-
-
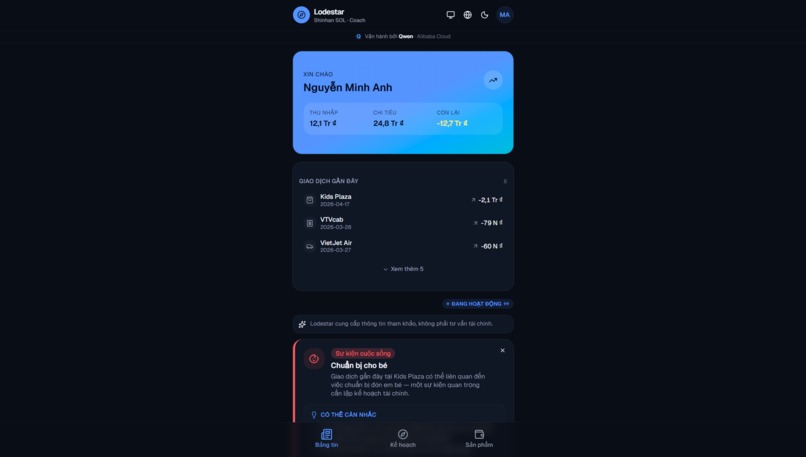
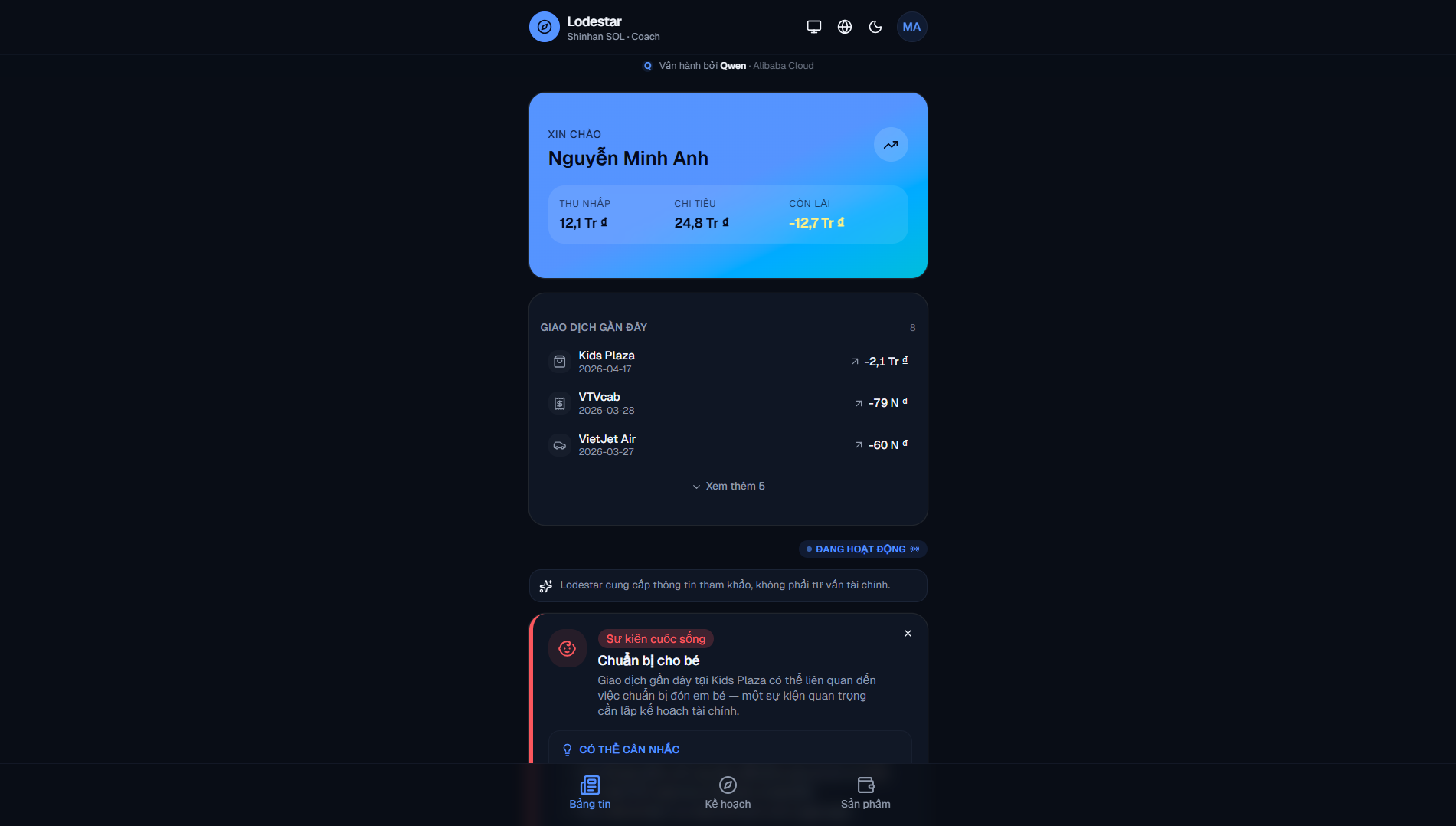
Feed: Balance is in the red. The system noticed baby shopping at Kids Plaza and put up a card about it.
