-
-
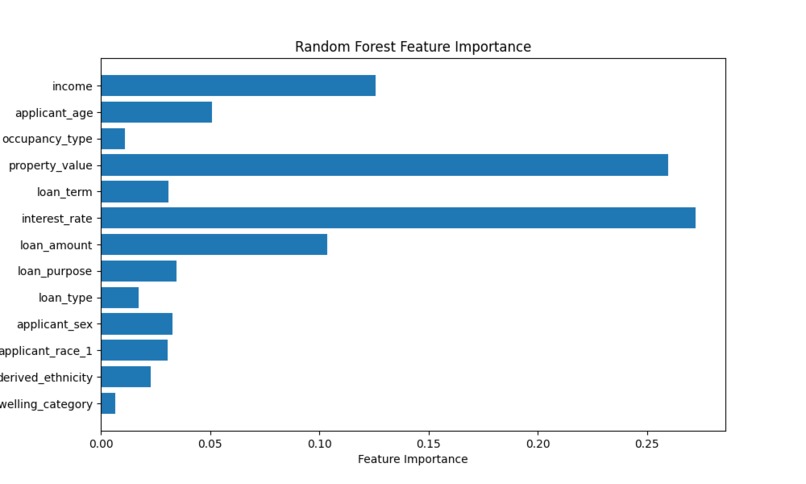
Feature importance plot
-
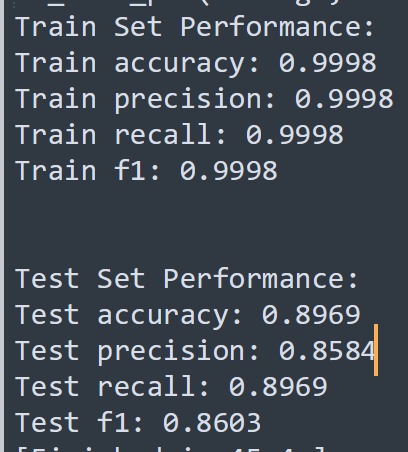
Performance of the model after cross validation
-
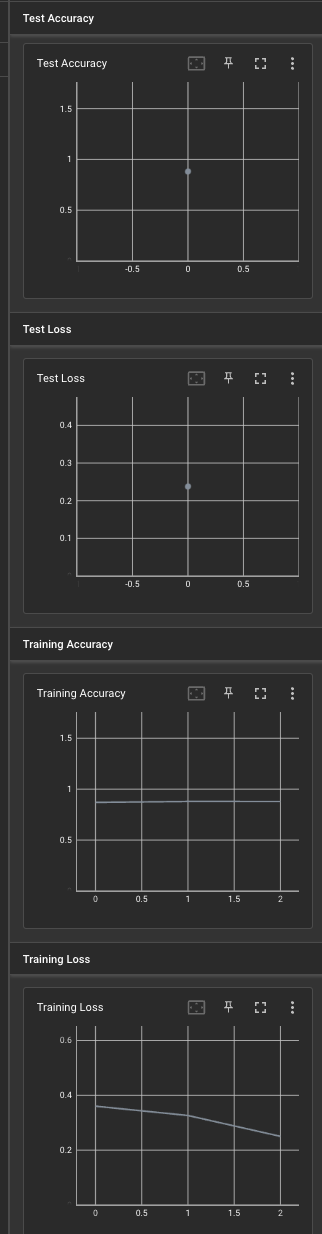
Tensorboard graph.
-

