-
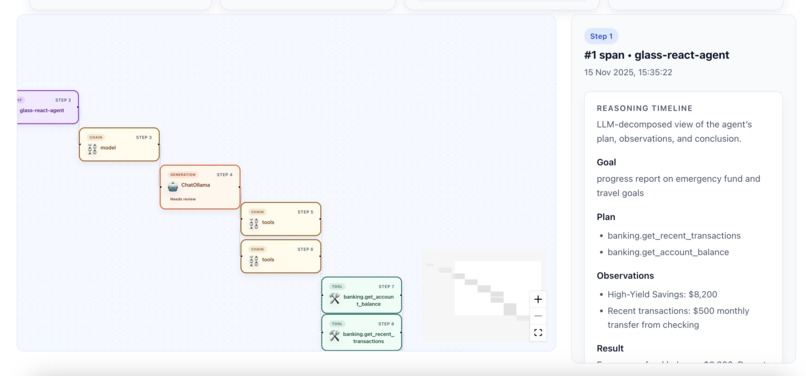
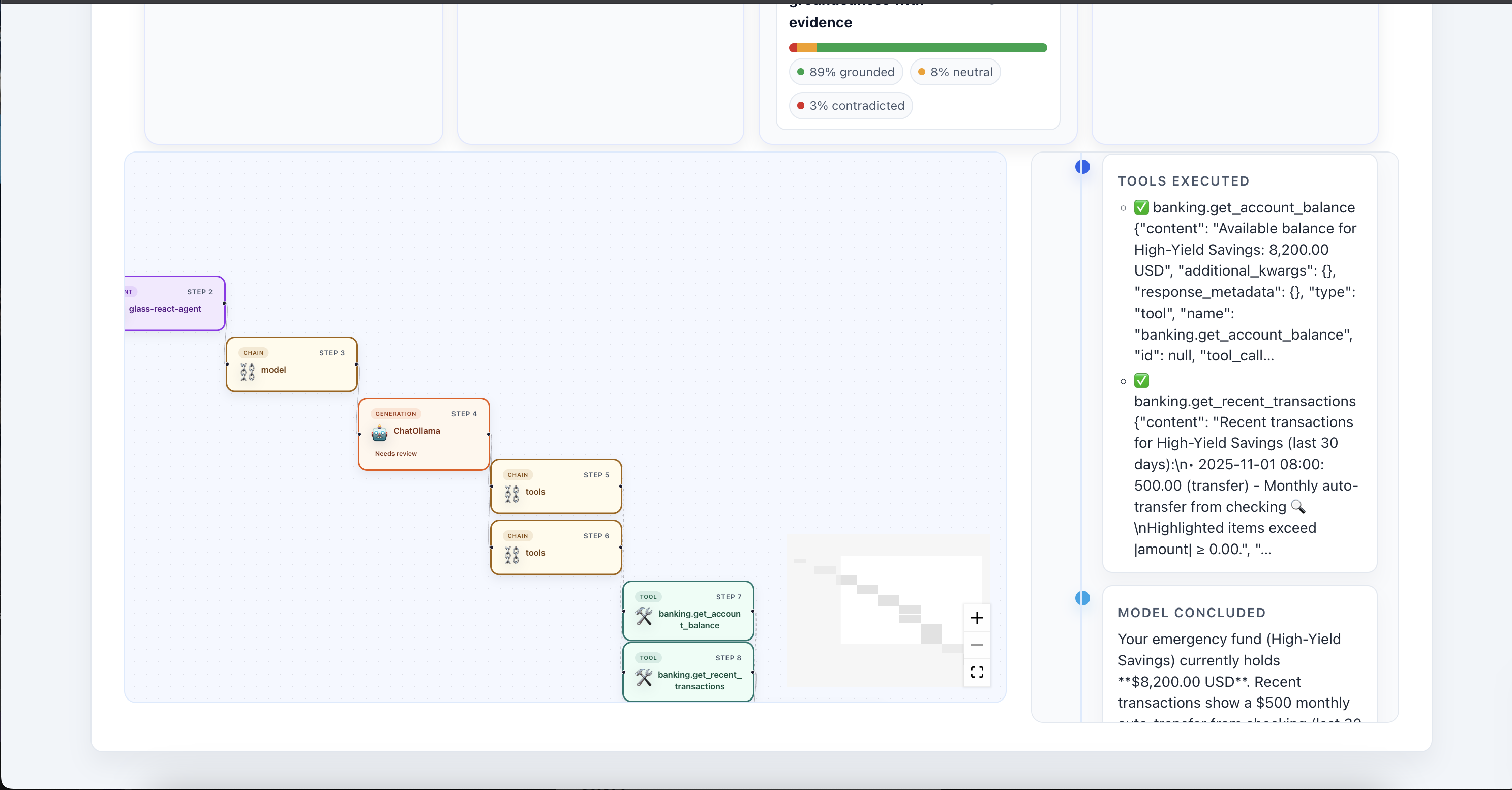
Agent Action Flow
-
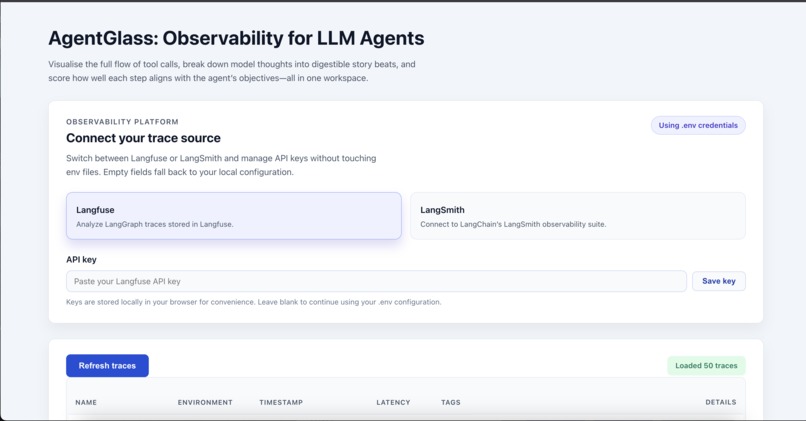
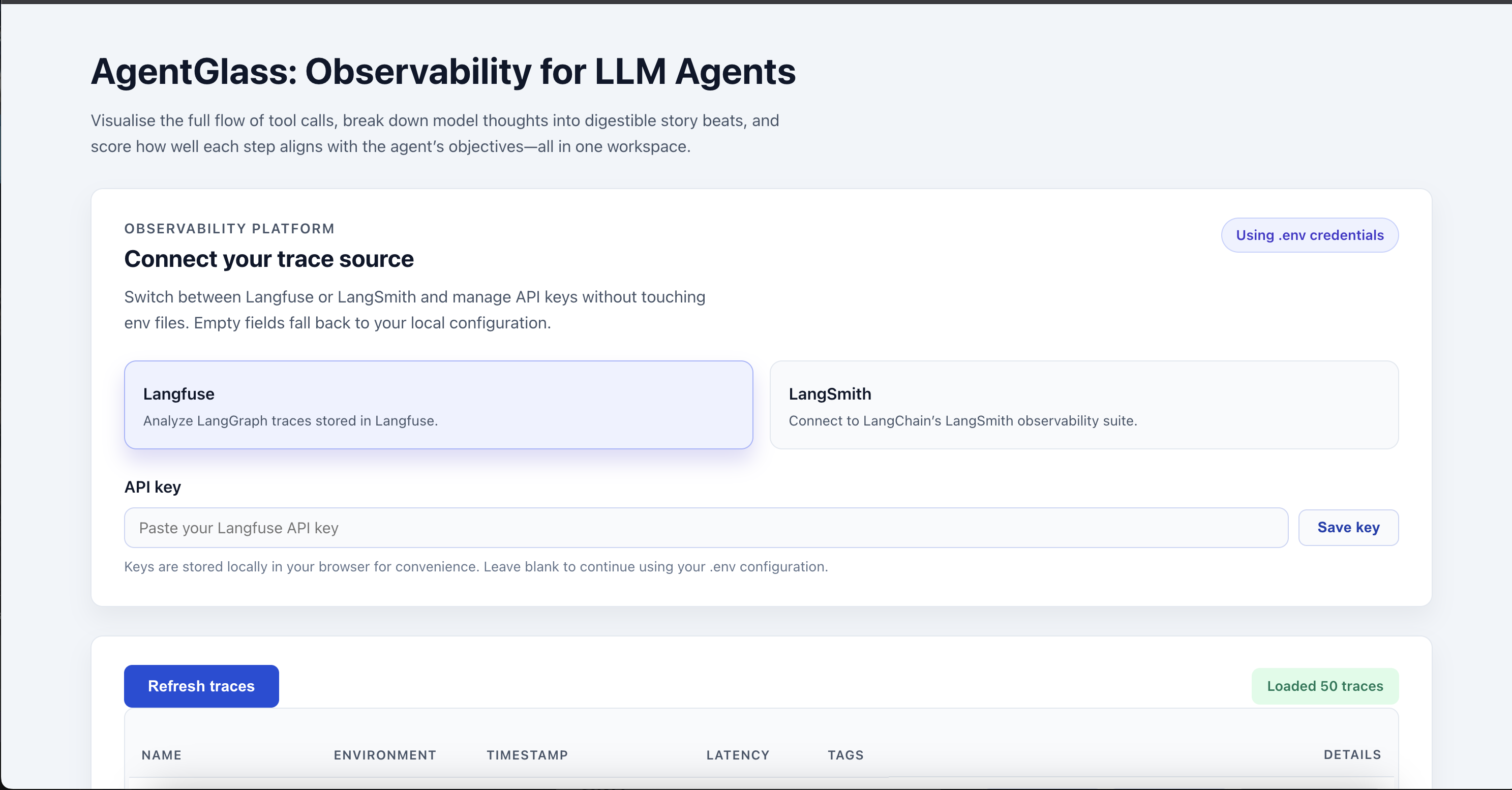
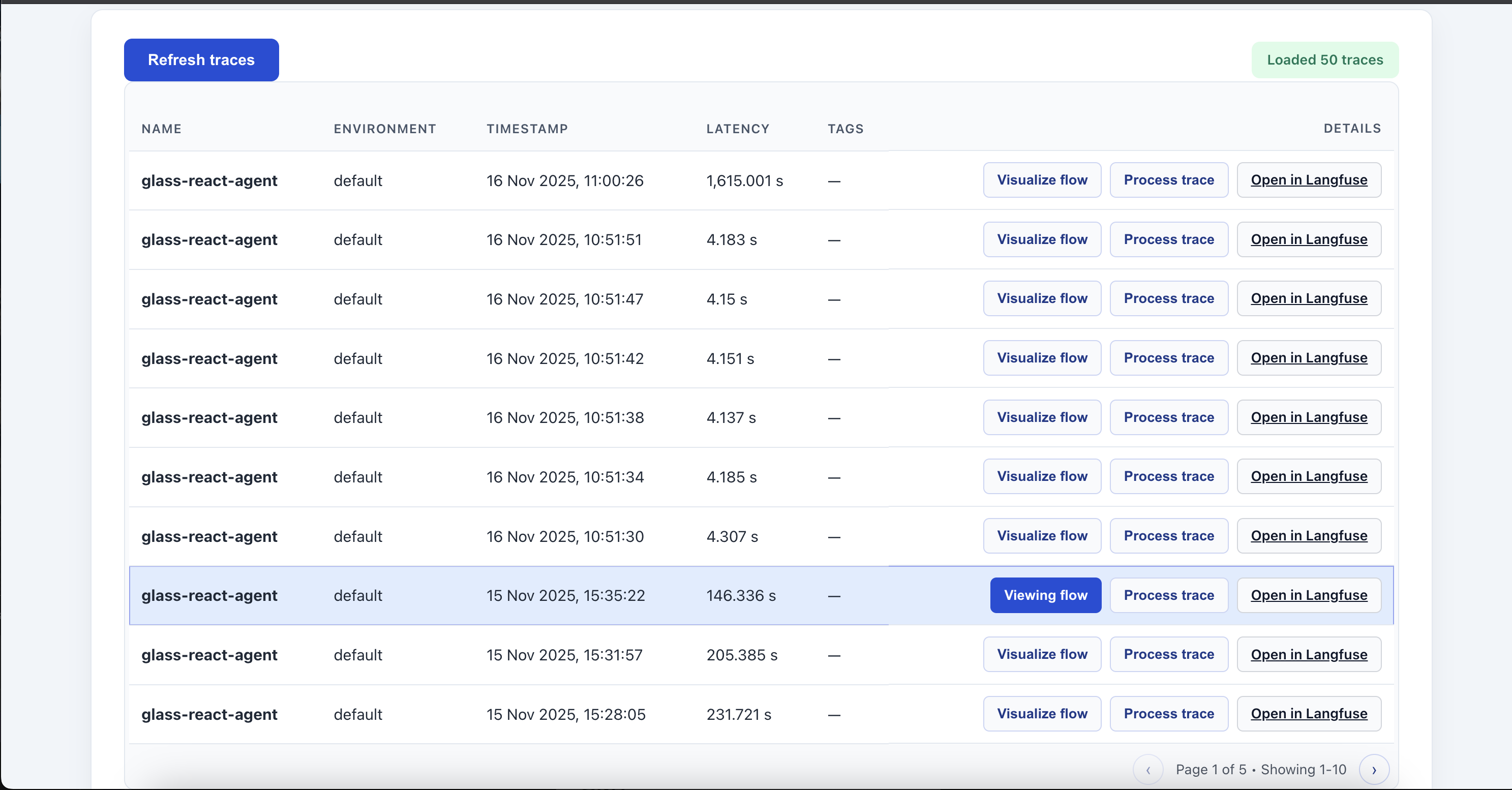
Import Traces from LangFuse or LangSmith easily
-
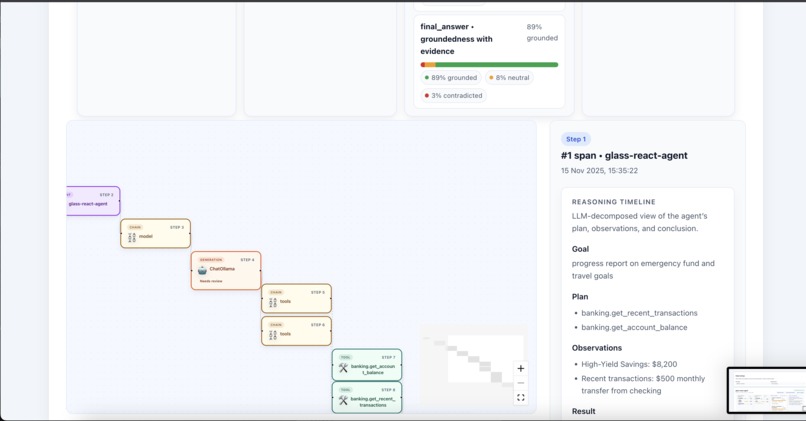
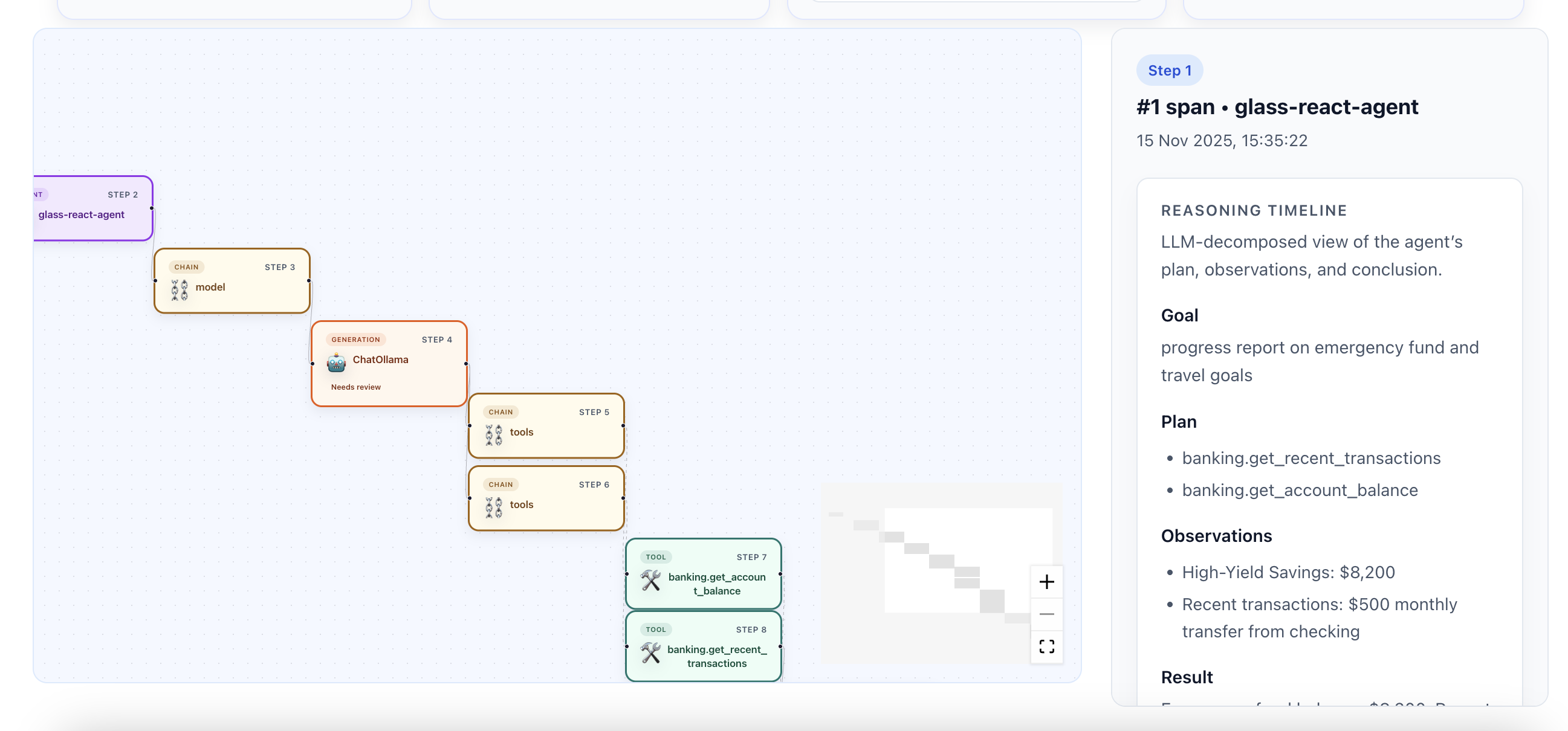
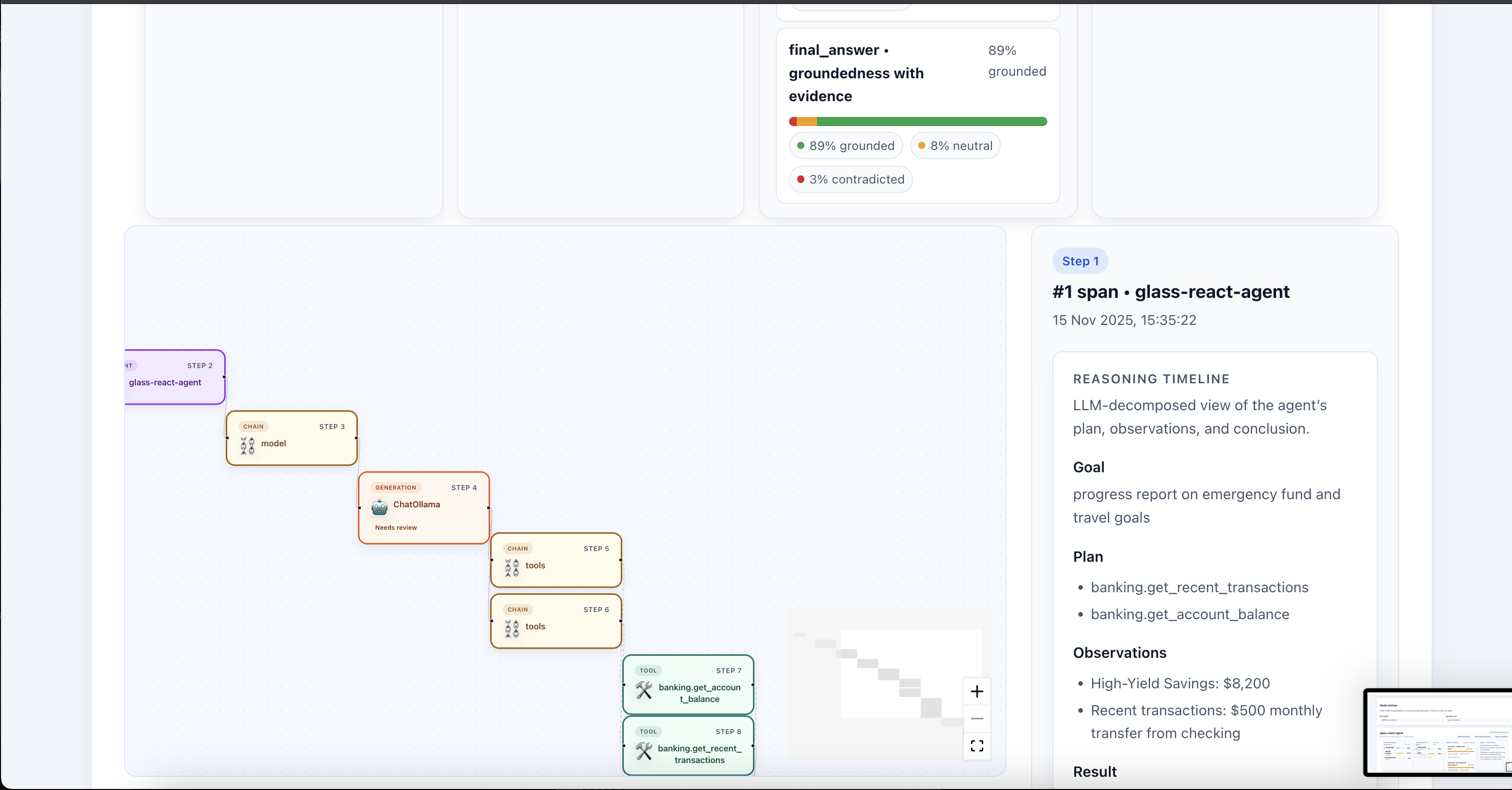
Inspect LLM Extracted Interpretable Traces
-
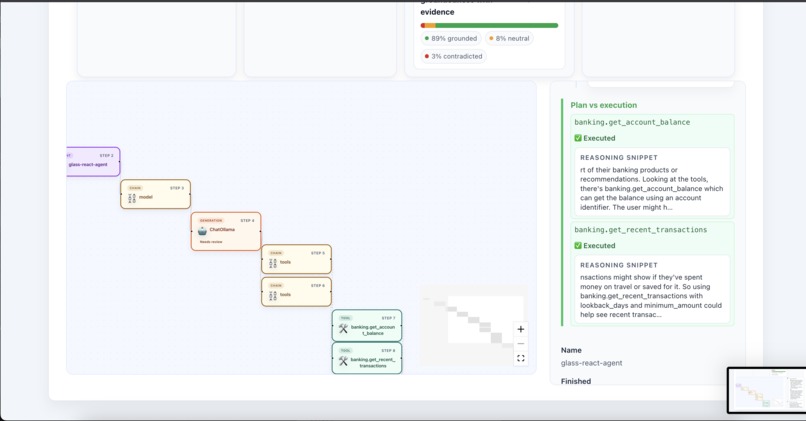
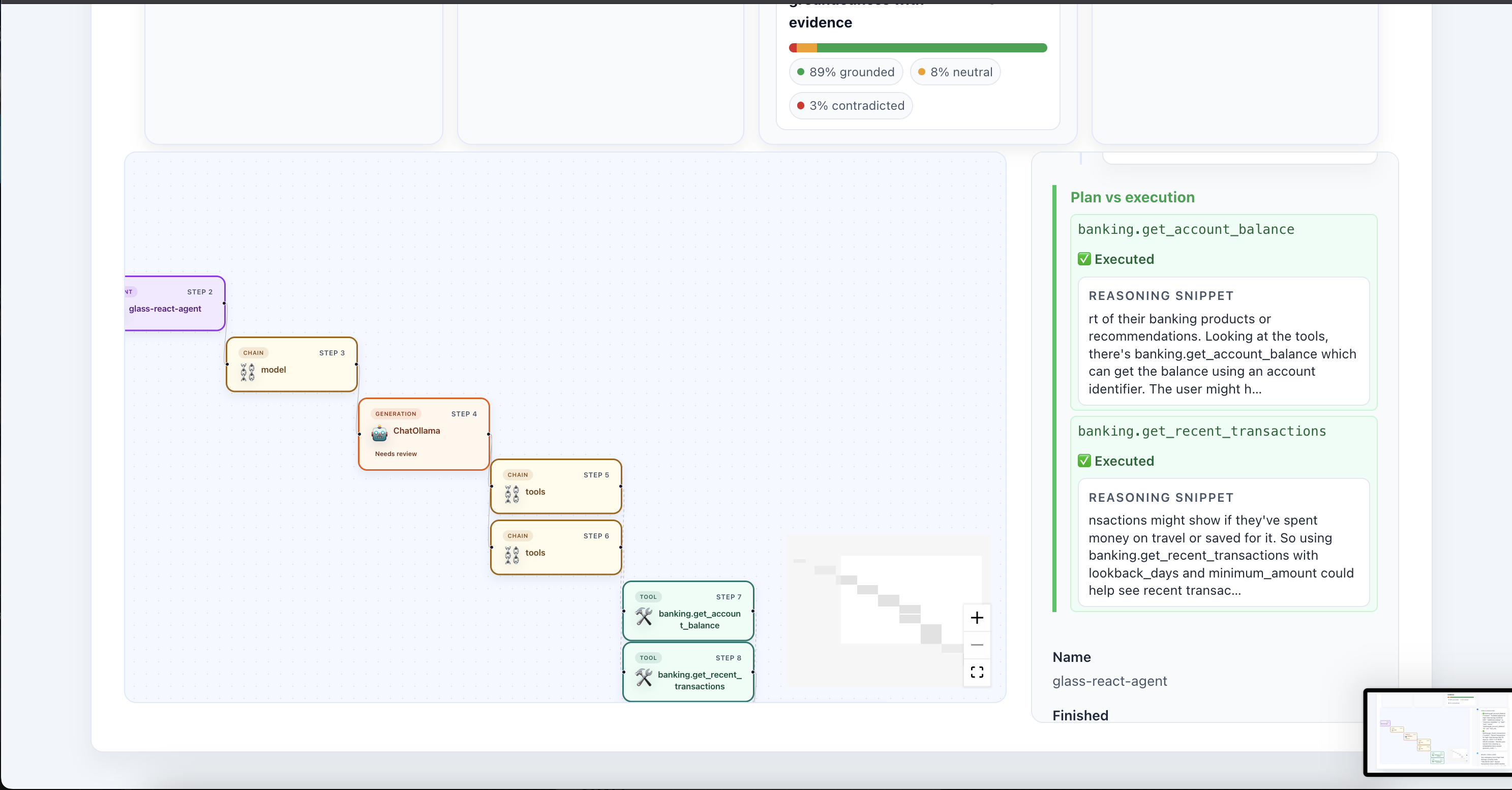
Plan vs agent execution comparison
-
