Inspiration
There are many large language models to choose from. Each one has pros, cons, costs, and other considerations. I wanted a way to quickly evaluate the best model for a particular task and report on the outcomes.
What it does
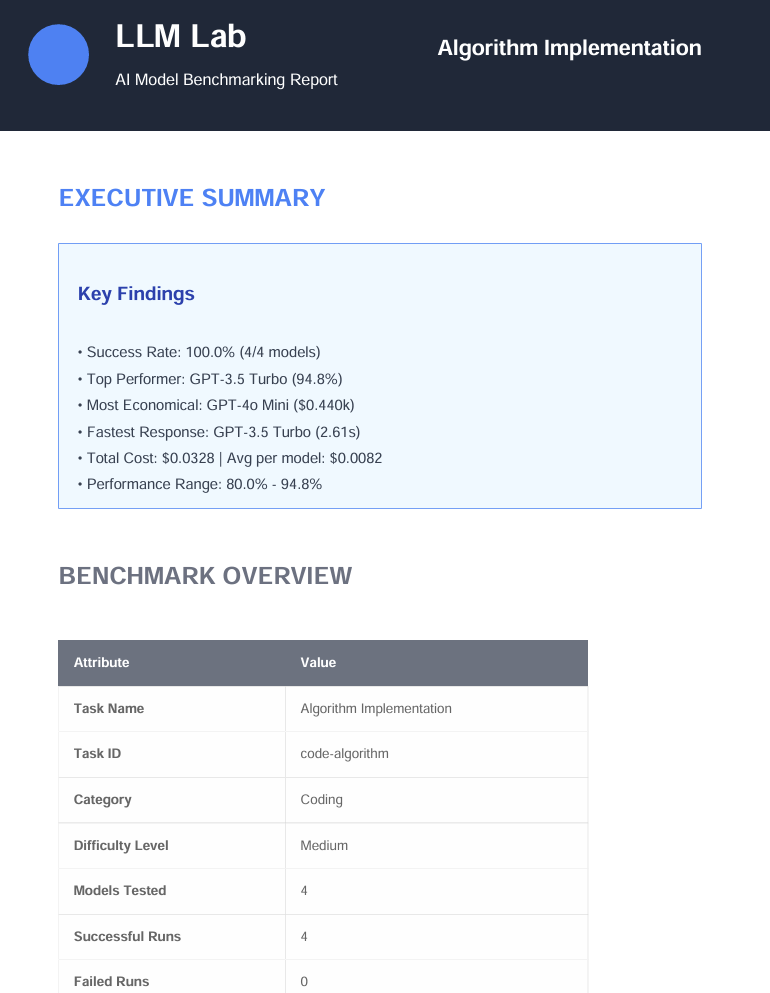
