LLM.evals 🌲💯
AI-Powered Requirements Engineering Evaluation
🎯 Project Overview
LLM.evals is a cutting-edge tool designed to evaluate the quality and relevance of requirements generated or extracted by Large Language Models (LLMs) in the context of Systems Engineering. Our project addresses the critical need for explainable and measurable AI outputs in the defense industry, focusing on requirements engineering.
🔬 Core Evaluation Metrics
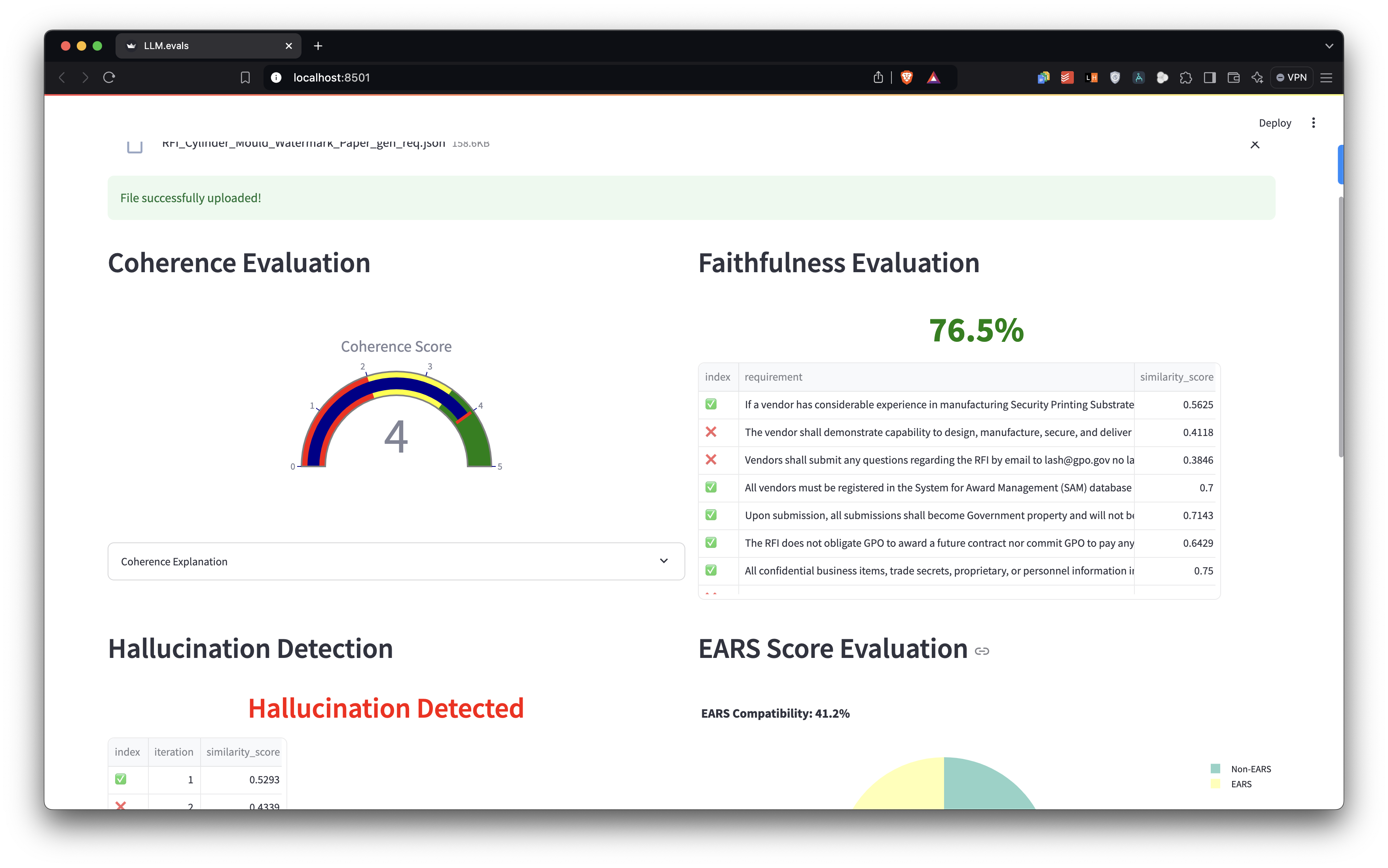
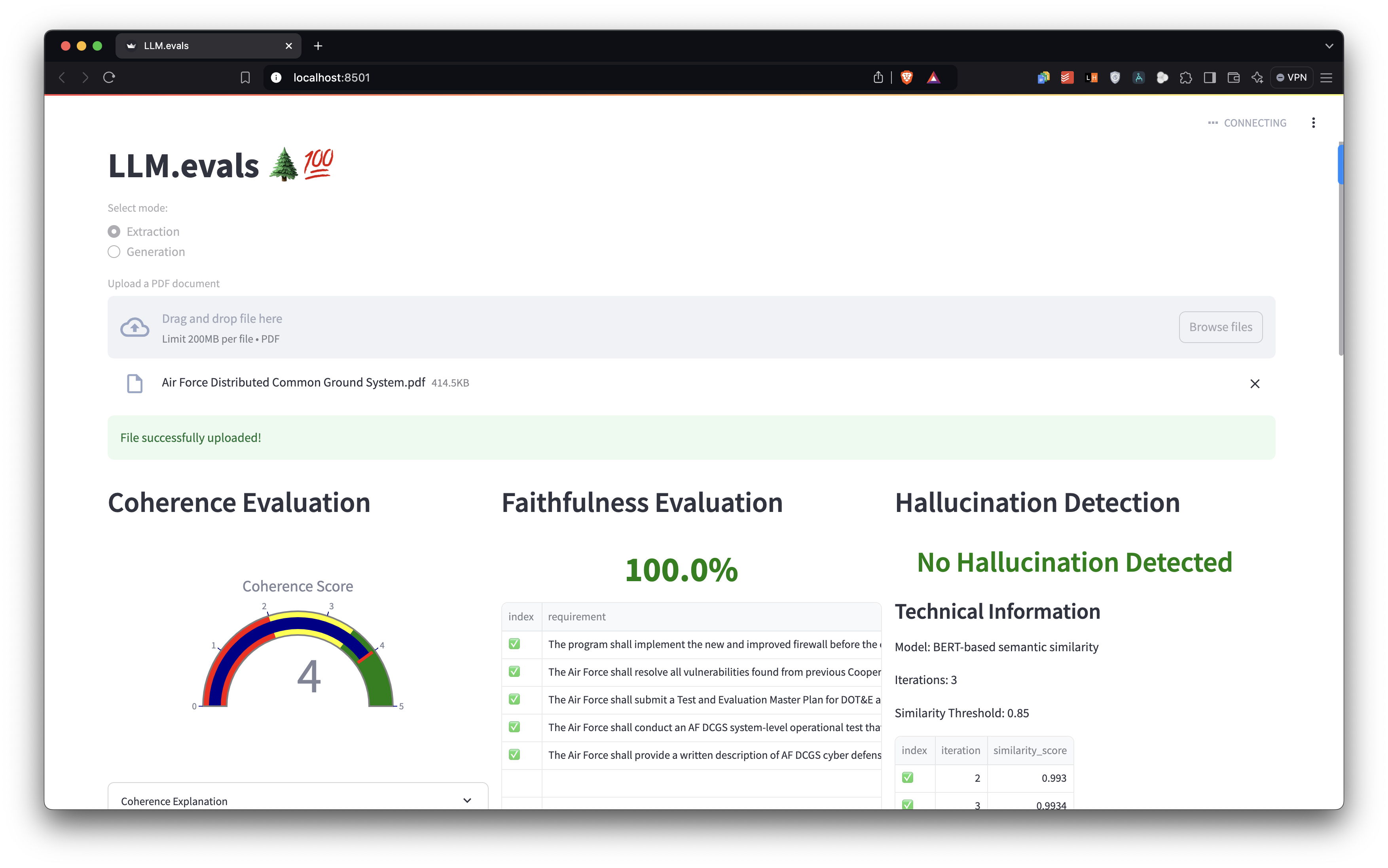
Coherence Analysis 📊
- Utilizes GPT-4 for semantic evaluation
- Scores requirements on a 1-5 scale for overall flow and relatedness
- Coherence score calculation:
C = (1/N) * Σ(w_i * s_i)where C is the coherence score, N is the number of requirements, w_i is the weight of the i-th requirement, and s_i is the individual coherence score of the i-th requirement.
