Inspiration
After discovering the GNEC Hackathon 2026 on Devpost, I got curious about UN SDG 3 and read the official UN progress report. One section stopped me "Falling global suicide rate contrasts sharply with upward trends in some regions" and I asked myself: why do people reach that point?
The answer, more often than not, is overwhelm. Too many tasks, too many unprocessed emotions, too much noise and no one to help make sense of it.
I looked at existing AI tools, and they all did the same thing: listed solutions. Clinical, detached, transactional. What people actually need isn't another checklist they need something that meets them where they are, turns a heavy moment into a reflective one, and makes them feel understood.
That's Lagom. Not a therapist, not a productivity tool a quiet companion that helps you find balance, one thought at a time.
What It Does
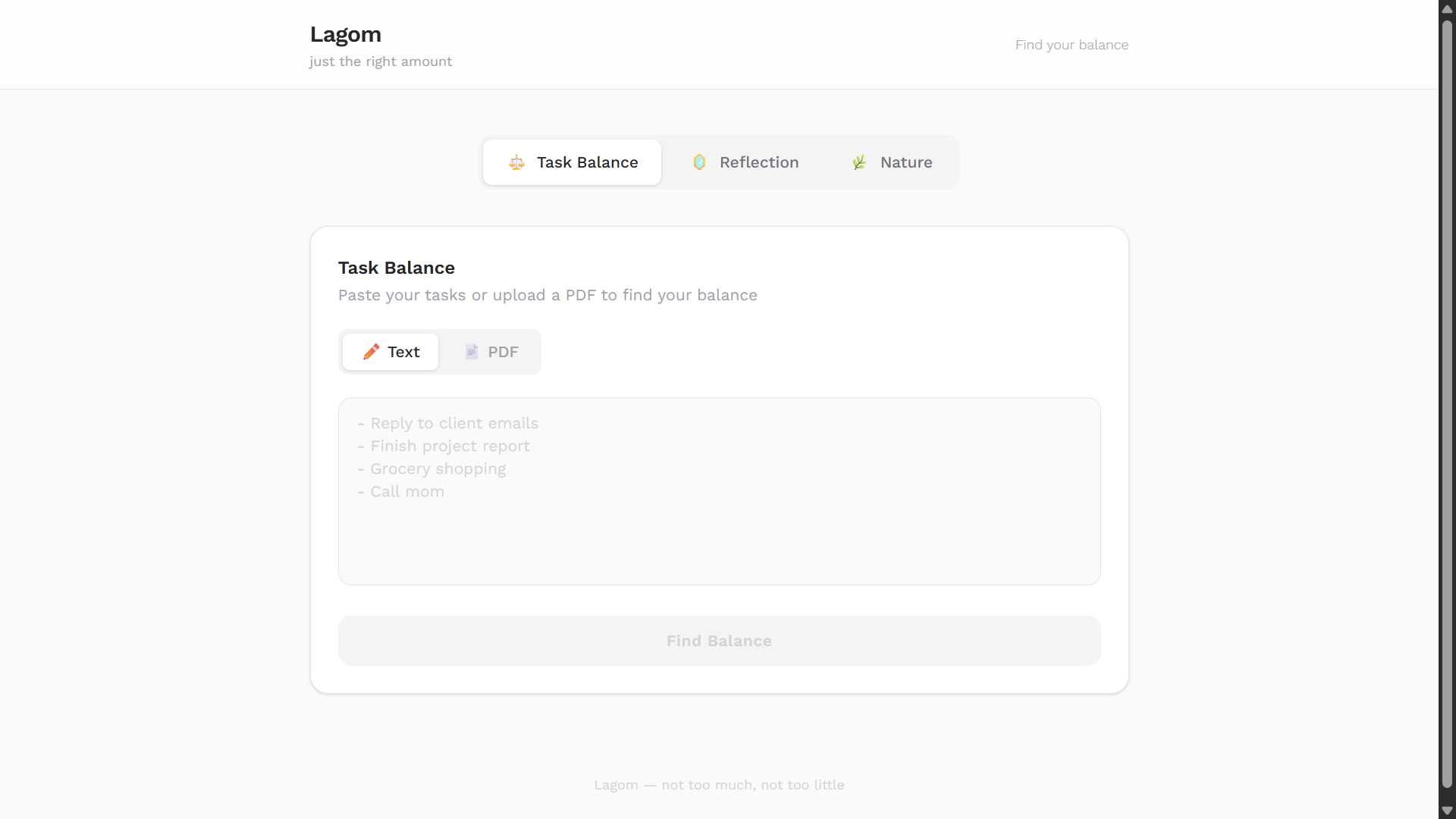
- Task Balance — Paste or upload your to-do list and Lagom identifies overload level, separates essential from non-essential tasks, and suggests what to keep, postpone, or remove.
