Inspiration
Our team has been shaped by dementia up close—grandparents sliding into cognitive decline, relationships strained not from lack of love but from how memory fails. We watched autonomy and familiarity erode while specialist care stayed expensive and often tied to clinical settings that remove patients from the homes and objects that still trigger emotional recall.
Research-backed approaches gave us a north star: reminiscence therapy (reactivating emotional memory through familiar people, places, and moments) and memory palaces (binding memories to specific locations and objects so recall feels spatial instead of effortful). Loci is our attempt to turn those ideas into something families can actually use every day, on hardware they already own.
What it does
Loci is an offline-first Android app for Alzheimer’s and dementia support:
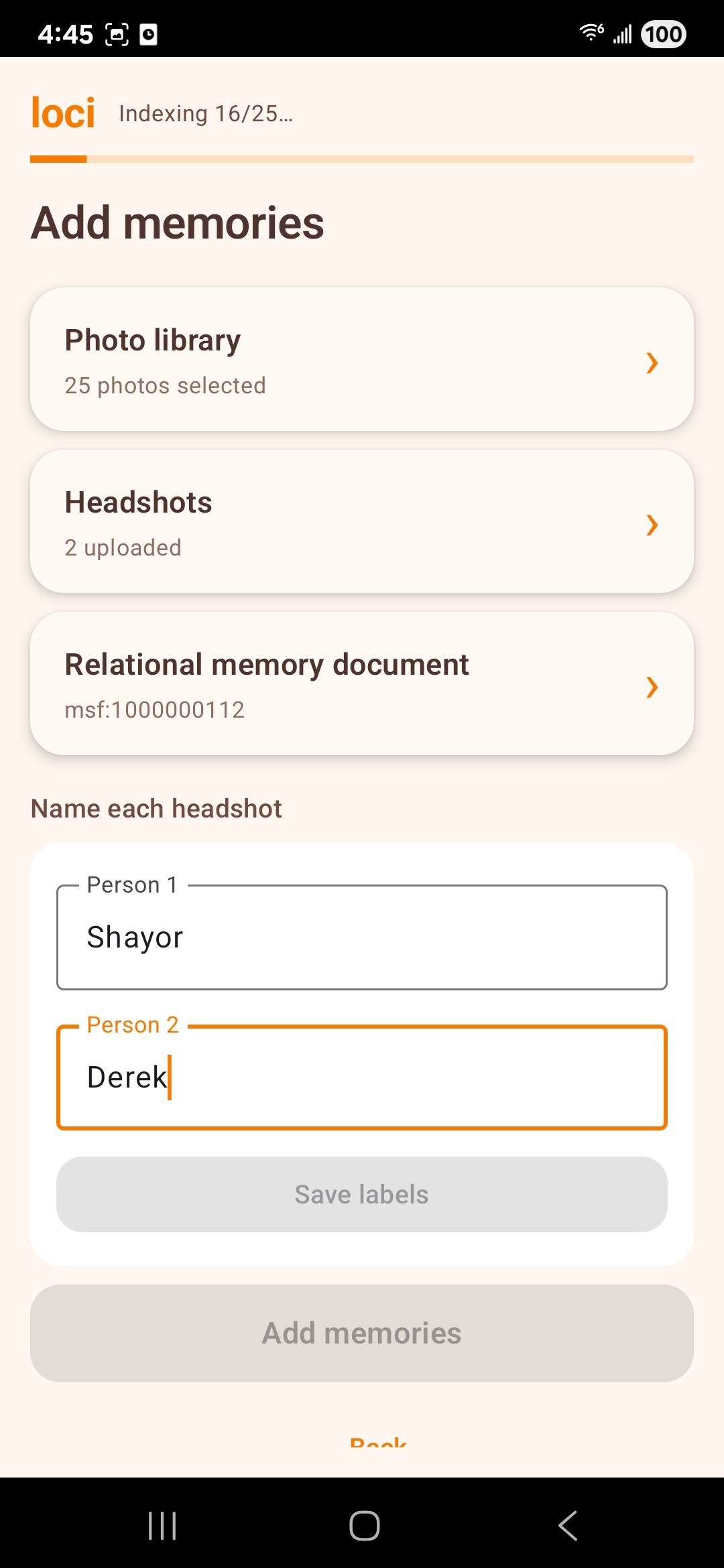
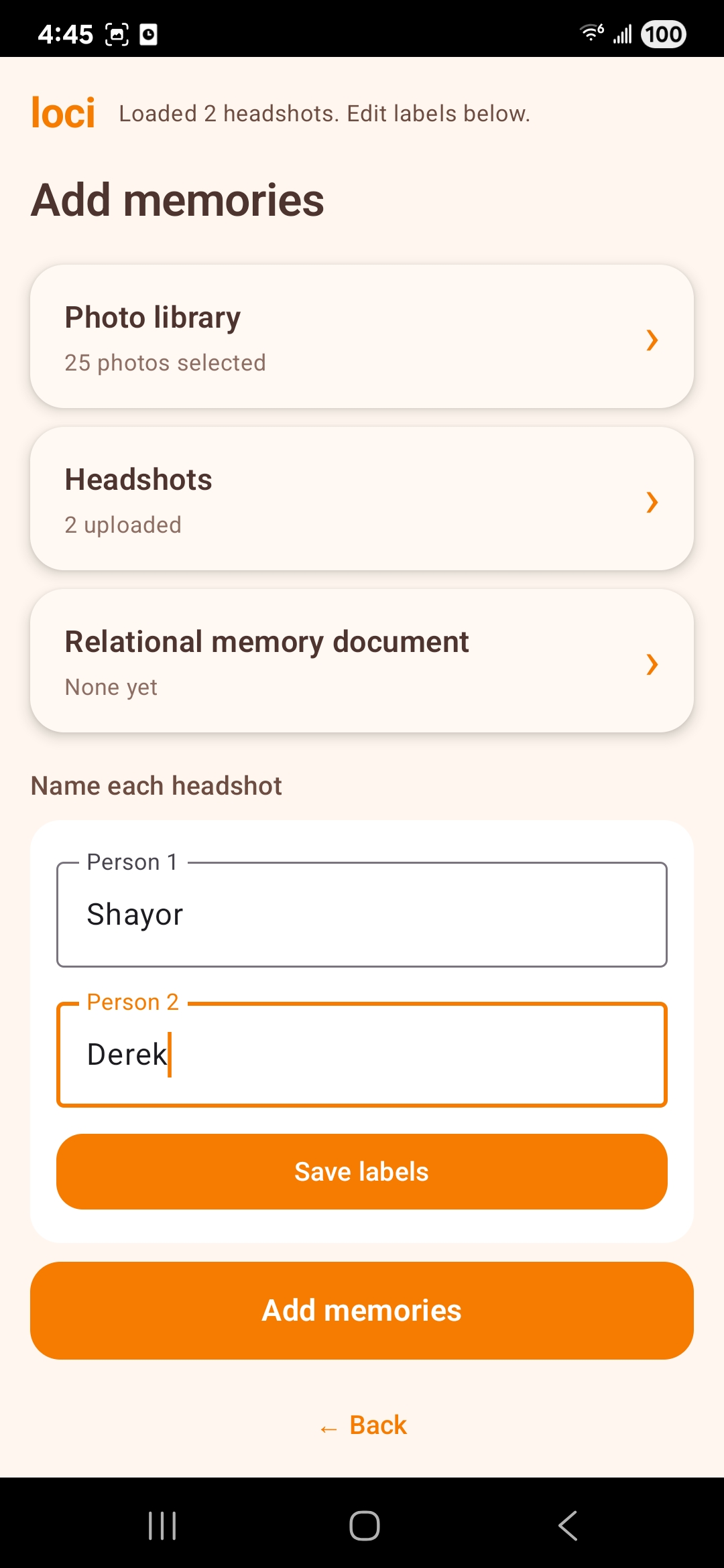
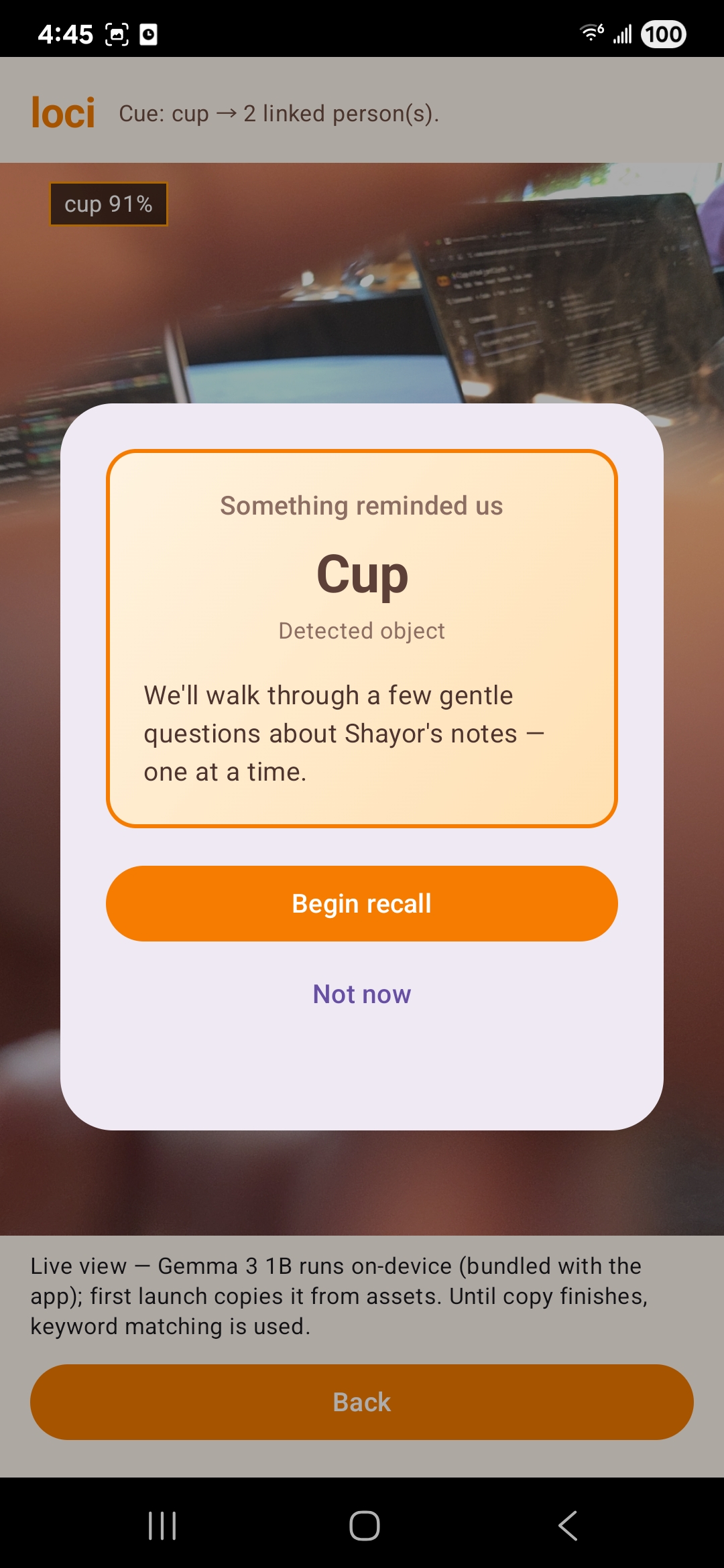
Caretakers create patient profiles and memory cards (titles, stories, optional images/audio, tags), then attach those memories to real-world objects using the camera and AR anchors—so “grandpa’s chair” or “the bottle on the counter” becomes a doorway into a curated narrative.