Neural Network Training

Inspiration
Our inspiration for the project was to make a financial prediction tool comparable to that of something like a FICO score estimator - relatively easy to use, applicable to a large audience, uses a broad range of factors to score as accurately as possible, and also provides constructive feedback versus a non-descriptive answer conclusion, which is essential for the financial health of the customer - since financial tools should be aimed making finances less daunting to approach.
What it does
Our application takes in several fields of user input, including things like age, income, loan amount, etc. Then, given these fields, our application interfaces this input with our networks, and runs an inference.
We then generate an output based on the result of the model, which we return to our user in the form of an approval or denied message in bold in the lower right corner of the UI.
How we built it
First, we worked together to brainstorm ideas. We knew we wanted to do the productivity track in combination with the financial and data science challenges, so we searched for potential topics along those lines, and came across loan approval.
Then, we searched for data regarding loan information. Thankfully, we were able to find an extremely comprehensive dataset on FFIEC's government data website. This, however, required lot’s of cleanup work to make it viable.
Then, we worked on feature selection. Some features were simply not that important to our model, while others had too many “NaN”’s for our liking, so we got rid of those features directly. We also at this point worked on entry selection. First, we had to cull the 6 GB file down to roughly a million entries, just to get that to work. Then, we randomly sampled a tenth of that million to get 100k random entries, and finally, we divided those 100k into an 80-20 split of training/testing datasets.
Then, we cleaned up the “NaN” features via replacing them with the average of all entries - this was our data cleaning process, and proved to be the hardest step. We also dropped all entries that had the text string “Entry” within them (of which there were like 20).
Then, we came up with ways to actually process our input and generate our output decision. During this time we had come to a crossroads regarding whether we should make this model binary classification or multi-class classification. Given the availability of labeled data (our denial reason with 1 - 10, with 10 being “N/A”, implying an acceptance of the loan, we went with multiclass classification.
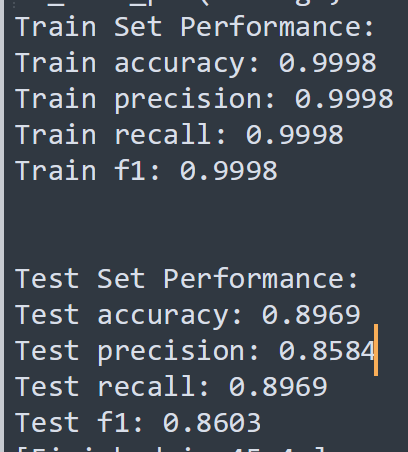
We trained several machine learning models to compare performance: Random forest: This model is based on decision trees. These trees’ edges have differing weights which the supervised machine learning process optimizes based on the loss calculated via a difference from the output. This was an out of the box scikit-learn model that boasted a very respectable training accuracy of roughly 99.9%, and a test accuracy of 86%. Clearly there is some overfitting going on, but it overall performed quite well.
Balanced Random Forest: This algorithm and model was also considered. However, we ended up not proceeding with this model in light of its 14% accuracy.
Linear Neural Networks with cross-entropy loss. This is a simple 11 layer model that uses 5 linear layers and 6 non-linear activation layers to solve this multi-classification task. It had a training accuracy of 87.9%, and a test accuracy of actually 88.1%. Very consistent performance, especially given that it was only trained over 3 epochs (roughly a minute run-time on a 2021 MacBook Pro).
We then chose to include both of these models into our application, and also implemented GUI (which was very non-trivial - we received extensive help from the mentors in our selection of PyQt as our ultimate platform for coding the GUI).
Challenges we ran into
Big Data! Our dataset initially was nearly 6 GB unzipped, and it was very difficult to work with, even with traditional tools like Excel. We ended up having to use juypter notebooks, combined with the power of pandas to select roughly a million entries, and make it more manageable. If the data had been too much bigger, it’s entirely possible the difficulty of working wit the data would increase to the point we would have to turn to a more powerful computer to work with it.
Another major issue was regarding the treatment of the distribution of NaN values across all examples. We first considered passing NaNs as zeros, but thought it would make more sense to fit the distribution across the existing values for each individual feature by averaging the existing feature values and passing that in place of all NaNs. There was considerable effort on filling in NaNs with a more systematic approach with Random Forest algorithm but did not have time to complete this implementation.
Accomplishments that we're proud of
I think we are proud of understanding several different models. We managed to operate under high-pressure and tight deadlines. We also managed to learn and work flexibly as a team, which I think was very helpful, especially as we became more and more sleep-deprived as the competition went on.
Regardless of the outcome, we truly appreciate the difficulty, but also usefulness and coolness of data science and machine learning, and its enormous potential to create useful application for others.
What we learned
We learned a lot about Qt front-end development, among other things. For example, we learned that data cleaning is a non-trivial task, and that pandas is a very flexible tool for handling errors we didn’t necessarily expect, like the difficulty of “NaN” cells versus empty cells, and how these situations would have to be edited separately.
We also learned a lot about different types of models, and once again realized the difficulty that goes into truly participating in a hackathon. We also learned of course a lot about models, how they work, how to actually implement them, and just garnered a lot of extra experience.
What's next for Local Life Loans
We plan on continuing the development of our application via optimizing our UI. Notably we would like to be able to fluidly change between available models, add to our model repository. Of course, we would like to do other things like increase model complexity, fine-tune models further, and possibly include more user flexibility on what they must input to get a prediction, and so on and so forth. There are many ways this application can be improved, but we believe the potential is enormous.






Log in or sign up for Devpost to join the conversation.