-
-
-
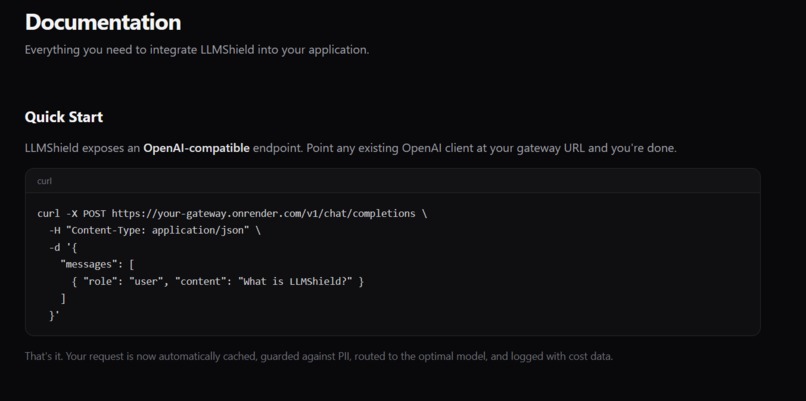
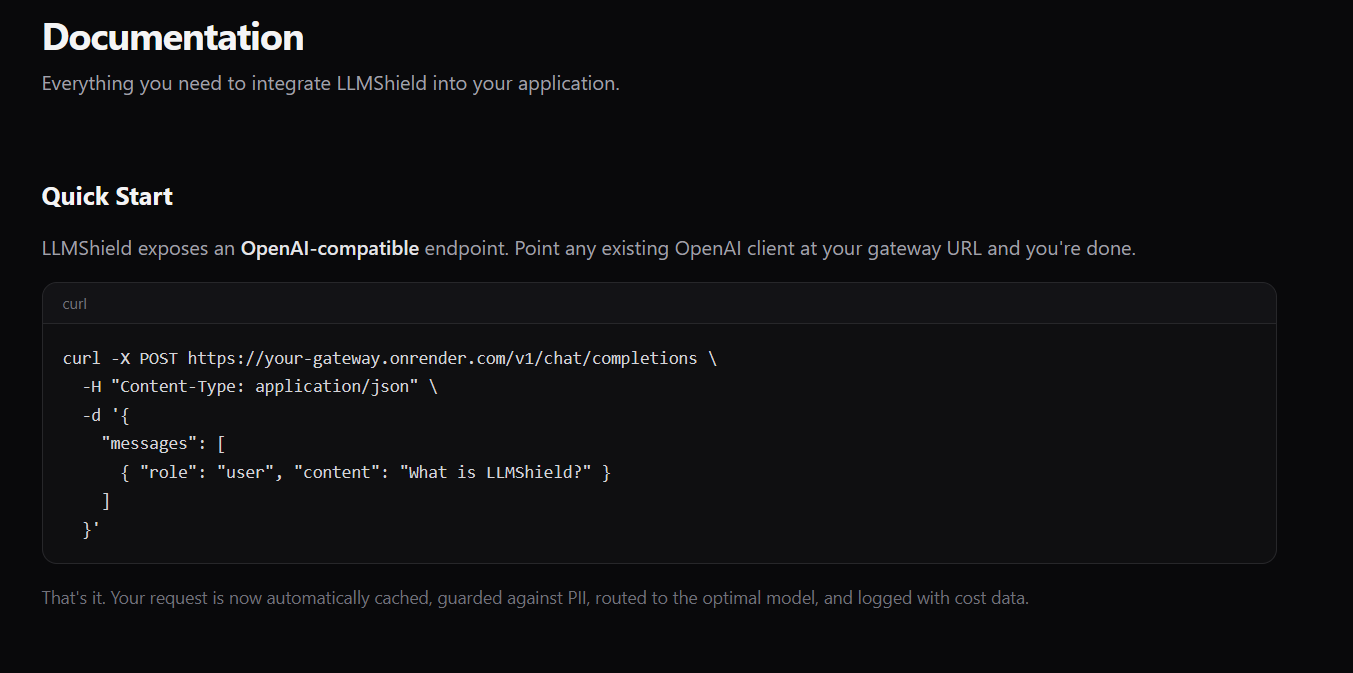
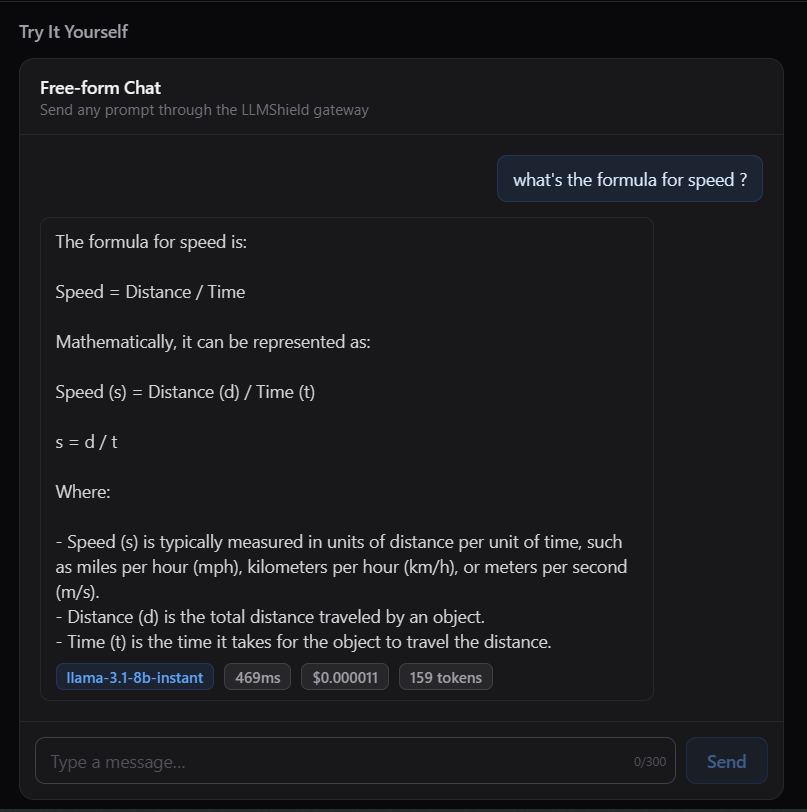
LLMShield exposes an OpenAI-compatible endpoint. Point any existing OpenAI client at your gateway URL and you're done.