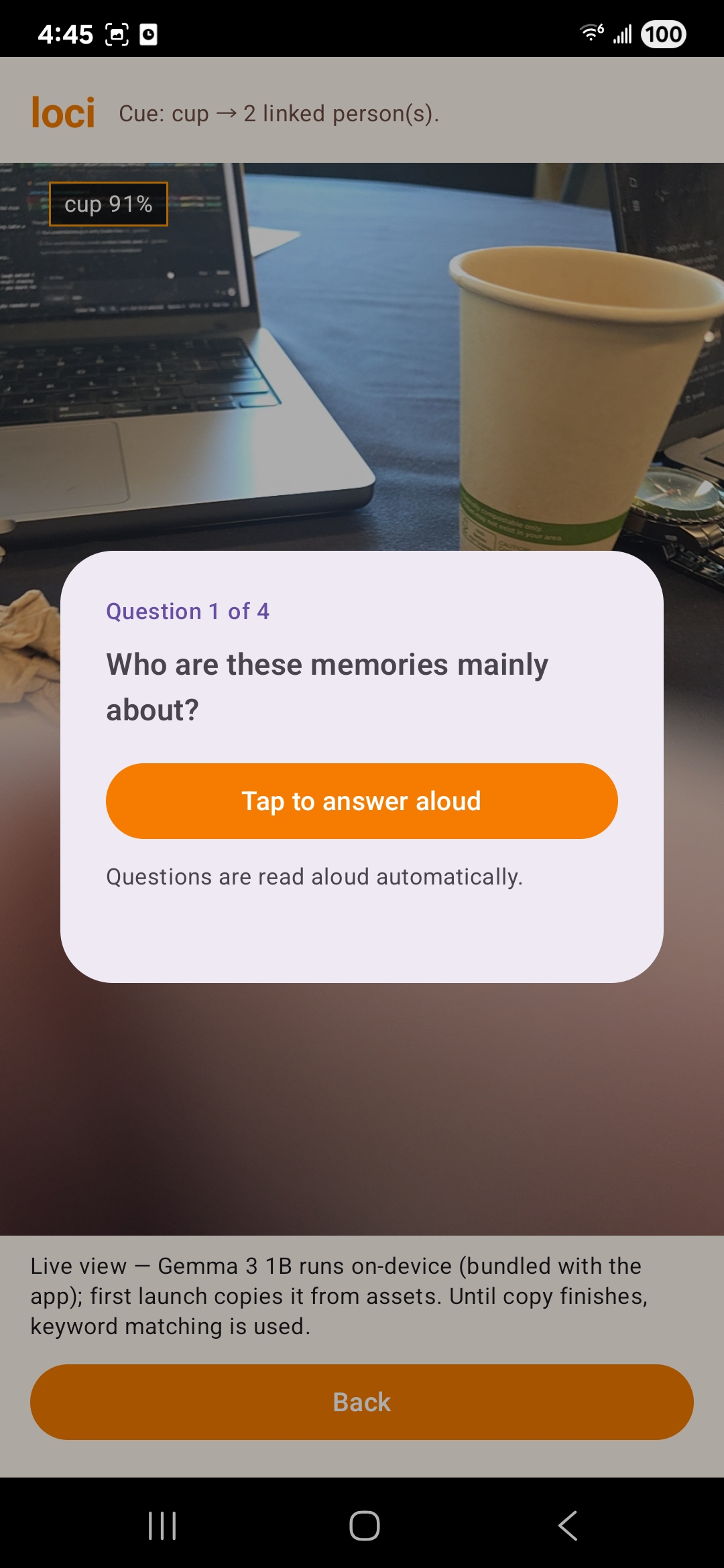
Patients point the phone around the home; on-device object detection (with secondary classification when labels are ambiguous) identifies what’s in view. The app matches that signal to stored anchors using label agreement and 3D proximity, then plays back the linked memory sequence.
A conversational layer supports gentle Q&A-style recall sessions, with paths that ground answers in caretaker-authored text where possible, optional cloud-assisted parsing when configured, and on-device LLM (e.g. bundled Gemma-style model via MediaPipe) when families want privacy without sacrificing dialogue.