- Reflection — Write, speak, or upload a journal entry and receive emotional analysis, philosophical interpretation, a relevant quote, and practical actions.
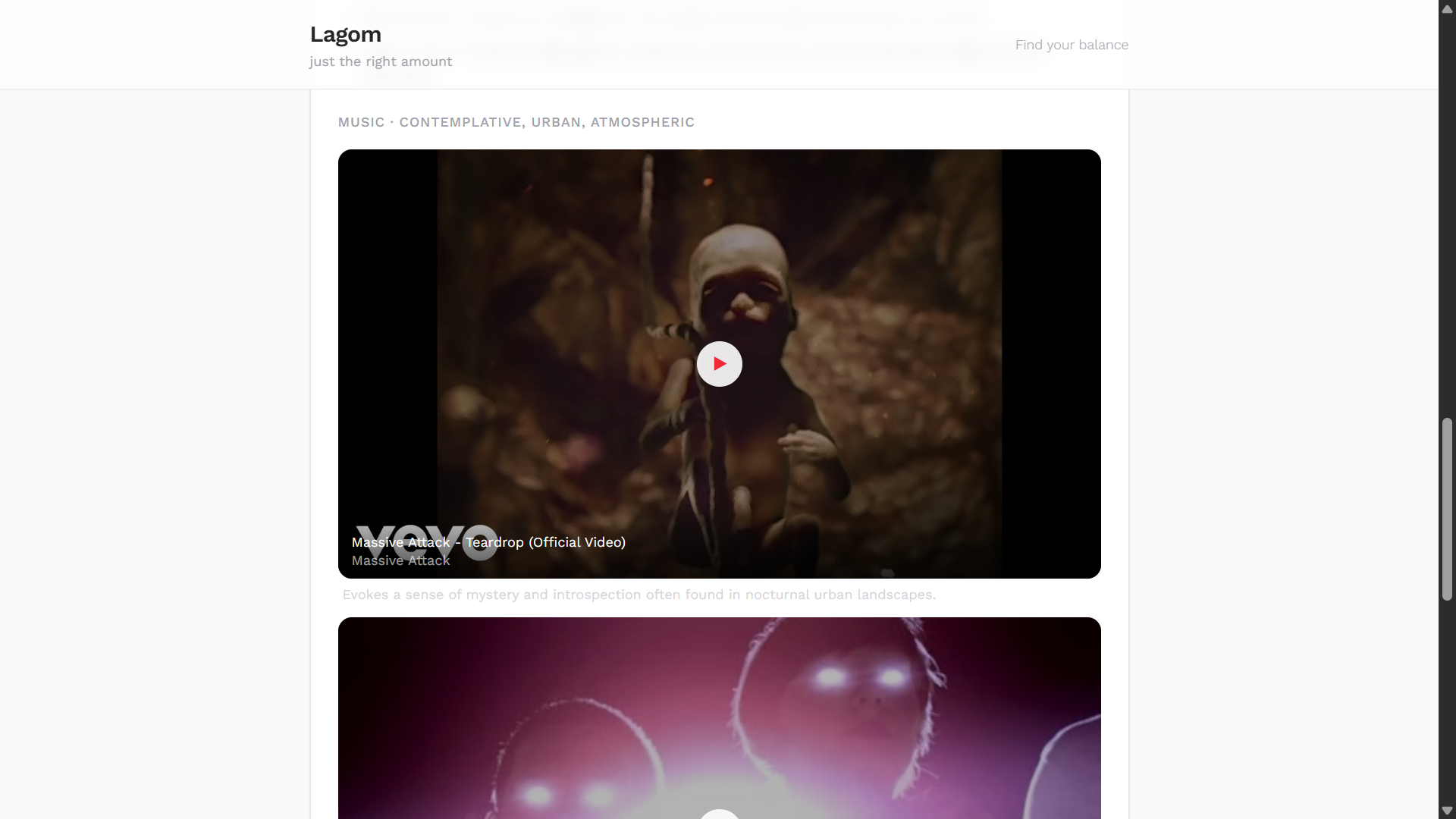