-
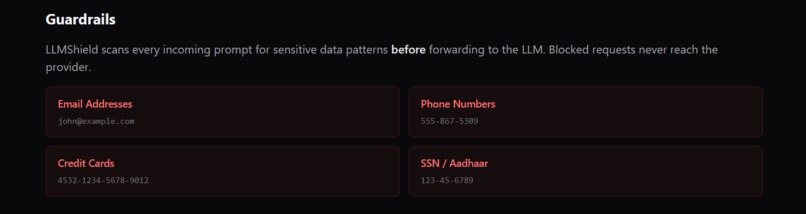
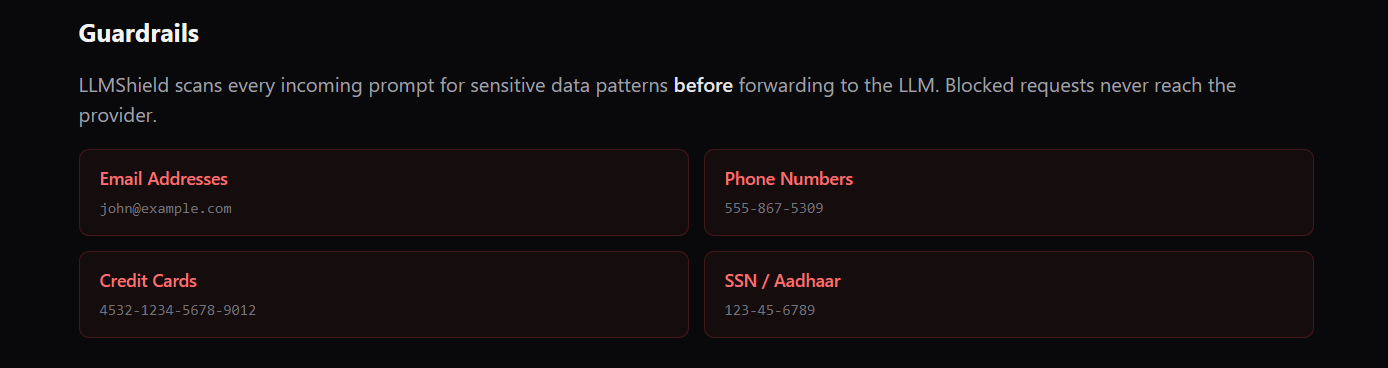
LLMShield scans every incoming prompt for sensitive data patterns before forwarding to the LLM. Blocked requests never reach the provider.
