-
-

Locle Official Logo
-

Vision-Language Model Experimentation (1)
-
Vision-Language Model Experimentation (2)
-
Vision-Language Model Experimentation (3)
-
Login Page
-
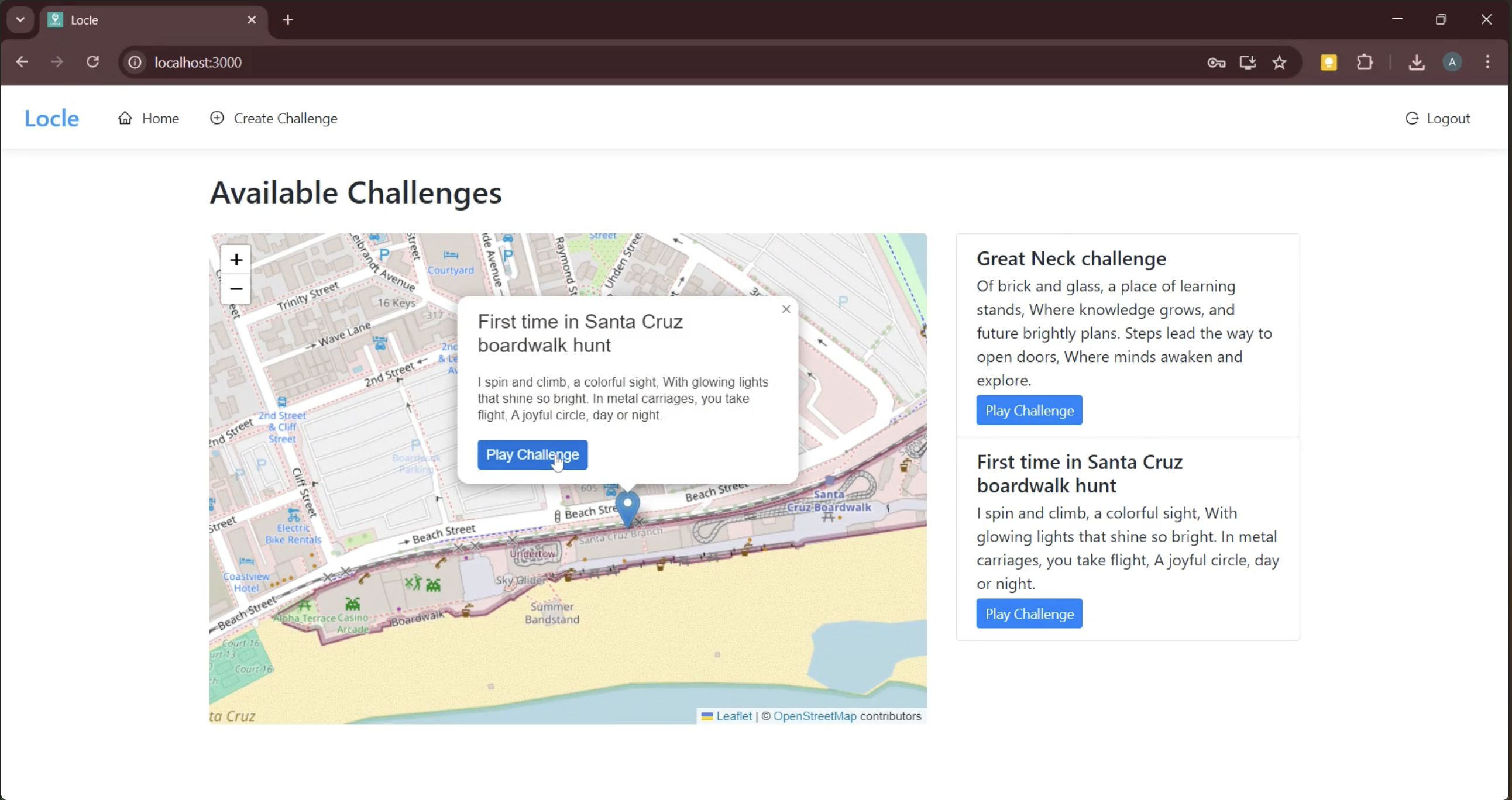
Available Challenges
-
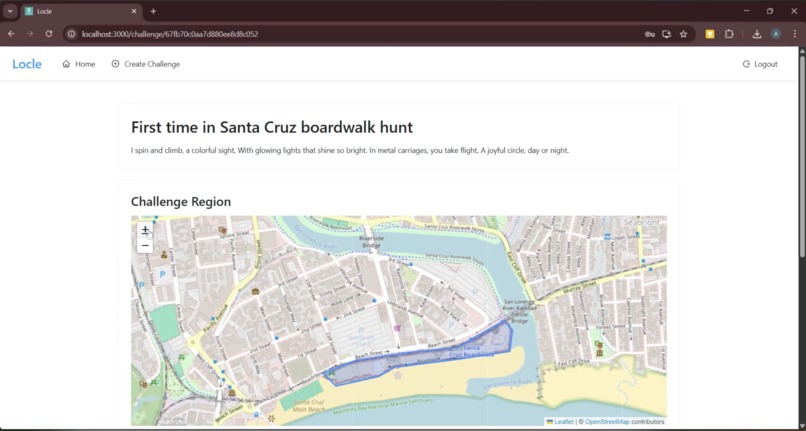
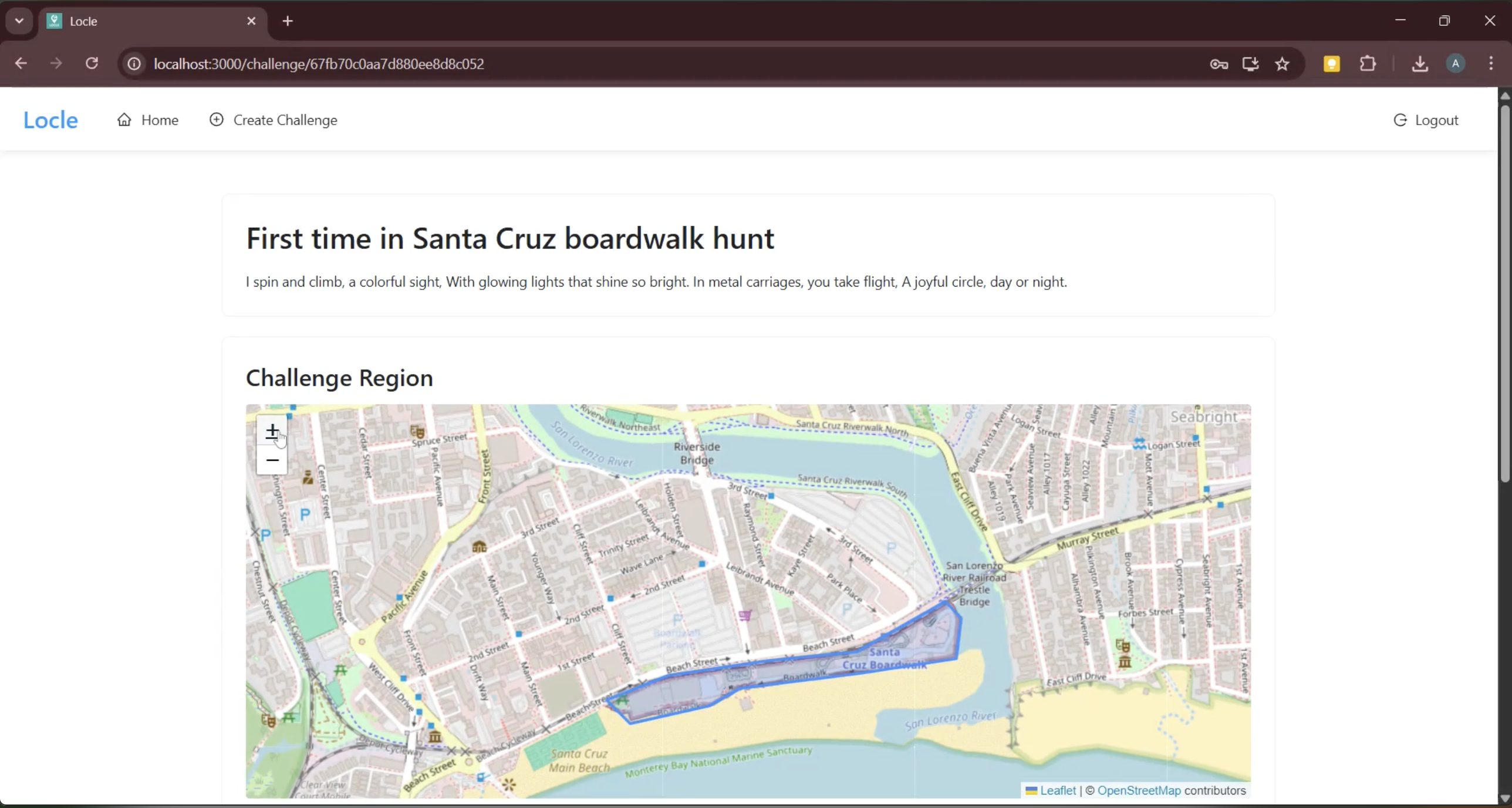
