-
-
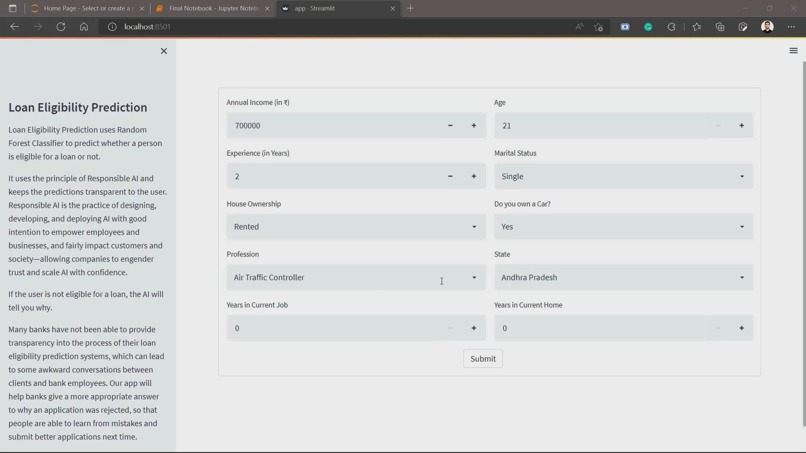
Homepage
-
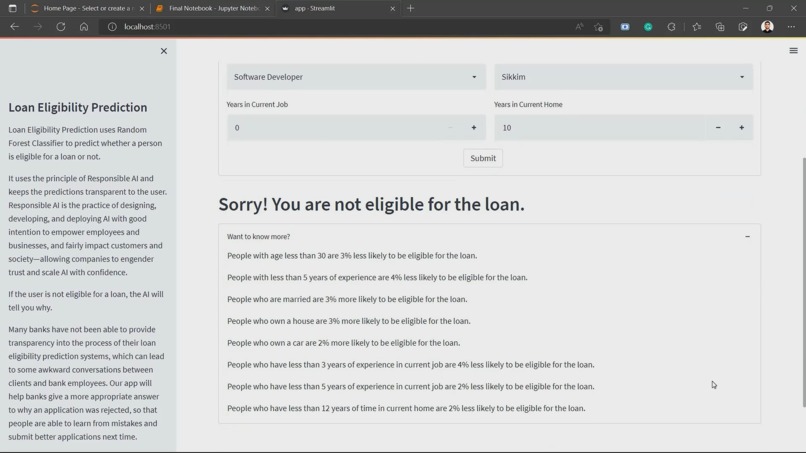
Explaining why not eligible
-

Interactive Viz
-
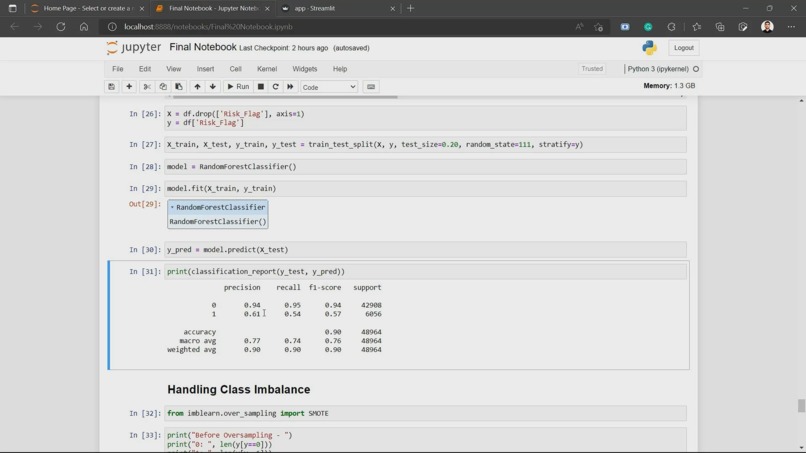
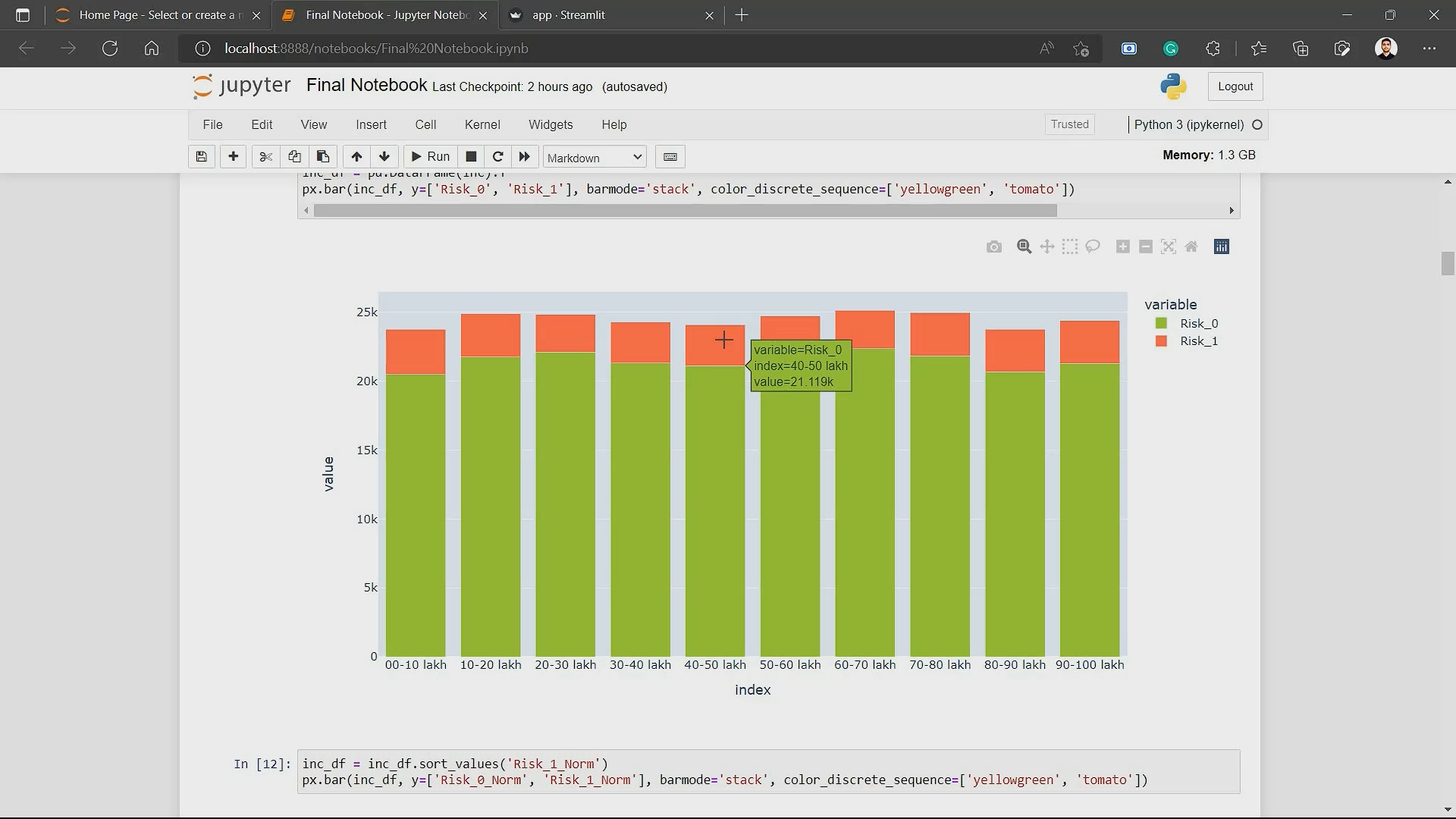