-
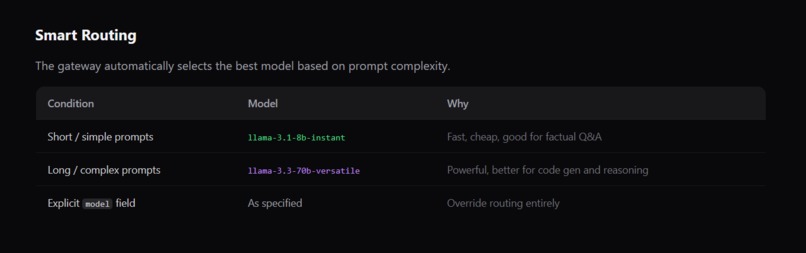
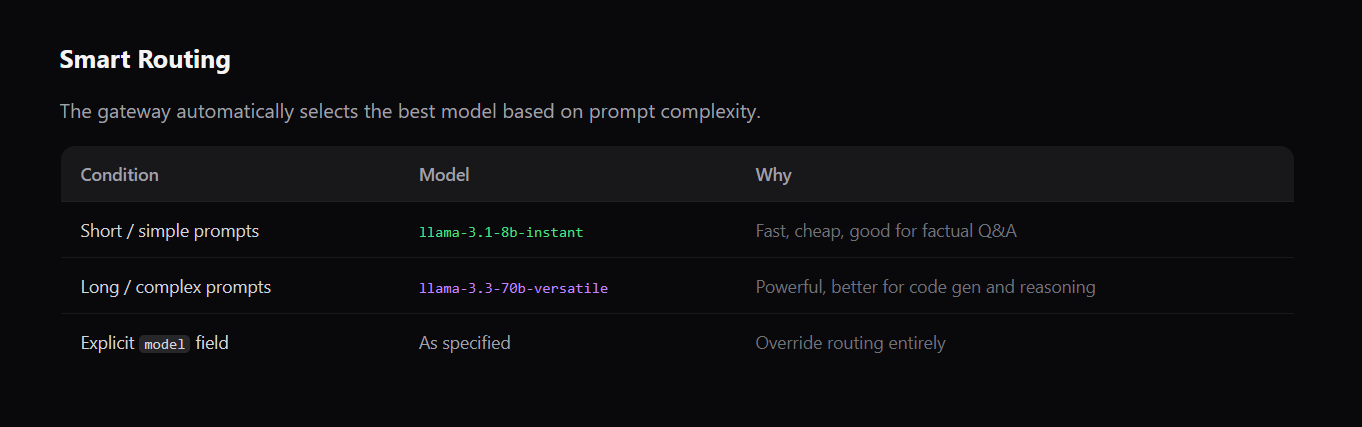
The gateway automatically selects the best model based on prompt complexity.
-

Gateway hashes normalized prompts (SHA-256); if found in Redis, returns cached response instantly with zero cost and sub-ms latency.