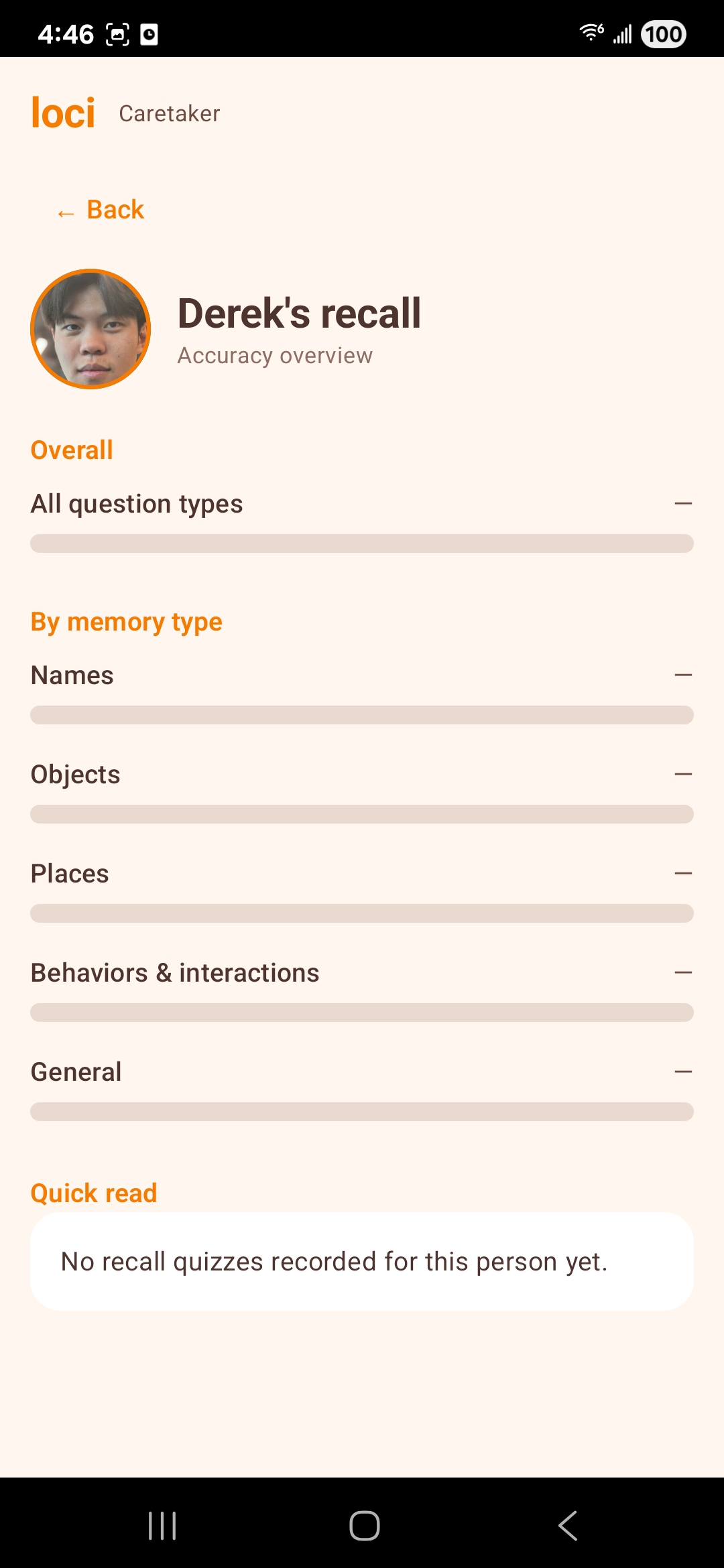
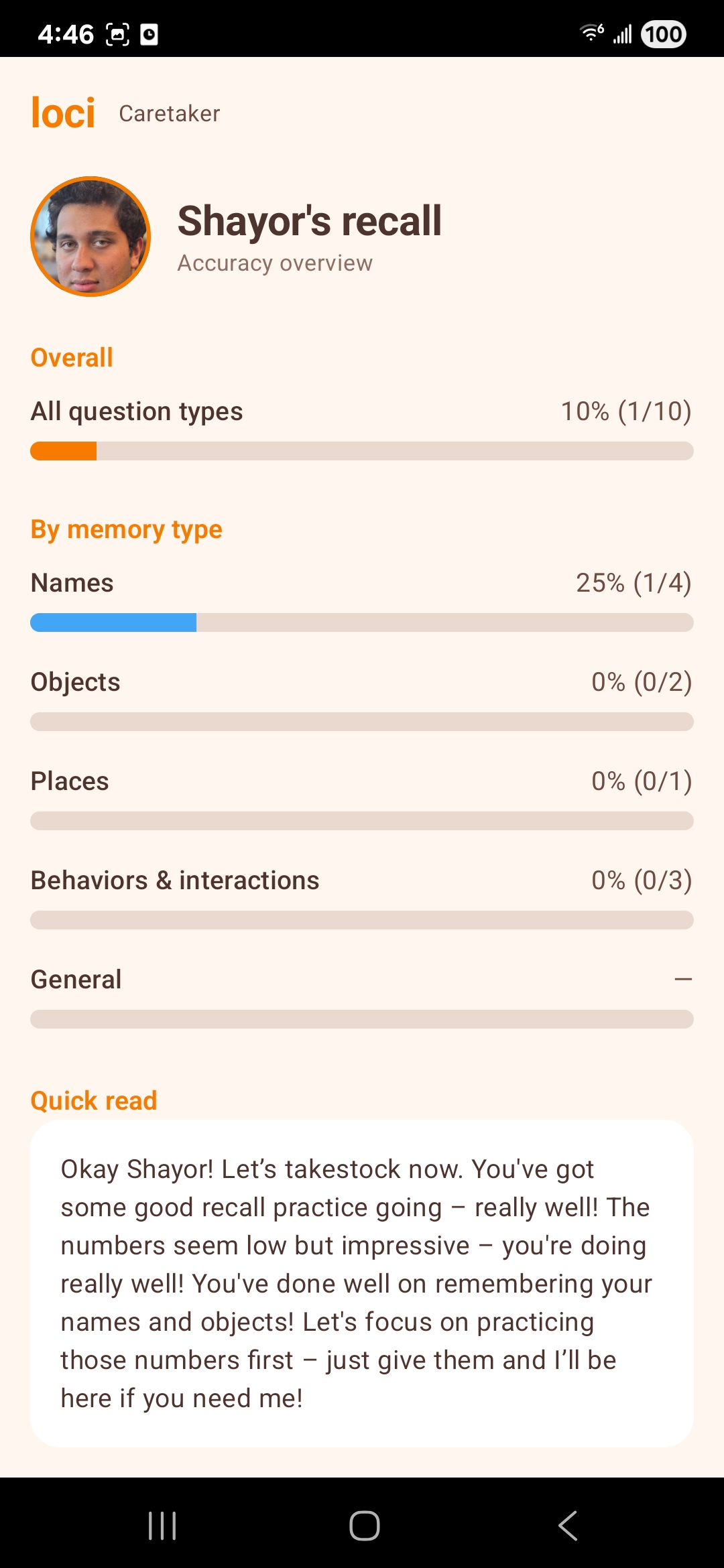
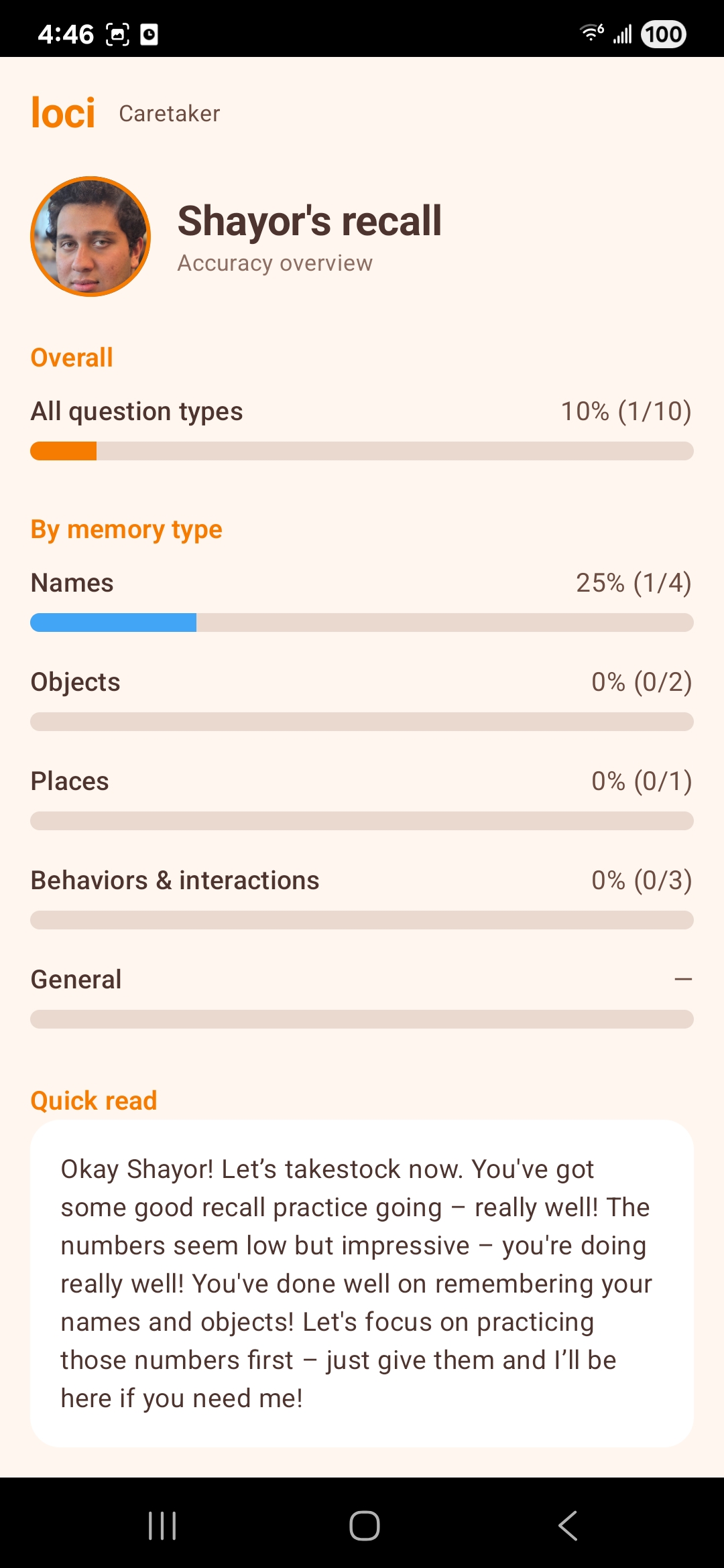
Session logs capture meaningful interactions (e.g. anchor matches) so caretakers can review patterns over time—not as a diagnostic substitute, but as a practical window into engagement.
How we built it
Architecture (multi-module Gradle):
app — Navigation, accessibility, camera orchestration, patient/caretaker flows, integrations (TTS, optional LLM, optional API-assisted matching). core-camera — Frame pipeline / throttling so inference stays responsive. core-ar — ARCore-backed anchor and pose access. ml-detection — Primary LiteRT / TFLite object detection (EfficientDet-style asset pipeline). ml-classification — Secondary LiteRT CompiledModel image classification (EfficientNet Lite) for disambiguation. memory-domain — Domain models (Patient, MemoryItem, ObjectAnchor, ObjectMemoryLink, SessionLog), smoothing (DetectionSmoother), spatial matching (AnchorMatcher), sequencing. data-local — Room database, DAOs, encrypted-media-oriented persistence. data-remote — Sync/API boundary (mock/TODO for production auth and consent). feature-caretaker / feature-patient — Separated UX flows for authoring vs live scanning and playback. Perception pipeline: Throttled frames → detection → optional refinement → temporal smoothing → match anchors by label + distance to stored pose → ordered memory playback → logging.
