-
-
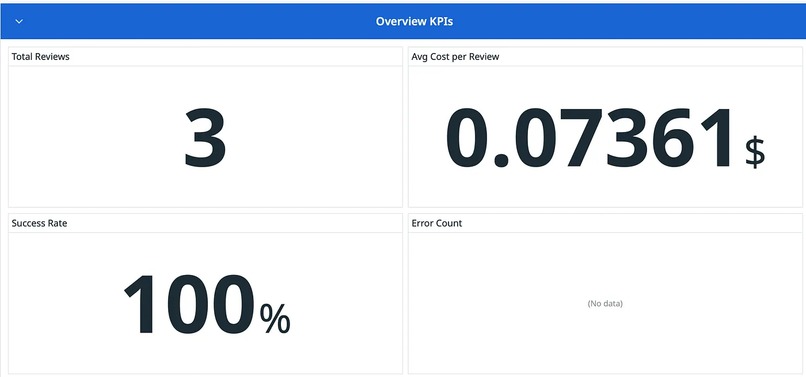
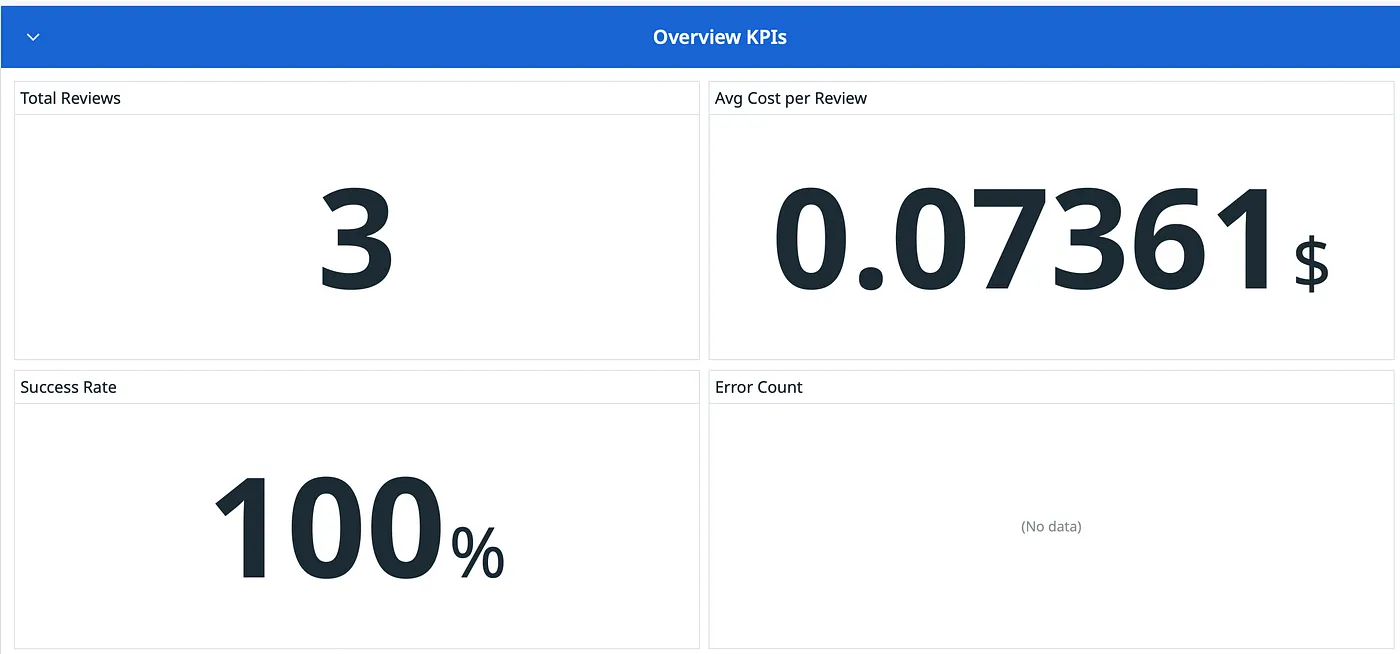
Overview KPI
-
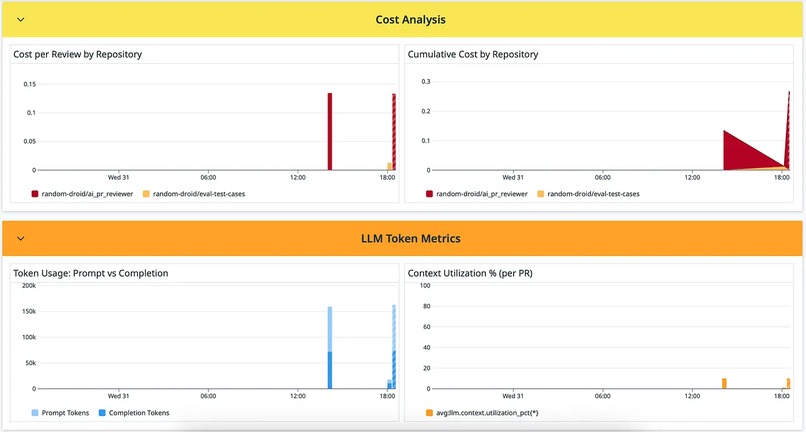
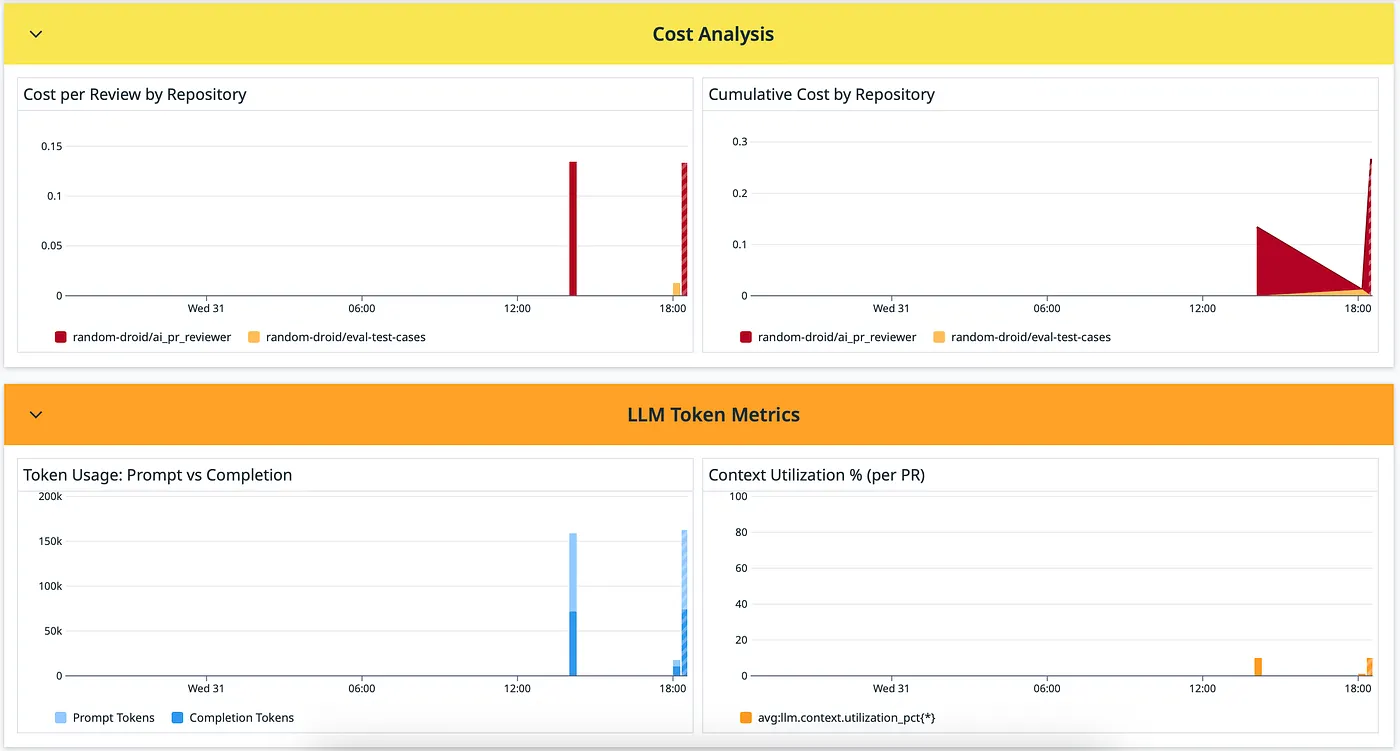