-
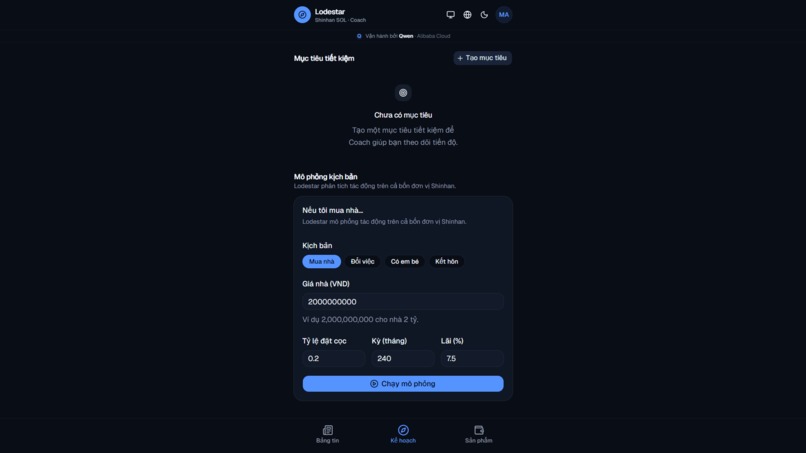
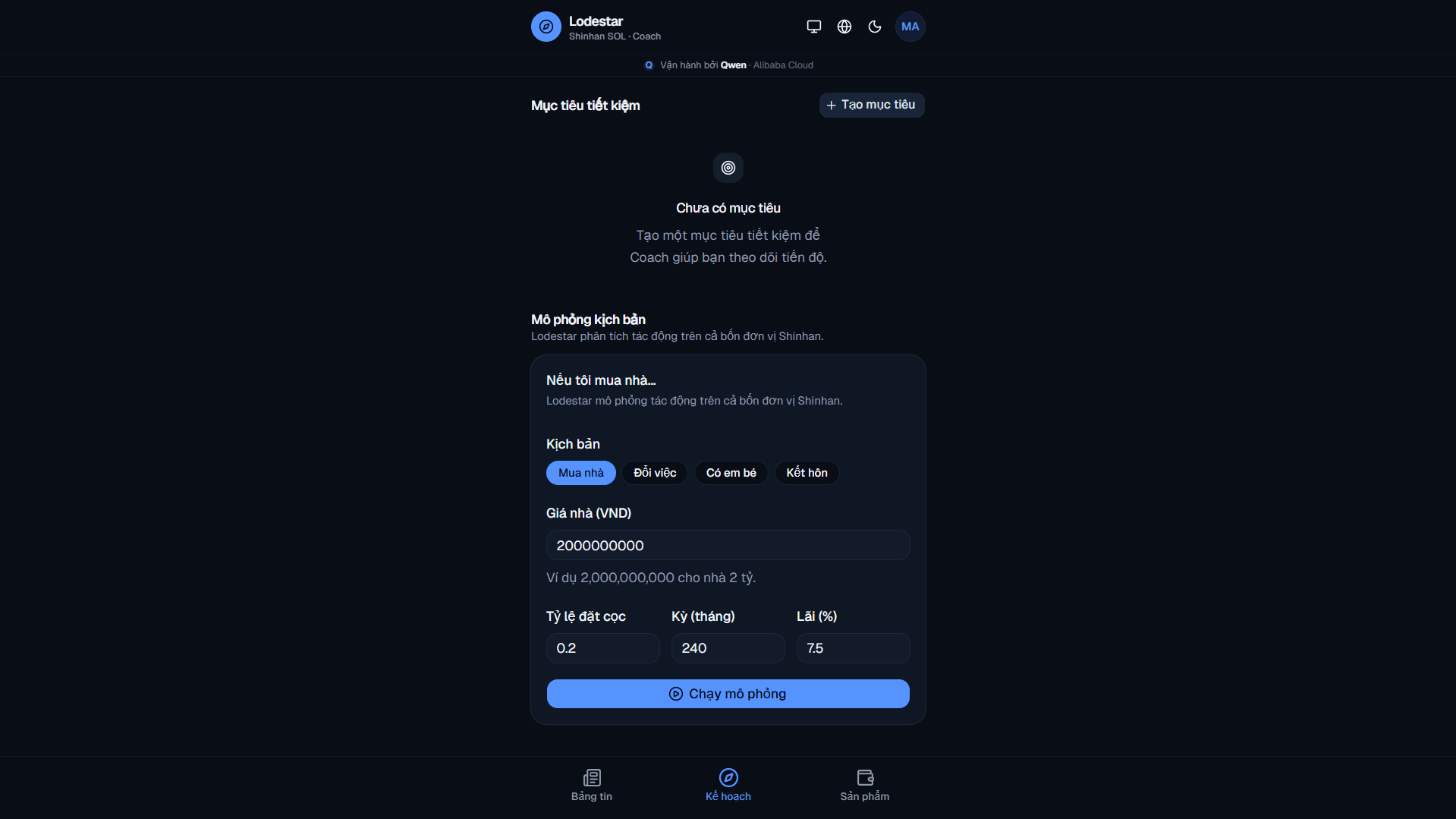
Scenario simulator: What if you bought a house? Put in the price and terms, hit simulate.
