Inspiration
Many of us struggled with English as children. In Ukraine, we mostly learned it through school classes, but those often felt boring, inefficient, and disconnected from how children naturally absorb language. At the same time, many of us loved movies and wanted to watch them all the time. That inspired us to build a platform that teaches language through content children already enjoy. Research shows that children have a remarkable capacity for language acquisition: in dual-language environments, they can learn two languages at the same rate as one. The problem is that not every child grows up in a bilingual household. Our platform makes that kind of natural language exposure accessible through movies. While children are our main focus, since the effect is strongest for them, the same idea works for adults too - especially for busy people who want to learn without setting aside separate study time.
What it does
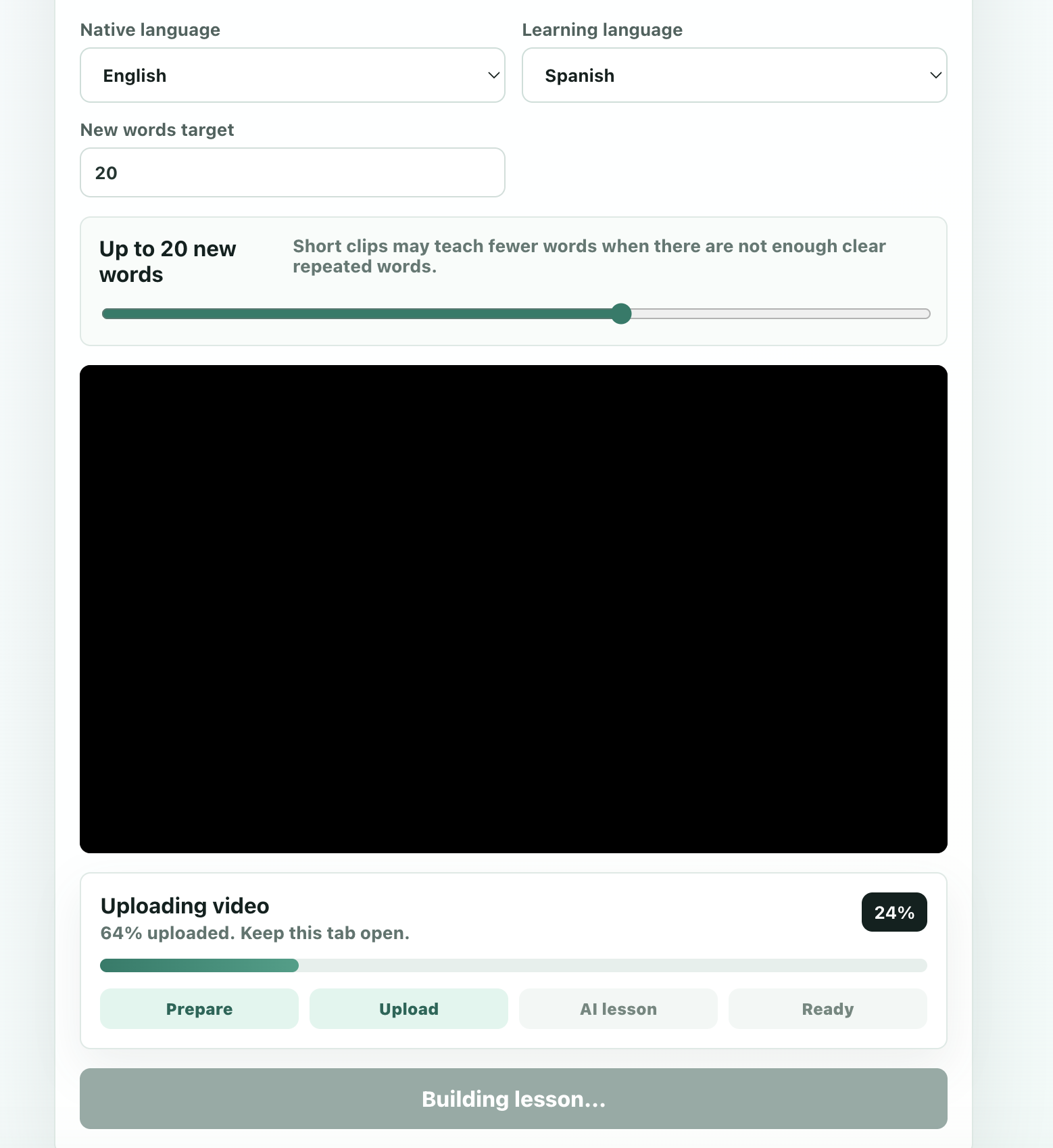
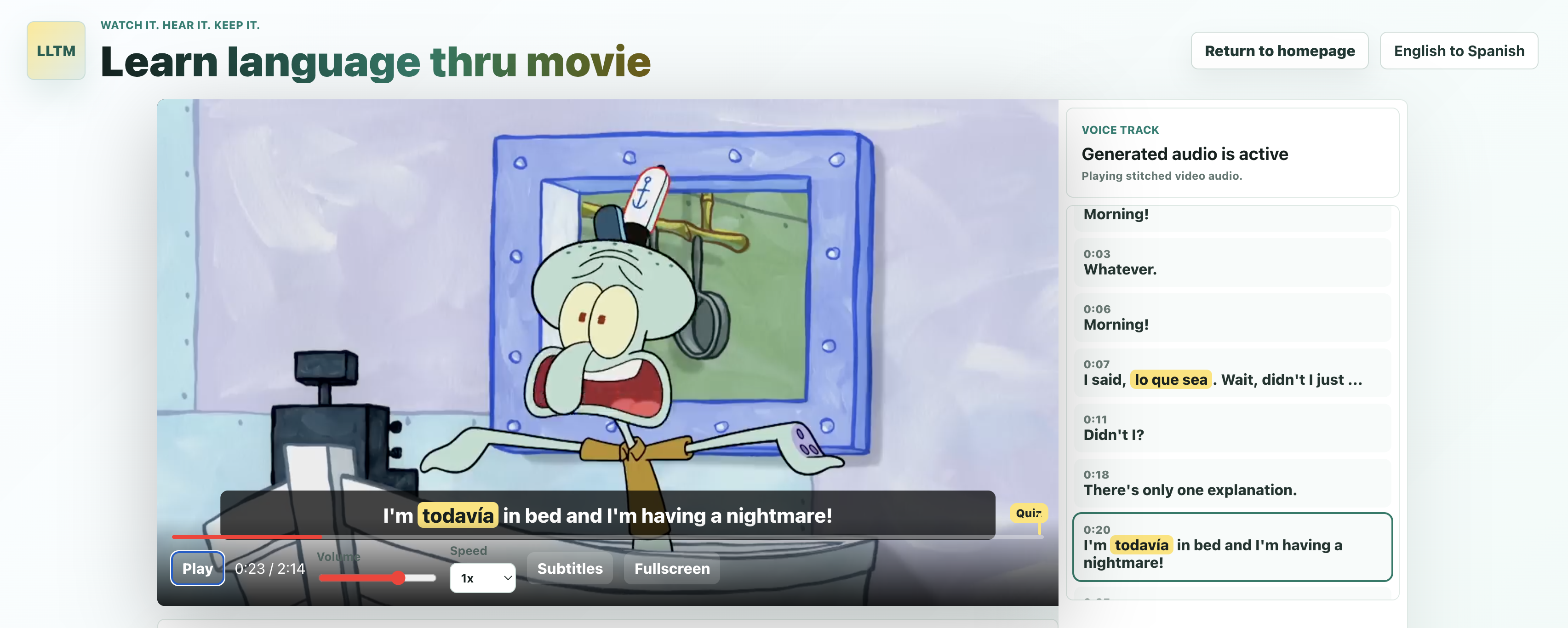
LLTM helps users learn a language through movies. It identifies words that are both important and easy to infer from context, based on the user's current vocabulary and what they have already learned on the platform. It then replaces those words with audio in the target language, so the user learns naturally through context instead of stopping to study.
How we built it
We use ElevenLabs to generate subtitles from uploaded video. Then we use open-source language models through featherless.ai (currently Qwen2.5-72B) to analyze the subtitles and decide which words should be introduced in the target language for this specific user. After that, we dub those selected words back into the video in a way that aims to feel smooth and natural rather than distracting.
Challenges we ran into
One challenge was handling differences in sentence structure across languages. In many cases, translating a single word inside a phrase would break the grammar or make the sentence sound unnatural, so we had to decide whether to translate the entire phrase or skip it altogether.
Another challenge was separating and processing different audio tracks correctly, so that voices would not get mixed together or sound unnatural in the final result.