Cost Analysis and LLM Token Metrics (Yellow, Orange)
-
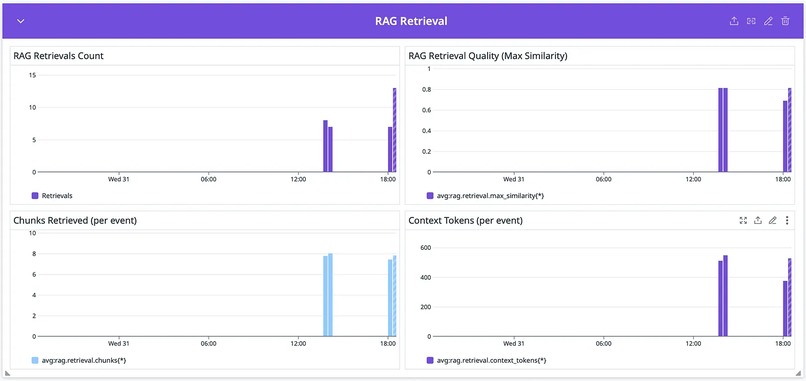
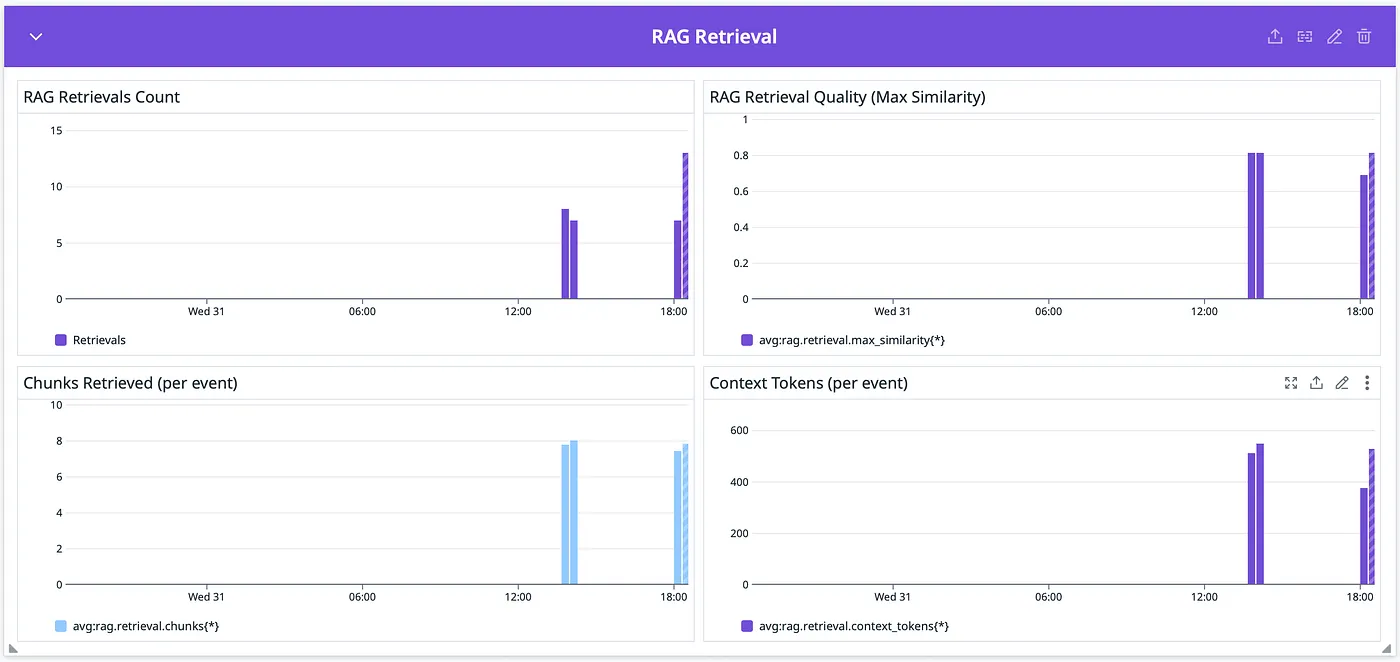
RAG Retrieval (Purple)
-
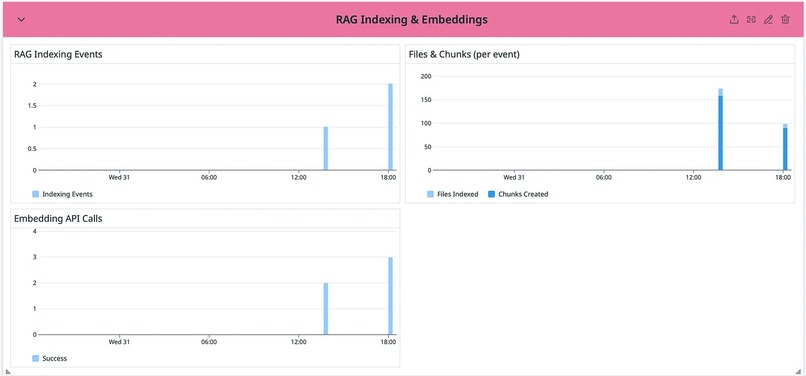
