-
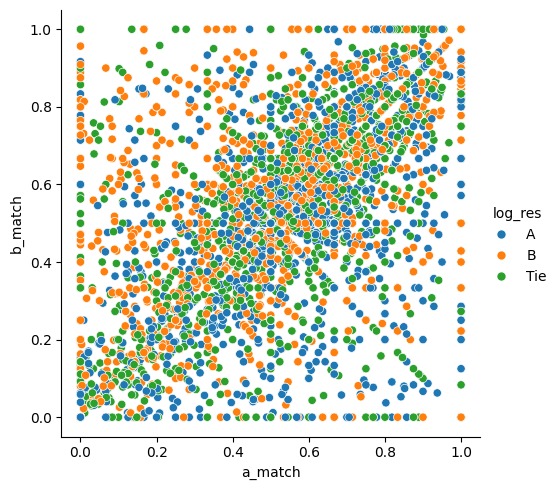
Metric 1
-
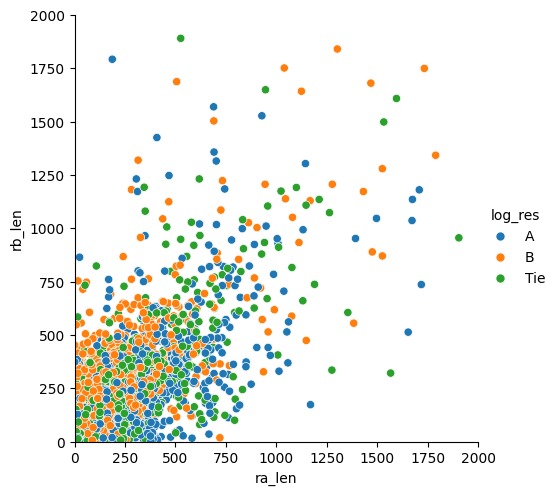
Metric 2
-
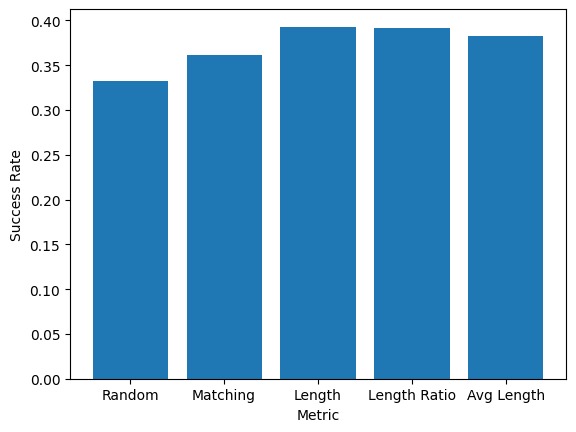
Metric 1 Success Rate
-
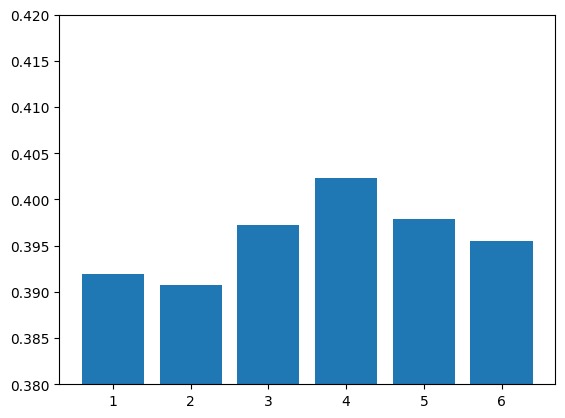
Metric 2 Success Rate
-
Code Sample
Inspiration
Our project was inspired by the fascinating challenge of predicting human preferences in chatbot interactions. The competition challenged us to predict which responses users would prefer in head-to-head battles between different LLMs, offering a unique opportunity to contribute to improving human-AI interaction. We were particularly intrigued by the real-world application of machine learning in addressing problems related to RLHF (Reinforcement Learning from Human Feedback) and the development of preference models.
What it does
Our project predicts which chatbot response a user would prefer when presented with two options from different large language models. Using various metrics extracted from both the prompts and responses, we built a predictive model that evaluates features like word matching, response length, prompt-to-response length ratio, and average word length to determine which response is more likely to be favored by users.