-
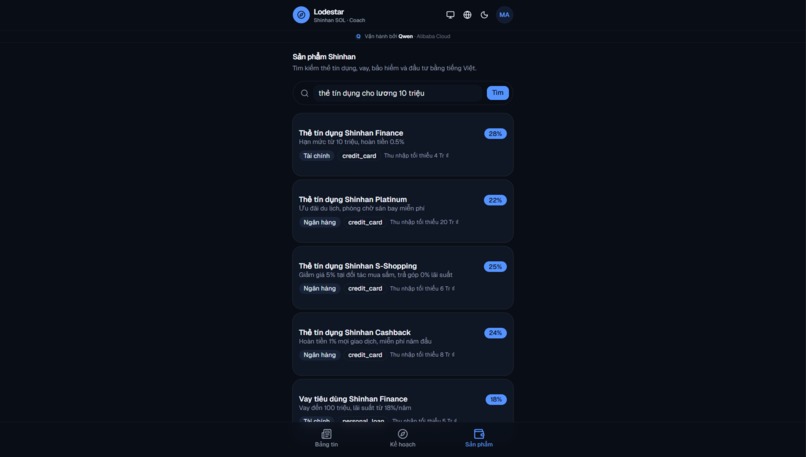
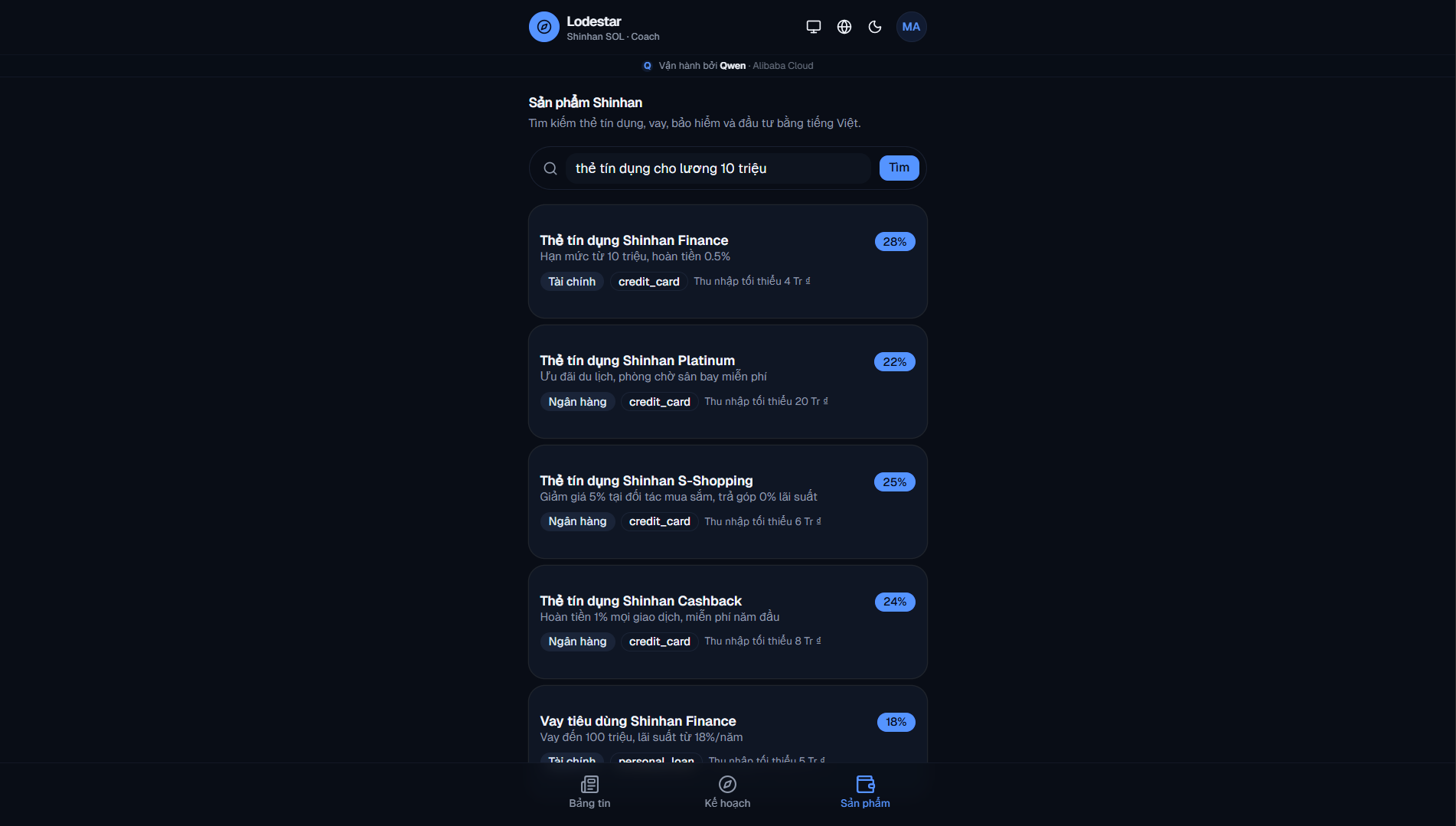
Product search: Typed "credit cards for 10M salary" in Vietnamese. Got five matches back.