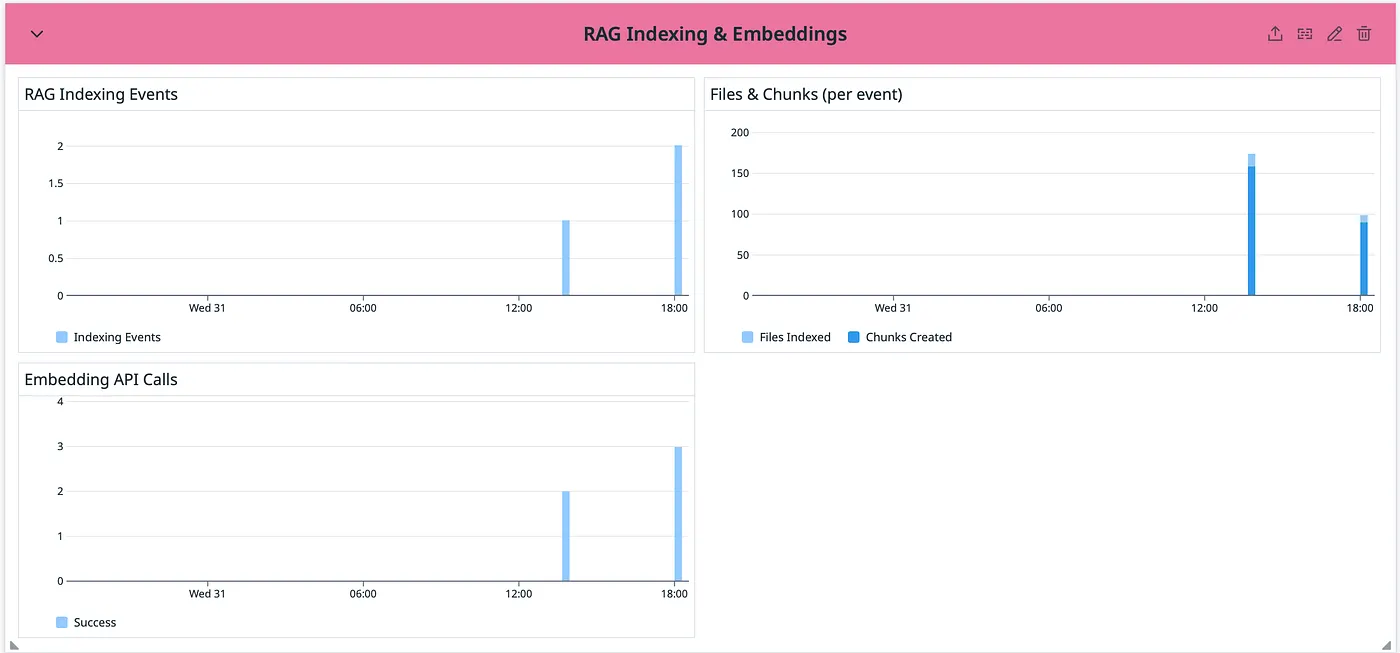
RAG Indexing and Embedding (Pink)
-
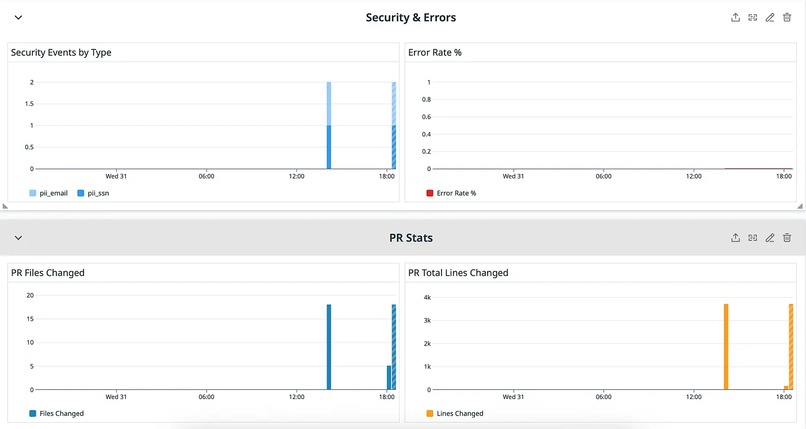
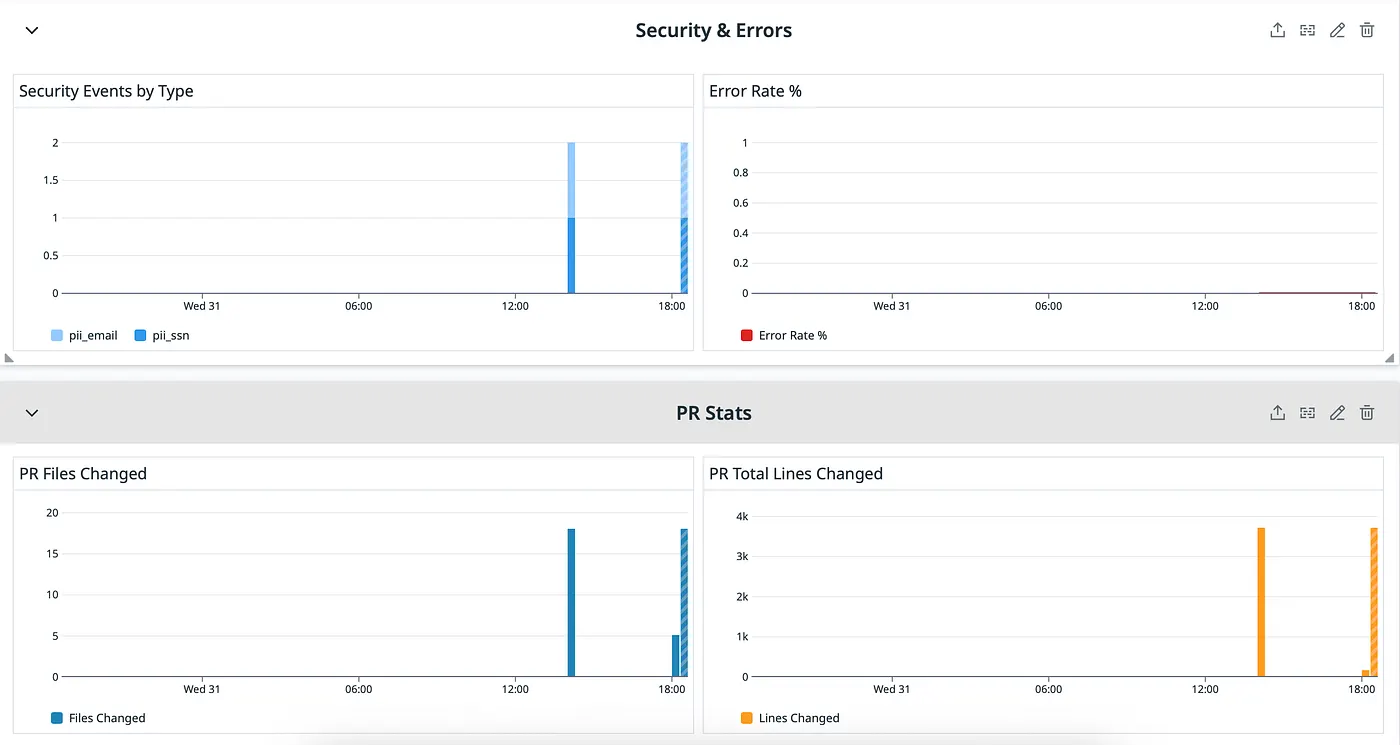
Security and Error, PR Stats (Grey)