How we built it
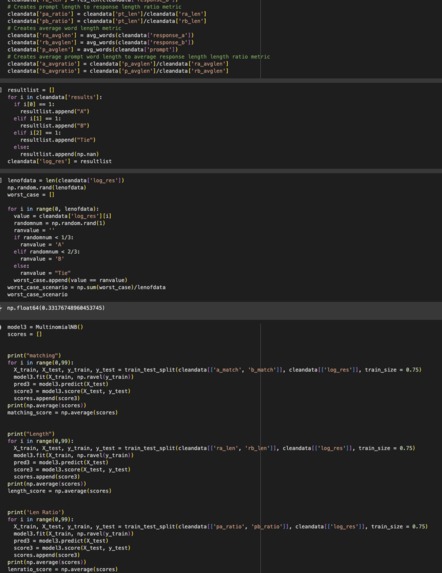
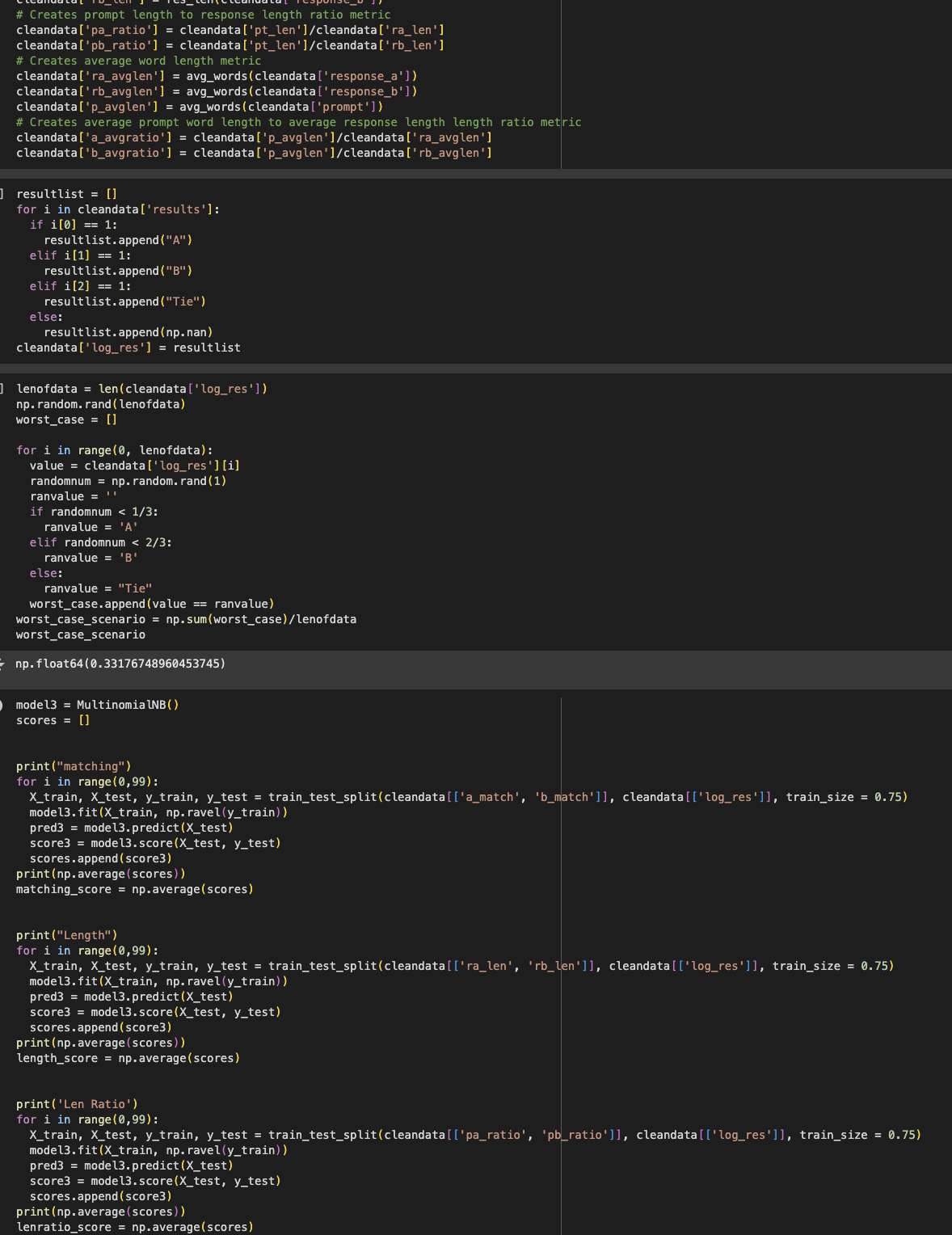
We started with data preprocessing, where we: Cleaned the strings from the dataset Extracted tokens using feature extraction Created several metrics for comparison: Word match rate between prompt and responses Response length (word count) Prompt-to-response length ratio Average word length in responses
We then experimented with a MultinomialNB (Naive Bayes) classification model to evaluate how well different feature combinations could predict user preferences. We systematically tested various feature combinations to identify which were most predictive:
Individual features (matching, length, ratio, average length) Two-feature combinations (e.g., matching+length, matching+ratio) Three-feature combinations All features combined
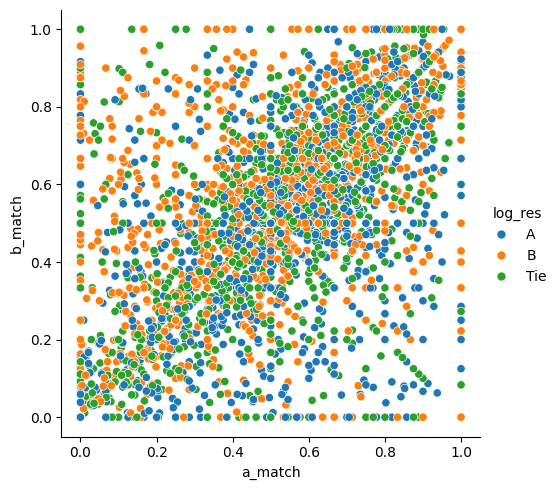
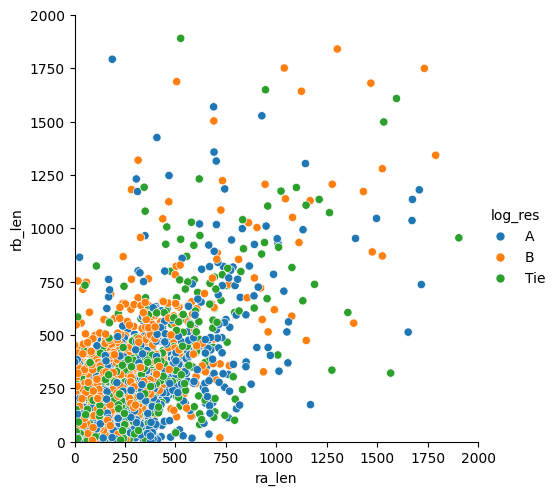
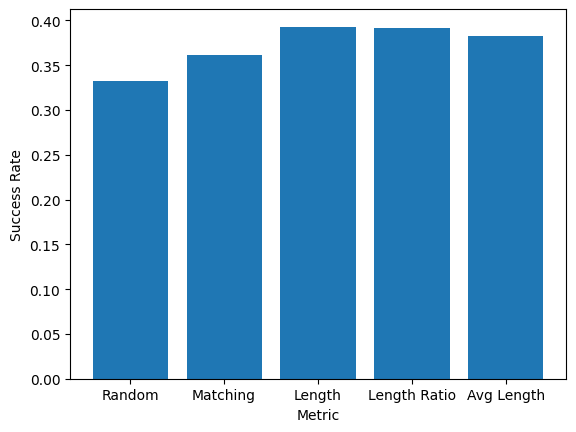
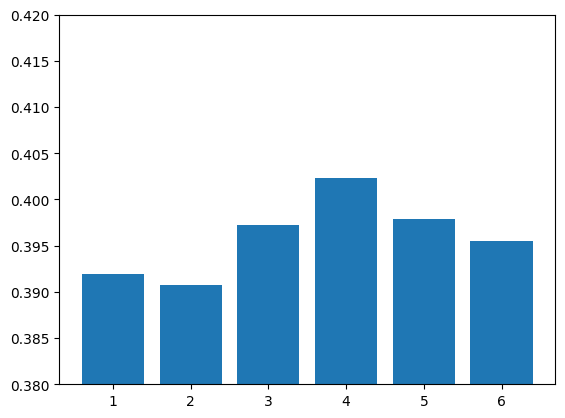
We conducted multiple train-test splits (99 iterations for each feature combination) to ensure our performance metrics were robust. We visualized relationships between features and user preferences using scatter plots and compared the performance of different feature combinations with bar charts.
Challenges we ran into
Feature engineering - determining which aspects of the prompts and responses would be most predictive of user preferences was not straightforward. We had to experiment with multiple metrics and combinations. Dealing with potential biases in the dataset - as mentioned in the competition description, LLM preferences can be influenced by biases like verbosity bias or position bias. Achieving high prediction accuracy - our models achieved modest improvement over random guessing (which would have ~33% accuracy in a three-way classification of A/B/Tie), suggesting the complexity of predicting human preferences.