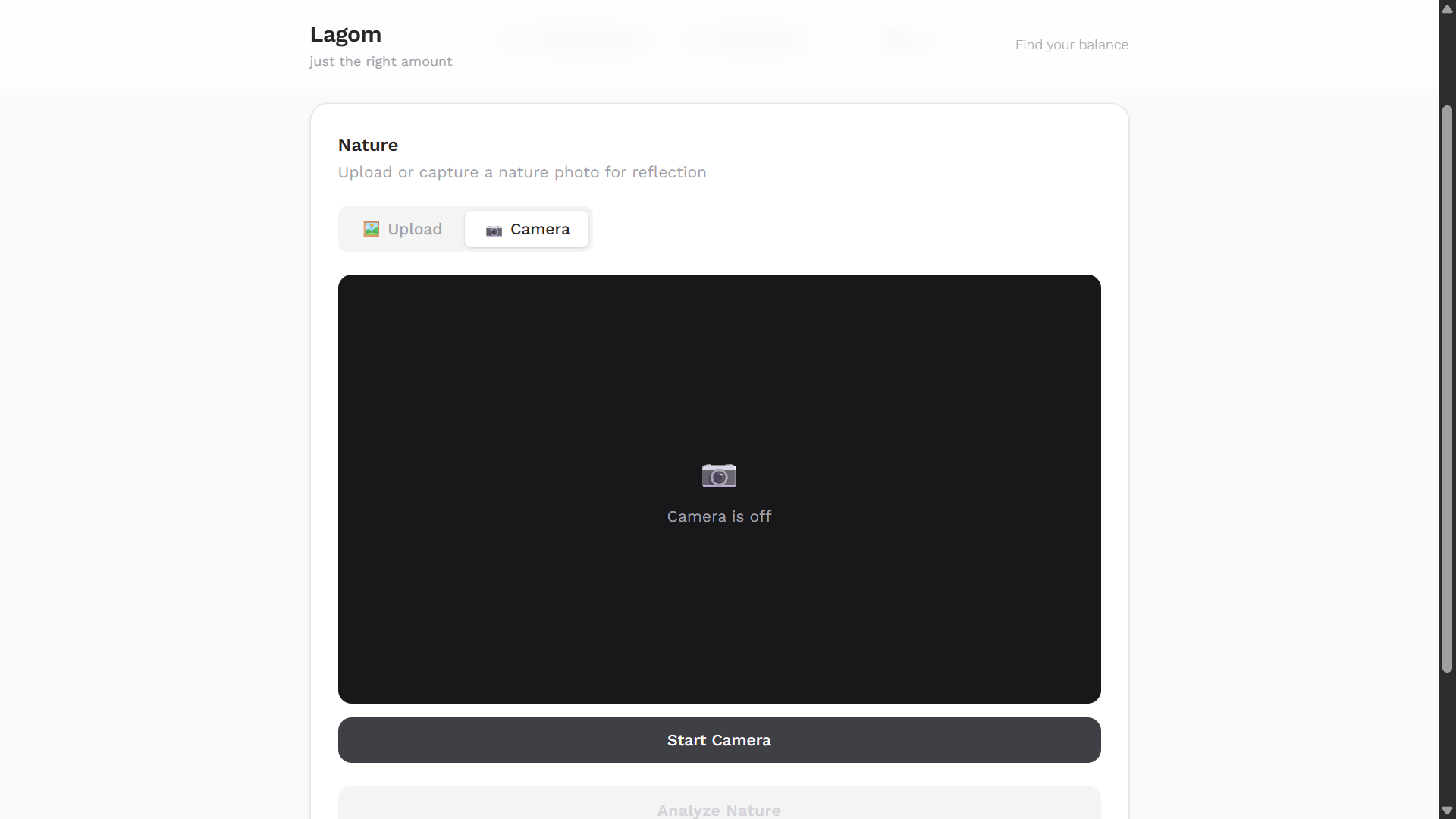
- Nature — Upload or capture a nature photo and Lagom extracts mood, symbolism, and a mindful reflection paired with curated music via YouTube.
