-
-
Rice x Salinity
Inspiration
The crops that smallholder farmers in the world's most food-insecure regions depend on — sorghum, millet, cowpea, cassava — are the ones agricultural science has invested in least. The major commercial crops get the research dollars; the staples feeding the Sahel, the Horn of Africa, and South Asia's drylands get a fraction of the attention, even as the droughts and saline soils they face intensify. Engineering these crops to survive stress means finding the right protein to edit — but a researcher faces thousands of candidate proteins, has to check whether each has a reliable 3D structure, and must read scattered, inconsistent literature to judge whether editing it would actually help. That triage is slow and expensive, which is exactly why under-resourced crops stay under-researched.
I built Locus to collapse that triage from weeks into minutes — and to be honest about the strength of the evidence behind every suggestion, so a researcher without a large lab behind them can trust what they're looking at instead of chasing dead ends.
What it does
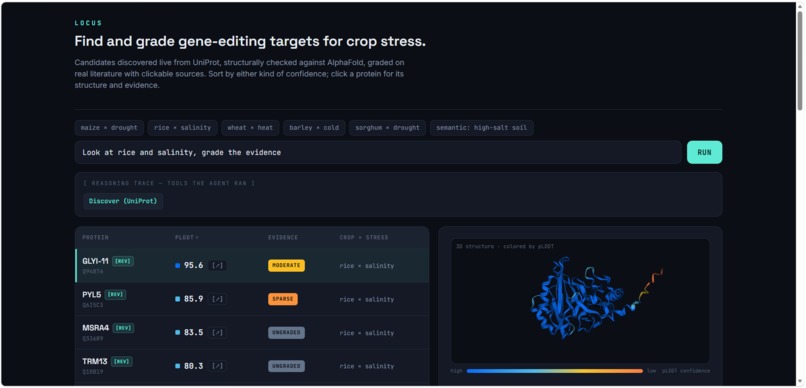
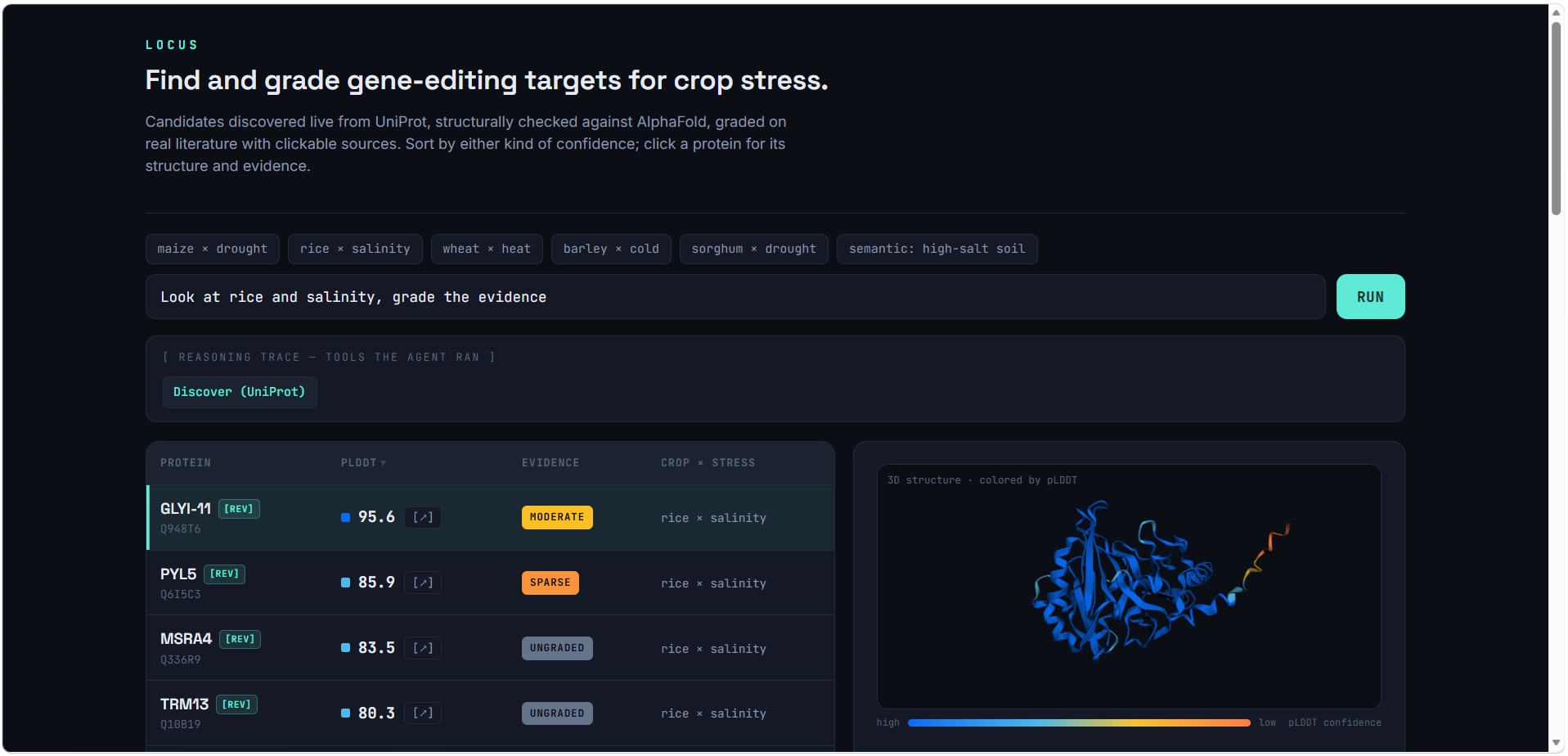
Given a crop and a climate stress (e.g. rice × salinity), Locus:
- Discovers candidate proteins live from UniProt, filtered by the stress's Gene Ontology term and ranked by curation quality.
- Checks structure by pulling each protein's AlphaFold model and reporting its pLDDT confidence, shown as an interactive 3D structure colored by per-residue reliability.
- Grades the evidence by searching the real literature (Europe PMC) and using Gemini to tag each paper by evidence type — causal, mechanism, homolog, correlation, review — and, critically, flagging papers that don't actually study the protein as IRRELEVANT rather than counting them.
- Ranks candidates in a sortable dashboard, by structural confidence or evidence strength, with every citation clickable for verification.
The defining feature is honesty. A protein that's well-folded but unstudied is graded UNGRADED and labeled an open target — not dressed up as a sure thing. The agent shows its work and won't be fooled by topically-adjacent literature.
How I built it
- Gemini 2.5 Flash on Vertex AI for agent reasoning and structured evidence grading. (Gemini 3 was not available in my project region; 2.5 Flash handled grading and tool orchestration well.)
- Google Agent Development Kit (ADK) for the agent and its six purpose-built tools.
