-
-
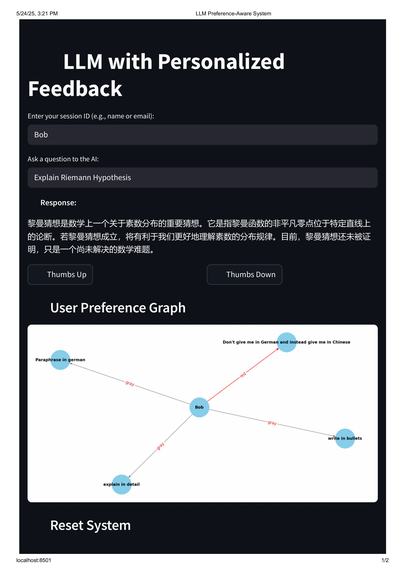
Sample Screenshot from demo
Inspiration
The inspiration came from a simple question: What if large language models could remember how you prefer your answers? Instead of manually rewriting prompts (which we sort of encountered before with legacy systems like GPT 3.5 and early versions of perplexity) I wanted to build a system that learns and adapts from user feedback of forming a persistent memory layer that makes LLMs feel more personalized and context-aware over time.
What it does
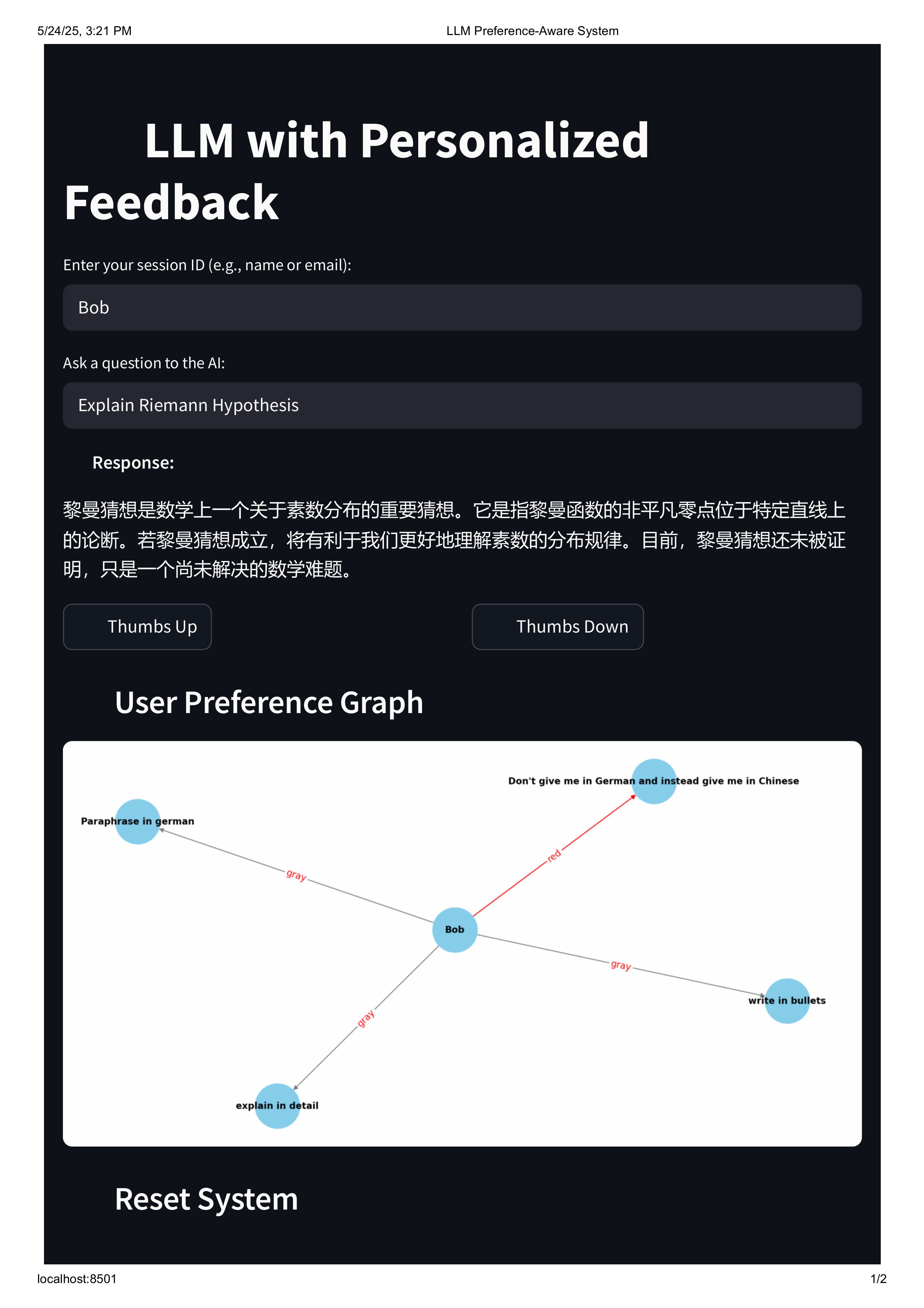
The app allows users to ask questions and receive responses from GPT-3.5 Turbo. If the user is unsatisfied, they can give feedback (e.g., "write in bullets", "translate to French", etc.). This feedback is recorded in a dynamic knowledge graph.
Only the latest active preference is used to generate future responses.
Preferences are persisted per user across sessions using JSON.
Rejected preferences are marked visually and ignored by the system.
The graph is rendered live and updated with every feedback interaction.
How we built it
Streamlit powers the frontend interface for user interaction.
OpenAI GPT-3.5 Turbo generates responses.( Can be changed to any model of choice)
NetworkX handles the internal knowledge graph, which maps users to preferences.
Matplotlib is used to render a visual graph, with edge colors representing state:
Red: latest active preference
Gray: previous preferences
JSON files store per-user graph data so the app retains memory even after shutdown.
Multi-user support is handled using session IDs, keeping graphs and preferences isolated.
Challenges we ran into
Some key challenges included handling duplicate feedback like “write in bullets” vs “Write in bullets,” which was solved by normalizing inputs. We also had to ensure the LLM used only the most recent preference while ignoring outdated or rejected ones. Updating the response and graph in real time without disrupting the user experience was tricky, and designing a clean, readable graph that reflected the user’s state without clutter took careful tuning.
Accomplishments that we're proud of
We’re proud of building a fully adaptive system where the LLM responds based on real-time user feedback. The app remembers preferences across sessions, supports multiple users, and visualizes each user’s state through a dynamic knowledge graph. It’s lightweight, modular, and easy to extend and runs on local
What we learned
We learned how to design a feedback loop that directly influences LLM behavior, how to normalize and manage user input effectively, and how to build a system that balances personalization with simplicity. Visualizing memory through graphs also taught us or rather appreciate the explainability part
What's next for LLM Preference Aware System
Next, we plan to add support for graph databases like Neo4j, enable hard deletion of preferences, and build preference analytics to track trends.
Built With
- networx
- python
- streamlit



Log in or sign up for Devpost to join the conversation.