Faithfulness Assessment 🔍
- Implements spaCy for Natural Language Processing
- Extracts key linguistic elements (nouns, verbs, proper nouns)
- Calculates Jaccard similarity for overlap score:
J(A,B) = |A ∩ B| / |A ∪ B|where A is the set of key elements from the source text and B is the set from the generated requirement.
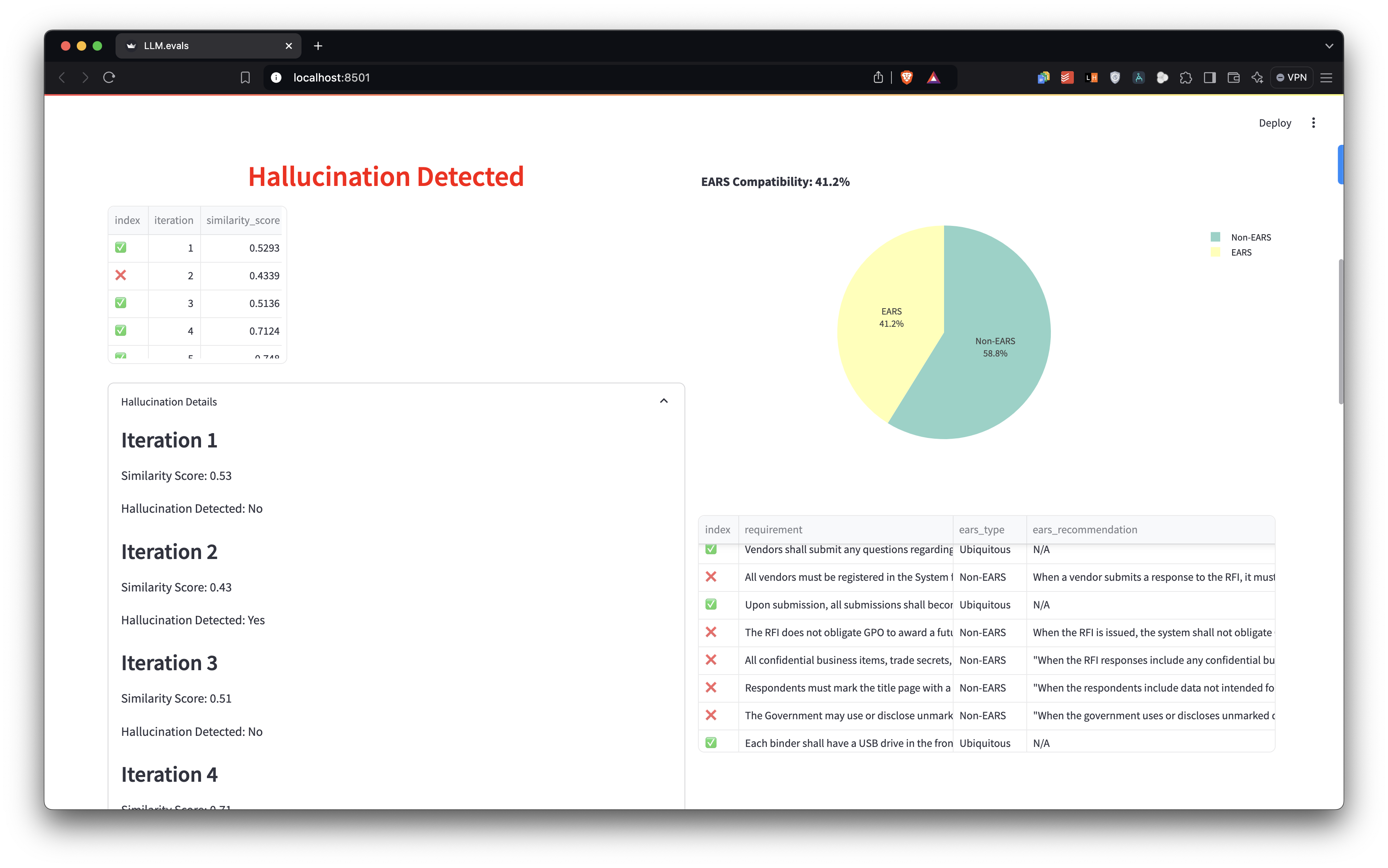
Hallucination Detection 🕵️
- Employs BERT embeddings for semantic similarity computation
- Applies cosine similarity metrics to identify potential fabrications:
similarity = cos(θ) = (A · B) / (||A|| ||B||)where A and B are the BERT embeddings of the source and generated texts. - Uses SequenceMatcher for granular text difference analysis
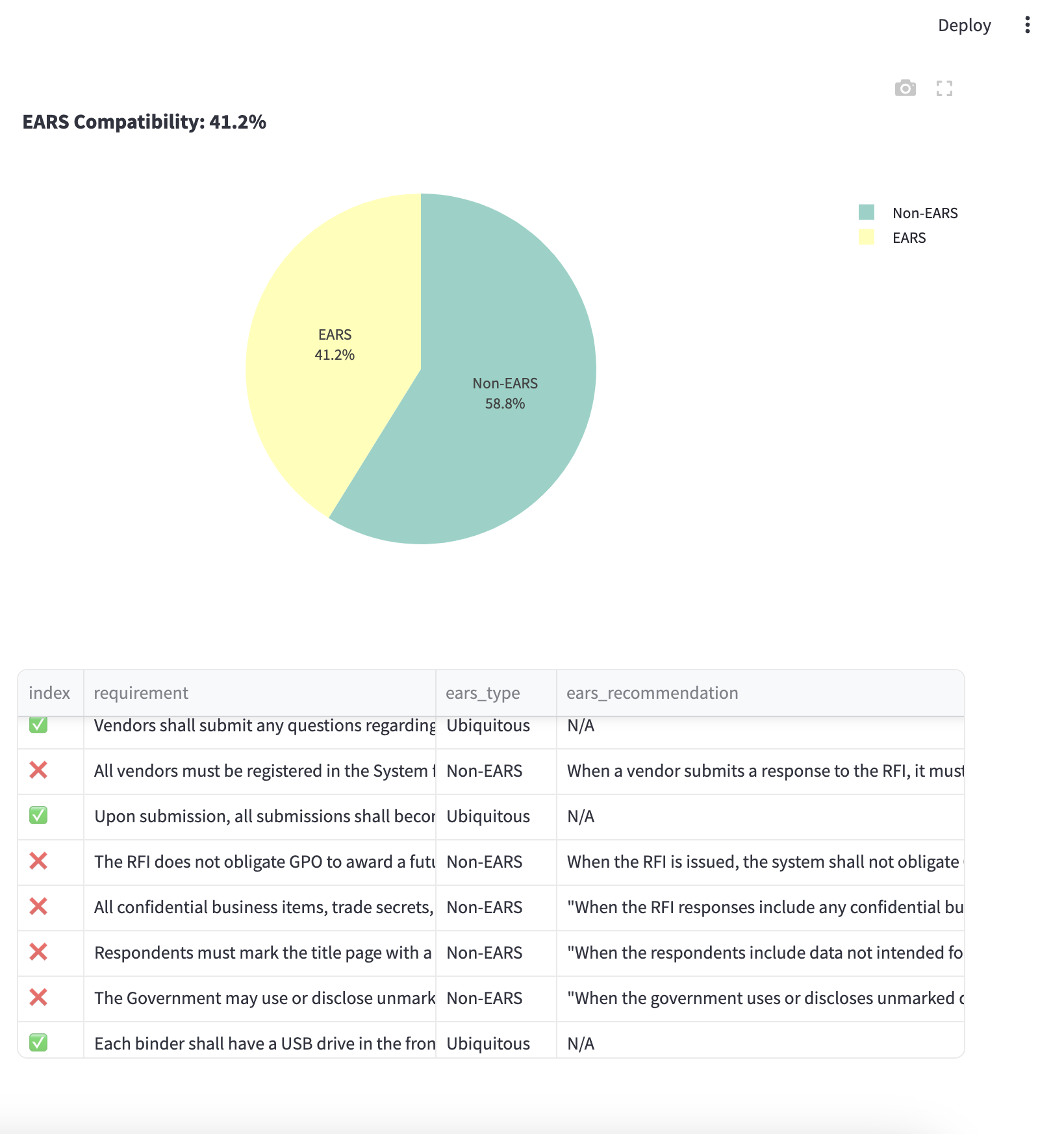
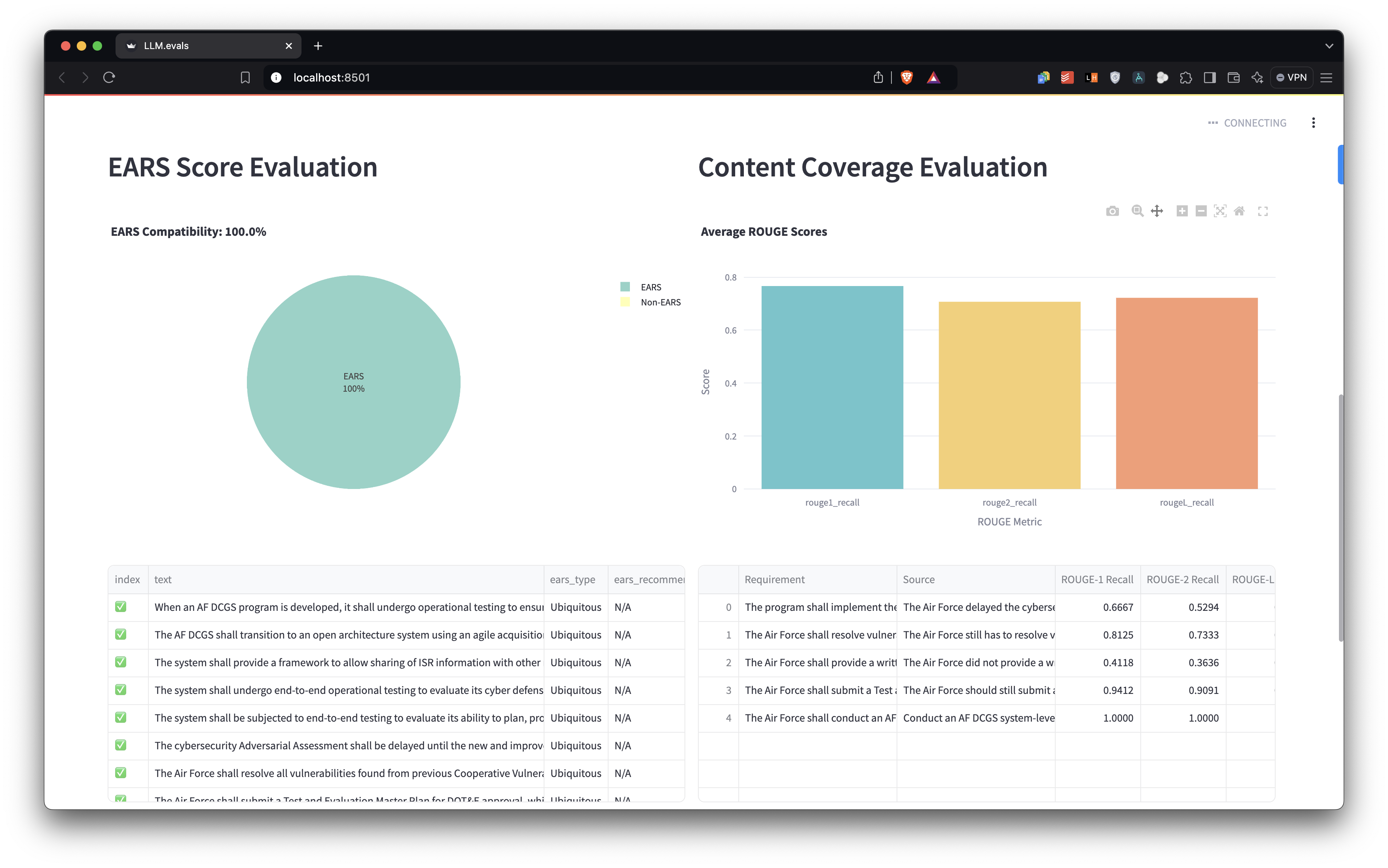
EARS (Easy Approach to Requirements Syntax) Compatibility 📏
