-
-
Intro Page
-
Working
-
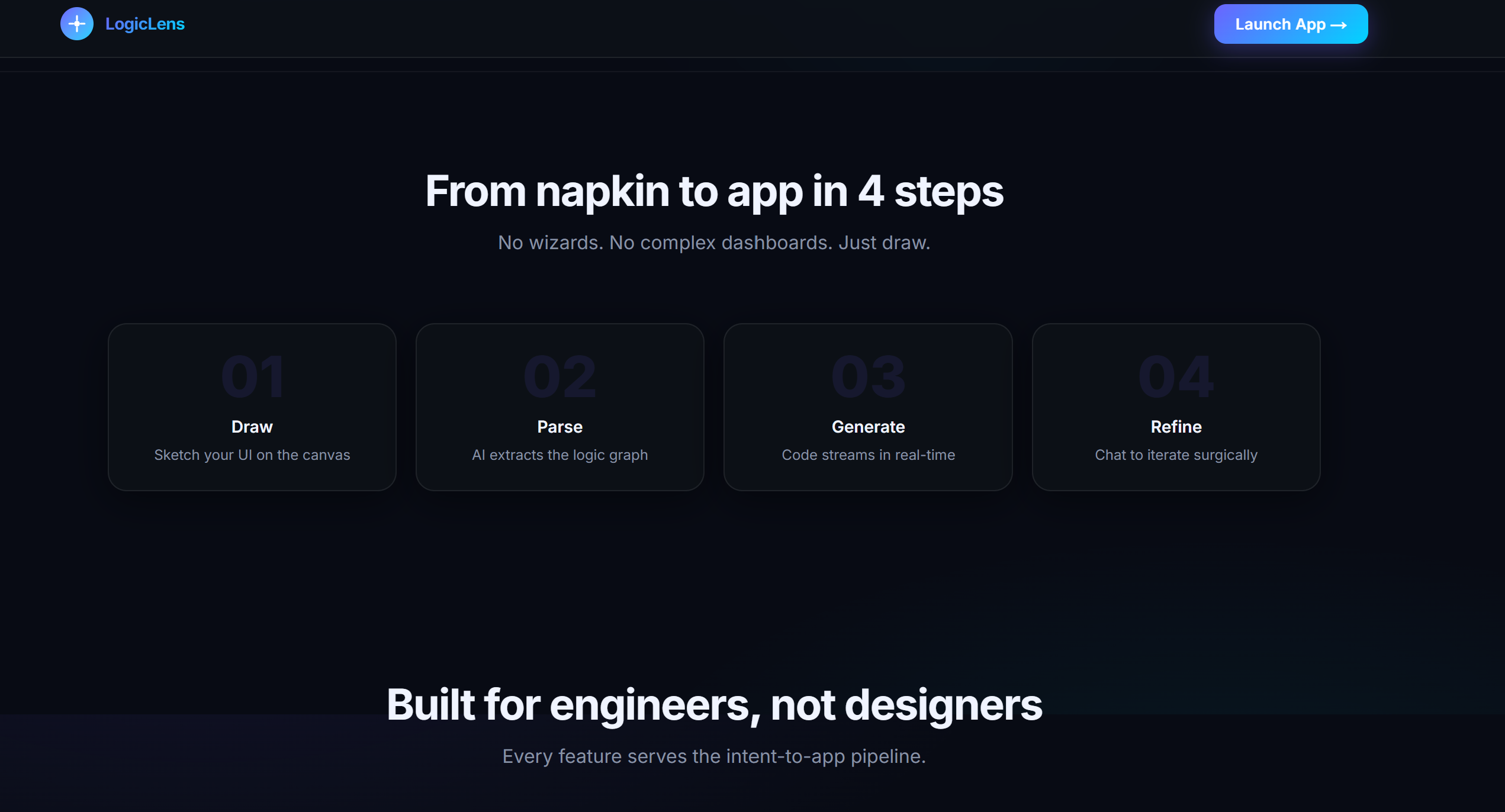
Stages of Working
Inspiration
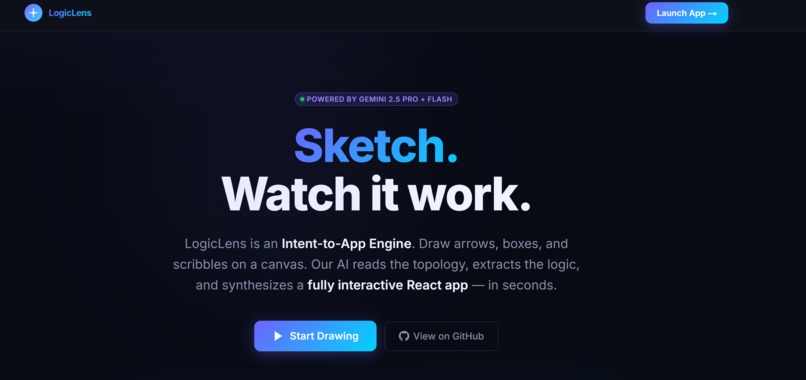
The gap between a brilliant idea and a working prototype is often filled with hours of tedious, boilerplate coding. We love mapping out architectures and UI flows on whiteboards, but translating those messy scribbles into functional code slows down the creative process. We asked ourselves: What if the whiteboard itself could write the code? We wanted to create an environment where drawing a box and an arrow is all it takes to generate a fully routed, interactive React application.
