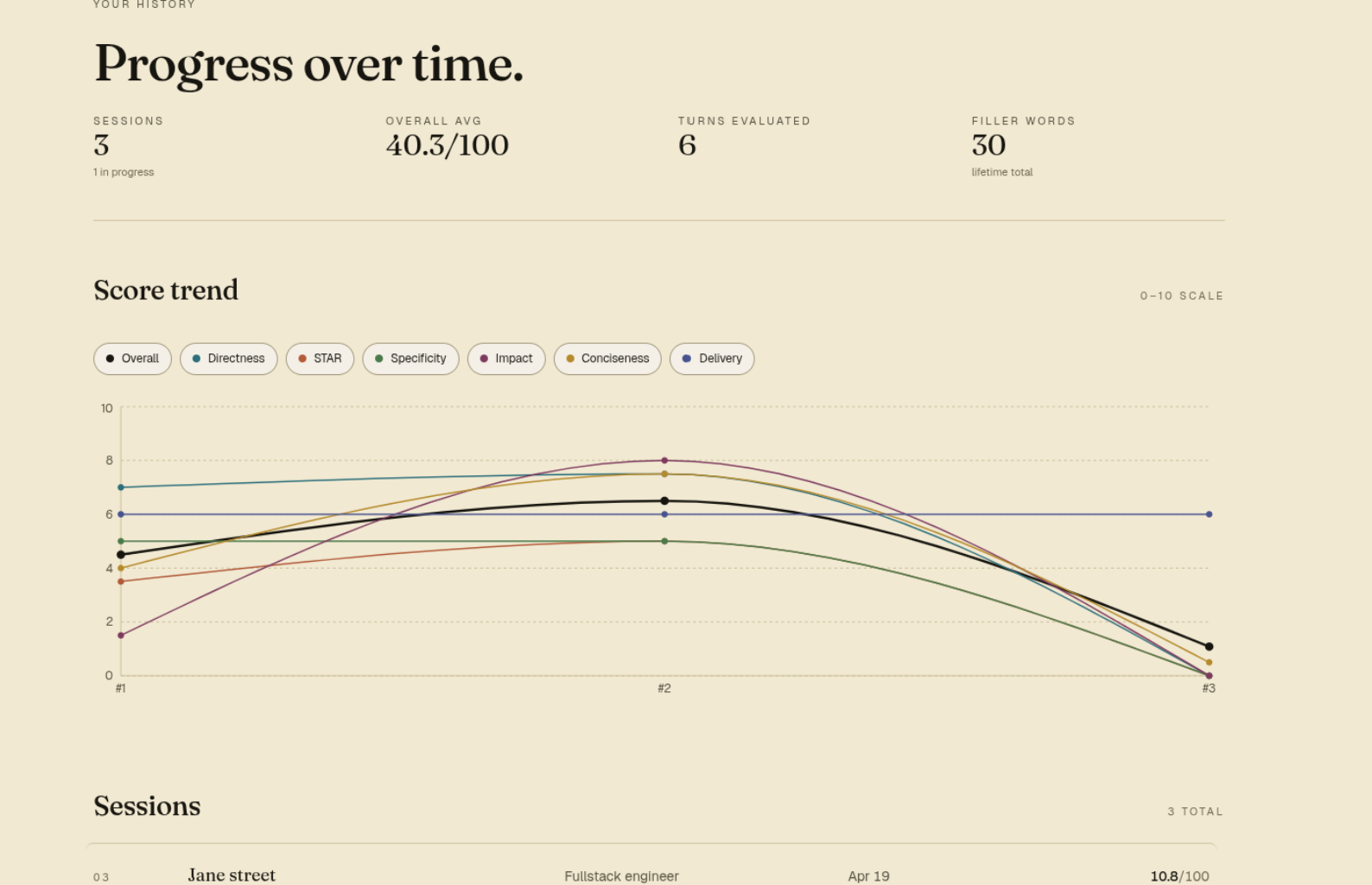
trends
-
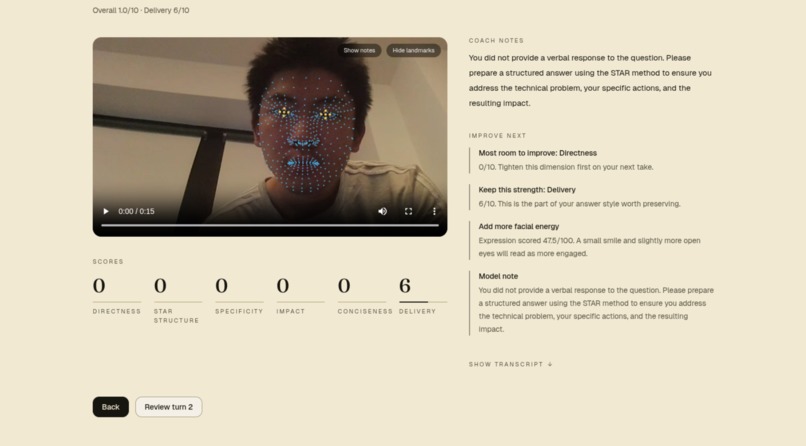
feedback
-
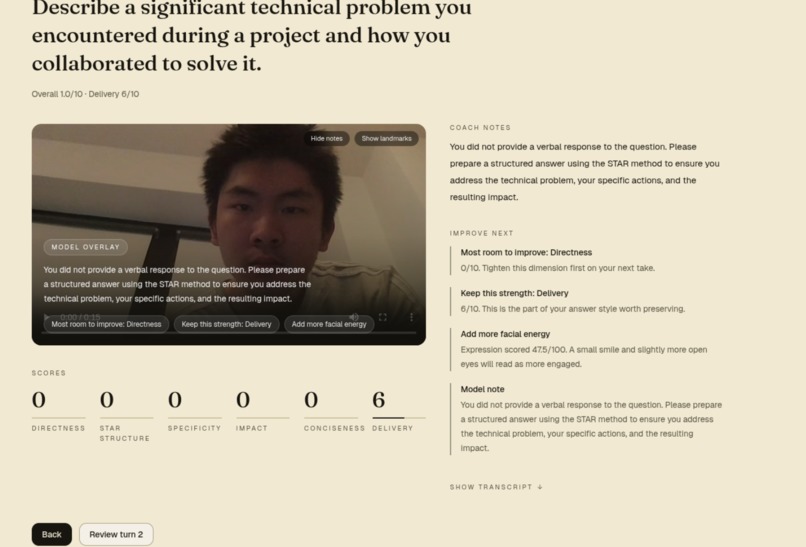
feedback
Inspiration
λόγος (Logos) is Greek for word, speech, reason.
We built an AI-powered behavioral interview coach. Speak your answer, get a tailored follow-up question and rubric-based scoring in the same flow you'd get from a real interviewer — including how you came across on camera.
Behavioral interviews are the part of the loop that students prepare the least for and lose offers on the most. Every undergrad has a Leetcode grinding routine. Almost none have a behavioral one. The rehearsal options that exist are bad in different ways:
- Friends and study partners — schedule-locked, can't simulate a stranger, almost never push back with a sharp follow-up.
- Mock-interview platforms — overwhelmingly skewed to technical / coding questions. The behavioral offerings are usually static question banks with no scoring, no follow-up, and no feedback on delivery.
- Recording yourself — gives you a tape, not coaching. You hear the rambling but you don't know which part is hurting you.
- Career-services mock interviews — high signal but rare, often booked out, and intimidating for a first rep.
The result is that students walk into "Tell me about a time when…" cold, lean on canned STAR templates they've never spoken out loud, and learn the hard way that they fill silence with um and look at the floor when they think.
Logos exists to give that rep, on demand, in a quiet workspace that treats the candidate as an adult. Voice in, transcript out, an interviewer that asks a real follow-up to your actual answer, scored on the dimensions interviewers actually care about, with a delivery grade pulled from your webcam.
Features
Voice-native interview loop
- Two-turn structure: one opening question grounded in company research, one follow-up that references the candidate's literal answer.
- Auto-recording: when the question audio finishes, the mic engages automatically — no "press record to begin" friction.