Accomplishments that we're proud of
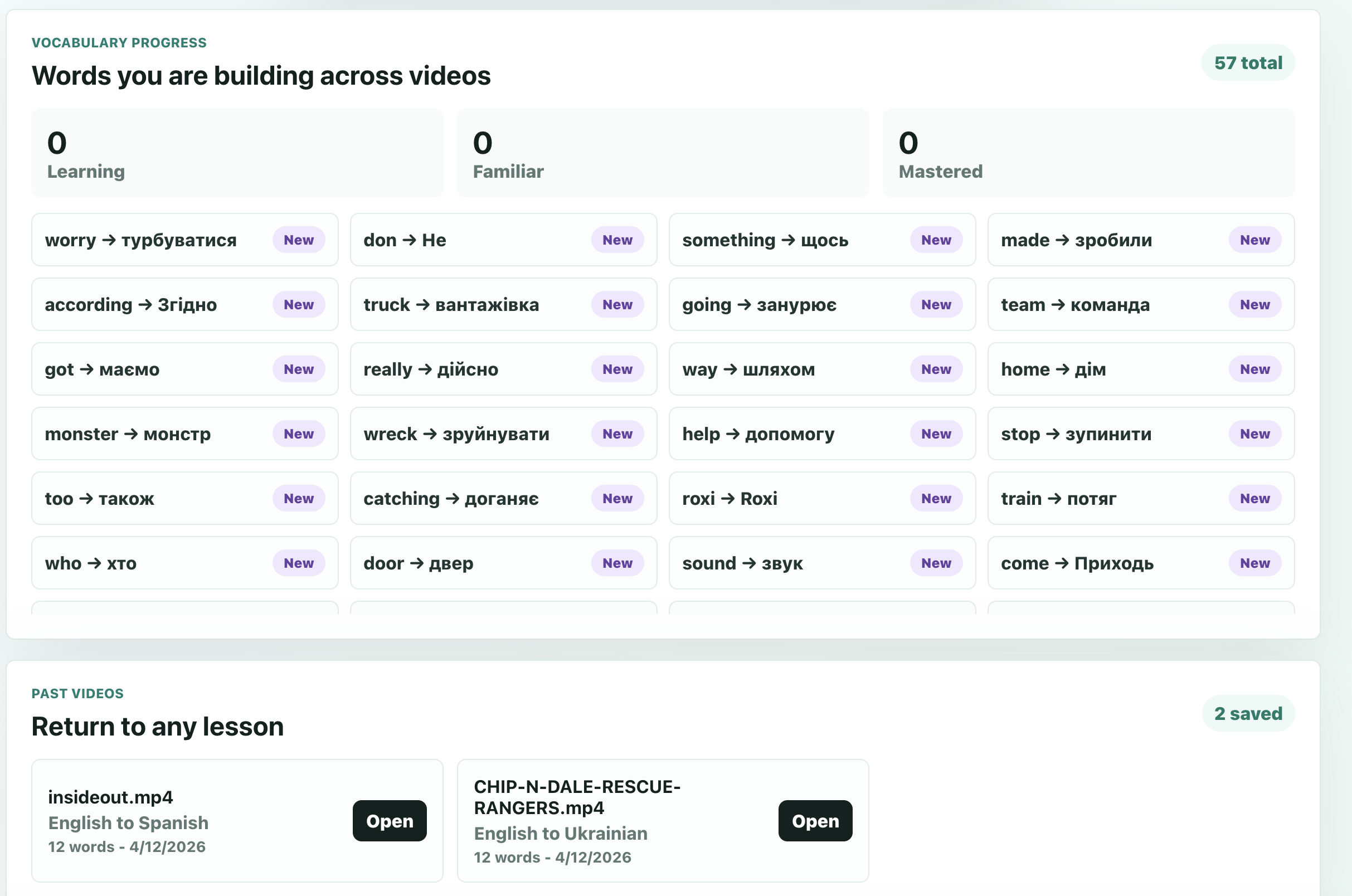
We built a word-selection pipeline that goes far beyond random substitution. It considers how recoverable a word is from context, whether the user has seen it before, how often it appears, and how useful it is overall. That lets us personalize the learning process instead of giving every user the same experience. We are also proud that the dubbed output already feels surprisingly watchable: it still feels like entertainment, not like a lesson interrupting the movie.
What we learned
We learned that preserving sentence structure matters as much as translating vocabulary. In many cases, replacing a single word inside a phrase breaks the grammar or natural flow, so it is often better to either skip the phrase or translate it as a whole. We also learned how important clean audio separation is, since mixing different speakers or tracks can quickly make the result feel unnatural.
What's next for LLTM — Learn Language Thru Movie
Next, we want to make the dubbing even smoother and more natural, improve processing speed, and expand language support carefully without sacrificing quality. We also want to test the product with real users and eventually explore integrations with streaming platforms.
Built With
- elevenlabs
- featherless.ai
- firestore
- gcloud
- mysql
- python
- typescript

Log in or sign up for Devpost to join the conversation.