


Inspiració
Canelons!!!
Que fa?
LoBonDetector analitza les imatges d'una càmera de seguretat d'alt rendiment d'un supermercat i detecta les posicions que es troben buides en una nevera per donar informació sobre les necessitats de reposició dels productes.
Com l'hem fet
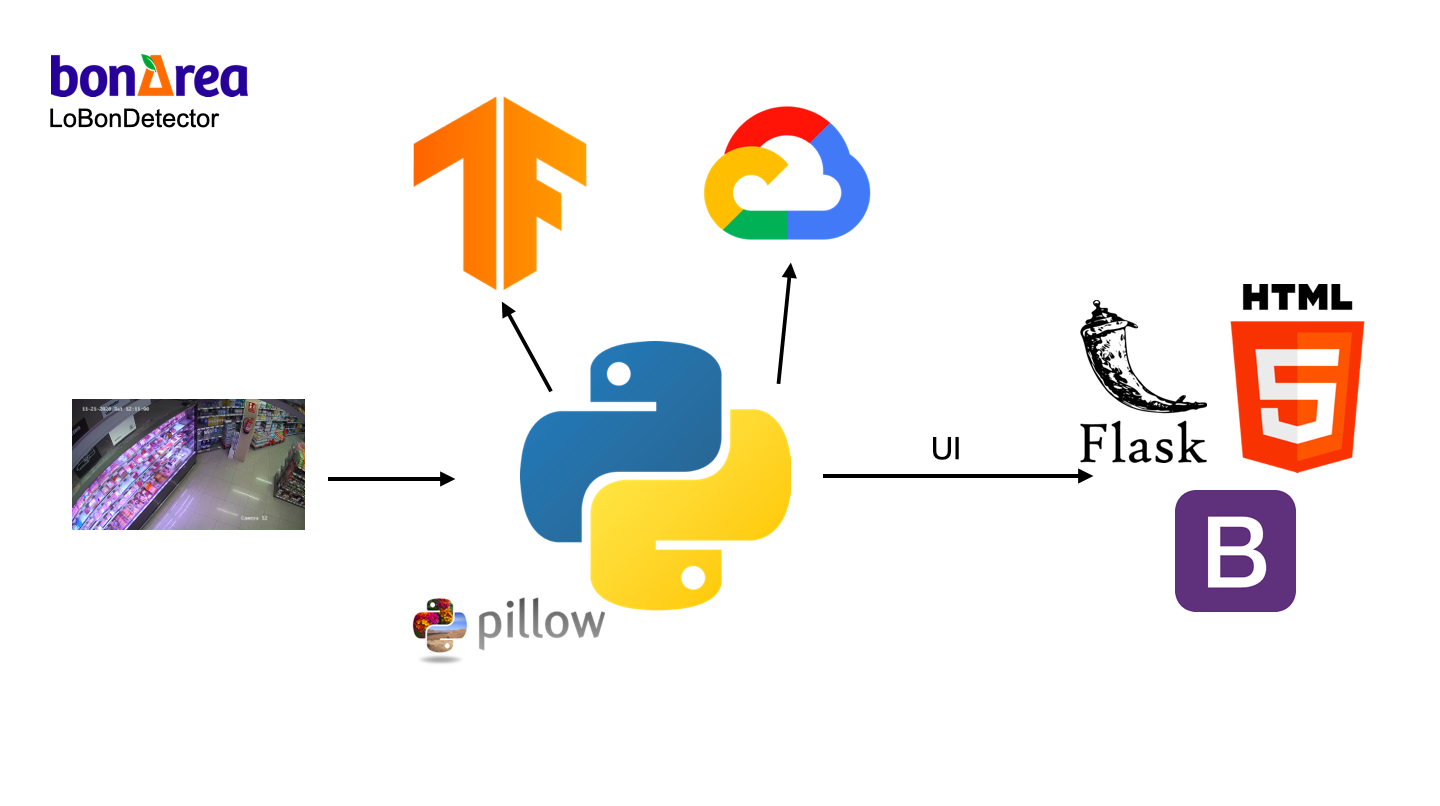
En primer lloc hem dividit l'estanteria en seccions, cadascuna de les quals representa un producte, obtenint les coordenades de cad aproducte en pixels. A continuació hem entrenat un model de Deep Learning amb les llibreries de Tensorflow a partir de les "subimatges" de cada secció anterior, que hem etiquetat com a "Buit" o "No buit".
En fer una petició d'una imatge es fa una crida a la API Vision de Google Cloud que etiqueta objectes (com persones, carros de la compra o altres obstacles) i la seva ubicació. A la matriu de l'estanteria marquem quines subimatges es troben bloquejades per un obstacle. Les que no estan bloquejades es passen al model de Deep Learning que ens retorna si es troben buides o no buides.
Finalment retornem una matriu on cada posició por estar buida, no buida, o bloquejada. Això es el que representem en la nostra app de Flask.
Reptes que hem afrontat
En una primera instància ha calgut reosldre el fet que en algunes fotos apareguèssin persones i altres obstacles davant de la nevera. s'ha solucionat a partir de l'etiquetatge de la imatge amb Google Cloud Vision.
Entrenar el model ha estat un altre repte, ja que haviem de crear el nostre propi training set amb un temps limitat, i equilibrar la quantitat d'imatges en el training set per evitar un overfitting però aconseguir una bona precissió en la classificació.
També hem trobat un petit repte d'algoritmia alhora de descartar imatges si s'hi superposa un obstacle, ja que calia avaluar si tapava la posició del producte verticalment i horitzontalment alhora.
Que hem après
En aquest projecte hem pogut veure un cop més el potencial de la Inteligència Artificial, ja que en molt poc temps i amb un training set relativament petit hem aconseguit un model força acurat. A més hem implementat solucions d'Inteligència Arficial externes per complementar el nostre model tenint en compte les dades disponibles, mostrant la imporància de combinar eines per fer un ús eficient del temps i els recursos. Finalment, hem utilitzat Pillow, una llibreria de Python per al tractament d'imatges que no haviem utilitzat mai.











Log in or sign up for Devpost to join the conversation.