What it does
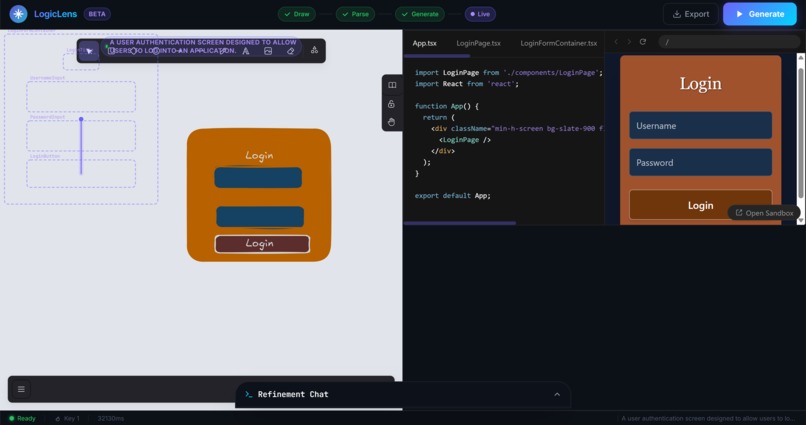
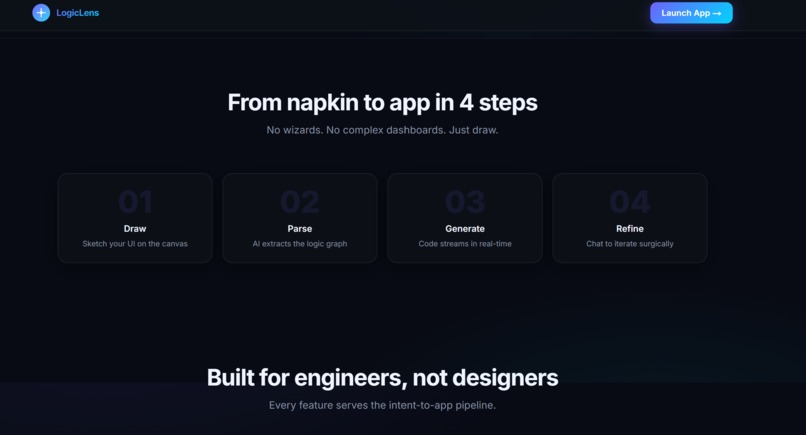
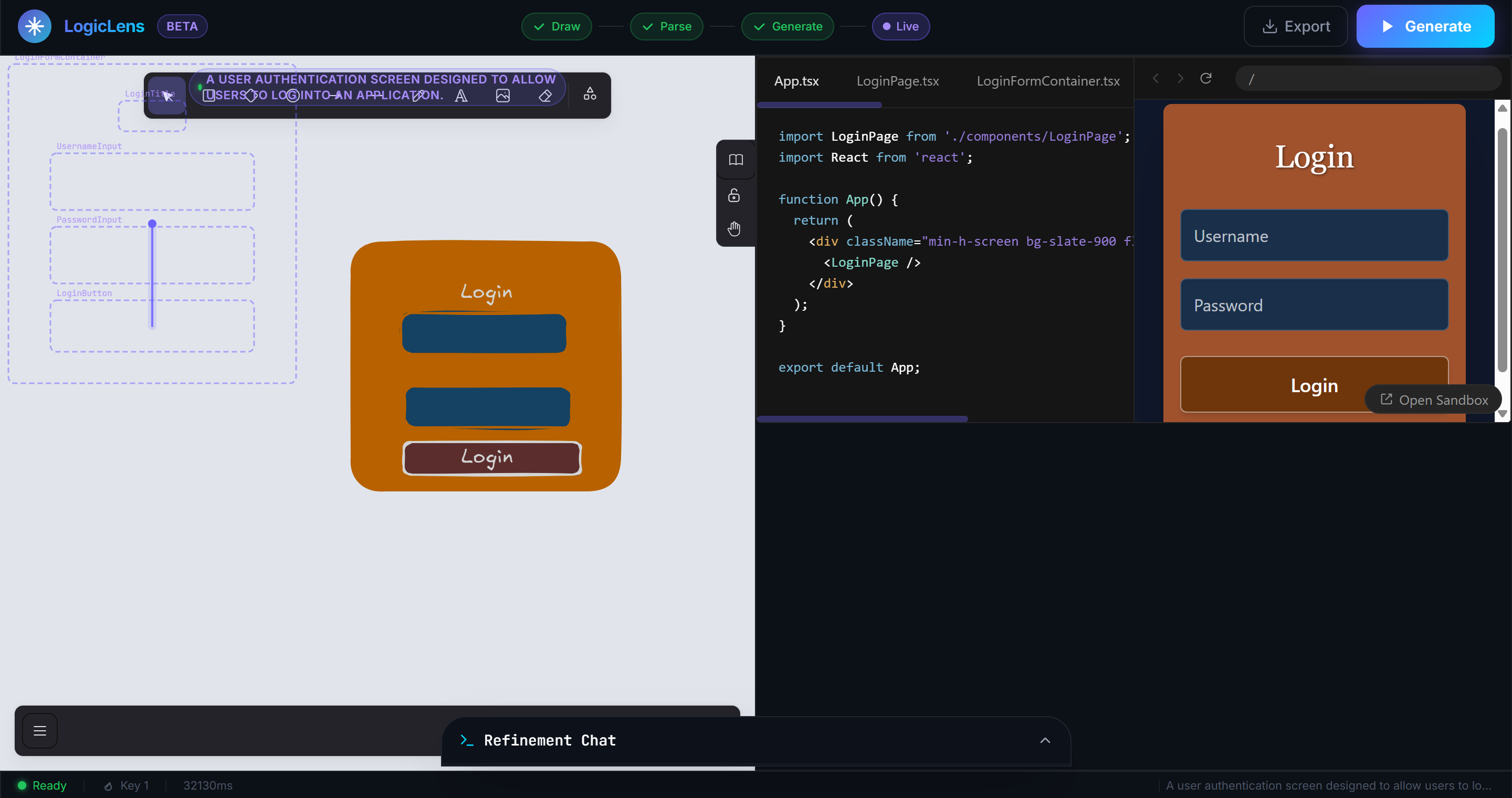
LogicLens is an AI-powered visual development engine. It provides an interactive Excalidraw canvas where you can sketch UI wireframes and logic flowcharts. When you hit generate, it analyzes your drawing and instantly synthesizes a multi-file, production-ready React application.
The generated app is streamed in real-time into a live, interactive CodeSandbox environment directly in your browser. If you want to change something, our surgical Refinement Chat lets you type natural language commands (e.g., "Make it dark themed") to instantly patch specific components.
How we built it
We built the application entirely on the edge using Next.js 15, TypeScript, and Tailwind CSS. To make the AI incredibly accurate, we engineered a custom Dual-Model Edge Pipeline:
- Semantic Parsing: We use Gemini 2.5 Flash to act as a systems architect, rapidly extracting a structured JSON
LogicGraphfrom your sketch. - Code Synthesis: We feed both the original image layout and the JSON data into Gemini 2.5 Pro. This allows the AI to synthesize code that is structurally sound while perfectly matching your visual proportions.
- Execution: The generated code is streamed via Server-Sent Events (SSE) into a client-side Sandpack environment for instant preview without backend container cold starts.
Challenges we ran into
- Taming AI Hallucinations: Initially, the AI struggled to respect the strict relationships between drawn UI elements. We solved this by forcing Gemini Flash to build a rigid JSON logic graph first, giving the code generation phase a definitive "contract" to follow.
