-
-
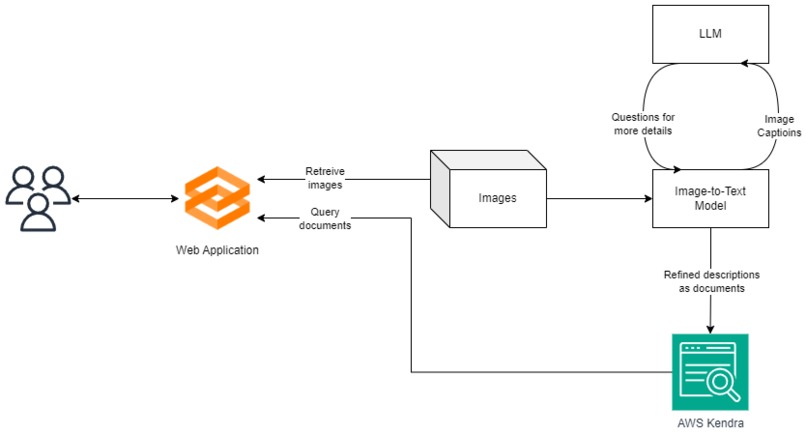
architecture
-

auto-spotter-logo
-

illustration


Inspiration

We accumulate an increasing number of photos each day, posing a challenge for individuals and companies to efficiently retrieve relevant ones from this vast pool. While services like Google Photos offer semantic image search functions, their semantic understanding of images is limited. The effectiveness of the search heavily relies on the clarity and specificity of the query, as well as the accuracy of the image tags associated with the photos in the user's library.
In this project, we aim to address this challenge by developing a solution that automatically generates detailed descriptions for photos. Leveraging recent advances in image-to-text and large language models, our system aims to enhance the semantic understanding of images, facilitating more accurate and comprehensive searches for users.
What it does
The system allows user to quickly search through a given image pool using natural language queries. An experiment is conducted using the Coco 2017 validation dataset, which contains 5000 images in total. A Gradio-based web application is built as the user interface. Users can type in the query sentences like "a women carrying a backpack in a bus", the application will return a list of relevant photos matching the query. The more detail the user provides, the more likely the ideal target is pushed to the top of the list.
How we built it
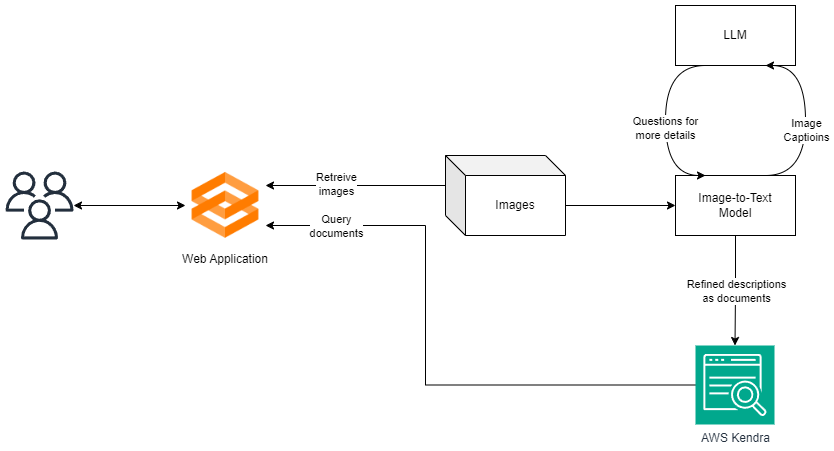 Initially, we leverage the cutting-edge Llava model (llava-v1.5-13b) to produce descriptive captions for each image within the dataset. Llava excels at crafting high-level image descriptions, although it may omit specific details during the generation process. Rather than exhaustively seeking an optimal prompt template to maximize detail inclusion in the Llava response, we employ the Language Model (LLM) as an image descriptor. Subsequently, we generate additional inquiries based on the Llava description. The LLM's directive is to scrutinize the original description for certain details and generate questions only if these particulars are absent. The checklist encompasses:
Initially, we leverage the cutting-edge Llava model (llava-v1.5-13b) to produce descriptive captions for each image within the dataset. Llava excels at crafting high-level image descriptions, although it may omit specific details during the generation process. Rather than exhaustively seeking an optimal prompt template to maximize detail inclusion in the Llava response, we employ the Language Model (LLM) as an image descriptor. Subsequently, we generate additional inquiries based on the Llava description. The LLM's directive is to scrutinize the original description for certain details and generate questions only if these particulars are absent. The checklist encompasses:
- Geographical context: Where the photo is taken, including continents, countries, cities, and whether it is indoors or outdoors.
- Temporal details: When the photo was taken, distinguishing between day and night, as well as seasonal attributes.
- Captured moment: Identifying the specific moment or scenario depicted in the photo.
- Object properties: Describing colors, shapes, and distinctive features of mentioned objects.
- People attributes: Noting details such as attire, ethnicities, and age groups.
- Flora and fauna characteristics: Specifying species and breeds of animals and plants.
The questions generated by the LLM are then submitted to Llava to obtain corresponding answers. These answers, combined with the initial round of descriptions, collectively form documents representing the content of each image.
Subsequently, a document search engine is developed using AWS Kendra. When users submit queries to the system, the backend conducts searches within the documents, identifies the most relevant matches, and returns the associated images as references to the users.
The following picture shows an example of how LLM generated questions help to collect more detail from the images.