- One-click submit: pressing End answer ships the audio and advances to the next question. No re-record gate, no preview to sit through.
- Per-session interviewer voice: pick from six accented ElevenLabs voices or let the system surprise you. Same voice across both turns.
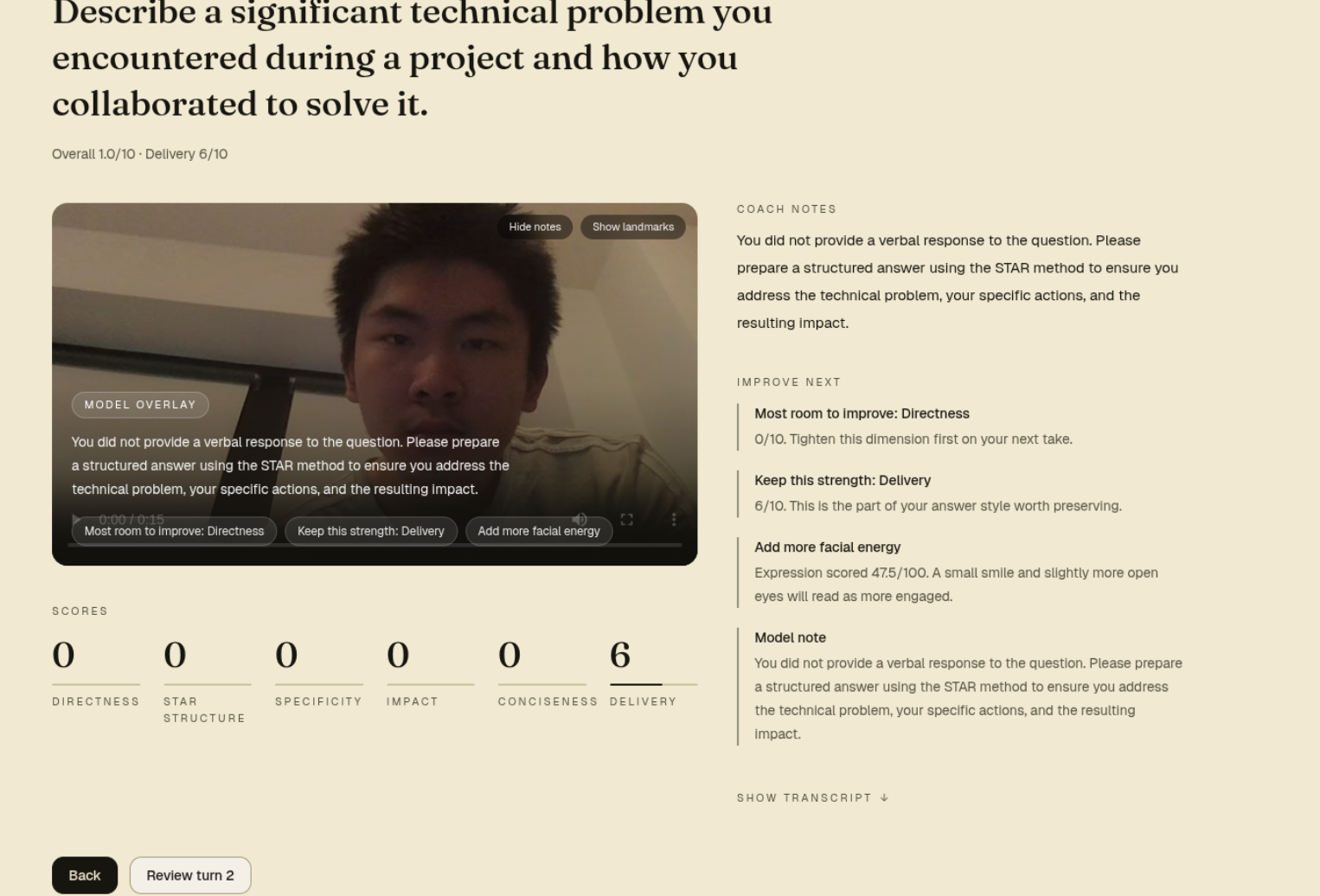
Rubric-based scoring
- Five LLM-scored dimensions: Directness, STAR structure, Specificity, Impact, Conciseness.