-
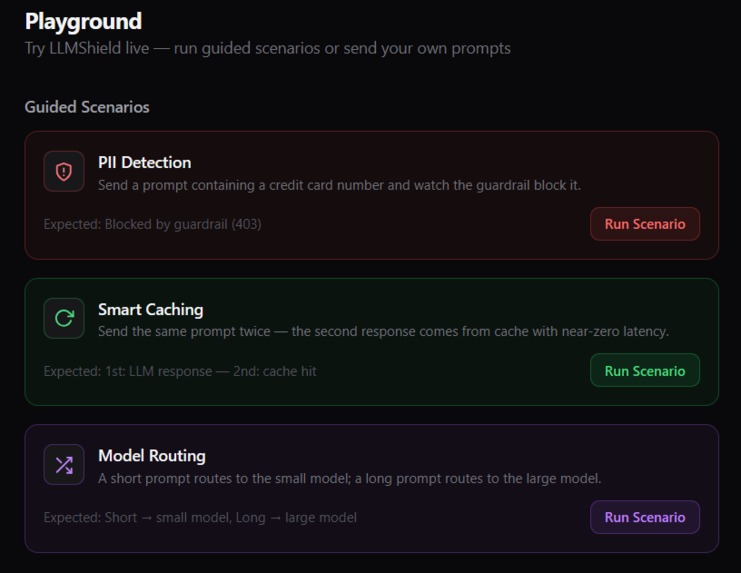
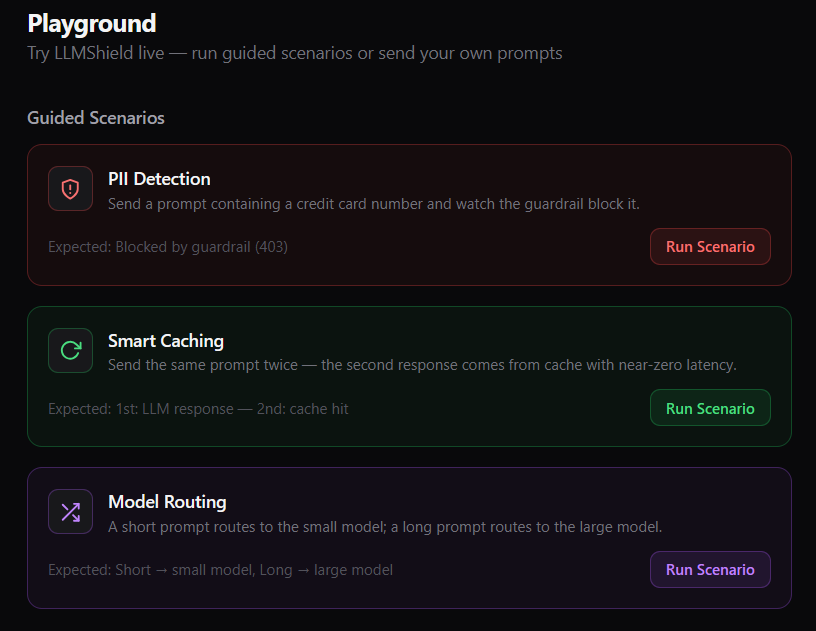
Offering an interactive playground to test and experience LLMShield’s core features in real time
-
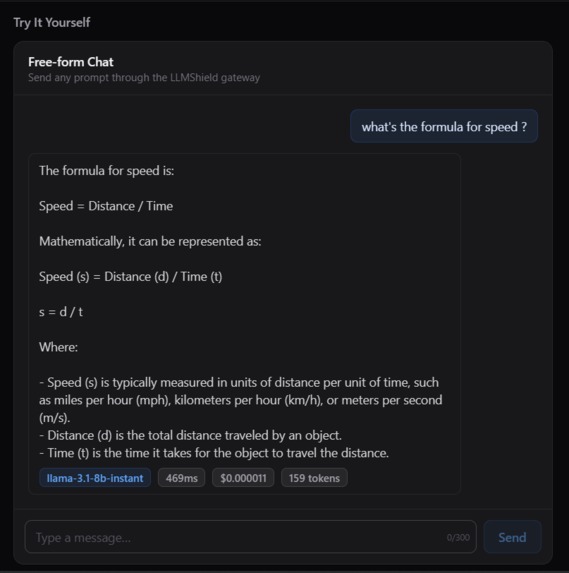
Users can send custom prompts to see how requests are secured, optimized, and routed.
