-
-
r
Inspiration
As Large Language Models (LLMs) move from chat experiments to production pipelines, they introduce a new attack surface. We realized that while everyone is focused on building AI apps, very few are focused on securing them. We saw developers blindly trusting user inputs, leading to prompt injections, data exfiltration, and PII leaks. We built LLM-Warden to be the missing "Firewall for the AI Era"—a dedicated security layer that sits between the user and the model, ensuring safety without sacrificing speed.
What it does
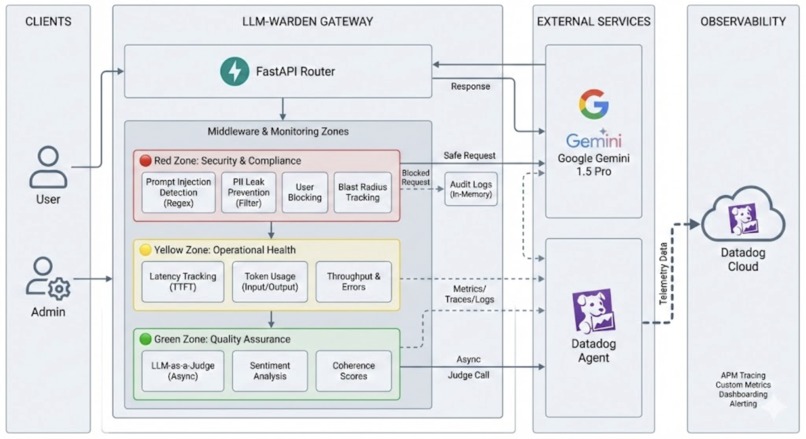
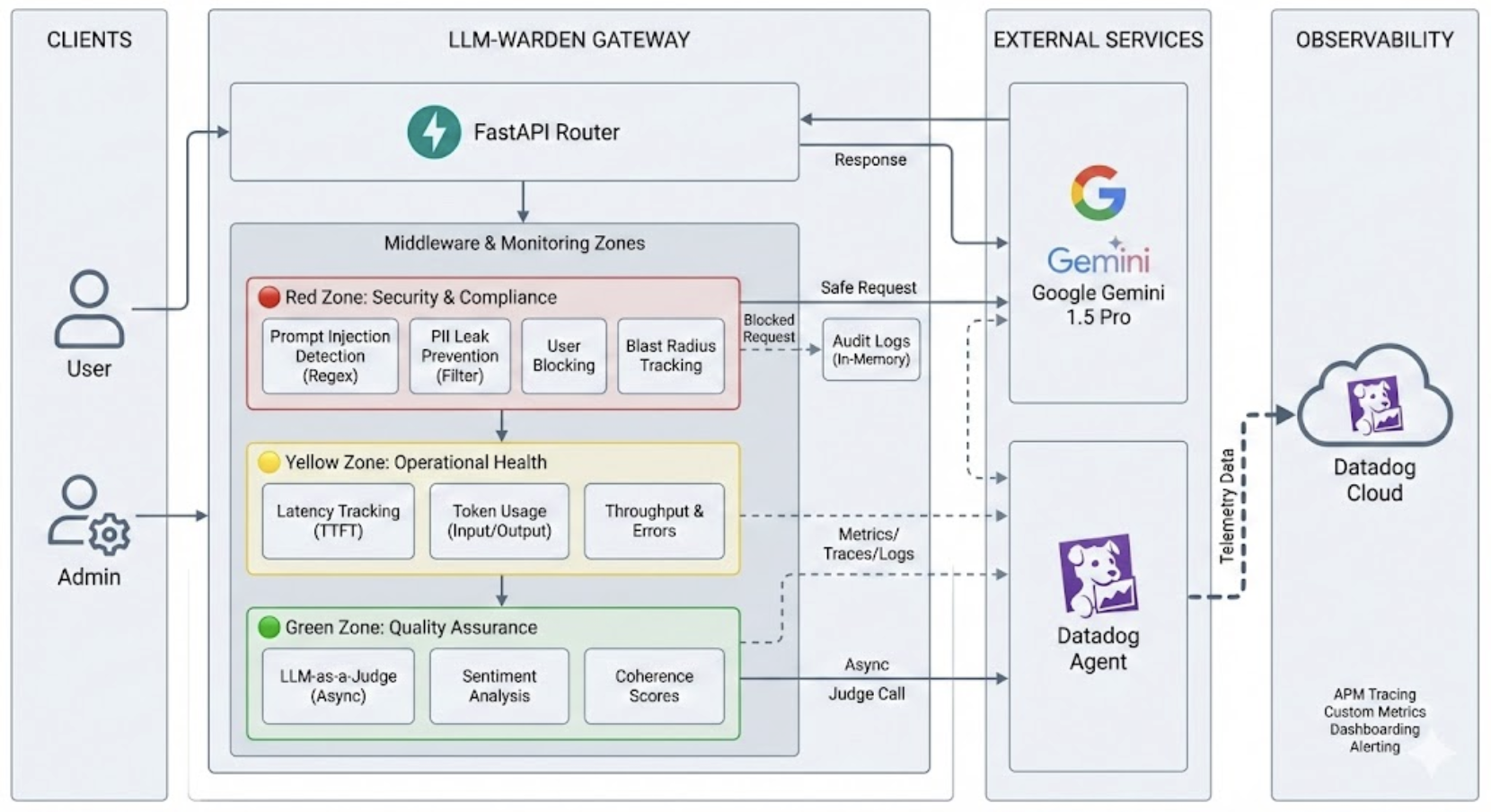
LLM-Warden is an intelligent gateway and observability platform for GenAI applications.
- Active Defense: It intercepts user queries before they reach the LLM. It detects and aggressively blocks prompt injections (e.g., "Ignore previous instructions") and PII leaks (e.g., Credit Card numbers) in real-time.
- LLM-as-a-Judge: It uses a secondary, lightweight AI model to evaluate every response for helpfulness and safety, giving you a distinct "Quality Score" for every interaction.
- Traffic Light Observability: We built a custom Datadog dashboard that categorizes traffic into three zones:
- 🔴 Red (Security): Real-time alerts on blocked attacks and attackers' IPs.
- 🟡 Yellow (Operational): Latency, token usage, and error rates.
- 🟢 Green (Quality): User sentiment and response coherence scores.
How we built it
- Backend: We used FastAPI (Python) for a high-performance, asynchronous gateway.
- AI Logic: We integrated Google Gemini 1.5 Pro as our core reasoning engine and for the "Judge" evaluation logic.
- Observability: We heavily instrumented the application using Datadog APM and DogStatsD. We used custom tags to track
user_id,attack_type, andsentimentacross every trace. - Deployment: The entire stack is containerized with Docker, using a sidecar pattern to run the Datadog Agent alongside the application for seamless metric collection.