- A sixth, Delivery, scored from webcam analytics (see below).
- Per-turn 2-3 sentence coaching note plus a "most room to improve" / "keep this strength" insight panel.
- Filler-word counts via Python regex, with a per-word breakdown.
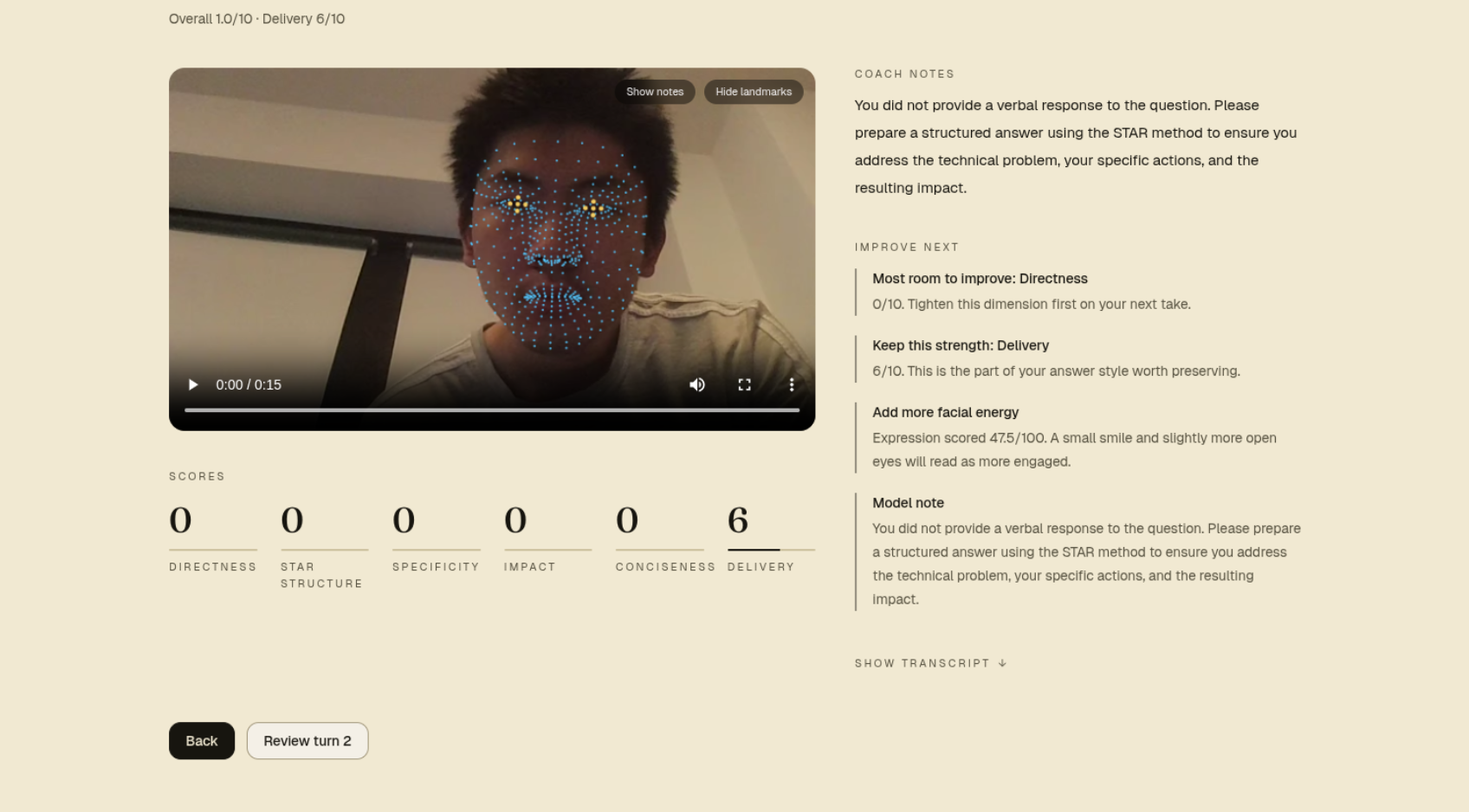
OpenCV / MediaPipe delivery scoring
A 478-point face-landmark mesh runs in the browser via MediaPipe's
face_landmarker, ported from a desktop OpenCV reference implementation
(backend/opencv.py) that calibrated the heuristics against real recorded
sessions. While the candidate is answering, a hidden 15 fps loop computes:
- Eye contact score (0-100) — derived from iris position relative to the eye corners, plus head-pose stability. Glancing away tanks the score; a steady forward gaze keeps it high.
