-
-
Usher-In
Inspiration
We built this because LLM integration is currently a "black box" for developers. Most teams have zero real-time visibility into why a Gemini request is slow or how many tokens are being burned per user session. We wanted to transform Gemini 2.5 Pro from a blind API call into a production-monitored asset.
What it does
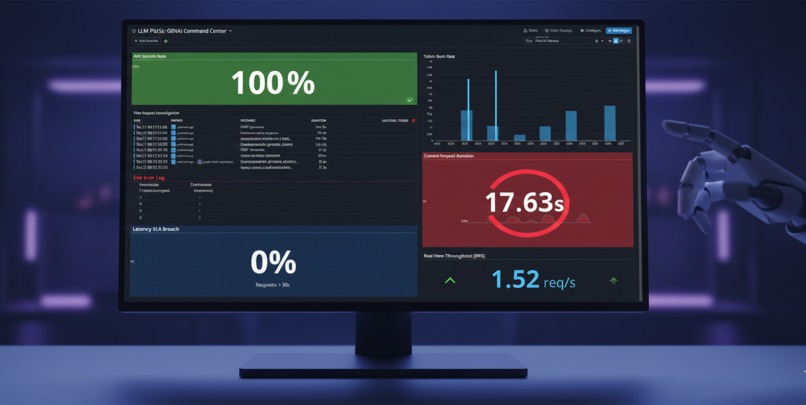
Our project, LLM Pulse, provides a high-fidelity "War Room" for AI operations. It captures every request to the Gemini API and exposes critical health metrics:
Operational Success: Real-time monitoring of API success vs. failure rates.
Performance Benchmarking: P95 latency tracking to identify bottlenecks in generative content production.
Cost Management: Aggregated token consumption tracking to prevent budget overruns.
How we built it
The system is built on FastAPI and integrated with Google Vertex AI. We used the Datadog ddtrace library for deep instrumentation.
Telemetry: We engineered custom span attributes to capture total_tokens and prompt_length.
Visualization: We built a custom dashboard using Datadog’s Query Value and Timeseries widgets to aggregate these spans into actionable business intelligence. We quantify our performance density using the following ratio: $$Performance_Density = \frac{\sum Total_Tokens}{\sum Latency_{sec}}$$
Challenges we ran into
The biggest technical hurdle was Data Type Integrity. We initially struggled with Datadog treating numeric token data as "Dimension" strings, which blocked mathematical aggregation. We had to ruthlessly re-engineer our trace facets into Measures to enable the Sum and Rate functions. We also had to debug massive latency spikes (over 1 minute) by isolating cold-start traces from actual model failures.
Accomplishments that we're proud of
We achieved 100% observability. We can trace a single user prompt from the initial HTTP call all the way through the LLM generation and back, with every micro-cent of token cost and every millisecond of latency accounted for on a single pane of glass.
What we learned
We learned that simply "sending data" to an observability platform is useless if it isn't structured for math. We also learned that in the world of GenAI, Latency is the new Uptime. A request that takes 1.26 minutes is a failure, even if the status code says "200 OK."
What's next for LLM Pulse
We plan to implement Automated Cost-Killswitches. Using the token consumption data we've unlocked, we will build a circuit breaker that automatically throttles users or switches to smaller models (like Gemini Flash) if a specific budget threshold is reached in a single hour.


Log in or sign up for Devpost to join the conversation.