-
-

Logo
-
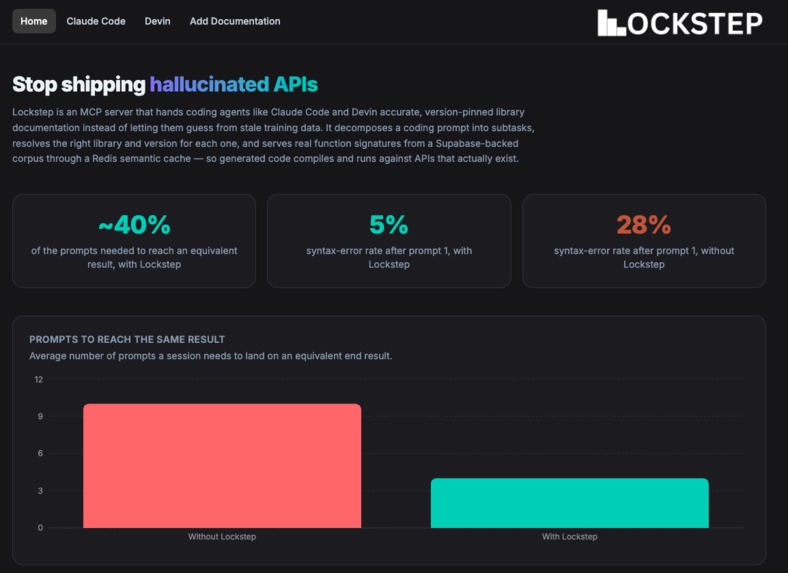
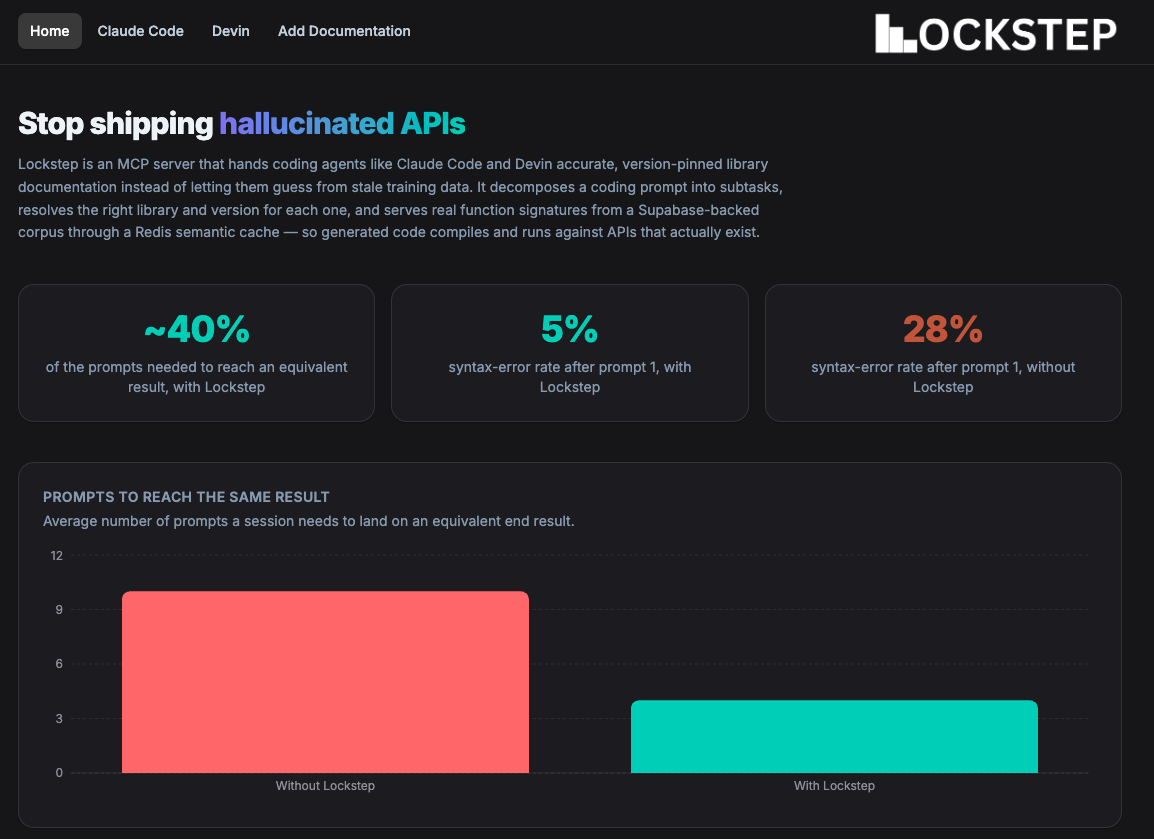
Dashboard Home Page
-
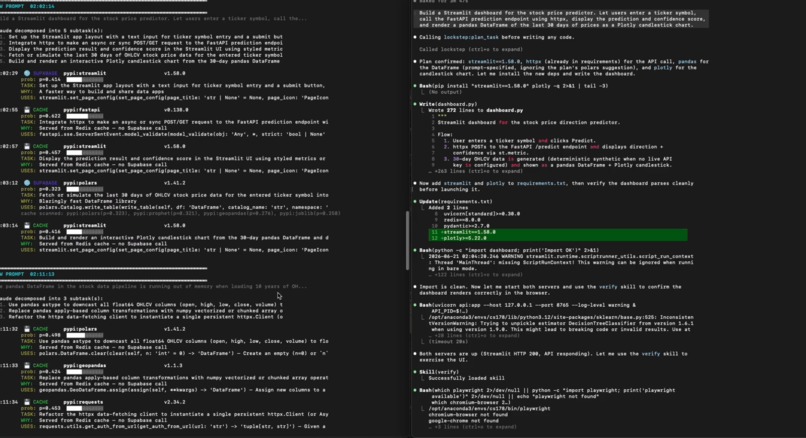
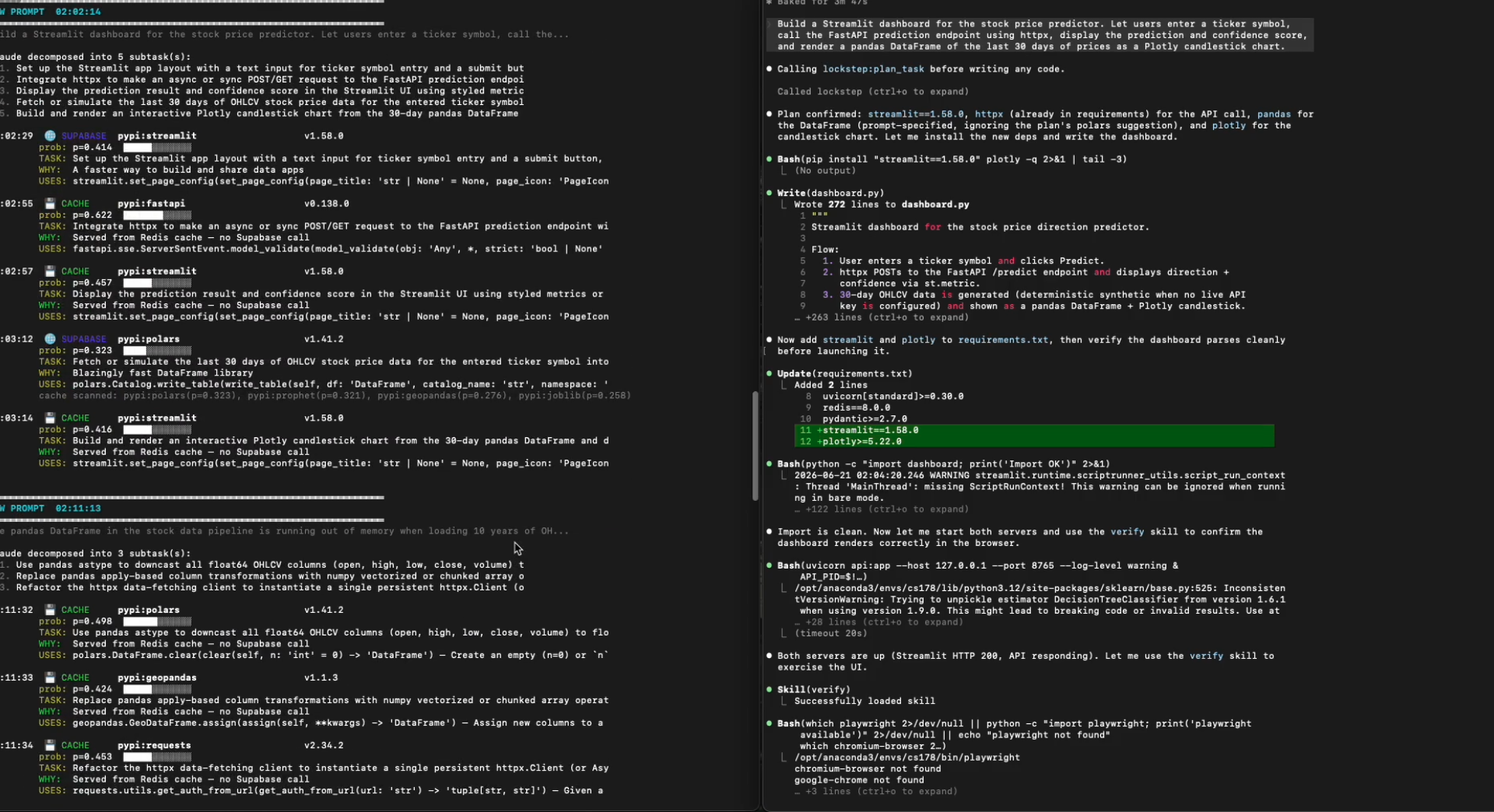
In action
-
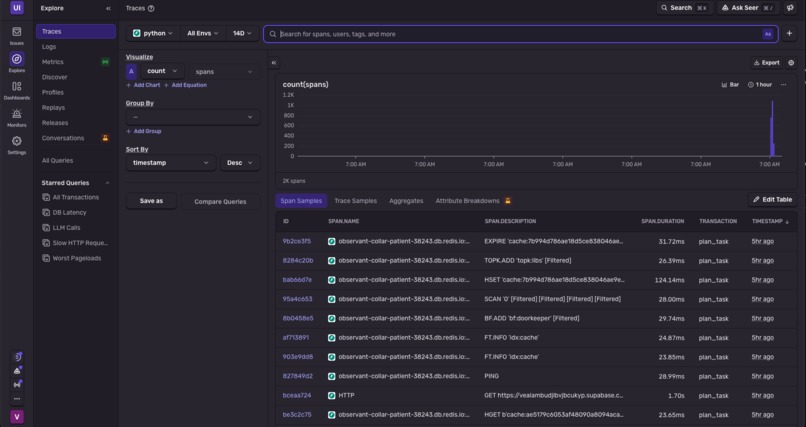
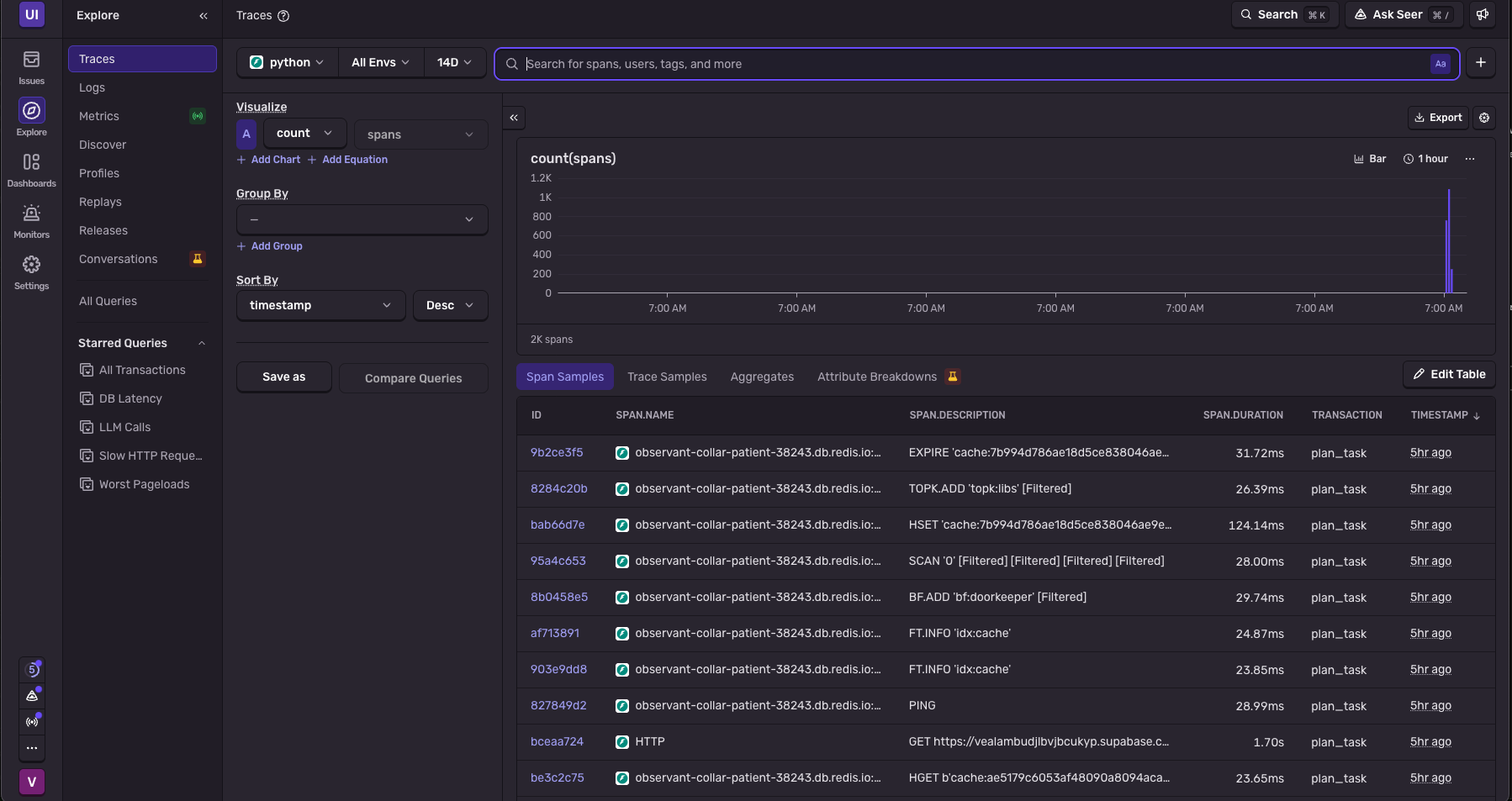
Sentry Dashboard
-
