-
-
PRX Something LOL
LLM to Radiant — Devpost Submission
Inspiration
I use AI all the time to find information quickly when I’m doing schoolwork. Sometimes you have a very specific question and you don’t want to spend 20 minutes digging through documentation, watching tutorials, or scrolling forum posts. You just want a quick, grounded answer that points you to exactly what you need.
I wanted to build that same experience for VALORANT esports coaching.
Coaches and players spend hours reviewing VODs, digging through match stats, and trying to answer questions like: “should we force buy here?” or “how do pros handle 2v3 post-plants on Bind?” These are highly specific tactical questions, and the answers are buried across thousands of hours of pro match footage and data.
The idea was simple: what if you could just ask and get an answer grounded in real professional play, with citations to specific rounds and matches you can review?
What it does
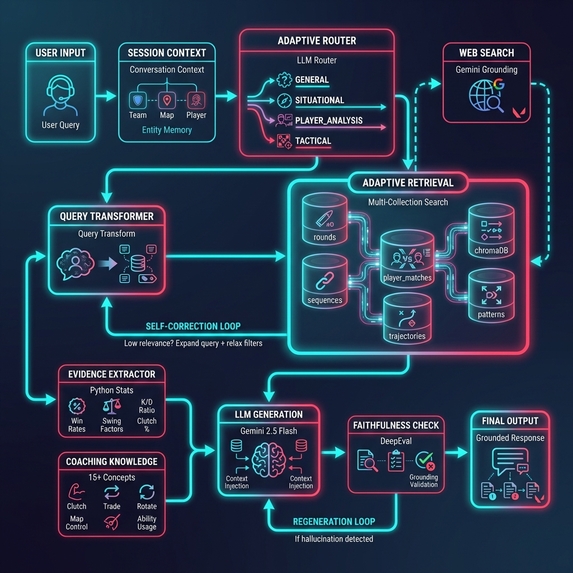
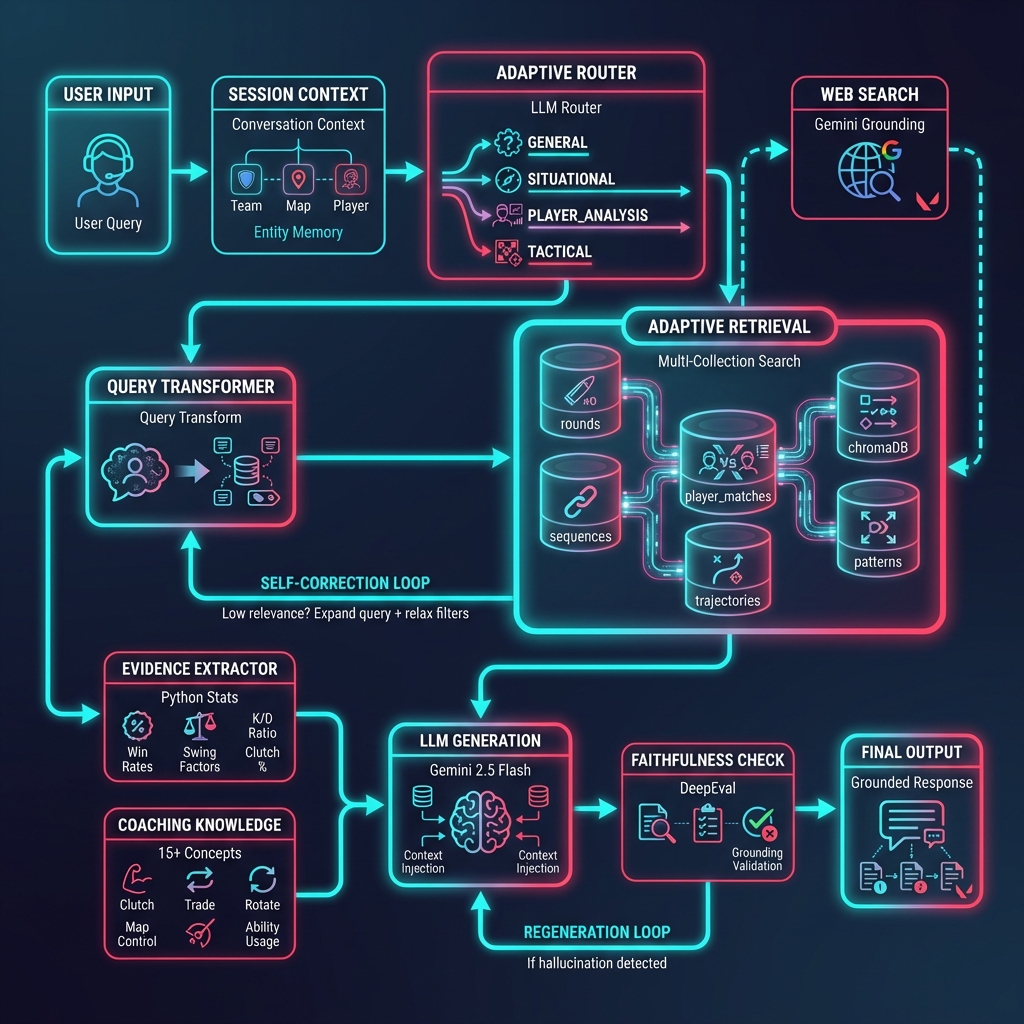
LLM to Radiant is an AI-powered coaching assistant that answers tactical VALORANT questions by grounding responses in actual professional match data. Unlike generic AI assistants that give theoretical advice, this system retrieves relevant information from a database of 11,000+ embedded pro match rounds and synthesizes responses based on what actually happened in competitive play.