Evaluation Metrics before using SMOTE
-
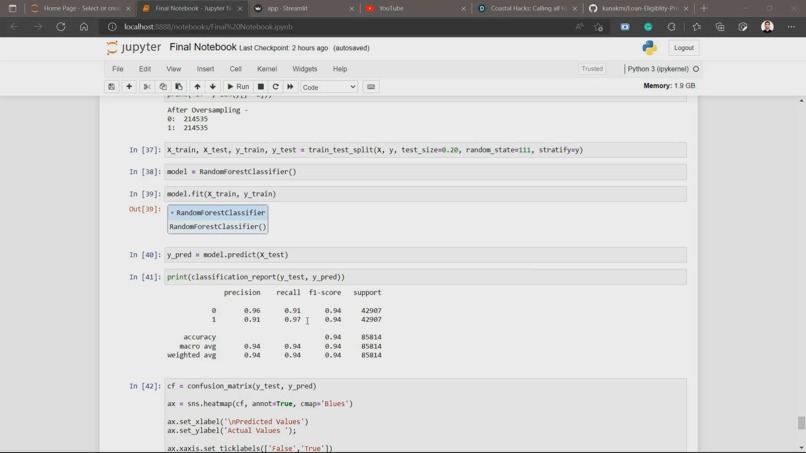
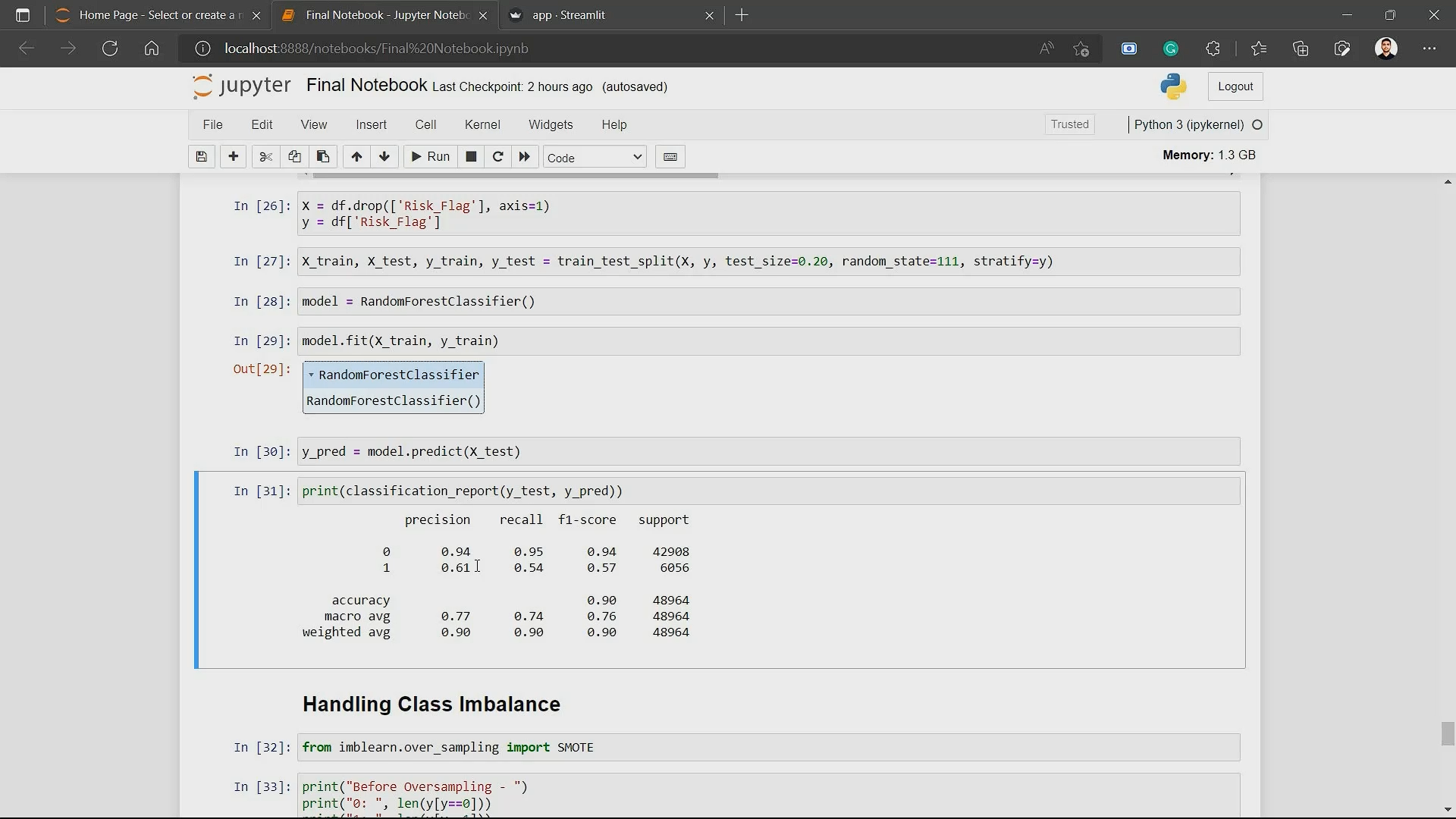
Evaluation Metrics after using SMOTE



💡 Inspiration
When you read the project's title, you're reminded of the same old type of rudimentary machine learning projects that can be found on YouTube Tutorials. But believe me when I say that this is a one-of-a-kind effort.
What distinguishes it from the competition? I'm glad you asked.