- MongoDB Atlas as the agent's growing research memory: discovered proteins are stored as rich documents, embedded with Vertex AI embeddings, and made searchable by meaning via Atlas Vector Search — so a conceptual query like "proteins for surviving high-salt soil" surfaces the right candidates without keyword matches.
- MongoDB's MCP server, integrated over Streamable HTTP, gives the agent native access to query the research database directly — listing collections, counting and filtering documents in natural language — complementing the purpose-built research tools.
- AlphaFold and UniProt public APIs for structure and discovery; Europe PMC for literature.
- A FastAPI backend serving a two-panel dashboard with a 3Dmol.js structure viewer, deployed on Cloud Run.
Challenges I ran into
Integrating MongoDB's MCP server on Windows was the hardest part — the default stdio transport hit a broken-pipe bug in the async subprocess layer. I solved it by running the MCP server as a standalone HTTP service and connecting the agent over Streamable HTTP, which sidestepped the platform issue entirely.
Grading also taught me to make the agent conservative. Early versions over-credited tangential papers, so I built explicit evidence-type tagging and an IRRELEVANT flag — turning "looks supported" into "is actually supported."
Accomplishments that I'm proud of
An agent that grades its own confidence on two independent axes — structural and evidential — and is honest when the evidence isn't there. The IRRELEVANT-tagging behavior, where it reads six on-topic papers and correctly discounts all of them, is the thing I'm proudest of: it's the difference between a tool a scientist can trust and one they can't.
What I learned
Building zero-to-working across Google Cloud, ADK, and MongoDB Atlas in a single sprint; that honest "I don't know" answers are a feature, not a gap; and that real agentic value comes from chaining real data sources with judgment, not from a single clever prompt.
What's next for Locus
Field-trial validation flags, deeper modifiable-vs-conserved region analysis for editing strategy, and growing the research corpus so vector search discriminates across a larger protein space.
Built With
- 3dmol.js
- alphafold
- atlas-vector-search
- europe-pmc
- fastapi
- gemini
- google-adk
- google-cloud
- mcp
- mongodb
- mongodb-atlas
- python
- uniprot
- vertex-ai

Log in or sign up for Devpost to join the conversation.