-
-
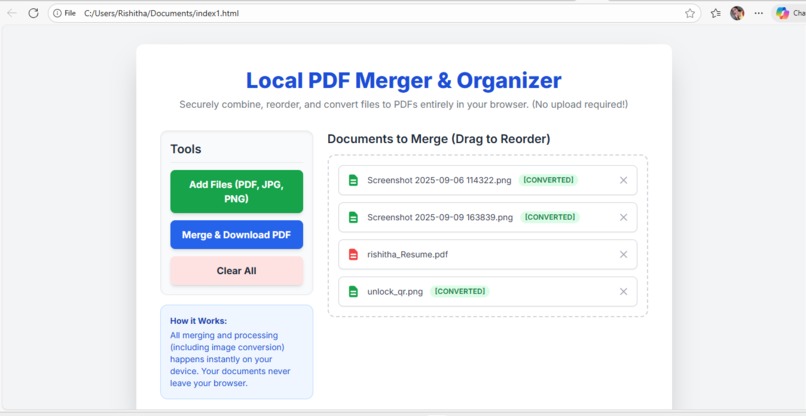
this is a sample testing on my website . I uploaded upto 6 different files and everyfile merged perfectly without any disturbance.
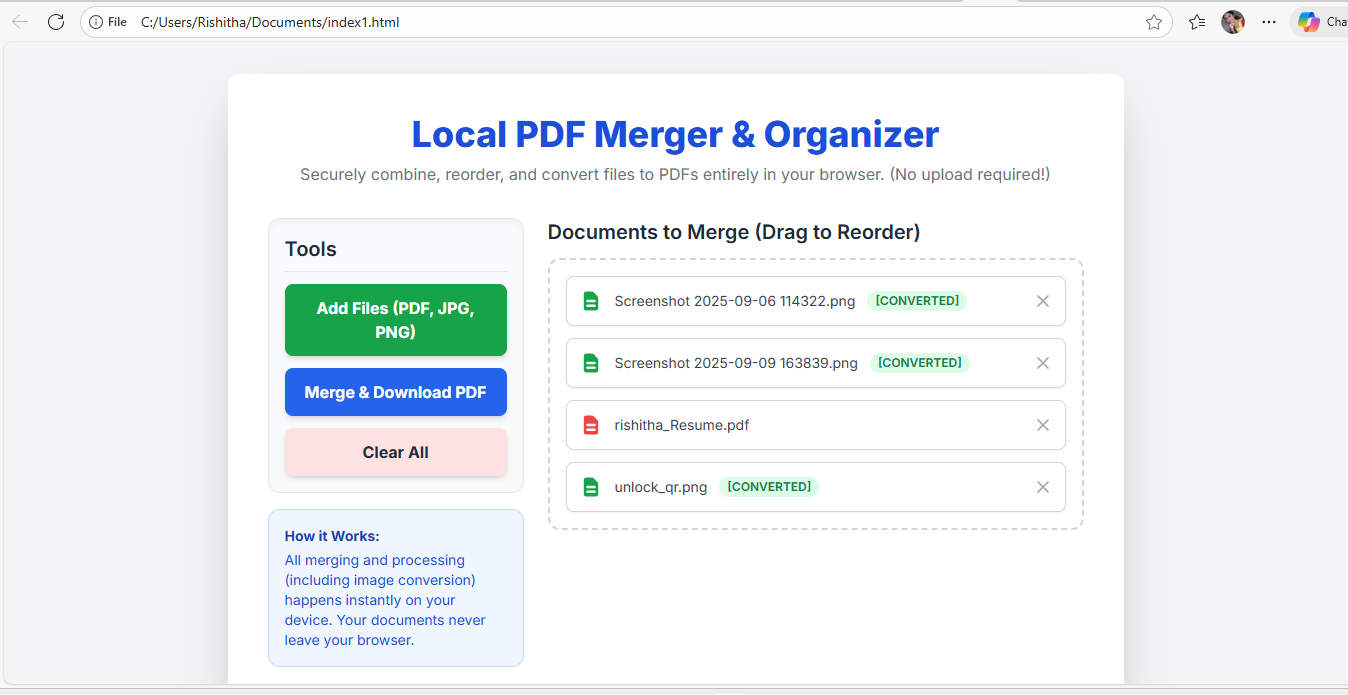
Project Description: Local PDF Merger & Organizer
Project Name
Local PDF Merger & Organizer (Code name: DocSecure)
Problem Statement
The challenge addressed is the need for a secure, fast, and multi-functional document preparation tool that maintains user privacy. Existing online PDF tools often require users to upload sensitive documents to an external server, creating privacy risks and delays. Users need a reliable, client-side solution to perform common document tasks like merging, reordering, and file-type conversion instantly.