- Multi-modal Input — Every feature supports text, PDF upload, and where relevant, voice input and camera capture no friction between you and your reflection.
How I Built It
Architecture

Core Features
1. AI Task Analysis
The user pastes a task list or uploads a PDF. On the backend, the text is preprocessed — normalized whitespace, bullet points, line endings then injected into a structured prompt and sent to Gemini. Gemini returns a JSON object containing an overload level (low, medium, high), a balance score between 0 and 1, essential vs non-essential task lists, per-task suggestions (keep, postpone, remove), and spiritual counterweights small reset activities placed after draining tasks.
2. Philosophical Reflection The user writes, speaks, or uploads a journal entry. Voice input uses the browser-native Web Speech API interim results appear live while the user speaks, and final words accumulate in an editable transcript. The text is sent to Gemini which returns a structured response covering primary and secondary emotions with confidence scores, a two-layer insight (summary + deep reflection), a philosophical tradition match (Stoicism, Taoism, Buddhism, Sufism), a relevant quote, practical actions, and real reading sources with URLs.
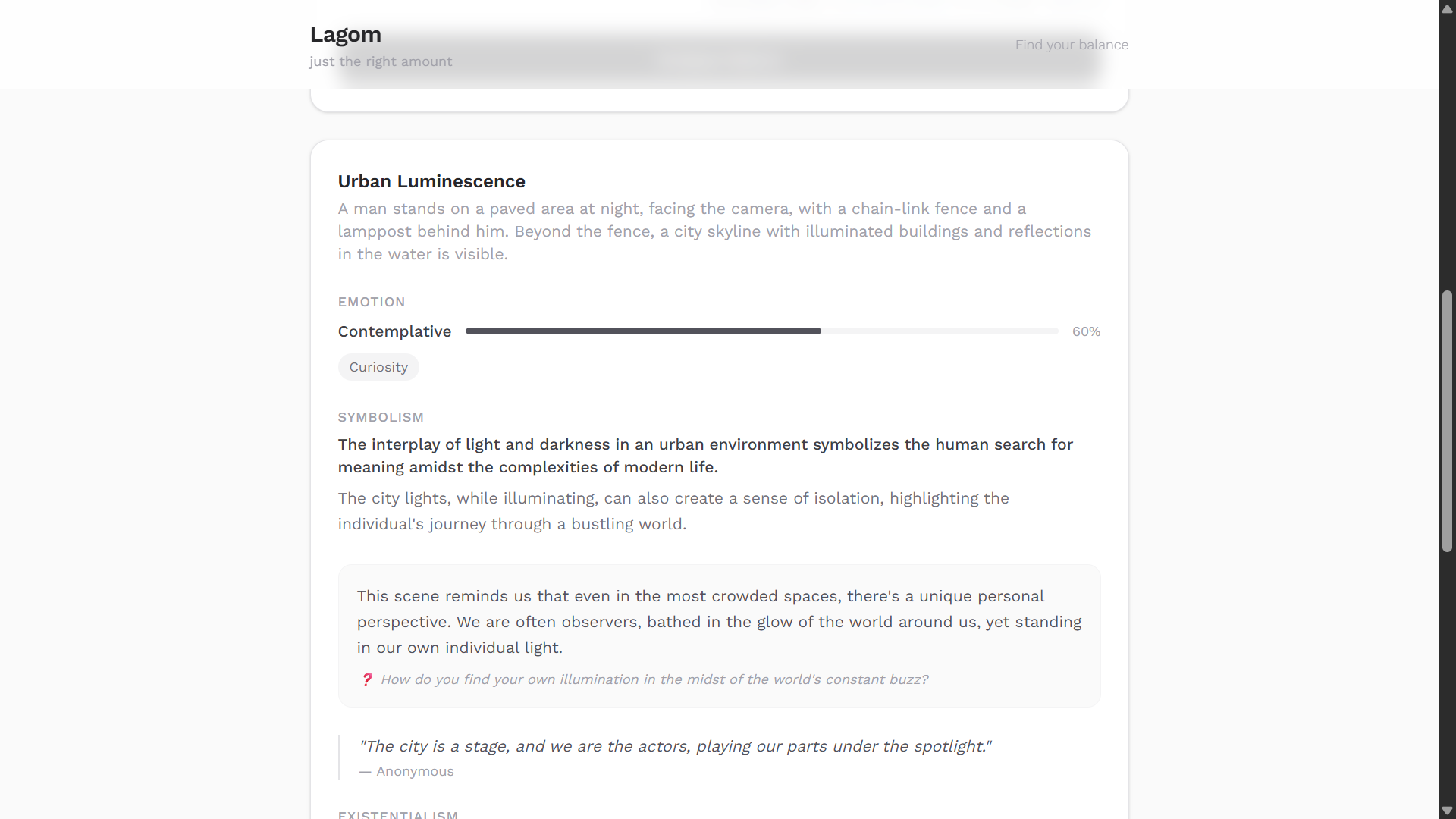
3. Nature Scene Analysis The user uploads or captures a photo. The image buffer is converted to a base64 inline data part and sent directly to Gemini no third-party OCR or vision library involved. Gemini reads the raw image and returns a JSON object with a poetic scene title, emotional mood and intensity, symbolic meaning, a personal reflection message, a self-reflection question, a philosophical insight, and three music track recommendations matched to the mood.
4. Music Integration
The three music tracks returned by Gemini include a search_query field. The backend passes each query to yt-search a lightweight YouTube scraper requiring no API key and returns the video ID, title, channel, thumbnail, and embed URL. The frontend renders each track as a thumbnail with a play overlay; clicking it swaps in a youtube-nocookie.com iframe. Only one video loads at a time to avoid unnecessary network requests.
5. Multi-modal Input
All three features support multiple input types. Text is sent as JSON. PDFs are converted to base64 and passed directly to Gemini as inline file parts no text extraction library needed since Gemini reads PDFs natively. Images follow the same pattern. Voice input is handled entirely in the browser via SpeechRecognition, producing editable text before submission.