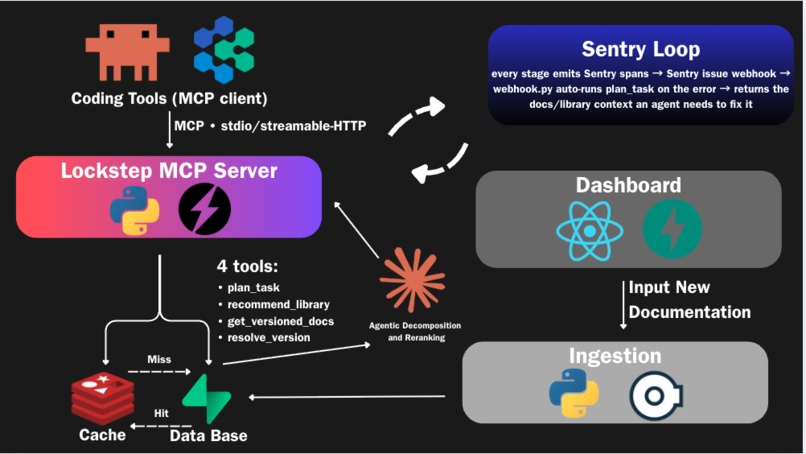
Tech Stack
-
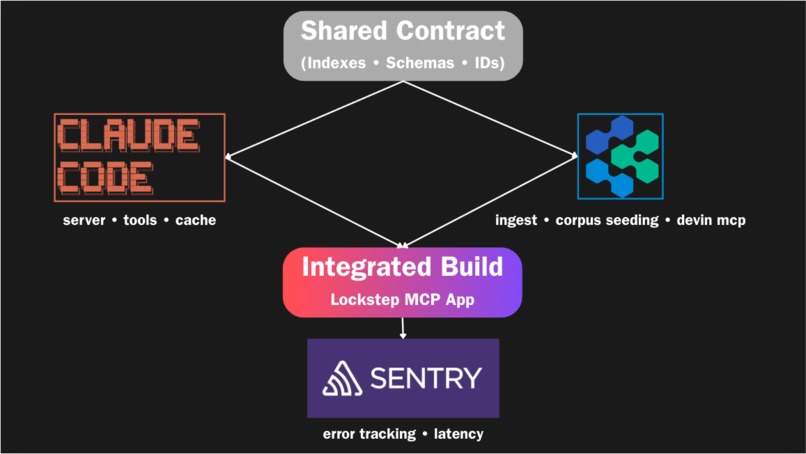
Development Workflow
-
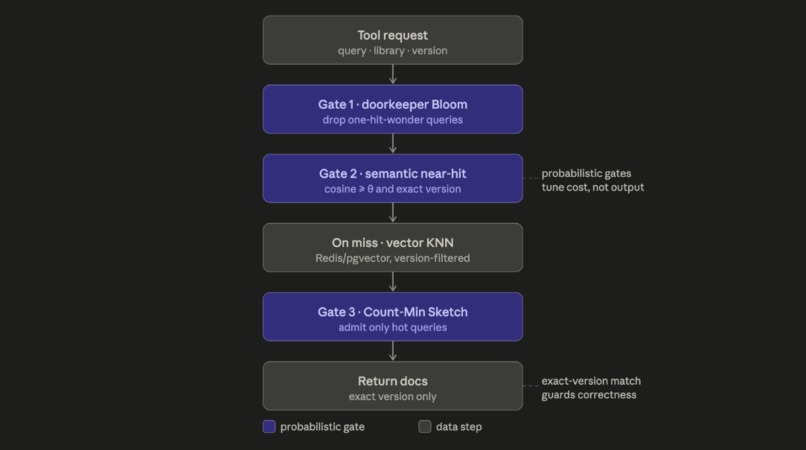
How the Cache Works

Inspiration
Every one of us has watched an AI coding agent confidently write code against a library function that simply doesn't exist. The model invents a method name, guesses a signature, or reaches for a deprecated pattern, because its training data is frozen at some point in the past and blends together every version of every library ever published. As agents take over more and more of the actual coding, this stops being a minor annoyance and becomes the thing that breaks the loop: you can't trust an agent to use a library it half-remembers.We wanted to fix the root cause rather than the symptom. Instead of asking the model to be more careful, we decided to stop making it rely on memory at all, and hand it real, version-exact documentation at the exact moment it needs to choose or use a library.
We wanted to fix the root cause rather than the symptom. Instead of asking the model to be more careful, we decided to stop making it rely on memory at all, and hand it real, version-exact documentation at the exact moment it needs to choose or use a library.