Challenge Region / Initial Riddle
-
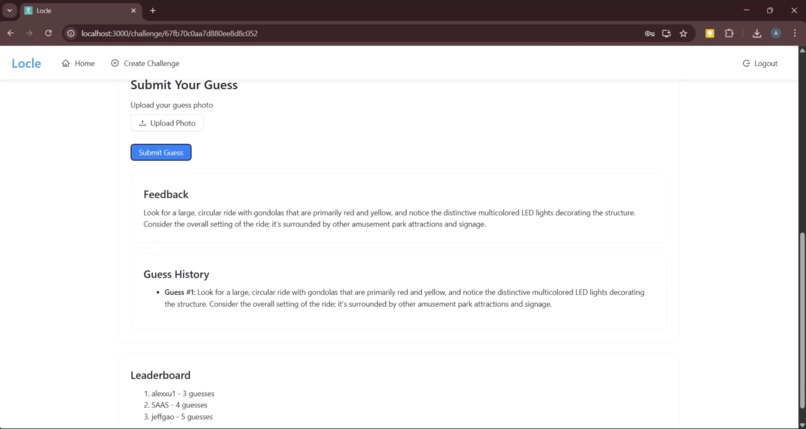
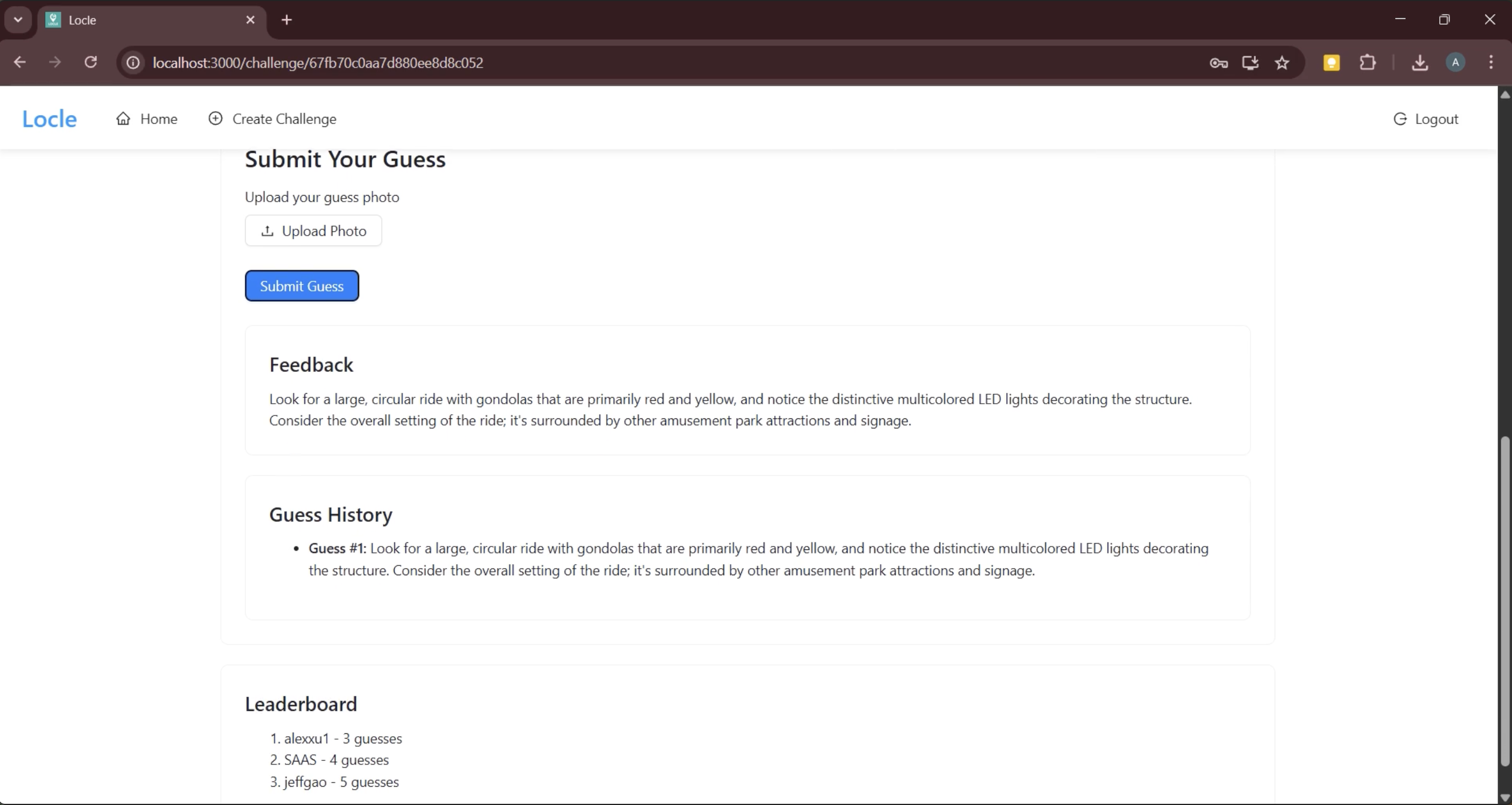
Guess Submission / Feedback / Scoreboard
-
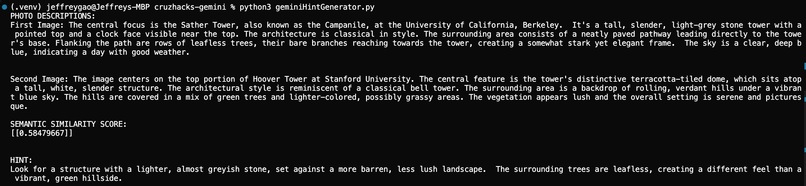
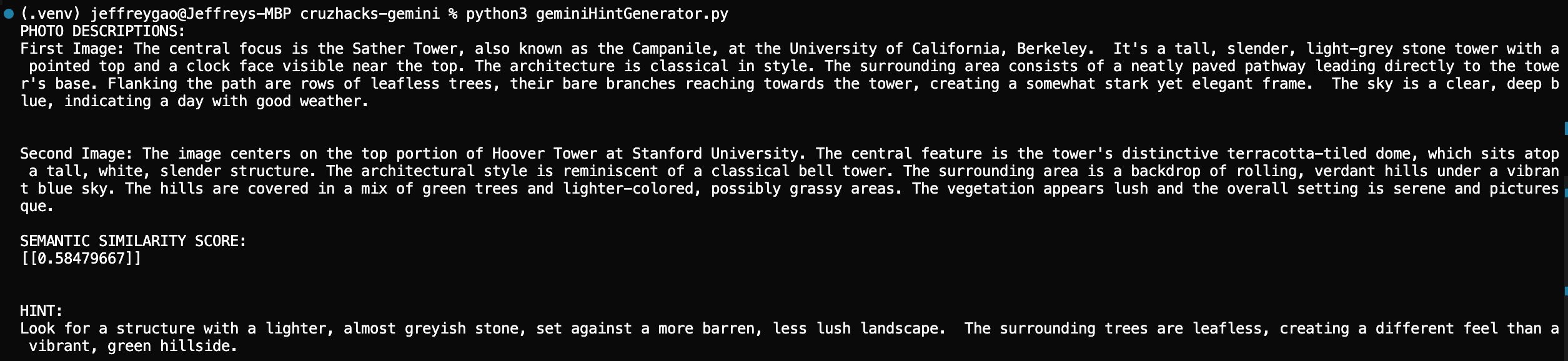
Gemini API Sample Call - Captioning, Similarity, Hint Generation