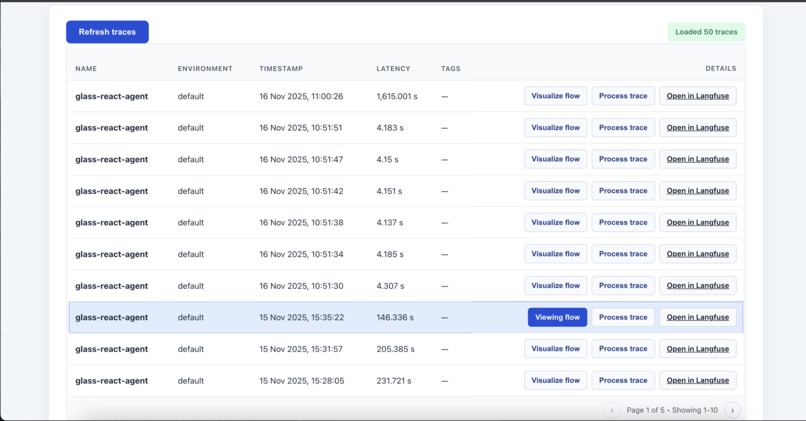
Process Traces to Graph and Compute Metrics
-
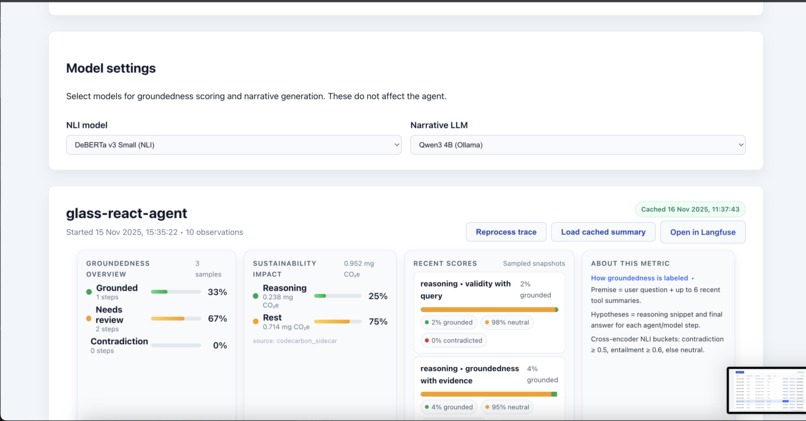
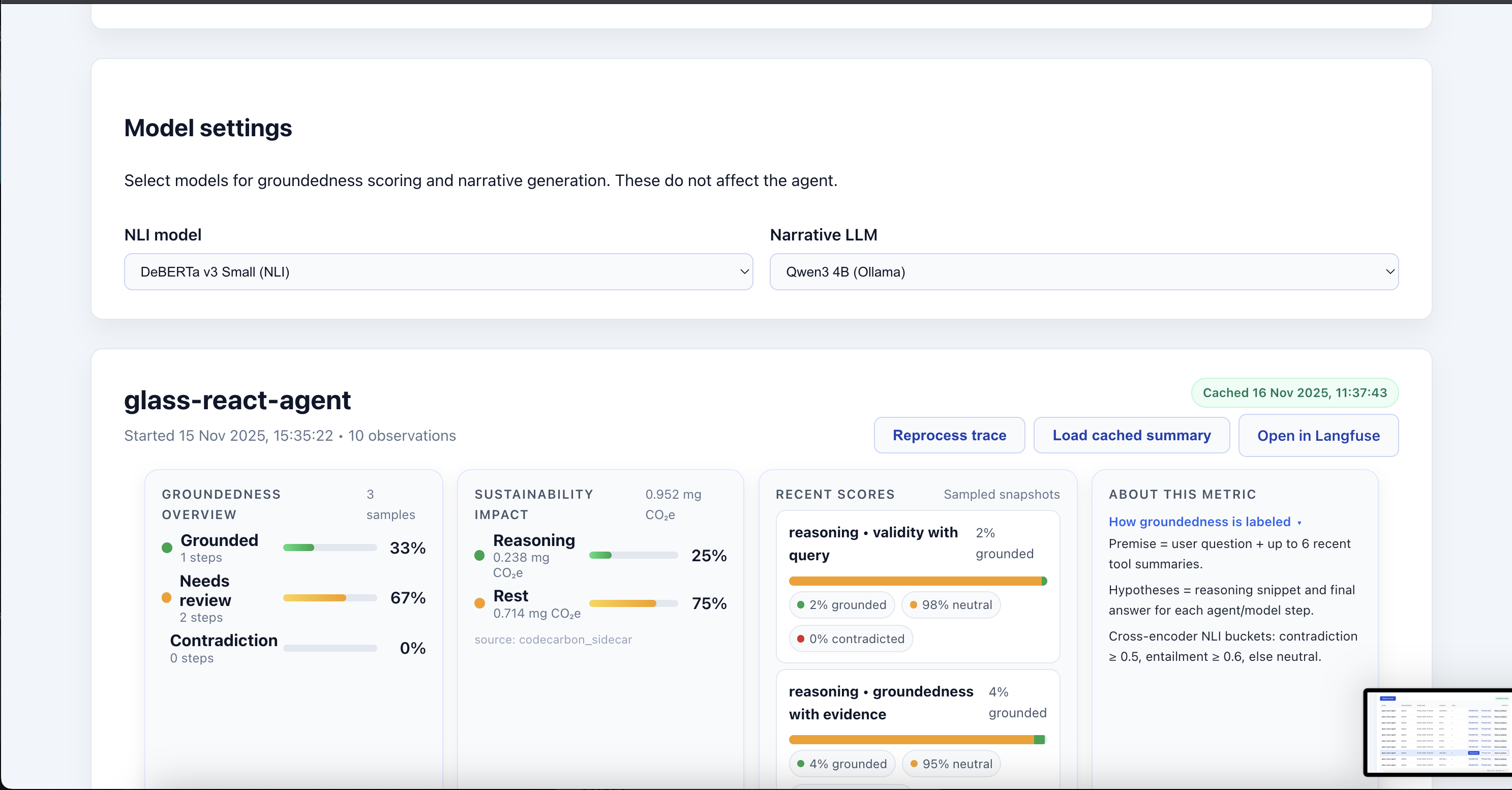
View NLI Metrics (Reasoning - Action Relation)
-
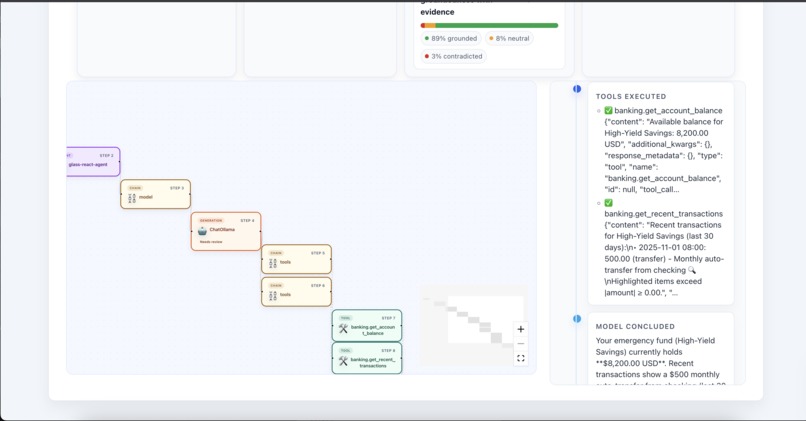
Further sidebar details for the agent execution narrative
-
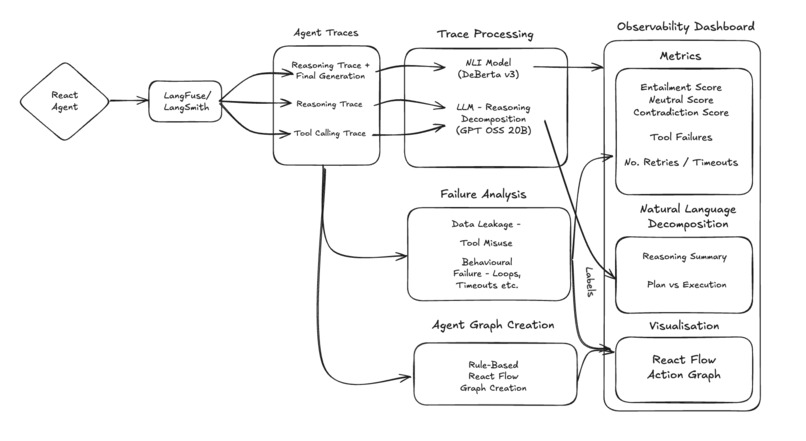
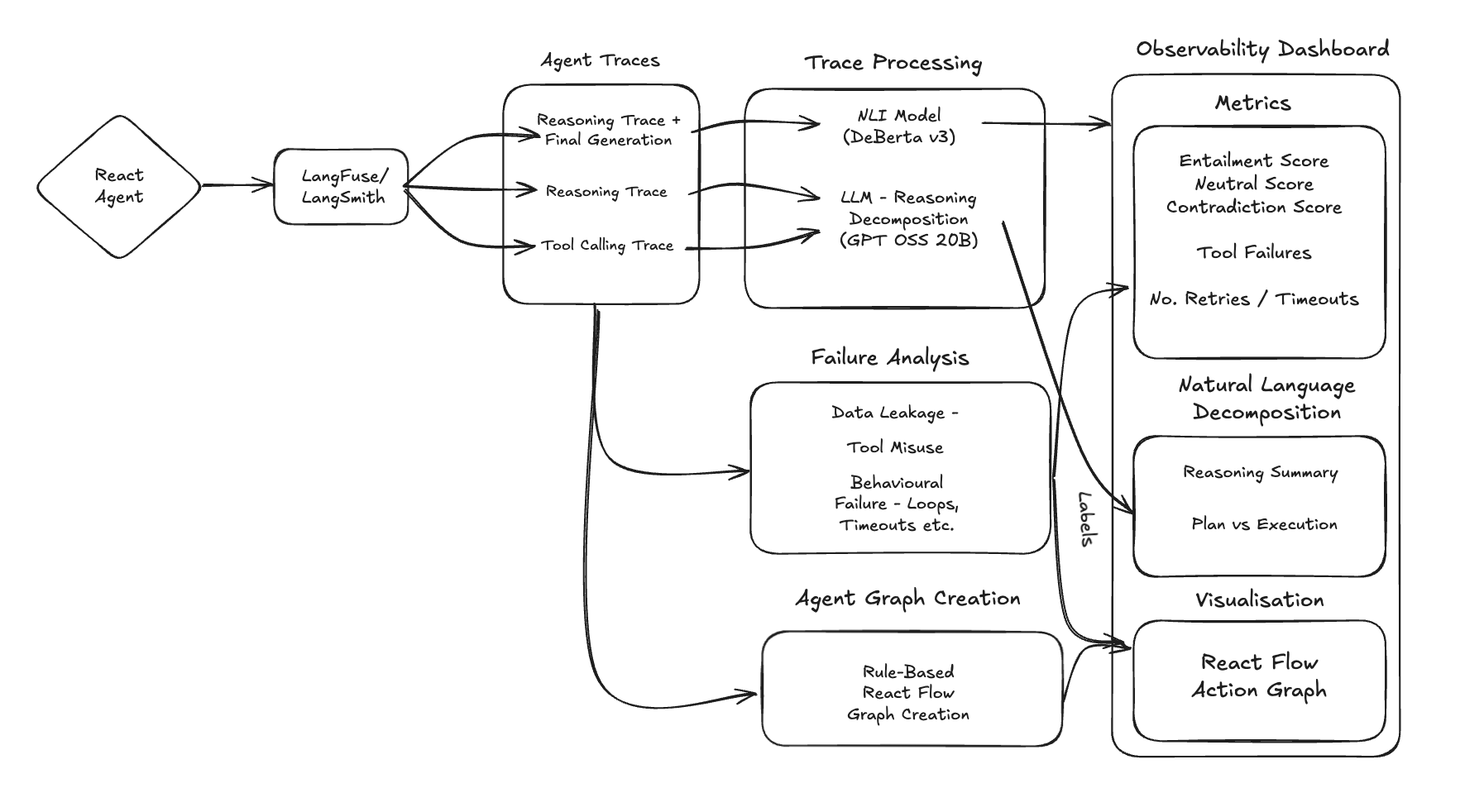
System Diagram
Inspiration
We were inspired by recent work showing that small cross-encoders can act as reliable judges of step-by-step reasoning. The ReCEval framework (Prasad et