Challenges we ran into
- Simulating Realistic traffic: Generating "fake" but realistic user traffic patterns to test our dashboard visualizations was tricky. We wrote a custom
load_test.shscript to simulate a mix of normal users, attackers, and PII leakers. - Docker Networking: Getting the application container to communicate reliable udp packets to the Datadog Agent sidecar required careful port mapping and network configuration in
docker-compose. - Latency Balancing: Adding a security layer adds latency. We had to optimize our regex patterns and "Judge" calls (moving them to background tasks) to ensure the user experience remained snappy.
Accomplishments that we're proud of
- The "Traffic Light" Dashboard: It’s incredibly satisfying to see a real-time visualization of attacks being blocked in red while normal traffic flows in green.
- Zero-Config Deployment: We managed to package a complex observability stack into a single
docker-compose upcommand. - Effective Blocking: Our system successfully catches common jailbreak attempts that would otherwise trick the raw model.
What we learned
- Observability is AI's best friend: You cannot improve what you cannot measure. Seeing token usage and latency per user changed how we thought about optimization.
- Prompt Injection is hard to solve: Regex helps, but it's cat-and-mouse. We learned that a multi-layered approach (Regex + AI Judge) is the only robust solution.
What's next for LLM-Warden
- Vector-Based Semantics: Moving beyond regex to use Vector Embeddings for detecting semantic similarity to known attacks.
- Custom Rule Engine: Allowing users to define specific "Forbidden Topics" (e.g., competitors, legal advice) via a UI.
- Multi-Model Support: Adding support for Claude and GPT-4 to make LLM-Warden a universal gateway.


Log in or sign up for Devpost to join the conversation.