-
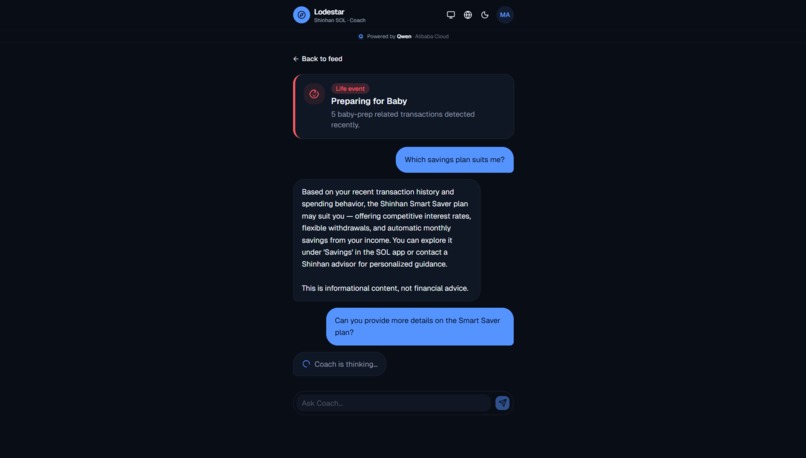
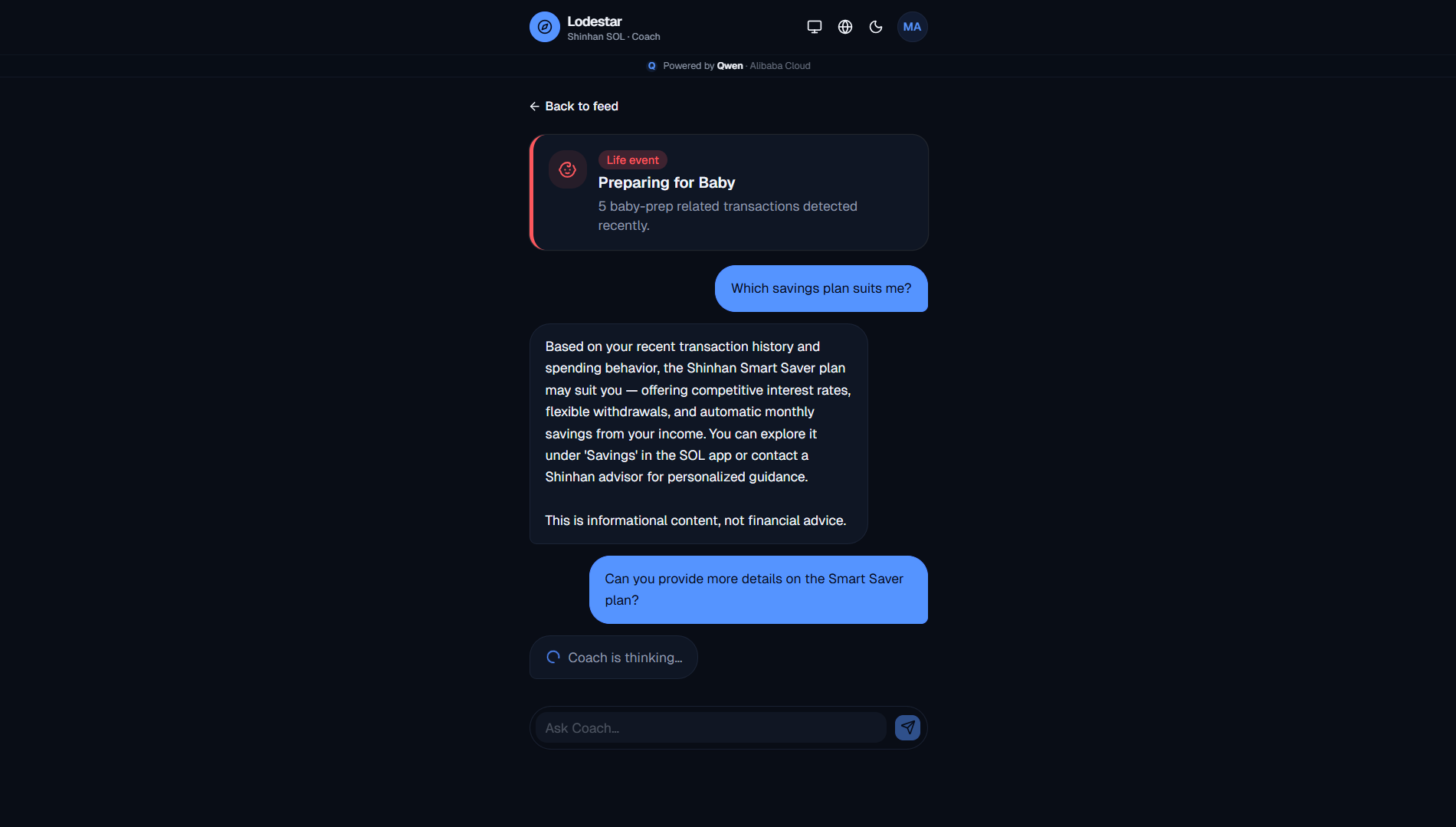
Life event: Tapped the baby card, asked about savings. Qwen pulled a plan from the catalogue.