- Face visibility (% of frames with a detectable face) — penalizes the "off-camera while talking" failure mode.
- Expression score (0-100) — uses brow / mouth landmarks to flag a flat affect vs. a present, slightly-engaged one.
- Coaching tip — a one-line readable summary derived from the above.
The frame-by-frame summary is batched into a cv_summary JSON sidecar that
ships with the audio blob in the same multipart POST. The evaluator factors
it into the delivery score and the per-turn coaching insights pull
specific call-outs (e.g. "Eye contact landed at 47/100. Pick one spot near
the camera and return to it between phrases."). On the results screen, a
toggleable face-mask overlay redraws the landmarks on the recorded video so
the candidate can see what the model saw.
Onboarding & personalization
- Clerk-based auth with passwordless email + SSO callbacks.
- Resume upload (
pdfplumberextraction) so the opening question can reference the candidate's actual experience. - Industry, target role, and experience level captured at onboarding to shape the question bank.
Session history & trend chart
GET /sessionsreturns the candidate's completed sessions with cached per-dimension averages, so the history page renders an inlinerechartstrend chart of all six dimensions over time without N+1 fanout.GET /sessions/{id}returns the full per-turn breakdown — transcript, scores, feedback, filler-word table, replay metadata.GET /me/statsreturns user-level rolling aggregates (total sessions, rolling averages, total filler count) for the profile strip.- A dedicated
session_metricstable caches the aggregates at session-finalize time so the history view stays cheap as the row count grows.
How we built it
- Frontend: React 19, Vite 8, TypeScript, Tailwind 4, Clerk, recharts,
MediaRecorder, MediaPipe Tasks Vision (
face_landmarker). - Backend: FastAPI, SQLAlchemy 2 (async), Alembic,
python-josefor Clerk JWT verification,pdfplumberfor resume parsing. - AI/APIs: Google Gemini (2.5 Flash, 2.0 Flash, Gemma 3), ElevenLabs (STT + TTS), Serper (Google search).
- Storage: PostgreSQL 17 in Docker.
Gemini API — evaluator and question generator
Logos does three sequential Gemini calls per session, not a multi-agent loop. Keeping the orchestration simple keeps latency predictable and the system debuggable on demo day.
| Stage | Model | Role |
|---|---|---|
| Company research | Gemini 2.5 Flash | Summarizes Serper search results into a 1-paragraph brief + values + headlines that ground the questions. |
| Opening question | Gemini 2.5 Flash | Reads the brief + the candidate's resume + target role and writes the first behavioral question. |
| Follow-up question | Gemini 2.0 Flash | After turn 1, drafts a sharp follow-up that references what the candidate actually just said. |
| Per-turn evaluator | Gemma 4 (gemma-4-26b) |
Reads the transcript + question + history and returns structured JSON scores on five rubric dimensions plus a 2-3 sentence coaching note. |
Every Gemini call uses response_mime_type="application/json" plus an
explicit response schema, so the contract is enforced upstream and the
backend never has to defend against half-formatted prose. The evaluator
output shape is locked:
{
"scores": {
"directness": 0,
"star": 0,
"specificity": 0,
"impact": 0,
"conciseness": 0
},
"feedback": "2-3 sentence coaching note",
"filler_words": { "um": 0, "like": 0 },
"next_question": "string, empty if is_final",
"is_final": false
}
A separate Python regex pass on the transcript is the ground truth for
filler-word counts (um, uh, er, like, you know, basically, literally,
actually, i mean, kind of, sort of, right). The LLM's own breakdown is kept
as a sanity check but never trusted as the source.