-
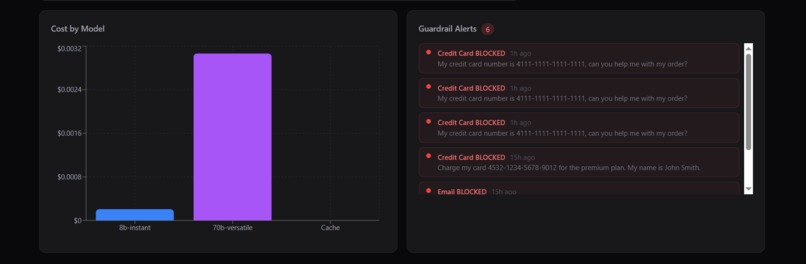
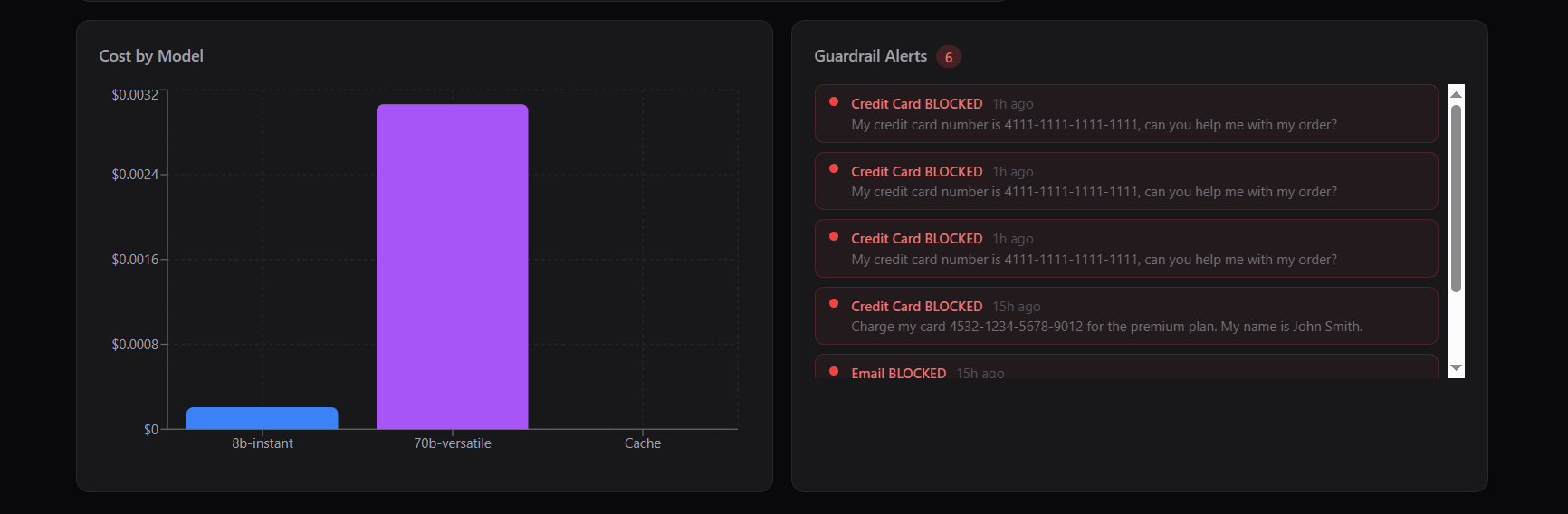
Analytics view highlighting model-wise cost breakdown and guardrail alerts, showcasing blocked PII attempts like credit cards and emails.