Embeddings (where relevant): Lightweight visual signatures (e.g. face/patch-oriented embeddings) complement the relational graph for similarity-style retrieval across noisy camera input—not a replacement for caretaker-authored truth.
Challenges we ran into
Toolchain vs ML stacks: Kotlin 2.2 and KSP2 were necessary for some LiteRT Kotlin metadata, but exposed rough edges—e.g. Room + KSP (unexpected jvm signature V) until moving to a newer Room line and tightening DAO signatures.
Duplicate classes on the classpath: LiteRT ships overlapping org.tensorflow.lite.* types with standalone tensorflow-lite artifacts; we had to consolidate on LiteRT and exclude conflicting Maven modules so checkDebugDuplicateClasses could pass.
Android SDK / Compose alignment: Newer Compose, Lifecycle, and Core artifacts demanded compileSdk 35 and AGP ≥ 8.6; the project needed a coordinated bump across modules—not just the app module.
Product/engineering tension: Making LLM-assisted flows safe meant investing in lexical grounding and sanitization so model output couldn’t invent labels that never appeared in family-provided context.
On-device LLM size & UX: Bundling a ~500MB+ Gemma-class model implies first-run copy, licensing/token flows for CI/dev machines, and honest messaging when the model isn’t present yet.
Accomplishments that we're proud of
A coherent end-to-end MVP: caretaker-authored memories → AR-anchored objects → patient live matching → sequenced playback + logging.
Privacy-aware defaults: local Room persistence, encrypted-media hooks, and on-device vision so core reminiscence doesn’t depend on shipping frames to the cloud.
Pragmatic perception: two-stage detection + classification and temporal smoothing reflect real-world camera noise, not demo-perfect conditions.
Grounded conversational design: emphasis on caretaker text as source of truth, with LLM paths treated as assistive, not authoritative.
Shipping through real Android build pain: resolving AGP/SDK, LiteRT vs TensorFlow Lite duplication, and Room/KSP2 interoperability—so teammates can actually assembleDebug and iterate.
What we learned
Therapy metaphors need engineering discipline: “Memory palace” only helps if anchors are stable, matching is conservative, and false positives don’t gaslight patients with wrong stories.
On-device ML is a packaging problem as much as a model problem: classpath conflicts, SDK floors, and asset size directly determine whether a humane idea survives contact with Gradle.
Hybrid cognition wins: relational graphs for narrative integrity plus embeddings for fuzzy visual similarity is more robust than pretending one representation solves everything.
Families need honesty: we should be clear where the product is clinical adjacency versus wellbeing tooling, and design logs as support for carers, not silent surveillance.
What's next for Loci
Harden patient runtime: Fully wire PatientRuntimeOrchestrator (and related UI paths) to real bitmap/frame conversion from CameraX where TODOs remain, end-to-end tested on diverse ARCore devices.
Caretaker analytics: Expand session logs into caregiver-readable summaries (frequency of matches, skipped prompts, time-on-task) with export and privacy controls.
Controlled sync: Implement data-remote with real auth, encryption in transit, and explicit consent flows—default-off until families opt in.
Evaluation: Structured pilots with occupational therapists or geriatric clinicians to validate task difficulty, cognitive load, and safety of conversational prompts.
Accessibility: Deep pass on large text, high contrast, motor-friendly controls, and audio-first modes for patients with vision or dexterity limits.
Model lifecycle: Smaller/faster variants, optional GPU/NPU backends where stable, and clearer fallback UX when heavy LLM assets aren’t installed.
Built With
- litert






Log in or sign up for Devpost to join the conversation.