-
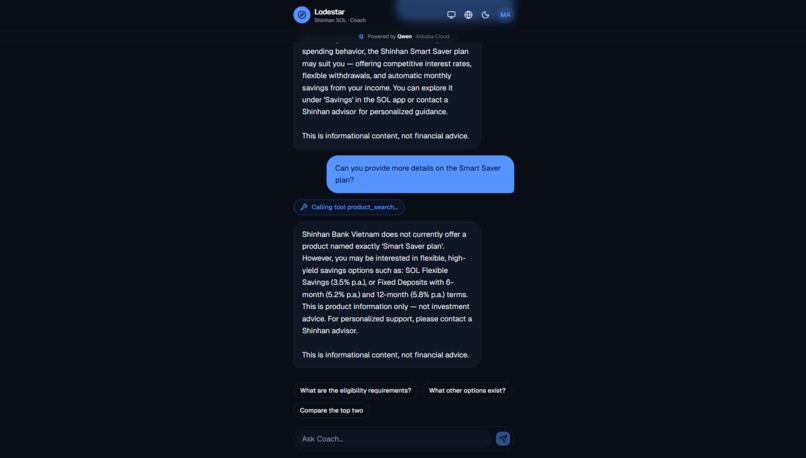
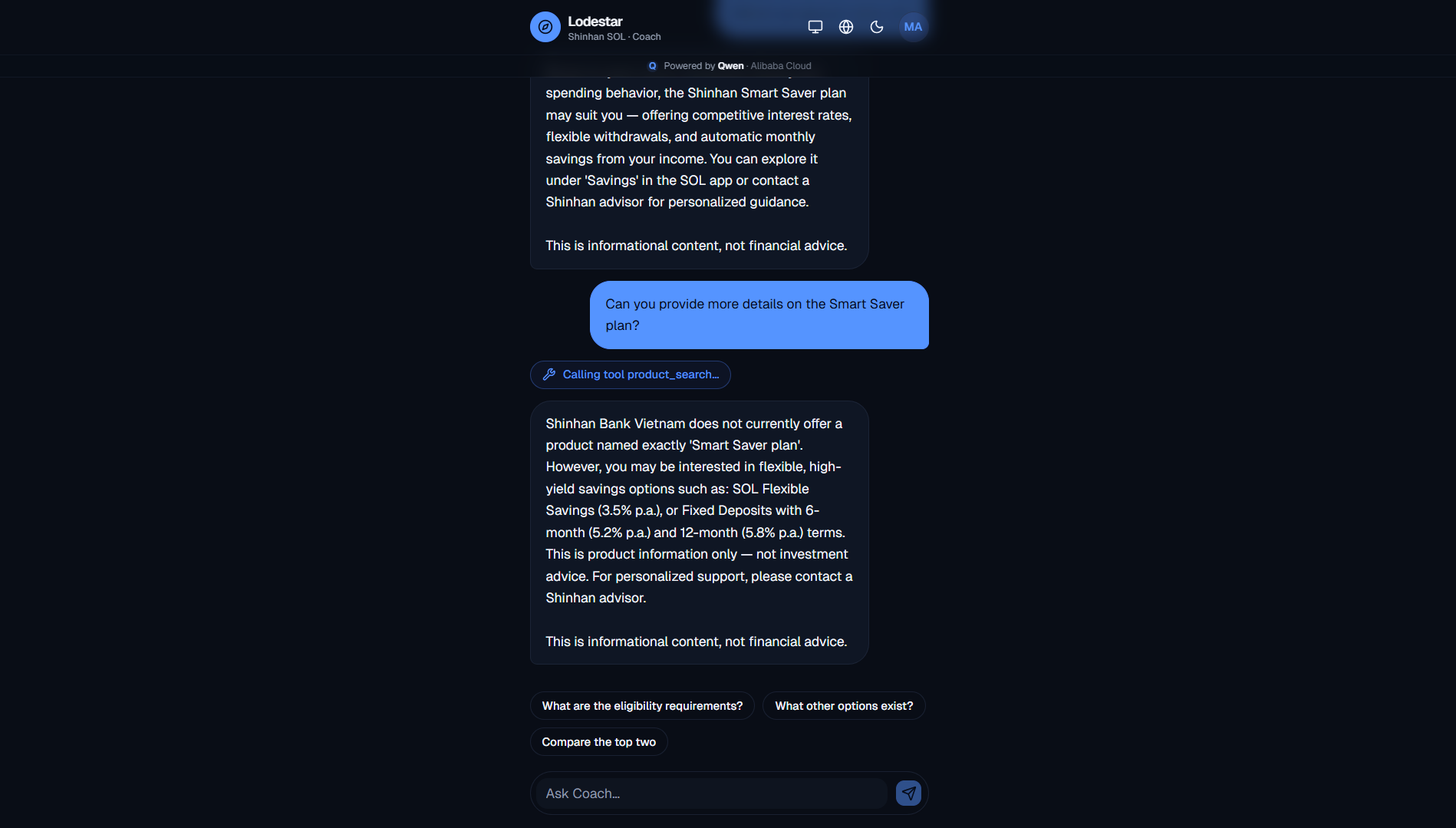
Tool-calling chat: Asked a follow-up. The coach looked up products mid-chat and came back with numbers.