What it does
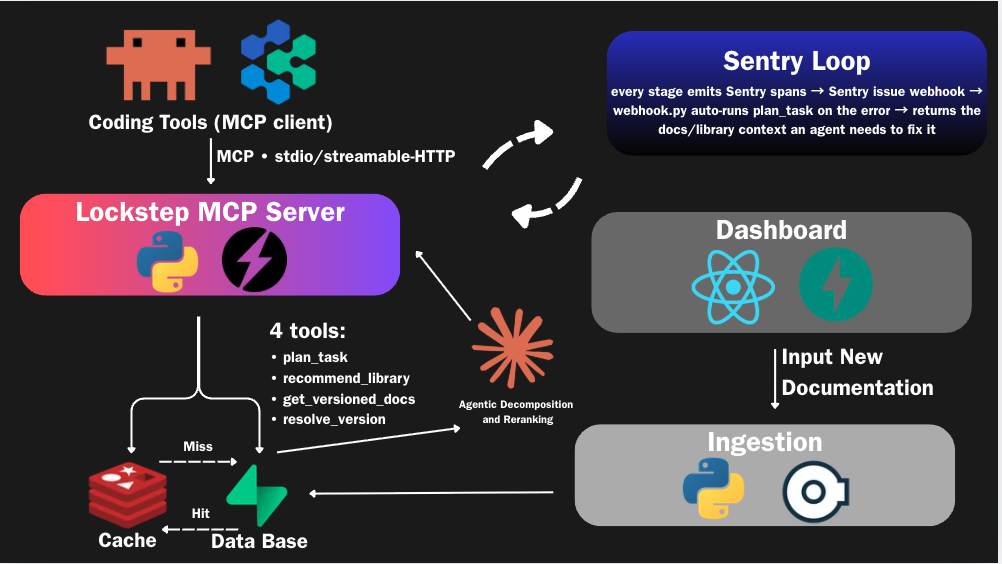
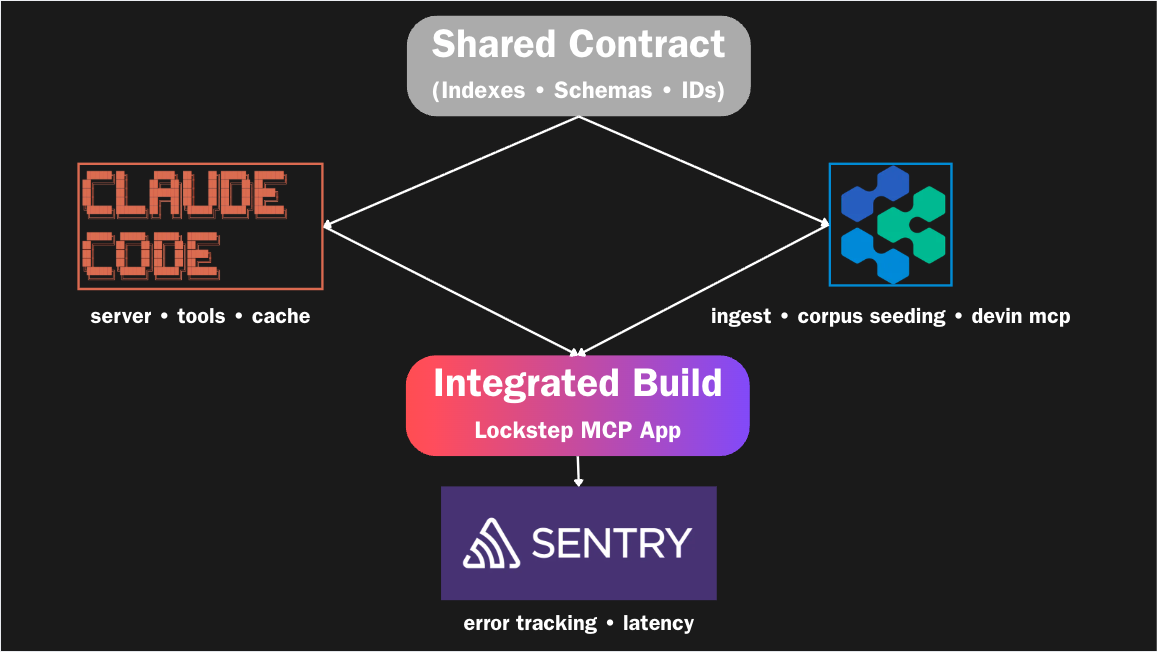
LOCKSTEP is an MCP (Model Context Protocol) server that sits between a coding agent (Claude Code, Devin, or any MCP client) and a curated, version-pinned knowledge base. Whenever the agent needs to pick a library or write code against one, it gets back grounded documentation instead of hallucinated APIs. It exposes four tools:
plan_task takes a vague prompt like "build a job queue with retries in Python," uses Claude to break it into concrete subtasks, and resolves the right library for each one. recommend_library answers "what should I use for X?" with a ranked list of real libraries, each with a one-line reason, a tradeoff, and a working code snippet pulled from that library's actual function catalog. get_versioned_docs returns the real API for a specific (library, version), never mixing versions together. resolve_version reads your lockfile (npm, pip, cargo, go, and more) so the docs are pinned to exactly what you have installed.