- Implements regex pattern matching for EARS classification and recommends EARS format wherever needed
- Categories: Ubiquitous, State-Driven, Event-Driven, Optional Feature, Unwanted Behavior, Complex
- EARS Compatibility Score:
EARS_score = (N_compatible / N_total) * 100where N_compatible is the number of EARS-compatible requirements and N_total is the total number of requirements.
Content Coverage Evaluation 📄 (Extraction mode only)
- Utilizes ROUGE (Recall-Oriented Understudy for Gisting Evaluation) scores
- Calculates ROUGE-1, ROUGE-2, and ROUGE-L:
ROUGE-N = Σ(gram_n ∈ RefSum) Count_match(gram_n) / Σ(gram_n ∈ RefSum) Count(gram_n)where gram_n is an n-gram, RefSum is the reference summary, and Count_match is the maximum number of n-grams co-occurring in the candidate summary and reference summary.
Data Processing Pipeline
Document Ingestion
- Supports PDF (Extraction) and JSON (Generation) inputs
- Implements custom API for requirement extraction from PDFs
- PDF processing using PyPDF2 or pdfminer.six libraries
Text Preprocessing
- Utilizes TfidfVectorizer for text vectorization:
python from sklearn.feature_extraction.text import TfidfVectorizer vectorizer = TfidfVectorizer() tfidf_matrix = vectorizer.fit_transform(documents) - Applies custom tokenization and normalization techniques
- Implements stop word removal and lemmatization using NLTK or spaCy
- Utilizes TfidfVectorizer for text vectorization:
🚀 Future Enhancements
Advanced NLP Techniques
- Implement transformer-based models for deeper semantic analysis
- Explore few-shot learning for improved requirement classification
Expanded Input Support
- Develop modules to support additional document formats (e.g., Word, Markdown)
- Implement OCR capabilities for handling scanned documents
LLM Comparison Framework
- Develop a system to compare outputs from different LLMs
- Implement statistical analysis for performance benchmarking
Integration with SE Tools
- Create APIs for seamless integration with popular Systems Engineering tools
- Develop plugins for MBSE (Model-Based Systems Engineering) platforms
Enhanced EARS Recommendation System
- Implement machine learning models for context-aware EARS suggestions
- Develop a feedback loop system for continuous improvement of recommendations
Built With
- bert
- gpt4
- plotly
- pypdf
- scikit-learn
- spacy
- streamlit
- torch
- transformers


Log in or sign up for Devpost to join the conversation.