Measuring saturated hydraulic conductivity (Ksat) in soil is essential for hydrological modeling, irrigation planning, and environmental management — but field or lab measurements are often costly, slow, and inconsistent. We were inspired to explore how machine learning could help predict Ksat using already available soil properties, making this process faster and more accessible for researchers and practitioners.
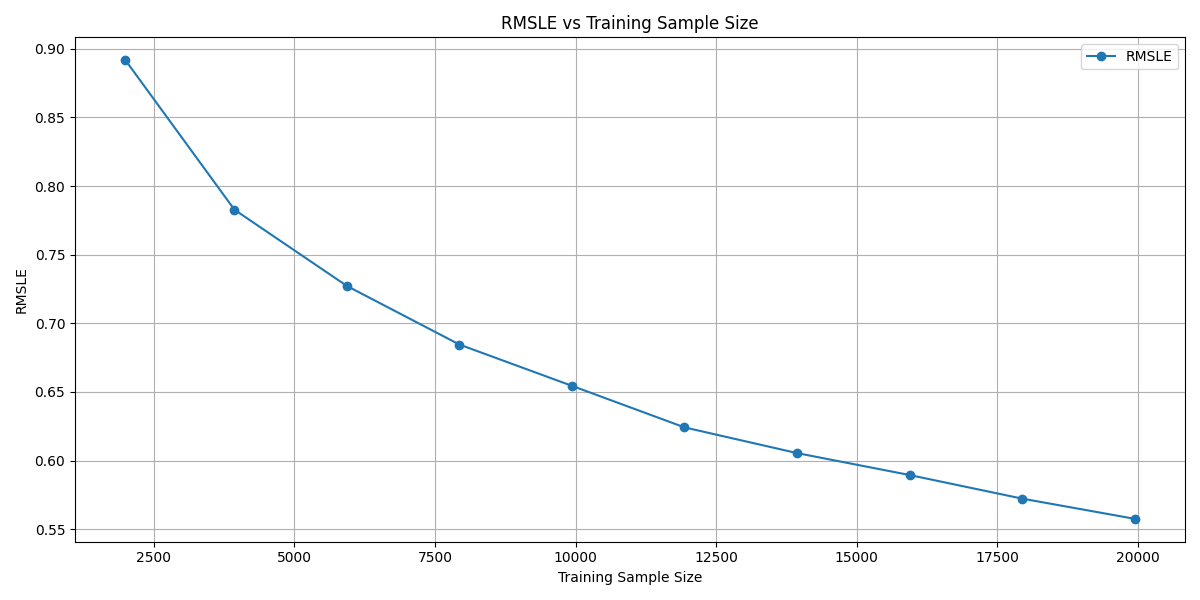
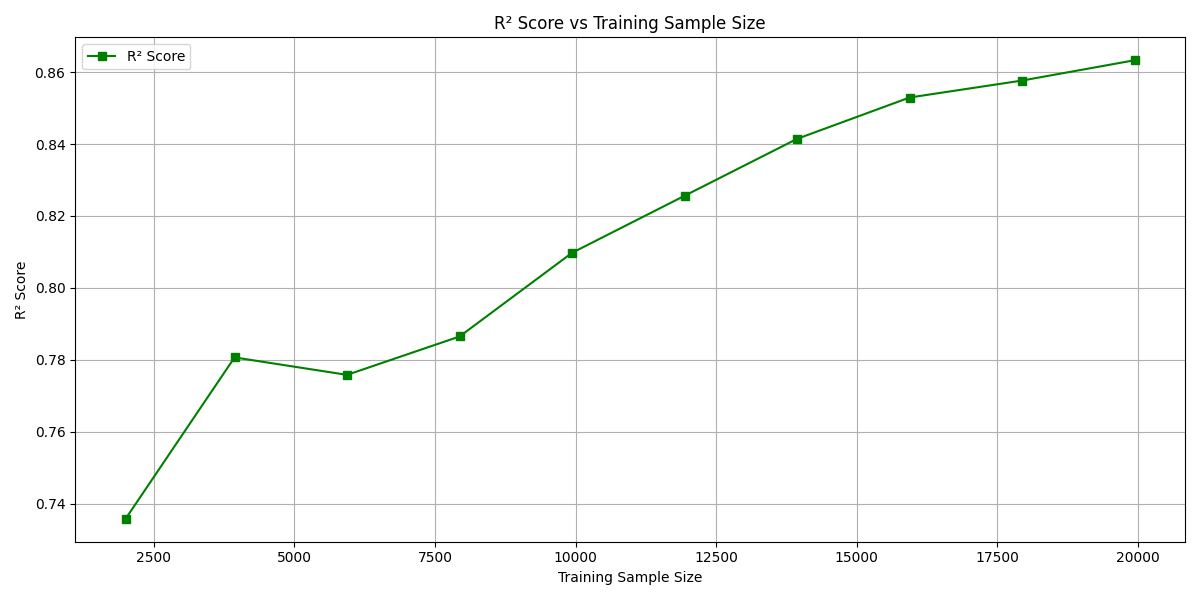
This project uses a Random Forest model to predict Ksat based on soil physical characteristics (e.g., bulk density, sand, silt, clay, organic carbon) and categorical features (e.g., textural class, field/lab source, measurement method). We also conducted a subset size experiment, testing how model performance changes as the amount of training data is reduced — helping us understand the data-efficiency of our model.
We cleaned and merged multiple Excel sheets, standardized Ksat units to cm/hr, handled missing values with imputation, and one-hot encoded categorical features. We trained a Random Forest using an 80/20 split and 5-fold cross-validated grid search for tuning. To evaluate data efficiency, we ran the model on random subsets (from 20,000 to 2,000 samples), repeating each size 50 times and tracked R² and RMSLE metrics to visualize performance trends.
Challenges we ran into
Cleaning and aligning many Excel sheets with different formats
Standardizing units from various sources (e.g., cm/hr, mm/h, in/hr, um/s)
Ensuring consistency during subset sampling and feature encoding
Keeping model training efficient despite running 1000+ experiments
We successfully built a robust machine learning pipeline capable of predicting Ksat with an R² score of up to 0.75. One of our key accomplishments was demonstrating that Random Forest maintains strong performance even when trained on smaller datasets. Through our subset experiments, we gained valuable insights into how training size impacts model accuracy. Additionally, we streamlined the entire data preprocessing and hyperparameter tuning workflow into a repeatable and efficient process that can be reused or scaled for future applications.
We discovered the true power of Random Forest for environmental regression tasks and the critical role of cross-validation in building trustable models. Subset experiments revealed how data volume shapes performance, while RMSLE taught us to respect the scale of our target. Most importantly, we learned that smart preprocessing isn’t just preparation — it’s the foundation of great predictions.
Next, we plan to integrate LLM-powered explanations to help users understand which features most influence Ksat predictions. We'll also experiment with alternative models like CatBoost and hybrid deep learning approaches. Adding spatial data—such as GPS coordinates, elevation, and climate zones—could further boost accuracy. Our goal is to package the model into a user-friendly web tool or API for researchers and practitioners, and eventually scale up to global datasets sourced from soil surveys and satellite imagery.
Built With
- jupyter
- python
- vscode





Log in or sign up for Devpost to join the conversation.