-
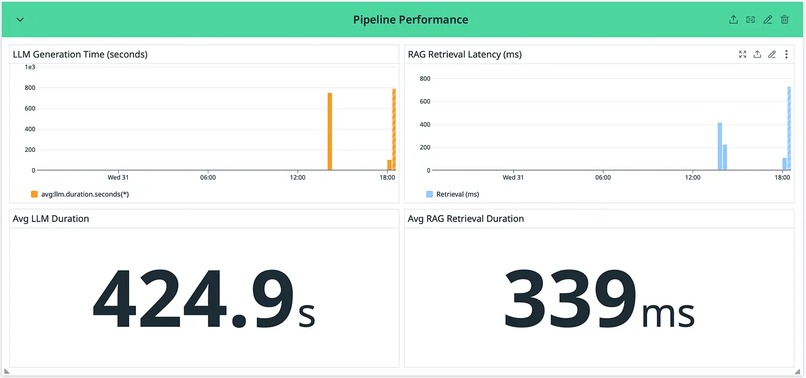
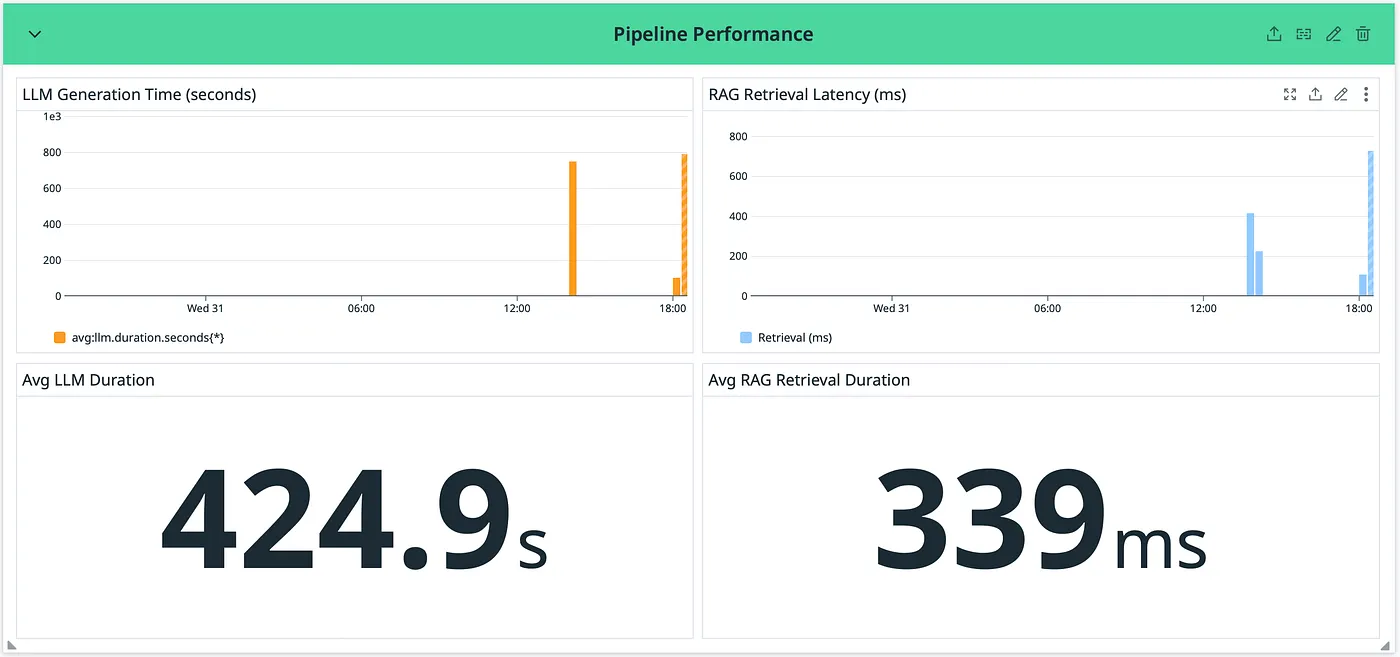
Pipeline Performance
LLM Code Review Service with RAG & Observability
Audience: Engineering Leadership / Tech Team
Inspiration
As AI transitions from standalone tools to embedded infrastructure, we realized that getting an LLM to work is the easy part—keeping it running reliably and cost-effectively at scale is the real challenge. Inference costs can rival training costs, yet most AI demos skip observability entirely. We wanted to build something production-ready from day one.