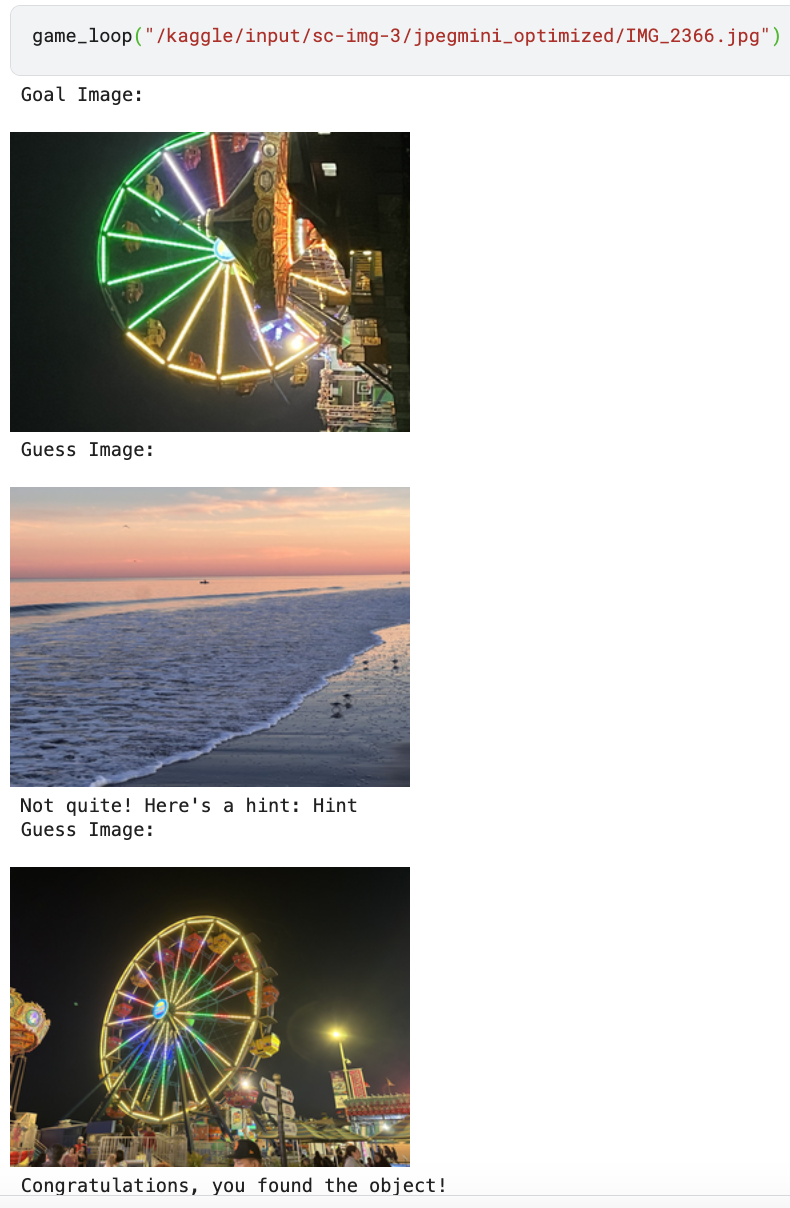
Inspiration
As college students, we’re always looking for ways to turn everyday moments into something more fun. Between classes, clubs, and meetings, we crave quick, meaningful ways to play, compete, and connect with friends and others. We love playing micro-challenges such as Semantle, New York Times’ Wordle, and LinkedIn’s Queens; they provide cognitive refreshment and a sense of accomplishment in the middle of a busy day. But while these games are fun, they're often screen-locked and can be done from the comfort of your room. We wanted to build something that makes the great outdoors feel just a little more playful — a game that embodies exploration, curiosity, and creativity. While absorbing the natural beauty of Santa Cruz at SeaBright beach on Friday, our team of Berkeley CS undergraduates devised the perfect way to combine these themes for our CruzHacks project.