al.) demonstrated that NLI-style cross-encoders can check whether each step follows logically from the previous ones and that these scores often relate to better task outcomes. This encouraged us to build a local reasoning quality checker that runs entirely on-device using lightweight NLI models. We also wanted to include transparent sustainability tracking, so we used CodeCarbon to link emissions data directly to each phase of the agent’s behaviour. Together, these ideas shaped a toolkit that helps users understand how their agents think, where they struggle, and what their environmental impact looks like.
What it does
- Local-first observability: trace graphs, timelines, and metrics rendered entirely on-device
- Actionable reasoning checks: a small NLI cross-encoder highlights weak steps and contradictions
- Sustainability transparency: CO₂e estimates with a clear breakdown across agent phases
- Works with your agents: integrates with Langfuse traces and runs with a single command
How we built it
- End-to-end pipeline: traces go in, a local backend processes them, and the UI presents clear insights
- React frontend, React Flow for visualisations, Huggingface sentence transformers for crossencoder NLI models, Ollama for local LLMs for the agent and narrative extractor.
Challenges we ran into
- Handling diverse trace formats and turning them into a unified, analysable graph with the correct hierarchy (needed to make a rule based system)
- Making sustainability data meaningful and trustworthy by aligning it with agent activity
- Designing UI views that make errors and failure patterns easy to understand
- Ensuring everything runs quickly and reliably without cloud services (local models can be slow on my laptop)