Lodestar
A guiding star for your financial life.
Track: SB1 — AI Personal Financial Coach Repository: https://github.com/BrianIsaac/lodestar Live demo: http://43.98.179.20:3000/?demo=1 Backend API: http://43.98.179.20:8000
Submission checklist
- Official track selected — SB1 · AI Personal Financial Coach (Digital Business Unit · Retail Solution Division · Card Division).
- Public repository attached — https://github.com/BrianIsaac/lodestar, Apache 2.0-licensed, full source, Dockerfile, and compose config.
- Live demo attached — running on Alibaba Cloud ECS, Singapore zone A. The
?demo=1flag reveals the Simulate drawer used for preset transactions; without the flag, the app matches the production embedding mode and only reacts to real SOL-side events. - Qwen utilisation — documented in the "Qwen in the architecture" section below. Two distinct agents (detector + orchestrator) run against
qwen-plusvia DashScope's OpenAI-compatible endpoint; both use tool-calling + structured JSON output. - Demo video — embedded on the Devpost submission page.
Inspiration
Most banking apps bury their chatbot three menus deep. You ask it something, you get a script. We wanted something that watches your transactions and says something useful before you ask.
Lodestar is a PoC for Shinhan Bank Vietnam's SOL app. Name is literal: a fixed point you navigate by. Runs on Qwen3, Vietnamese-first, works on-premise.
The SB1 brief is explicit — analyse spending, recommend products, answer financial questions in natural language, and do it in a way that moves DAU/MAU, cross-sell, retention, NPS, and CASA. Today SOL serves ~2M customers with balance-check chrome. Sixty-eight percent of digital interactions never go beyond that. Half the customer base splits money across three or more banks because nothing in SOL gives them a reason to stay. That's the surface Lodestar activates.
What it does
Monitors transactions, spots patterns, pushes insight cards to a feed. Spending spike, recurring charge changed, baby products appearing? It notices. Tap a card, get a conversation with charts.
- Cross-entity scenarios. Ask "what if I buy a house?" and see the impact across Shinhan's four subsidiaries at once: mortgage from Bank, existing debt from Consumer Finance, portfolio liquidation from Securities, coverage gap from Life Insurance. Single-entity competitors architecturally cannot ship this.
- Life-event detection from transactions. Hospital visits and baby-store purchases clustering? The agent synthesises them into one card before the customer says anything. Silent on one coffee, synthesised on three baby-merchants plus a hospital.
- Learns per customer. Keep dismissing spending alerts but clicking investment cards, it adjusts. Advice that worked by luck doesn't get reinforced — Van Tharp's process/outcome split, borrowed from trading. Good outcomes from bad process are dumb luck, not lessons.
- Cross-customer cohort aggregates. Anonymised patterns from similar customers feed back in so new users aren't starting cold. Keyed by
{city}_{segment}so no PII leaves the customer record. - Authored in three locales at write time. Every card title, summary, action hint, chat reply, chart caption, follow-up chip, and waterfall step label is written in Vietnamese, English, and Korean by a single structured-output LLM call. Language toggle is pure render — zero round-trips.
- Compliance gated at composition time. A classifier runs across all three locales before anything ships. Worst class propagates, so a Vi refusal never sits next to untreated En advice.
- Financial math is deterministic Python. The LLM writes and reasons but doesn't touch a calculator. Cashflow, mortgage amortisation, scenario projections are all pure functions the LLM calls as tools.
How we built it
Python 3.11+ (runs on CPython 3.13 locally and in the container), FastAPI, LangGraph for workflows, OpenAI-compatible tool calling for orchestration. Qdrant embedded, SQLite (WAL + BEGIN IMMEDIATE for lesson-evolution concurrency), bge-m3 multilingual embeddings. Synthetic customer data via SDV and Faker.
Qwen3 through DashScope API (qwen-plus) for the live demo, Ollama (qwen3:14b) locally. On-premise target is Qwen3-8B at Q4_K_M on a 12GB GPU — one env var swaps the backend.
Next.js 16 App Router + React 19, shadcn/ui (base-nova preset), Recharts. Shinhan Blue (#0046FF) in OKLCH. SSE diff-only streaming for the insight feed.
The agent wiring is the interesting bit:
- Detector watches each transaction. Qwen3 picks which of 10 rule sensors to invoke (as callable tools), decides whether the signals compose into a card, writes the card in all three locales in one structured output, runs compliance, persists via WAL.