When you ask something like “How should I play 2v3 clutches on defense?”, the system doesn’t generate generic advice. Instead, it:
- Routes your query to determine what kind of question it is (player analysis, round analysis, tactical advice, economy decisions, etc.)
- Transforms the query into data-aligned search terms (turning “clutch tips” into something like “2v3 post-plant defender retake”)
- Retrieves relevant rounds from multiple ChromaDB collections (rounds, player stats, event sequences, tactical patterns)
- Computes actual statistics in Python (win rates, swing factors, K/D splits) instead of letting the LLM invent numbers
- Generates a grounded response with citations to specific matches/rounds (e.g., “VCT Americas: 100T vs EG — Round 10 on Corrode…”)
- Validates for faithfulness—if the model makes claims not supported by retrieved evidence, the system regenerates with stricter constraints
It also supports:
- Multi-turn conversations that remember context (team, map, player) across messages
- Live game mode for real-time coaching during matches
- What-if analysis (e.g., “What if we saved instead of forcing?”) by pulling historical outcomes from similar situations
How we built it
Development was done primarily in PyCharm, using Junie (the AI agent) for AI-assisted coding, and alternating with Claude for design discussions, debugging, and iterating on the RAG architecture.
Tech Stack
- LLM: Gemini 2.5 Flash (Vertex AI)
- Embeddings: Vertex AI
text-embedding-004(768 dimensions) - Vector Store: ChromaDB with persistent local storage (5 collections: rounds, sequences, players, patterns, trajectories)
- Backend: Python 3.10+ with FastAPI
- Frontend: Vanilla JavaScript (dark, VALORANT-inspired UI)
- Data Source: GRID Esports API (professional match data)
Pipeline Session Context → Query Routing → Query Transformation → (Optional Web Search) → Adaptive Retrieval → Evidence Extraction → LLM Generation → Faithfulness Check
Each stage is designed to maximize both relevance and groundedness.
Challenges we ran into
1) Data-query mismatch (keyword brittleness)
One of the biggest problems was getting user language to match what exists in the data. If someone asks about “half buys” but the dataset labels it as bonus_or_eco, retrieval can fail. Typos and slang make this worse (“retake tipz” vs “retake strategy”).
We added fuzzy matching (difflib), synonym expansion, and LLM-based query transformation to bridge the gap—but vocabulary mismatch is still an ongoing challenge.
2) Data enrichment
The raw GRID data has match events, but not the tactical annotations needed for coaching. We built an enrichment pipeline that:
- parses kill sequences to detect trades (e.g., traded within 5 seconds)
- detects clutch situations from player-count timelines (5v5 → 1v3, etc.)
- classifies economy types (pistol, eco, force, full buy)
- identifies sites/zones/map positions
- extracts first blood impact and post-plant scenarios
Without enrichment, embeddings were basically just event logs—hard to retrieve and not very “coachable.”
3) Hallucinated statistics
Early versions had the LLM confidently inventing numbers (“force after pistol loss wins 62% of the time”). We fixed this by computing all statistics in Python before the LLM sees them, then injecting them as evidence that must be cited verbatim. The LLM is not allowed to invent numbers.
Accomplishments that we’re proud of
This is my first fully working RAG system built end-to-end—from ingestion and enrichment, through embedding + vector storage, to retrieval, evidence extraction, grounded generation, and faithfulness checking.
Also: I managed to use my free Vertex AI credits perfectly… they expired on the last day of the hackathon 😅
Current system includes:
- 11,296 enriched rounds indexed with tactical metadata
- conversation memory that tracks entities (team/map/player) across turns
- self-correcting retrieval that expands queries when initial results are low-relevance
- faithfulness checking that catches hallucinations and forces regeneration
What we learned
RAG can only be as good as your data
We initially thought a good LLM + retrieval would solve everything. In practice, response quality is dominated by data quality. If the data doesn’t include explicit labels for clutch outcomes, economy types, and tactical events, the system can’t reliably retrieve what it needs—and the LLM starts guessing.
Data cleaning / feature engineering matters more than model choice
We spent far more time on enrichment (parsing events, detecting trades, labeling clutches) than on prompt tweaks. Richer metadata → better retrieval → more grounded answers.
Keyword brittleness is a real problem
Embeddings help, but they don’t fully solve slang vs structured labels. Explicit synonym mapping and fallbacks (fuzzy/BM25-style matching) are still necessary.
What’s next
- Label more tactical concepts: utility usage (smoke placements, flash timings), rotation patterns, executes, defensive setups
- Add live VOD playback: link citations to timestamped video clips so coaches can instantly watch the cited rounds
- Improve responses: more depth, cleaner formatting, more concrete examples (player names + timestamps)
- Better economy classification: distinguish half-buy vs thrifty vs bonus vs true save (instead of lumping)
- Agent-specific coaching: deeper advice per agent role, matchups, and ability usage
- Scrimmage mode: allow users to upload their own match data for personalized coaching on their gameplay
If you want, paste your Devpost “Built With” tags list and I’ll format them exactly how Devpost displays them (so it looks clean and consistent).

Log in or sign up for Devpost to join the conversation.