What it does
An AI-powered code review service that automatically reviews GitHub pull requests using Gemini 2.5 Pro with RAG (Retrieval-Augmented Generation) for full codebase context. It:
- Analyzes PRs with awareness of the entire codebase, not just changed lines
- Scans for security issues (secrets, PII, prompt injection) before LLM processing
- Posts actionable review comments directly to GitHub PRs
- Tracks every metric in Datadog: cost per review, token usage, RAG quality, and errors
How we built it
Started with the webhook — FastAPI endpoint to receive GitHub PR events with HMAC signature verification
Added the LLM — Integrated Vertex AI Gemini 2.5 Pro to analyze code diffs and generate reviews
Built the RAG pipeline — FAISS vector search + Vertex AI embeddings to give the LLM full codebase context
Layered in security — Pre-LLM scanning for secrets, PII, and prompt injection attempts
Instrumented everything — Datadog metrics for cost, tokens, latency, and RAG quality
Deployed serverless — Cloud Run for auto-scaling and cost efficiency
Challenges we ran into
- RAG tuning: Finding the right chunk size and similarity threshold to retrieve relevant context without overwhelming the LLM's context window
- Cost visibility: LLM APIs don't return cost directly—we had to calculate it from token counts and model pricing
- Webhook reliability: Handling GitHub's ping events, retry logic, and signature verification correctly
- Cold starts: Cloud Run scale-to-zero means first requests are slow; balancing cost vs. latency
Accomplishments that we're proud of
- Full observability from day one: Every review is tracked—cost, latency, token usage, RAG quality
- Security-first design: Pre-LLM scanning catches secrets and PII before they hit the model
- Production-ready architecture: Not a demo—this handles real PRs with real error handling
- Unit economics visibility: We know exactly what each review costs (~$0.02) and can optimize
What we learned
- Observability isn't optional for production AI—it's essential for cost control and debugging
- RAG quality metrics (similarity scores, chunks retrieved) are as important as LLM metrics
- Context window utilization is a key optimization lever (we use ~15% of 128K)
- The gap between "working demo" and "production system" is mostly error handling and monitoring
What's next for LLM Code Review Observability Service
- Multi-repo RAG: Index across related repositories for monorepo-style context
- Review quality scoring: Track whether reviews get resolved or dismissed
- Cost optimization: Experiment with smaller models for simpler files
- Caching layer: Avoid re-embedding unchanged files
- Custom review rules: Let teams define their own code standards
Slide 1: Introduction - The Shift to Production AI
LLM Code Review Service: "Prototype vs. Production"
Inference costs can rival training costs at scale
| Category | Tool/Technology | Purpose |
|---|---|---|
| AI/ML | Vertex AI Gemini 2.5 Pro | LLM for code review analysis |
| AI/ML | Vertex AI text-embedding-005 | Text embeddings for RAG vector search |
| Vector Search | FAISS | Local vector similarity search for RAG |
| Web Framework | FastAPI | HTTP API & webhook handling |
| HTTP Server | Uvicorn | ASGI server for FastAPI |
| Observability | Datadog | Metrics, traces, and monitoring |
| Cloud Platform | Google Cloud Run | Serverless container hosting |
| Source Control | GitHub | Code hosting & webhooks |
| Data Validation | Pydantic | Request/response models |
| Language | Python 3.11+ | Runtime |
Slide 2: The Solution - Context at Scale
Key features include:
- RAG-Powered Context: Uses in-memory Vector Search (FAISS) to understand the entire codebase, not just the changed lines. This means it catches issues that might break other dependencies.
- Multi-Language Support: Handles Python, Go, JS, and more out of the box.