Accomplishments that we're proud of
Building a systematic approach to feature engineering that extracted meaningful metrics from text data. Our rigorous testing methodology that evaluated multiple feature combinations through extensive cross-validation. Identifying that combinations of features (particularly three-feature and four-feature combinations) performed better than individual features alone. Creating visualizations that helped us understand the relationships between different features and user preferences.
What we learned
Human preferences for chatbot responses are complex and difficult to predict with simple metrics alone. Word matching between prompt and response, response length, length ratios, and average word length all contribute to user preferences, but none dominates as a single predictor. The best models combined multiple features, suggesting that users evaluate responses based on a complex combination of factors. Naive Bayes classification can work reasonably well for this type of prediction task, though there's significant room for improvement.
What's next for LMSYS Challenge - Chatbot Arena Predictions
Explore more sophisticated feature engineering, potentially incorporating semantic similarity measures rather than just word matching. Experiment with more advanced models beyond Naive Bayes, such as gradient boosting or deep learning approaches. Investigate additional features like sentiment analysis, response coherence, and specific linguistic patterns that might influence user preferences. Consider model ensembling techniques to combine the strengths of different predictive approaches. Analyze the cases where our model performs poorly to identify additional factors that might influence human preferences.
Built With
- chatgpt
- matplotlib
- numpy
- pandas
- python
- scikit-learn
- seaborn

Log in or sign up for Devpost to join the conversation.