- Orchestrator handles drill-down chat. Always-two-turns pattern: turn 1 is tool-calling (product_search / spending_analysis / scenario_simulation), turn 2 is JSON synthesis emitting
content_i18n+user_message_i18ntogether. Zero re-translation on toggle. - Learning loop records each interaction, runs a Van Tharp reflection, gates lesson extraction on process grade ≥ B and confidence ≥ 0.70, then aggregates into the cohort table once N distinct customers share a pattern.
Challenges we ran into
bge-m3 CDN wouldn't cross the border. The 1GB multilingual embedding model kept timing out downloading from HuggingFace — Alibaba Cloud's network and HuggingFace's CDN don't get along. We downloaded it manually through hf-mirror.com, cached it in a Docker volume, wrote a retry loop + warmup ping on lifespan startup.
Qwen3 sometimes echoed the user's text into the wrong locale. When a user typed Korean with the UI in Vietnamese, the orchestrator's JSON turn occasionally put the raw Korean into every locale slot — so toggling to Vi rendered Hangul inside a Vietnamese bubble. Fixed with a script-based guard: detect Hangul Unicode range vs Vietnamese-specific diacritics, drop entries whose script doesn't match the slot, preserve the source locale's legitimate echo. Also bumped turn-2 max_tokens from 2048 to 3072 because the model was hitting the budget mid-JSON and taking translation shortcuts to stay inside.
Lesson journal grew linearly on the cloud deploy. The merge path in add_or_evolve_lesson concatenates existing.insight with the new piece every time, no dedupe. Invisible locally because developers wipe the SQLite file between sessions; visible on the cloud container because the mounted Docker volume persists lessons and cohort_insights across every redeploy. After ~14 identical chat engagements the stored lesson text is the same sentence repeated 14 times and the cohort row inherits the garbage. Diagnosed via a codebase-analyzer trace down to journal.py:110; fix (split-dedup-cap helper + DELETE FROM cohort_insights on demo reset) is designed but not yet shipped — it's a known issue we'd land before any real deployment.
SQLite race under concurrent dismiss + chat. Two tabs could both fire reflection-write on the same interaction row; WAL mode doesn't serialise read-modify-writes. Wrapped the hot paths (append_to_interaction, aggregate_to_cohort, add_or_evolve_lesson) in BEGIN IMMEDIATE transactions.
Compliance patterns had Latin-bias. The first classifier caught English and Vietnamese ADVICE/GUIDANCE wording but not Korean — a Ko reply could ship next to a Vi refusal. Rewrote apply_compliance_multilingual to classify every locale, pick the worst class across all three, and gate every locale at that level.
Accomplishments we're proud of
- Design doc said deterministic triggers auto-fire cards. What we built gives the LLM the triggers as callable tools. It decides which to check and whether a card is worth showing. The model combined signals we hadn't hardcoded — e.g. cluster baby-merchants + hospital = one card, not three.
- Tri-lingual UI at zero latency. Detector writes every card in all three languages at creation. Orchestrator writes chat replies + the user's own message verbatim-translated in all three. Chart i18n covers titles, summaries, axis labels, and waterfall step labels via a backend
lodestar.i18nmodule so the deterministic chart generators never need an LLM call for captions. The toggle is a pure render. - Learning loop works end-to-end. Tracks card interactions, extracts Van Tharp reflections quadrant-coded, crystallises lessons with bge-m3 embeddings, feeds them back into the next detector run. Every subsequent card carries a
lessons_applied=Ncount — the compounding is visible in the memory panel. - Cross-entity simulator actually ships. Four scenarios (home, career, baby, marriage), each computes impact across Bank + Consumer Finance + Securities + Life Insurance in one deterministic Python pass. Bank-only competitors can show you the mortgage; Lodestar shows the whole picture.
- 83 tests green, including concurrency regression tests for the BEGIN IMMEDIATE work and a Korean RAG retrieval test that confirms bge-m3 surfaces the Vietnamese catalogue from Hangul queries.
What we learned
Giving the LLM tools instead of answers changes how you design the system. We started with hardcoded rules that auto-fired. Switching to "here are 12 tools, figure it out" felt risky but the model combined signals we hadn't thought of.
Tri-lingual at write time beats tri-lingual at render time — but only if the prompt is unambiguous about which locale is the source and what translating into a locale means. Qwen3's first instinct, when told to "echo the original unchanged", was to echo into every locale. We rewrote the prompt with an explicit few-shot example and a source-language interpolation; reliability went from ~60% to ~95%. The remaining 5% is handled by the script-based post-parse guard.
Compliance is a system property, not a feature. If the classifier only sees one locale, the other two can quietly drift into unlicensed advice. Running it across the whole bundle and taking the worst class is the only way to guarantee consistent regulatory posture.
Building the learning loop was the easy part. Evaluating it is harder. Lessons are accumulating but we don't have enough runway to know if the advice is actually getting better — that's a multi-week telemetry story, not a demo.