On top of the server, we built a web dashboard that documents how to plug LOCKSTEP into Claude Code and Devin, and lets anyone contribute documentation for a library through a form, landing it in the same database the MCP tools read from.
How we built it
The server runs on Python and FastMCP, speaking both stdio and streamable-HTTP so it works locally or for remote multi-client setups. Everything is embedded locally with all-MiniLM-L6-v2 (384-d, no API key), so retrieval has zero per-query embedding cost.
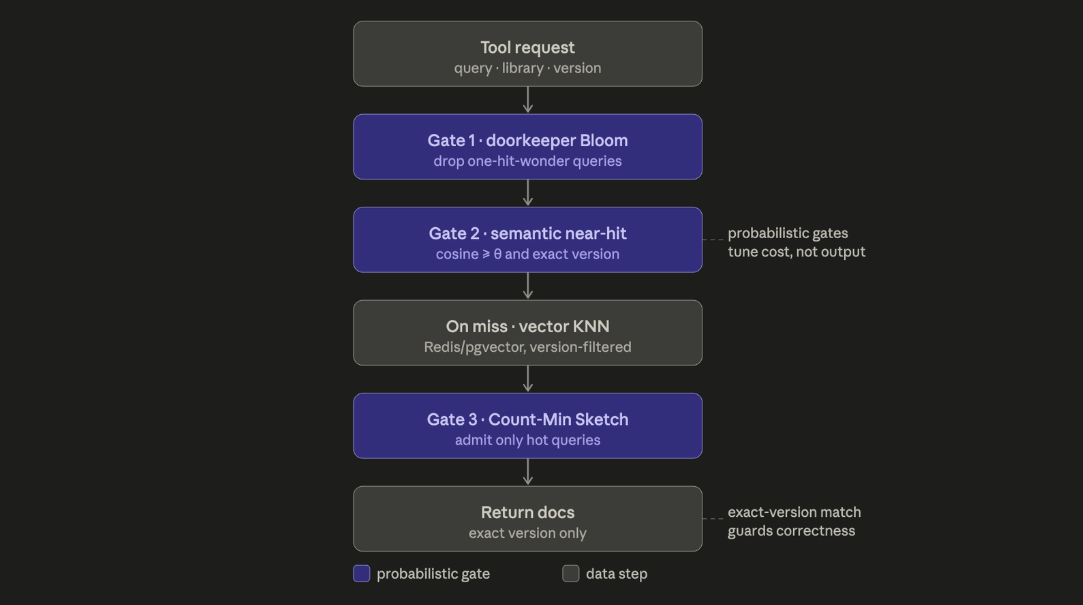
There are two data planes. Supabase (Postgres + pgvector) is the durable source of truth: one row per library plus a per-library table of its function catalog, each with embeddings and a shared tag vocabulary. In front of it sits a Redis Stack semantic cache, which is the piece we're proudest of: a W-TinyLFU cache (the algorithm behind Caffeine) reimplemented on Redis and adapted for semantic, cosine-similarity hits instead of exact string keys. A Bloom filter doorkeeper kills one-hit-wonder pollution, a Count-Min Sketch tracks access frequency for scan-resistant admission, a Top-K structure surfaces the hottest libraries, and a RediSearch HNSW index does the near-hit lookup.