- Proactive Security: Before the code even hits the LLM, scans run for secrets, PII, and prompt injection attempts.
Slide 3: Observability - The "Special Sauce"
In production, inference at scale is expensive. We can track:
- Cost per Review: Know exactly how much each PR costs.
- Token Efficiency: Monitor prompt vs. completion tokens to optimize context window.
- Quality Metrics: Track errors and RAG retrieval relevance.
Example stats from my experiments: Average review cost: ~$0.07 Average LLM duration: ~6 mins Context utilization: 15% of 128K window
This gives confidence to scale with full visibility into performance and unit economics.
LLM Token Metrics (Orange) Tokens directly drive cost and latency. Understanding the prompt-to-completion ratio reveals whether you’re sending too much context or getting verbose responses. Token Usage: Prompt vs Completion — Prompt tokens = what you send (code diff + RAG context + system prompt). Completion tokens = the review response. A healthy ratio is typically 10:1 to 20:1 (prompts much larger than completions). Context Utilization % — What percentage of Gemini’s 128K context window you’re using. If consistently low (<20%), you have room to add more context. If high (>80%), you risk truncation on large PRs.
RAG Retrieval (Purple) RAG quality directly impacts review accuracy. Poor retrieval = irrelevant context = hallucinated issues or missed bugs. RAG Retrievals Count — How many times the system searched for relevant code context. Should roughly match PR review count. RAG Retrieval Quality (Max Similarity) — The highest cosine similarity score from vector search (0–1). Scores >0.7 indicate highly relevant context was found. Low scores (<0.5) mean the retrieved code may not be useful. Chunks Retrieved (per event) — Number of code chunks injected into the prompt. Too few = missing context. Too many = noise and wasted tokens. Context Tokens (per event) — Token count of retrieved context. Balance between providing enough context and staying within budget/limits.
RAG Indexing & Embeddings (Pink) The RAG pipeline must index code before it can retrieve it. Indexing failures = blind spots in code review. RAG Indexing Events — Count of codebase indexing operations. Spikes indicate repo updates being processed. Files & Chunks (per event) — How many files were indexed and how they were chunked. Large repos will show more chunks. Useful for capacity planning. Embedding API Calls (Success/Failed) — Vertex AI embedding API reliability. Failed calls mean code wasn’t indexed. Any red bars here need investigation.
Security & Errors (Grey) Pre-LLM security scanning protects against sending secrets to the model and catches issues before they reach production. Security Scan Findings — Count of detected secrets, PII, or prompt injection attempts in PR diffs. High numbers may indicate developer education needed. Review Errors — Failed review attempts (API errors, timeouts, parsing failures). Should be near zero. Spikes indicate service health issues.
| Metric Pattern | What It Means |
|---|---|
| High cost, low similarity | Sending lots of context but it's not relevant — tune RAG |
| Low context utilization | Room to add more files or history to improve reviews |
| Embedding failures | Vertex AI quota/connectivity issues — check GCP console |
| Security findings spike | New developer or repo with different practices |
| Cost variance between repos | Some codebases need different review strategies |
Slide 4: Architecture & Stack
Request Flow:
- GitHub Webhook → Triggers on PR open/update
- FastAPI → Receives and validates webhook
- Security Scan → Checks for secrets, PII, prompt injection
- RAG Context → Retrieves relevant code from FAISS index
- Gemini LLM → Generates code review
- GitHub API → Posts review comments to PR
External Services:
- Datadog — Metrics and observability
- FAISS — Vector similarity search
- Vertex AI — Gemini 2.5 Pro + Embeddings
Slide 5: Conclusion
Ready for Testing the Deployment
| Resource | URL |
|---|---|
| Running App (Health) | https://llm-code-review-blz5bvu6kq-uc.a.run.app/health |
| Running App | https://llm-code-review-blz5bvu6kq-uc.a.run.app/health |
| Observability Datadog | https://p.us5.datadoghq.com/sb/6134f236-e075-11f0-bac8-b24f51c75d5d-8eb6a42c48d48e6171c5b72d9037c42c |
| Eval Test Cases PR | https://github.com/random-droid/eval-test-cases/pull/1 |
| Project Codebase | https://github.com/random-droid/llm-observability-service |
Log in or sign up for Devpost to join the conversation.