-
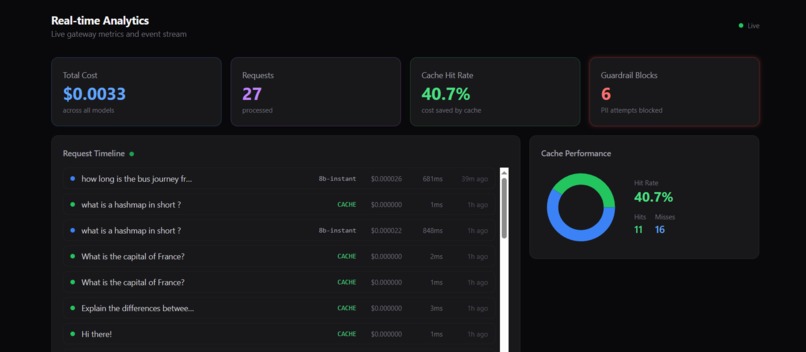
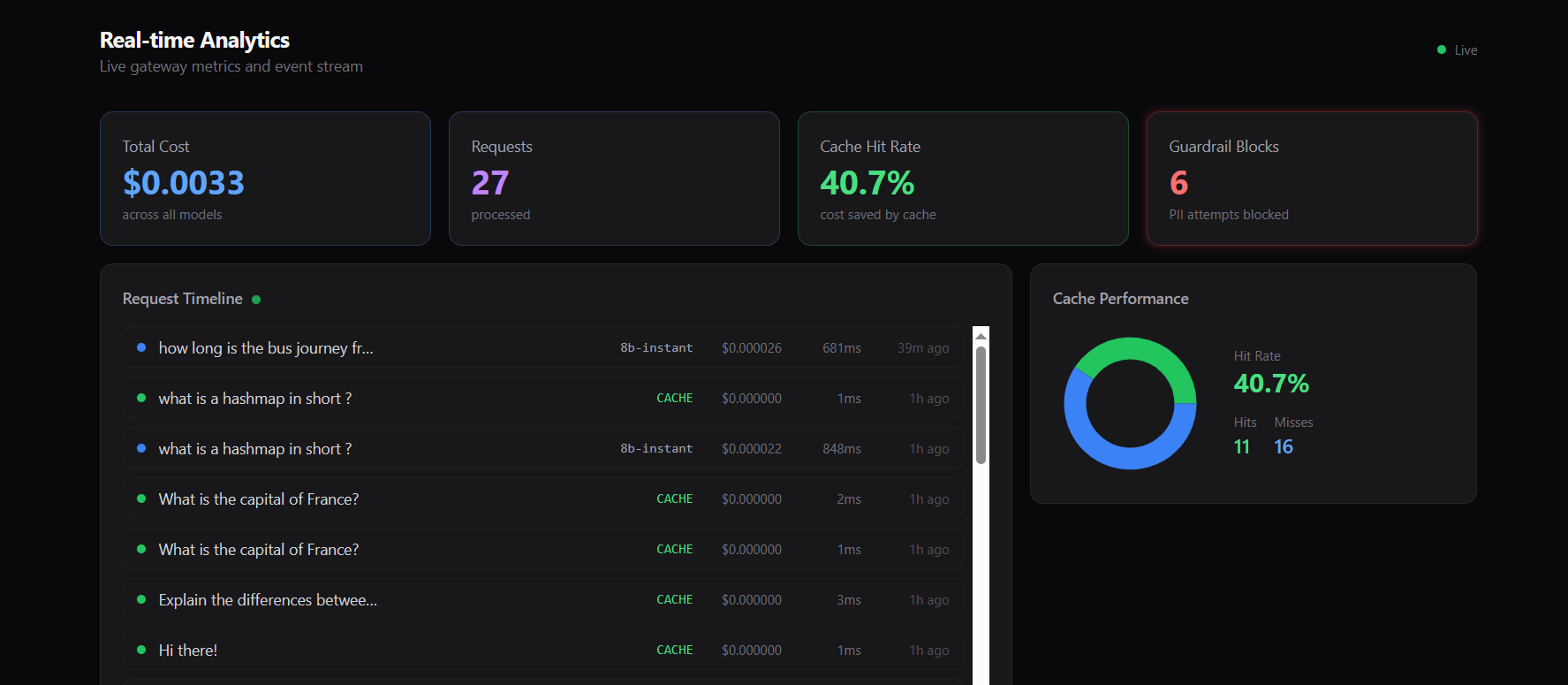
Real-time dashboard showing cost, requests, cache hit rate, and guardrail blocks with live request timeline and cache performance insights.

