-
-
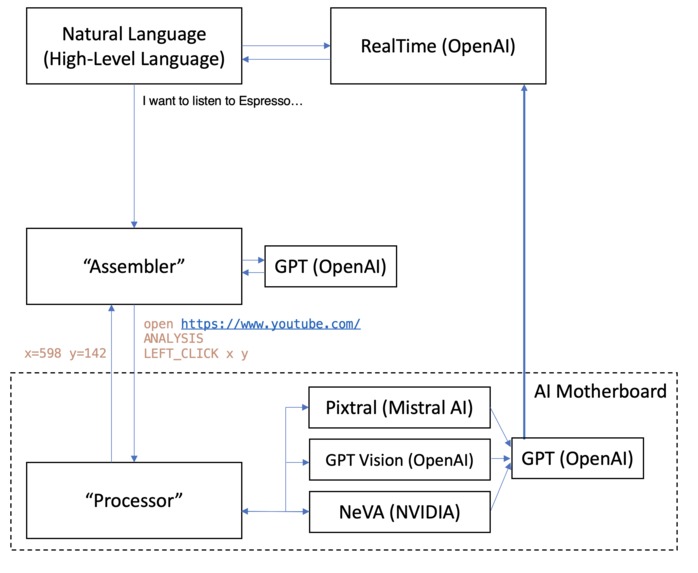
Schematic diagram of LLMaOS, featuring the 3 modular components. It highly resembles the standard computer stack, but with AI enhancements.
Inspiration
The average typing speed is 40 words per minute, which is considerably slower than the average speaking speed (150 words per minute). However, the keyboard is still the main way in which most people interact with their devices, and it has stayed that way for decades. There are existing voice applications like Siri and Alexa, but those products did not process other streams of information such as the display. I propose a voice-controlled operating system, with the entire stack (the assembler, the processor) enhanced by AI components. This should remind people of J.A.R.V.I.S. and the robots in WALL-E.
What it does
As an operating system, LLMaOS simplifies the way you interact with the computer. Below are some examples (non-exhaustive).
(1) "Play me the song Espresso"
- LLMaOS launches Chrome, enters youtube.com in the URL bar, enters Espresso in the YouTube search bar, clicks the first non-ad entry, clicks Skip Ads, enters fullscreen
(2) "What is the score between Manchester City and Real Madrid?"
- LLMaOS launches Chrome, enters google.com in the URL bar, enters "Man City vs Real Madrid" in the search bar, analyses the screen, and tells you the score.
(3) "When is the next Codeforces contest?"
- LLMaOS launches Chrome, enters codeforces.com in the URL bar, analyses the screen, and tells you the time of the next contest.
LLMaOS is voice controlled, transparent (you keep a log of its "assembly-level" instructions and can see what it is doing), and possesses screen-processing capabilities.
How we built it
There are three modular components:
User interface: This (application) layer is for voice control and is powered by OpenAI's RealTime API. In the RealTime session, user transcripts were decoded and sent to the Assembler for code generation.
Assembler: The purpose of this (operating system-compiler) layer is to generate "assembly-like" instructions for the processor. Such instructions include any non-dangerous UNIX commands, device commands (
LEFT_CLICK x y,KEYBOARD string) and the screen-processing commandANALYSIS.Processor: The processor executes the instructions generated by the assembler. For example, the special instruction
ANALYSIStakes a screenshot and uses 3 AI models (NVIDIA's NeVA, Mistral AI's Pixtral, OpenAI's GPT) in parallel (Python's asyncio) to extract information from it. The collated information is fed back to both the assembler and RealTime. This layer of LLMaOS deviates from the traditional computer architecture in the sense that instructions are generated on the fly. For example,ANALYSISon an image must be done first before determining thexandyarguments for the nextLEFT_CLICKinstruction. Much like a motherboard, the processor can offload tasks to large models' API endpoints, analogous to specialised hardware accelerators.
Challenges we ran into
The main challenge lies in image analysis. For example, it is difficult to detect a cross symbol on a high-pixel-density screen. It is also difficult to understand the texts on the screen. Due to these, models' confidence in bounding boxes sharply decreased, which made it hard for the assembler, particularly the LEFT_CLICK x y instructions. To alleviate this problem, I threw three giant models at it, but there are still failure cases. In the end, I had to hardcode some portions for demonstration purposes. (I would also have liked to use NVIDIA's ocdrnet model, but there is a tradeoff between the image sizes it supports and the clarity of texts.)
The latency and user-friendliness of the operating system are also crucial - the calls to the three API endpoints are parallelised (using Python's async). However, there is still significant latency due to image-processing the screen. The context switching between LLMaOS (especially maintaining the RealTime session) and other applications like Chrome is not very significant but still noticeable.
Accomplishments that we're proud of
Made a demo-able (though slightly hackish) prototype. Come by to try it out!
What we learned
(1) The power of abstraction and (2) connecting many layers of the computer stack together.
What's next for LLMaOS
I'll focus on improving the AI subcomponents first, by using/training better models that are specifically for this task. Then, add more features and optimisations to the LLMaOS stack.
Built With
- asyncio
- gpt
- mistralai-pixtral
- nvidia-neva
- openai-realtime

Log in or sign up for Devpost to join the conversation.