For optimizations, turn-1 evaluation runs in the background as a detached asyncio task. The candidate hears the follow-up question (from Flash) within a couple of seconds and moves on while Gemma is still scoring turn 1. By the time turn 2 finishes, both turns are scored in the database and we render the full session summary. Hackathon-realistic latency without compromising on which model scores.
ElevenLabs API — the interviewer's voice and ears
Logos uses ElevenLabs on both sides of the audio loop, so the entire session is voice-native:
- Speech-to-text (STT): the candidate's
MediaRecorderblob is POSTed to the backend, which forwards it to the ElevenLabs Speech-to-Text API. We get back a clean transcript with no client-side Whisper download and no need to ship a 600 MB model in the browser. - Text-to-speech (TTS): every question Logos asks — the opener and the
follow-up — is synthesized by ElevenLabs Flash v2.5, returned as a base64
data:audio/mpeg;...URL inline in the JSON response, and dropped straight into an<audio>element on the frontend. No S3, no signed URLs, no extra hop. - Voice variety per session: the start-form has a "Choose interviewer voice" disclosure that lets the candidate pick from a pool of six named, accented voices (Divya — Indian, Jennifer — American, David — British, Irene — Malaysian-American, Ding — Chinese, Daniel — American). Skip the picker and Logos randomizes the voice deterministically from the session UUID. Either way, the chosen voice is persisted on the session row so turn 2 sounds like the same interviewer who asked turn 1, even after a refresh.
The result is a session that feels like a phone screen — one voice, consistent, asking real questions about real answers — instead of a chat window with a synthetic buzzer noise.
Challenges we ran into
CORS issues (connecting the frontend with the backend) - resolved using Claude Code and Cursor AI agents.
Accomplishments that we're proud of
Logos exists to give that rep, on demand, in a quiet workspace that treats the candidate as an adult. Voice in, transcript out, an interviewer that asks a real follow-up to your actual answer, scored on the dimensions interviewers actually care about, with a delivery grade pulled from your webcam.
What we learned
Embrace the power of using AI responsibly to speed up the development process!
What's next for Logos
The hackathon scope was intentionally tight (two turns, one company at a time, single-shot scoring). A few directions worth exploring beyond this build:
- Variable-length sessions — drop the hardcoded 2-turn rule, let the evaluator decide when the answer warrants a deeper follow-up vs. moving on. Requires a smarter end-condition than turn_number >= 2.
- More interview formats — the architecture is generic; technical-screen framing, case-interview prompts, and consulting fit-style questions are all swap-the-prompt features.
- Streaming TTS / LiveAvatar — ElevenLabs supports streaming; pairing it with a HeyGen LiveAvatar would give the interviewer a face. Lite-mode integration was scoped but cut for time.
- Recruiter mode — let the candidate paste a job description and have the question generator target it, instead of inferring from company + role.
- Spoken-feedback mode — pipe the coaching note back through TTS at the end of the session so the review feels like a debrief, not a report card.
- Calibrated delivery scoring — the OpenCV thresholds were tuned on a small calibration sample (backend/recordings/calibration_*). A larger labeled dataset would let us calibrate per ethnicity / lighting / camera angle and flag low-confidence frames instead of silently averaging them in.
- Comparative analytics — anonymized cohort percentiles ("your STAR scores trail the median for entry-level SWE candidates") would turn the trend chart from a self-comparison into a benchmark.
- Mobile capture — the current MediaPipe loop assumes a laptop webcam; a dedicated phone capture flow with portrait framing and on-device STT would extend the practice context.
- Persistent question library — at the moment the question generator is fully on-the-fly. Caching the strongest prompts per company / role would make demos faster and let candidates retry the same prompt to compare improvement directly.
- Production hardening — usage caps per user, exponential backoff on the ElevenLabs / Gemini rate limits, structured error reporting, and an actual test suite beyond the evaluator unit tests.
Built With
- docker
- elevenlabs
- fastapi
- gemini
- postgresql
- python
- react
- tailwindcss
- typescript
- vercel
- vite





Log in or sign up for Devpost to join the conversation.