Inspiration
I observed a common pattern in how teams adopt LLMs , start with direct API calls, ship fast, and optimize later.
But this approach creates hidden problems. A large portion of requests are duplicates, like the same “What is the refund policy?” query hitting expensive models repeatedly. At the same time, users often paste sensitive data (credit cards, emails, phone numbers) directly into prompts, which gets sent to third-party APIs without filtering.
Existing tools solve parts of this logging, routing and analytics , but none combine cost control, caching, security, and real-time visibility in one place.
With AI API spending projected to cross $200B by 2027, it’s clear: most teams lack control and visibility over their LLM usage.
So I built LLMShield.
What it does
LLMShield is an intelligent gateway that sits between your application and any LLM provider. Think Cloudflare, but for AI API traffic. You swap one line in your code , point your SDK at our gateway instead of directly at OpenAI or Groq and you instantly get four layers of protection and optimization:
Smart Caching — Every prompt is normalized and hashed. If the same (or trivially similar) question has been asked before, the cached response is returned in under 50ms at zero cost. No LLM call needed.
PII Guardrails — Before any prompt leaves your infrastructure, it's scanned for credit card numbers, email addresses, phone numbers, and Aadhaar IDs. If PII is detected, the request is blocked with a 403 — the prompt never touches a third-party server.
Intelligent Routing — Not every question needs the most powerful model. Short, simple prompts route to fast, cheap models (8B parameters). Complex, long-form prompts route to powerful models (70B parameters). You stop overpaying for "Hi, how are you?"
Real-Time Cost Tracking — Every request is logged with exact token counts, per-token cost, model used, latency, and cache status. All of it streams live to a dashboard via WebSocket, so you see your spend in real time , not 30 days later on an invoice.
The result: teams get full control over their AI spend, full protection over their data, and full visibility into every request without changing how they build.
How we plan to build it
LLMShield is designed as a Fastify-based API gateway with an OpenAI-compatible interface , allowing seamless integration with existing applications.
Each request will pass through a middleware pipeline:
Guardrails — Detect and block sensitive data (cards, emails, phone numbers, Aadhaar) before it reaches the LLM.
Cache (Redis) — Store prompt-response pairs so duplicate queries return instantly with zero cost.
Smart Router — Route simple prompts to smaller models and complex ones to larger models to optimize cost-performance.
Cost Tracker — Log tokens, cost, latency, and metadata to a database for analysis.
Live Dashboard — Provide real-time visibility into usage, cost, cache efficiency, and security alerts.
The system is containerized using Docker, and a lightweight SDK enables one-line integration with existing apps.
Before LLMShield (Current Architecture)
Title: Today's AI Stack — No Control, No Protection
Diagram:
┌──────────────┐ ┌──────────────────┐ ┌──────────────┐
│ │ │ │ │ │
│ Your App │────────►│ LLM Provider │────────►│ Response │
│ │ │ (OpenAI / Groq) │ │ │
└──────────────┘ └──────────────────┘ └──────────────┘
No caching — every call costs money
No PII filtering — sensitive data leaks to third parties
No cost tracking — bills are a surprise at month-end
No smart routing — one model fits all (badly)
No real-time visibility — zero observability
- Direct connection = zero middleware, zero intelligence
The Solution — LLMShield Architecture
Title: LLMShield — Your Intelligent AI Gateway
Diagram:
┌──────────┐ ┌─────────────────────────────────────────┐ ┌──────────────┐
│ │ │ LLMShield Gateway │ │ │
│ Your App │──────►│ │──────►│ LLM Provider │
│ │ │ ┌───────────┐ ┌────────────────────┐ │ │ (Groq/OpenAI)│
└──────────┘ │ │ Guardrails│ │ Smart Router │ │ └──────┬───────┘
│ │ PII Block │ │ Small vs Large │ │ │
│ └───────────┘ │ model selection │ │ │
│ └────────────────────┘ │ │
│ ┌───────────┐ ┌────────────────────┐ │ │
│ │ Cache │ │ Cost Tracker │ │◄─────────────┘
│ │ (Redis) │ │ per-token pricing │ │
│ └───────────┘ └────────────────────┘ │