Introduction
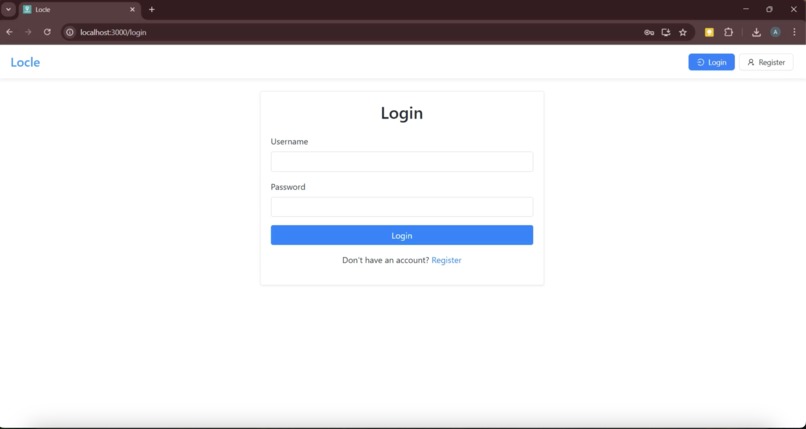
Our app Locle (a play on “location riddle”) is a multiplayer puzzle game centered around capturing photos of real-world places, objects, and landmarks. One user can initiate a “challenge” by taking a photo of a selected “goal” object (in secret) and uploading it to Locle. It is then the goal of other players in the nearby geographic area (from a house to a park to a college campus) to guess what the goal object is and take their own photo of it. Provided with an initial guiding riddle, players can then capture and submit “guess” photos. If incorrect, they will receive LLM-powered hints that lead them towards the goal object. Which users can use their deduction skills and geographic knowledge to find the goal object as quick as possible?
Technical Challenge: Visual Understanding
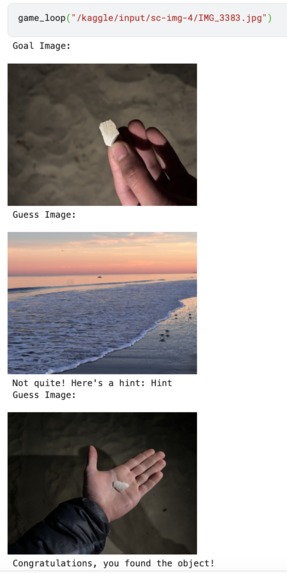
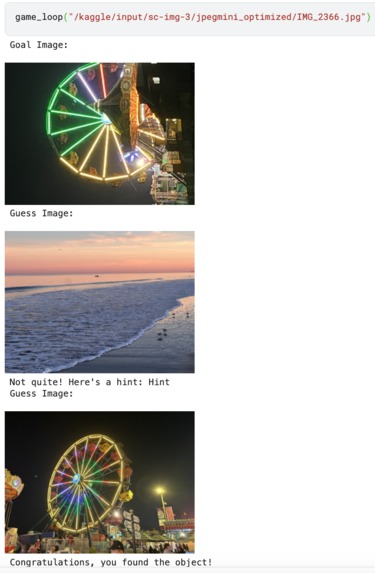
After the initial wave of excitement our group experienced after brainstorming this idea, we were greeted with an immense technical challenge: how can we get our software to determine if an object in the user’s photo matches the “goal”, or if it is just a photo of something similar looking? This problem requires the computer to have an understanding of the image beyond just the raw pixel values: it needs to understand the semantic contents of the photo as well. Our background in computer vision inspired us to research vision-language transformers that have been designed for this very purpose. We started testing OpenAI’s CLIP (Contrastive Language-Image Pre-training) model, but found the accuracy underwhelming. More research revealed that combining contrastive models like CLIP with generative AI models can increase robustness. Experimentation confirmed this result, and led us to use an ensemble of CLIP and Gemini’s 1.5 Flash LLM for the image classification model in our final version. Our system embeds the goal image and the guess image in a high-dimensional vector space, and then combines cosine similarity and Gemini’s text descriptions to decide if they contain the same object – keeping our game consistent and challenging!