What's next for Lodestar
- Scale Qwen3 up or down depending on deployment target. The LLM backend is abstracted behind one env var (
COACH_LLM_BASE_URL+COACH_LLM_MODEL), so the same agent code runs against anything that speaks the OpenAI-compatible API: DashScopeqwen-plusfor the live demo;qwen3:14bvia local Ollama for dev; Qwen3-8B at Q4_K_M on a 12GB GPU for on-premise bank hardware; or Qwen3-4B / Qwen3-1.7B for an eventual edge-device deployment on a branch kiosk or agent tablet. No code change — only a config flip. The same tool-calling contract, the same tri-lingual JSON schema, the same compliance pipeline. What we still need is the ops story: warm-up time on cold boots, GPU utilisation under concurrent detector + orchestrator load, and telemetry to pick the right size per deployment. - Real Shinhan product catalogue instead of synthetic. Webhooks for transaction ingestion against actual SOL infrastructure.
- Run the learning loop for weeks on a closed-beta customer cohort and find out if the advice measurably gets better over time (lesson apply-rate × dismiss-rate × goal-completion).
- Explore PII-free federated cohort aggregates across multiple Shinhan entities — the cohort table is scoped by
{city}_{segment}today, but it could cross bank / finance / securities / insurance customer bases. - Mobile-native embed inside SOL's existing navigation rather than the web-app shell.
Qwen in the architecture
Qwen3 is the reasoning core of the system. It is called from two distinct agents, each with a different role, prompt, and tool set. Both use the DashScope OpenAI-compatible endpoint (qwen-plus) — one env var swaps the backend between DashScope and local Ollama, so on-premise deployment to a Qwen3-8B host requires no code change.
Agent 1 — Detector (src/lodestar/agents/detector.py)
- Trigger: runs inside an asyncio background task after every transaction write.
- Role: decides whether a new transaction is worth surfacing to the customer as an insight card.
- Inputs: the new transaction row, recent transaction context, the customer's prior lesson journal (retrieved via bge-m3 cosine similarity and pasted into the system prompt as agent memory), and the list of 10 rule-sensor tool definitions.
- Loop: Qwen3 iterates a tool-calling loop — invokes sensors like
check_velocity_anomaly,check_life_event_pattern,check_first_time_merchant, reads the results, and decides whether the signals cohere into a card or whether to stay silent. Silent is a first-class outcome: most transactions produce zero cards. - Output: a structured JSON object (
response_format=json_object) containingtitle_i18n,summary_i18n,action_hint_i18n,quick_prompts_i18n, andchart_spec— all three locales authored in one call, never translated post-hoc. - Downstream: compliance classifier runs on all three locale outputs, worst class propagates, card is persisted with the full i18n bundle, SSE stream fires to the frontend.
Agent 2 — Orchestrator (src/lodestar/agents/orchestrator.py)
- Trigger: customer taps an insight card and asks a question (or picks a quick-prompt chip).
- Role: answers the customer in natural language, calling deterministic workflow tools where needed.
- Always-two-turns pattern:
- Turn 1 — Qwen3 receives the chat history + tool definitions (
spending_analysis,product_search,scenario_simulation). It may call one or more tools; results are fed back. Tool results include deterministic Python output (cashflow math, product retrieval, scenario projection) — the LLM never does arithmetic. - Turn 2 — tools stripped,
response_format=json_objectenforced, temperature dropped to 0.3. Qwen3 emits a single JSON object containingcontent_i18n(assistant reply in three locales) anduser_message_i18n(the customer's own last message verbatim-translated into three locales). This is what makes the user bubble swap on language toggle.
- Turn 1 — Qwen3 receives the chat history + tool definitions (
- Guardrails: post-parse, a script-based sanity check validates each locale's value matches its expected script (Hangul for
ko, Vietnamese-diacritic Latin forvi, otherwiseen). Duplicate-locale guard drops failed translations. Compliance runs once across all three locales and takes the worst class. - Output:
ChatResponsewithmessage.content_i18n,user_message_i18n,tool_calls,suggested_followups_i18n, and optionalchart_spec(also tri-lingual).
Why two agents, not one
Separation is about prompt size and latency. The detector's job is decide and silently exit most of the time — it has a narrow sensor palette and optimises for deciding fast. The orchestrator's job is converse and compose — it needs bigger context, more tools, and structured JSON output. Forcing a single agent to do both made the silent-exit path too slow and the compose path too constrained. Two agents, same model, different prompt shapes — Qwen3 handles both cleanly under DashScope's streaming throughput.
Alibaba Cloud stack
- ECS (
ecs.c9i.xlarge, 4 vCPU, 8GB RAM, Ubuntu 22.04, Singapore zone A) - DashScope API (Model Studio) for all Qwen3 inference
- VPC + Security Groups for network isolation
- Block Storage (80GB cloud disk, Docker-volume mounted for SQLite + Qdrant persistence)
- Anti-DDoS Origin Basic
- Security Center Basic
Deployment is a single docker compose up --build -d against the repo — the backend image bakes in the bge-m3 cache, the frontend image builds Next.js production output, and a named volume carries state across redeploys.
Built With
- alibaba
- bge-m3
- cloud
- css
- dashscope
- docker
- ecs
- faker
- fastapi
- huggingface
- langgraph
- next.js
- oklch
- python
- qdrant
- qwen3
- recharts
- sdv
- sentence-transformers
- shadcn/ui
- sqlite
- tailwind
- typescript
- underthesea




Log in or sign up for Devpost to join the conversation.