Key Capabilities Demonstrated
1. Multimodal Reasoning
- Accepts text, voice, PDF, and images within the same application
- PDFs and images are passed as base64 inline data parts directly to Gemini no separate OCR or vision pipeline
- Gemini reads the raw content and reasons across modalities in a single API call
- Voice input is transcribed browser-side and treated identically to typed text on the backend
2. Advanced Document Understanding
- PDFs are not parsed into plain text they are sent to Gemini as native file parts, preserving layout context
- Gemini extracts meaning from scanned documents, formatted to-do lists, and handwritten journal PDFs
- The backend validates and post-processes the extracted structure before returning it to the client
- Works regardless of font type, layout complexity, or document formatting
3. Structured JSON Generation
- Every Gemini call returns a strictly defined JSON schema no free-form text responses
- Prompts enforce field names, value types, and array lengths (e.g. exactly 3 music tracks)
- The service layer post-processes responses clamping scores, ensuring arrays exist, applying fallbacks
- This makes the AI output directly renderable by React components without transformation
4. Emotional and Philosophical Intelligence
- Reflection analysis identifies primary and secondary emotions with a confidence score
- Each response is grounded in a real philosophical tradition Stoicism, Taoism, Buddhism, or Sufism
- Quotes are attributed to real historical figures; sources link to real, publicly accessible texts
- Nature analysis connects visual scenes to human emotional states through symbolic interpretation
5. Real-time Contextual Music Matching
- Gemini suggests music tracks semantically matched to the emotional tone of the nature scene
- Each track includes a
search_queryfield used by the backend to find the real video viayt-search - Music is fetched in parallel using
Promise.allSettleda failure on one track does not block the others - Videos load lazily thumbnails render first and the iframe only initialises on user interaction
Tools Used
| Tool | Why |
|---|---|
Google Gemini (gemini-2.5-flash-lite) |
Core AI engine. Chosen for its native multimodal support it reads PDFs and images directly as inline data without a separate vision pipeline. Fast and cost-efficient for structured JSON output. |
yt-search |
Lightweight YouTube search scraper. Used for music lookup without requiring a Google Cloud account or API key quota. |
multer |
Handles multipart file uploads in Express. Memory storage keeps files as buffers no disk writes so they can be base64 encoded and forwarded to Gemini directly. |
| Web Speech API | Browser-native speech recognition. Used for voice journal input with no external dependency works in Chrome and Edge without any backend involvement. |
What I Learned
The most valuable lesson wasn't technical it was learning to slow down and actually understand the problem before writing a single line of code. I spent time reading the UN SDG 3 progress report, not skimming it, and that's what led me to a specific gap: existing tools offer solutions, but people in overwhelm need to feel understood first. Finding that gap gave the entire project a clear direction.
From there, planning the architecture before coding made everything easier. When your folder structure is intentional routes, services, prompts, utils each doing one thing the code becomes readable, and readable code writes better documentation. I refactored several files specifically because I realized I couldn't explain them clearly, and that was a signal they weren't clean enough.
Writing the documentation taught me that clarity is a design decision. If you can't describe what a function does in one sentence, it's doing too much.
Finally, recording the demo video taught me something I didn't expect how to describe your own thinking genuinely. Not as a feature list, but as a story that connects a real human problem to a real solution. That's harder than building the app.
Challenges I ran into
The first challenge was translating a human problem into a buildable system. I knew I wanted to help people find balance but "balance" isn't a feature, it's a feeling. Turning that into a concrete architecture took time. I broke it down to one feature at a time, wrote out each step before touching code, and that discipline is what made it possible.
During development, three things genuinely slowed me down:
PDF parsing was unexpectedly painful. I went through two libraries — pdf-parse failed silently on ESM, pdf2json returned garbled text on Type3 font PDFs before realising the cleanest solution was to skip parsing entirely and send the raw PDF buffer directly to Gemini as an inline file part. Sometimes the fix is removing the problem, not solving it.
Gemini's JSON output wasn't always reliable. Without responseMimeType the response sometimes included markdown fences or got truncated mid-JSON. I had to tighten the prompts, add explicit rules, raise maxOutputTokens, and add post-processing in the service layer to clamp values and ensure arrays always exist.
Getting Spotify to work took longer than expected. The Client Credentials flow authenticated fine but the Search API returned "Active pre-condition failed" the app wasn't approved for extended quota yet. I dropped Spotify entirely and routed all three music tracks through yt-search, which required no API key and worked immediately. Knowing when to cut a dependency is a real skill.
Built With
- express.js
- javascript
- multer
- node.js
- react
- tailwind


Log in or sign up for Devpost to join the conversation.