- The dataset used in this project is a real one with over 250K data points.
- The dataset, like the actual world, is highly imbalanced.
- The initiative makes responsible use of artificial intelligence (it not only tells you if you are eligible for a loan but in case you are not, it tells you what exactly went wrong and how can you improve).
💻 What it does
Loan Eligibility Prediction uses Random Forest Classifier to predict whether a person is eligible for a loan or not.
It uses the principle of Responsible AI and keeps the predictions transparent to the user. Responsible AI is the practice of designing, developing, and deploying AI with good intention to empower employees and businesses, and fairly impact customers and society—allowing companies to engender trust and scale AI with confidence.
If the user is not eligible for a loan, the AI will tell you why.
Many banks have not been able to provide transparency into the process of their loan eligibility prediction systems, which can lead to some awkward conversations between clients and bank employees. Our app will help banks give a more appropriate answer to why an application was rejected so that people are able to learn from mistakes and submit better applications next time.
⚙️ How it Works
The user enters their details that including their
- Income
- Age
- Experience
- Marital Status
- House Ownership
- Number of Cars the person owns
- Profession
- State
- Years in Current Job
- Years in Current Address
The app uses this data to predict whether the user is eligible for a loan or not.
If the user is not eligible for a loan, the app will give you the option to gain insights into why.
🔨 How I built it
- ML: Python, Sklearn, Pandas, Numpy, Plotly, Imblearn
- UI & Backend: Streamlit
🧠 Challenges we ran into
Since the dataset was highly imbalanced, there were only 12% of the total data points belonged to the "Loan Defaulter" class. This is such a small fraction that developing a model that can reliably forecast this class is exceedingly difficult.
Take this scenario for example: If the model simply classifies all the data points as "Not Loan Defaulter", then the accuracy of the model will be 88%, but is this model useable? This phenomenon is called Accuracy Paradox. So, to evaluate the model, we need to use better metrics like Precision and Recall or combinedly the F1 score.
Before handling the class imbalance, this is what the evaluation metrics look like:
precision recall f1-score support
0 0.94 0.95 0.94 42908
1 0.61 0.54 0.57 6056
accuracy 0.90 48964
macro avg 0.77 0.74 0.76 48964
weighted avg 0.90 0.90 0.90 48964
As you can see, even though the model has 90% accuracy, the precision for the "Loan Defaulter" class is 61%, which means, out of 6056 data points predicted as "Loan Defaulter", 61% of them were actually "Loan Defaulter" and rest were misclassified. Moreover, the recall for this class is 54% which means out of every 100 persons that belong to the "Loan Defaulter" class, only 54 of them were rightly classified. This could result in a huge loss for the company. This is not a good model.
Solution:
We could downsample the "Not Loan Defaulter" class to a similar size as the "Loan Defaulter" class. But if we fail to downsample it accurately, then the dataset might not be able to represent the true population.
We could upsample the "Loan Defaulter" class to a similar size as the "Not Loan Defaulter" class by considering the same data points multiple times. But this could result in model overfitting.
We could use SMOTE (Synthetic Minority Over-sampling Technique) to create synthetic data points for the "Loan Defaulter" class. SMOTE uses the KNN algorithm to create synthetic data points that are similar to the original data points but not exactly the same. Kind of what Data Augmentation does in the Computer Vision domain.
Count of data points belonging to each class -
Before using SMOTE -
0: 214535
1: 30281
After using SMOTE -
0: 214535
1: 214535
This is what the evaluation metrics look like after using SMOTE:
precision recall f1-score support
0 0.96 0.91 0.94 42907
1 0.91 0.97 0.94 42907
accuracy 0.94 85814
macro avg 0.94 0.94 0.94 85814
weighted avg 0.94 0.94 0.94 85814
🏅 Accomplishments that we're proud of
- Achieving an F1 score of 94% on the test set.
- Completing the Project in such a short time frame.
📖 What we learned
- Using SMOTE to handle class imbalance in a dataset.
- About Accuracy Paradox (a phenomenon in which accuracy is not the correct metric to evaluate the performance of a model).
🚀 What's next for Loan Eligibility Prediction
- Using different kinds of SMOTE techniques for upsampling the dataset and improving the model. Since oversampling is a CPU-intensive task, on my current hardware, it takes about 30 minutes to try out 1 technique and also exhaust the machine so I was not able to try them all in this short time frame.

Log in or sign up for Devpost to join the conversation.