The advantage of our approach is: As the LLM dynamically generates questions in the second round based on the original description, there is no need for an exhaustive pre-definition of a question list. This streamlined approach significantly simplifies the automation of the entire pre-processing phase.
Challenges we ran into
Initially, we attempted to utilize vector stores such as Pinecone and Chroma as the search engine. However, we encountered issues with the accuracy of the returned results, possibly attributed to the brevity of our standard queries. Subsequently, we transitioned to Kendra for document search, where the result ranking proved to be more satisfactory.
Llava occasionally experiences hallucinations. Through a series of experiments, we discovered that employing a temperature of 0 and shortening the output length somewhat alleviates this issue. However, addressing hallucination remains an ongoing challenge.
During the course of this project, GPT-4V was released. Although we aspired to leverage this advanced model for enhanced image descriptions, the prohibitive cost became a hurdle, particularly considering the substantial volume of images requiring processing. Nonetheless, this challenge underscored the cost-effectiveness of a self-managed Llava+LLM solution, requiring just one GPU.
Accomplishments that we're proud of
We take pride in establishing a pipeline for the automated generation of image captions, aimed at enhancing image retrieval performance. Our approach presents a cost-effective solution suitable for both personal and enterprise applications.
What we learned
The synergy between multimodal models and LLM enhances the depth and richness of AI-driven experiences. The recent strides in those models have ushered in a myriad of opportunities to implement sophisticated AI use cases. It not only signify technological progress but also unlock the potential for a more interconnected and intelligent future.
What's next for Auto Spotter
Enhance the auto-inquiry generation process by moving beyond the current one-time generation approach. Consider adopting an iterative methodology where questions are generated and answered incrementally. This iterative framework allows for a step-by-step refinement, leveraging answers from earlier steps as valuable context to generate more precise and informed questions. By embracing this iterative strategy, the system can dynamically adapt and optimize the quality of inquiries throughout the generation process.
Validate the efficacy of the solution across diverse industrial domains. While the Coco dataset primarily comprises lifestyle photos, it is essential to explore the adaptability of this solution in industrial settings. Specifically, conduct tests to evaluate its performance in scenarios such as retrieving photos for asset management or site inspections.
Include more metadata to enhance the search performance. We have done some preliminary experiments with face clustering during the hackathon and will continue to explore other type of data.
Built With
- amazon-web-services
- databricks
- ec2
- gradio
- kendra
- llava
- llm
- pinecone
- python

Log in or sign up for Devpost to join the conversation.