Solution Overview
The Local PDF Merger & Organizer is a single-page web application that performs all PDF and image processing entirely within the user's browser, eliminating the need for server uploads.
The core functionality leverages the pdf-lib JavaScript library to:
File Normalization: Convert various document and media file types (including JPG, PNG, HTML, and TXT) into PDF format dynamically.
Organization: Allow users to drag-and-drop file cards to visually reorder the document sequence.
Merging: Combine multiple PDF buffers (original PDFs and converted assets) into a single, cohesive document for immediate download.
This provides users with a fast, private, and powerful document utility tool.
Inspiration
Our inspiration stemmed from the pervasive, yet often overlooked, problem of digital trust. Every time a user uploads a sensitive document (like a resume, tax form, or medical record) to a free online PDF service, they surrender control and privacy. We wanted to build a "zero-trust" utility tool—a solution that is powerful, free, and operates entirely on the user's device, proving that complex file manipulation can be both secure and accessible.
What it does
The application acts as a secure, local document hub:
- Input Flexibility: Users drag-and-drop or select PDF, JPG, PNG, HTML, or TXT files.
- Normalization: It instantly converts images and text files into temporary PDF buffers in memory.
- Organization: The user can visually reorder the files using a responsive drag-and-drop interface.
- Merging: It combines all sequential PDF buffers into a single, master PDF file.
- Secure Output: The merged document is downloaded directly to the user's device, and all file buffers are cleared from memory when the browser tab is closed.
How we built it
We used a client-side architecture built on HTML5, Tailwind CSS for rapid UI development, and pure Vanilla JavaScript for the logic. The entire project is self-contained in one file.
The critical technical component is the pdf-lib library. We built custom JavaScript utility functions around it:
- File Reading: Using the FileReader API to read raw file data into an ArrayBuffer.
- Conversion Pipeline: Custom functions like
convertImageToPdfBufferandconvertTextToPdfBufferhandle the creation of new PDF documents sized exactly to the content within. - Merging Logic: Iterating through the ordered list of ArrayBuffers, loading each one into memory, and using
pdfDoc.copyPages()to assemble the final merged document.
Challenges we ran into
The primary challenge was handling file diversity and memory management in a synchronous-feeling environment:
- Asynchronous Buffering: Managing the sequential, asynchronous loading and buffering of multiple files (especially large images) to ensure they were processed in the correct user-defined order.
- Image Scaling: Ensuring that converted images filled the PDF page correctly without distortion required precise calculation of image dimensions and setting the pdf-lib page size accordingly.
- Drag-and-Drop Reliability: Implementing smooth, cross-browser reliable drag-and-drop functionality for reordering dynamic list items using native DOM APIs proved complex.
Accomplishments that we're proud of
- Zero-Trust Security Model: Successfully proving that a robust document utility can operate entirely client-side, making it inherently more secure than most competing online tools.
- Multi-Format Pipeline: Developing a stable internal normalization pipeline that handles images, text, and native PDFs interchangeably for merging.
- Performance: Achieving near-instantaneous merging speeds, as the process is only limited by local CPU power and not network latency.
What we learned
We learned the immense power and limitations of browser APIs. Specifically, we gained deep experience in:
- Client-Side File APIs: Mastering the use of FileReader, Blob, and URL.createObjectURL for local file handling.
- Web Assembly Dependency Management: Understanding how large libraries like pdf-lib enable complex desktop-level functionality directly on the web.
- Optimizing DOM Manipulation: Building efficient drag-and-drop interfaces that do not introduce noticeable lag, even when reordering many complex elements.
What's next for Local PDF Merger & Organizer
- DOCX/ZIP Compatibility: Integrating specialized WASM modules (if available) to support more complex proprietary formats like DOCX and ZIP directly in the browser.
- Page Previews: Implementing a small library to render thumbnails of the first page of each PDF/Converted file to improve visual organization.
- Splitting and Extraction: Adding functionality to select a page range from a merged document to extract a new, separate PDF.
Built With
- and-tailwind-css
- api
- blob
- filereader
- html5
- javascript
- leveraging-the-pdf-lib-library-and-native-browser-apis-like-filereader
- pdf-lib
- pure-vanilla-javascript
- tailwind-css
- url.createobjecturl


Log in or sign up for Devpost to join the conversation.