Accomplishments that we’re proud of
- Fully local observability (Langfuse can also be integrated locally if desired) with no paid APIs needed - bring your own finetuned NLI models as well for domain-specific reasoning trace evaluation
- Reasoning scores that actually help users improve prompts, tools, and policies
- Clear CO₂e insights that connect environmental impact to agent behaviour
- Reproducible toolkit that you can install with 3 simple commands and use for your own traces
- Simple, low-friction setup that works with almost any agent
What we learned
- Small models can provide strong reasoning evaluation when the context is focused
- Local-first observability is practical, fast, and often all teams need
- Clear, interpretable explanations help users fix issues more effectively than opaque scores
What’s next for LocalGlass
- Human-in-the-loop tool failure labelling: a panel beneath the graph to label tool nodes as Correct, Risky, or Incorrect, with persistence per trace
- Configurable local labeller: choose a local model and customise a “Tool Failure Labeller” prompt for your domain
- One-click labelling: automatically label tool calls and cache the results, with the option to adjust by hand
- Lightweight fine-tuning: export labelled data for adapter-style tuning (for example LoRA or Unsloth) to create a domain-specific classifier
This would turn the toolkit into a truly end-to-end system. We can already visualise and understand the reasoning, and this final piece would let us actively refine and improve the agent.
Built With
- codecarbon
- crossencoder
- huggingface
- llm
- ollama
- python
- react
- typescript
- vite

Log in or sign up for Devpost to join the conversation.