│ │
│ Real-time events → Socket.io → Dashboard│
└─────────────────────────────────────────┘
Cache → Duplicate prompts return instantly at $0
Guardrails → PII (emails, cards, phones) blocked before reaching LLM
Router → Short prompts → fast/cheap model, long → powerful model
Tracker → Every request logged with cost, tokens, latency
- Drop-in middleware — sits between your app and any LLM provider; OpenAI-compatible API
- Cache (Redis) — Normalized prompt hashing; identical/similar queries return cached responses at zero cost, sub-50ms latency
- Guardrails — Regex-based PII detection (credit cards, Aadhaar, emails, phone numbers); blocks before the prompt ever leaves your infrastructure
- Smart Router — Automatically selects cost-efficient model based on prompt complexity (8B for simple, 70B for complex)
- Cost Tracker — Per-token cost calculation with model-specific pricing; every request logged to PostgreSQL with full metadata
Challenges we identified
Defining “simple vs complex” prompts — Short prompts can be complex and long ones trivial. A token-based heuristic (~80% accuracy) works as a baseline; ML-based classification planned.
Cache normalization trade-offs — Over-normalization can cause collisions (e.g., similar but different queries). Favoring precision over recall; semantic caching planned.
PII false positives — Regex patterns may flag valid numeric inputs (order IDs, phone numbers). Requires careful tuning to balance accuracy and strict protection.
Latency overhead — Middleware must stay lightweight; target is <15ms added latency per request.
Accomplishments that we're proud of
Designed for significant cost reduction through caching and intelligent routing of repeated queries
Enables up to 60x faster responses on cache hits (~800ms → ~12ms)
Built with a strong PII protection layer to block sensitive data (cards, emails, phone numbers, Aadhaar) before reaching external APIs
One-line integration — drop-in replacement for OpenAI-compatible APIs with minimal changes
Designed for real-time observability — live dashboard for cost, usage, cache performance, and security insights
What we learned
Middleware is the missing layer in the AI stack. Everyone talks about models, prompts, and fine-tuning. Almost nobody talks about the infrastructure between the app and the model and that's where the biggest cost and security wins live.
Cost optimization is not just about cheaper models. Caching, deduplication, and intelligent routing together have a larger impact than switching providers. The cheapest API call is the one you never make.
Security can't be an afterthought. PII protection needs to happen at the gateway level , before data leaves your infrastructure. Post-hoc logging doesn't prevent the leak; it just documents it.
Real-time visibility changes behavior. When developers can see cost accumulating live on a dashboard, they start writing better prompts, caching more aggressively, and thinking about model selection. Observability drives optimization.
What's next for LLMShield — Cloudflare for AI APIs
Semantic Caching — Move from exact-match hashing to embedding-based similarity so semantically similar queries share cache results
Advanced Routing Engine — Evolve beyond prompt-length heuristics to smarter techniques:
- Prompt complexity classification (intent, reasoning depth)
- Token + semantic analysis (not just length)
- Historical performance-based routing (latency, cost, accuracy)
- Dynamic cost-aware routing (choose cheapest model for required quality)
Multi-Provider Failover — Automatic fallback across providers like OpenAI, Anthropic, and Groq based on availability, latency, and cost
ML-Powered Guardrails — Move beyond regex to NER-based PII detection, prompt injection defense, and toxicity filtering
Enterprise Features — Per-team budgets, global edge caching, API key management, and rate limiting
Prompt Analytics — Identify high-cost queries, frequent prompts, and risky inputs across the system
Final thought
LLMShield turns AI from a black box into a controllable, observable, and optimized system — just like Cloudflare did for the web.
Built With
- api
- docker
- fastify
- groq
- javascript
- next.js
- node.js
- postgresql
- prisma
- redis
- socket.io

Log in or sign up for Devpost to join the conversation.