- Streaming Latency: Vercel's standard serverless functions time out after 10 seconds, which abruptly killed our long-running code streams. We had to migrate our entire API layer to Next.js Edge Functions.
- Rate Limits: To handle aggressive hackathon testing, we engineered a transparent "Dual-Key Failover" system that automatically intercepts quota errors and switches API keys mid-stream without the user ever noticing.
Accomplishments that we're proud of
We are incredibly proud of the Surgical Refinement Chat. Instead of wasting time and tokens regenerating the entire application when a user wants a small tweak, we instructed Gemini Pro to act as a code reviewer. It looks at the current project state and streams back targeted file patches, updating the live preview in under two seconds.
What we learned
Building LogicLens was a masterclass in chaining Large Language Models. We learned that using a fast, cheap model (Flash) for structured data extraction combined with a heavyweight model (Pro) for creative synthesis yields results far superior to using a single model alone. We also gained deep experience with Edge Computing and Server-Sent Events (SSE).
What's next for LogicLens
We plan to introduce GitHub Integration, allowing users to push their generated LogicLens sandboxes directly to a new repository. We also want to implement a custom UI component library so users can train LogicLens to use their company's internal design system (like Material UI or Radix) when generating code.
Built With
- excalidraw
- javascript
- node.js
- typescript

Log in or sign up for Devpost to join the conversation.