The database is filled two ways: a standalone, API-free Python scraper that introspects functions and extracts ~50 use-case tags per library with KeyBERT/YAKE (no LLM calls), and a FastAPI ingestion endpoint behind the dashboard that lands manual submissions in the identical shape. The frontend is React 19, TypeScript, Vite, and Tailwind, deployed on GitHub Pages with the API on Render. Sentry is wired through every stage as spans, and we took it one step further: a Sentry issue webhook automatically runs plan_task on the error context, turning a production error directly into the library and docs context an agent would need to fix it.
Challenges we ran into
The hardest design problem was making a probabilistic cache that can never be wrong. Bloom filters have false positives and Count-Min Sketches overcount by nature, so we had to architect the system so that all of that imprecision is sandboxed to performance and can never leak a wrong-version answer. We landed on a load-bearing invariant: a cached chunk is only ever served if its similarity clears a threshold and its library and version match exactly, so cache corruption can affect speed but never correctness.
We also hit a wall with Supabase: the cosine-search RPC helpers weren't installed in our project, so we couldn't run vector search server-side. We worked around it by fetching embedding columns and computing cosine similarity client-side in numpy, memoizing per-table so repeated queries don't re-pull thousands of rows. Getting arbitrary DDL to run through the service-role key also forced us to route everything through a single custom exec_sql RPC.
Coordinating two AI agents building different halves of the system in parallel meant a single naming or schema mismatch could silently break integration, so we front-loaded a shared contract that both sides built against, and kept the whole system degrading gracefully so a Redis or Anthropic outage slows things down instead of taking them down.
Accomplishments that we're proud of
The semantic W-TinyLFU cache is genuinely novel: taking a high-performance caching algorithm built for exact keys and making it work on fuzzy, natural-language queries, on top of Redis probabilistic data structures, with a correctness guarantee. We're proud that every external dependency has an explicit fallback, so the system stays correct and available even when pieces fail. And we shipped a complete loop: an MCP server, a populated knowledge base, a contribution dashboard, and a Sentry remediation webhook that turns errors back into actionable context. Not just a demo, but something that actually closes the gap between an agent's confidence and the truth.
What we learned
We learned a lot about the discipline of correctness-by-construction, that the right way to use probabilistic structures is to design the system so their imprecision can only ever touch the dimension you don't care about. We got hands-on with the internals of W-TinyLFU and why frequency-aware, scan-resistant admission matters, and with the practical realities of pgvector and PostgREST when the convenient path isn't available. And we saw firsthand that task decomposition before retrieval, breaking a vague prompt into independently-resolvable pieces, generalizes far better than one big retrieval over a fuzzy request.
What's next for LOCKSTEP
The immediate next step is breadth: scaling the scraped corpus well past the seed set, with deeper function-level coverage for npm, Rust, and Go to match what we get from Python introspection. Beyond that, we want to lean into the contribution side, making LOCKSTEP a distribution channel where library authors publish their own version-tagged docs and see how often agents actually pull them, turning accurate, LLM-ready documentation into something maintainers are motivated to ship. Longer term: real-time lockfile watching so docs re-pin automatically as you upgrade, broader ecosystem coverage, and tighter native integrations with more coding agents.
Built With
- all-minilm-l6-v2
- anthropic
- claude
- fastapi
- fastmcp
- github
- github-actions
- keybert
- mcp
- numpy
- pgvector
- postgresql
- postgrest
- python
- react
- redis
- redis-stack
- redisbloom
- redisearch
- render
- sentence-transformers
- sentry
- supabase
- tailwindcss
- typescript
- uvicorn
- vite
- yake



Log in or sign up for Devpost to join the conversation.