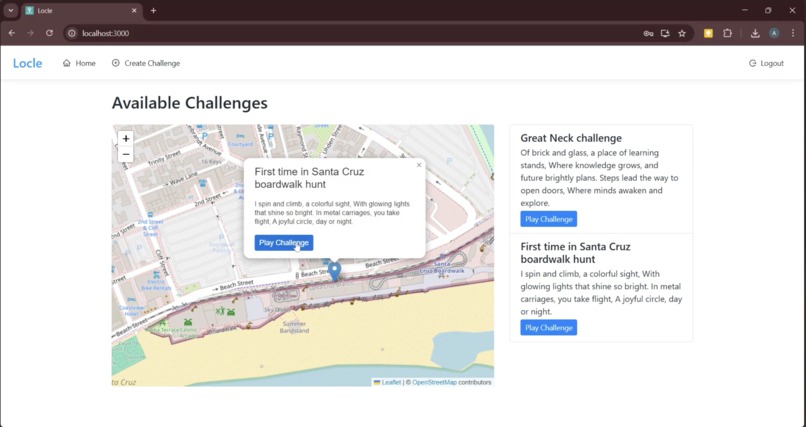
Map-Based Challenges
Besides technical hurdles, we also worked hard to make our game as engaging as possible. With our goal of promoting outdoor exploration (and the physical and mental health benefits that accompany it) in mind, we reflected on an app that accomplished this aim better than any game in history: Pokemon Go. Specifically, we wanted a way to include a map interface in our software that links real-world locations to important locations in the game, just like Pokemon Go did with “Gyms” placed at park-like locations. We decided to allow users to select a geographic region or boundary when they take their goal photo - that is, guessers will know that the object is somewhere in this area, and the area will be highlighted on the map so people can seek out local challenges. On the implementation side, we faced various computational and stylistic challenges trying to implement this feature. Leveraging the Leafly library, we modified our backend to record the coordinates of every uploaded photo in our MongoDB database. Visualizing on our front end, we realized an obvious gameplay flaw: the boundaries we were drawing to enclose the user’s selected area were centered on the location where they uploaded the photo, so any guesser could find the object just by walking towards the middle! Patching was simple: just place the polygon in a random (non-centered) zone encompassing the goal object, but the situation demonstrated the benefit of thinking in your target audience’s shoes as a developer.
Conclusion and Next Steps
Overall, our hackathon started as an ocean of disjoint, beach-related ideas that we channelled into a project that we believe embodies our own passions as well as the unique spirit of CruzHacks. In the future, we hope to launch Locle into full production; we envision improving the accuracy of our image models, efficiency of our backend, and enjoyability of our features until we see college students from across the country snapping odd photos.
Built With
- 4o
- axios
- clip
- cursor
- flask
- gemini
- huggingface
- javascript
- kaggle
- leaflet.js
- mongodb
- nominatim
- numpy
- openai
- pillow
- python
- pytorch
- react
- vscode



Log in or sign up for Devpost to join the conversation.