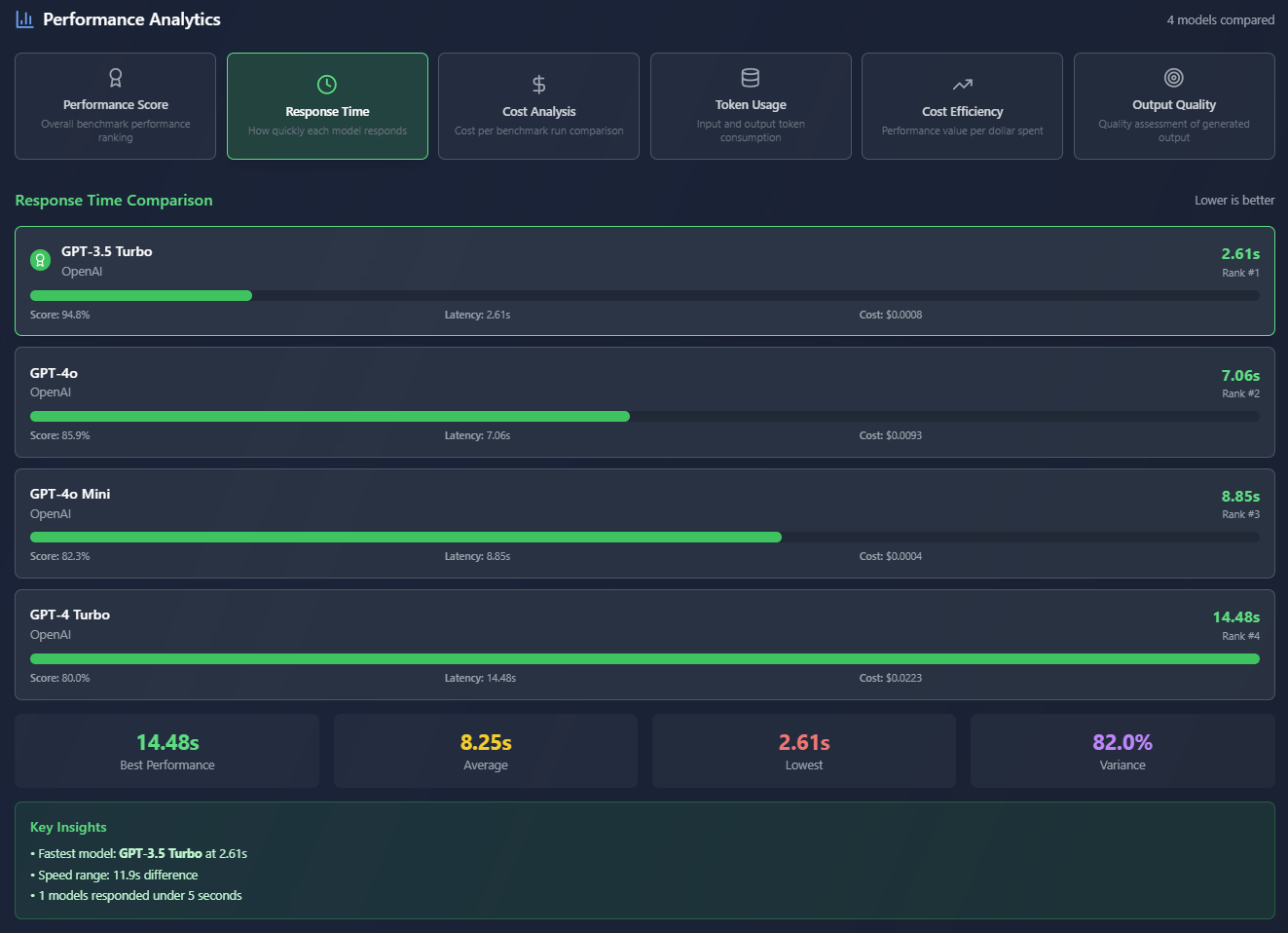
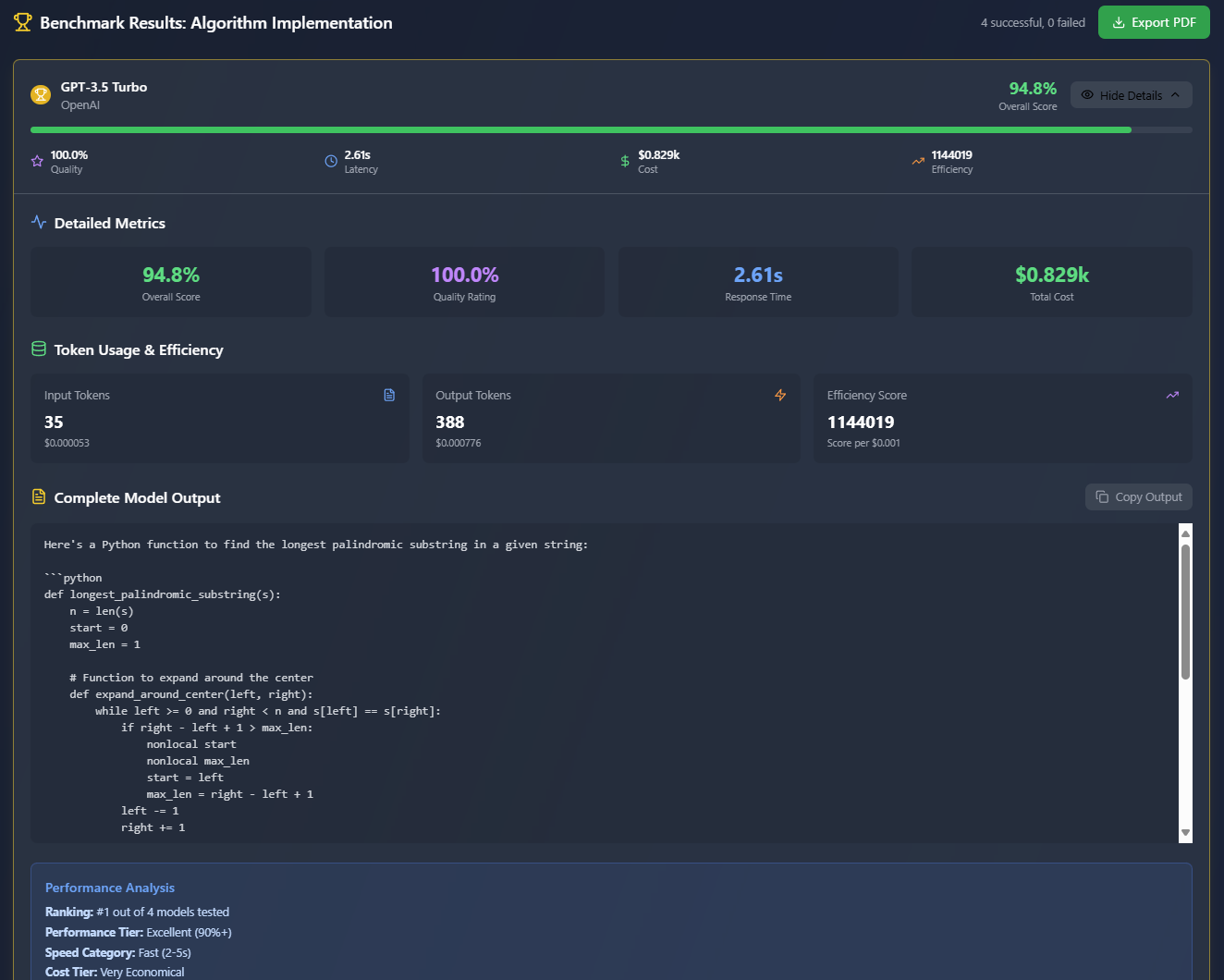
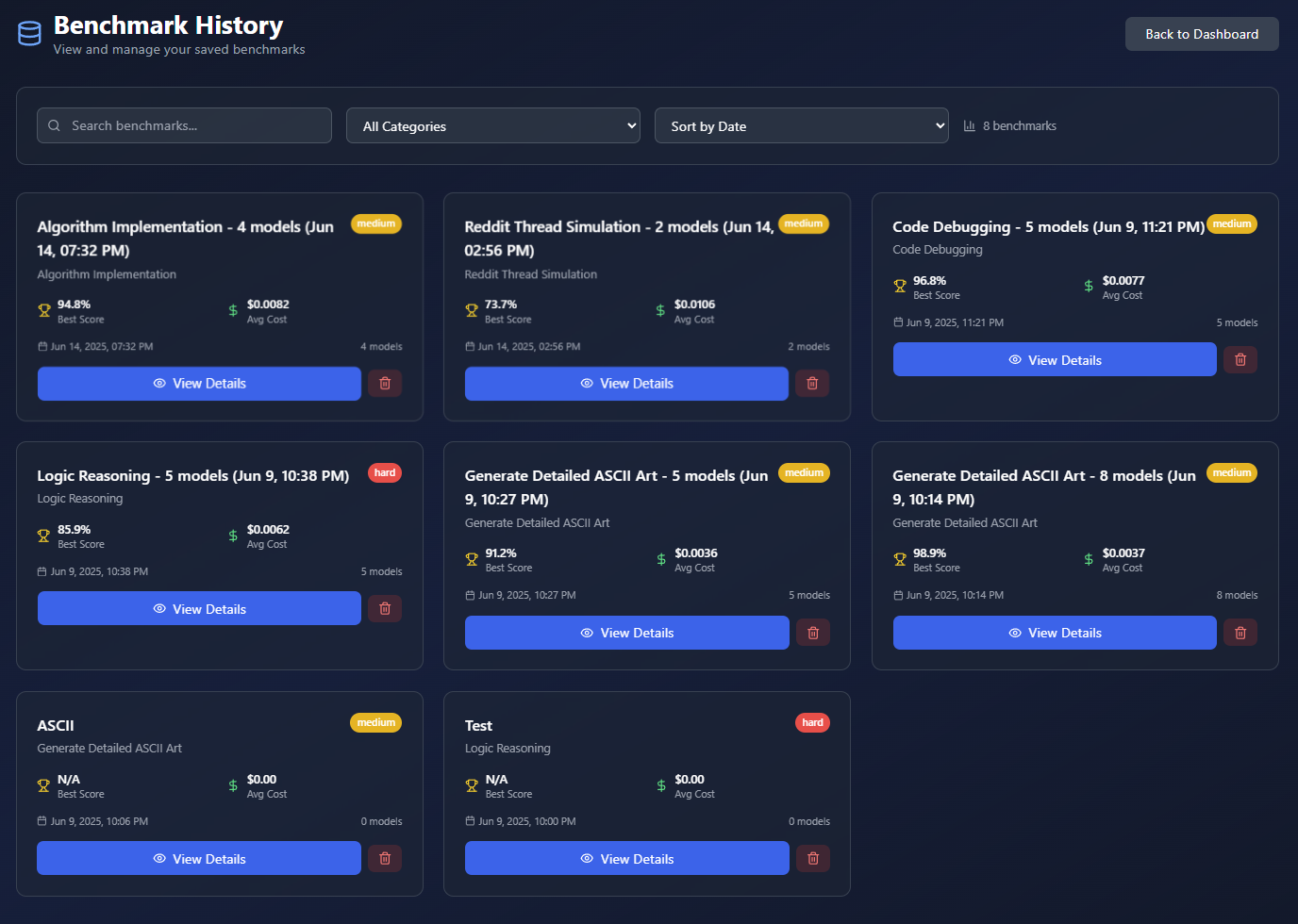
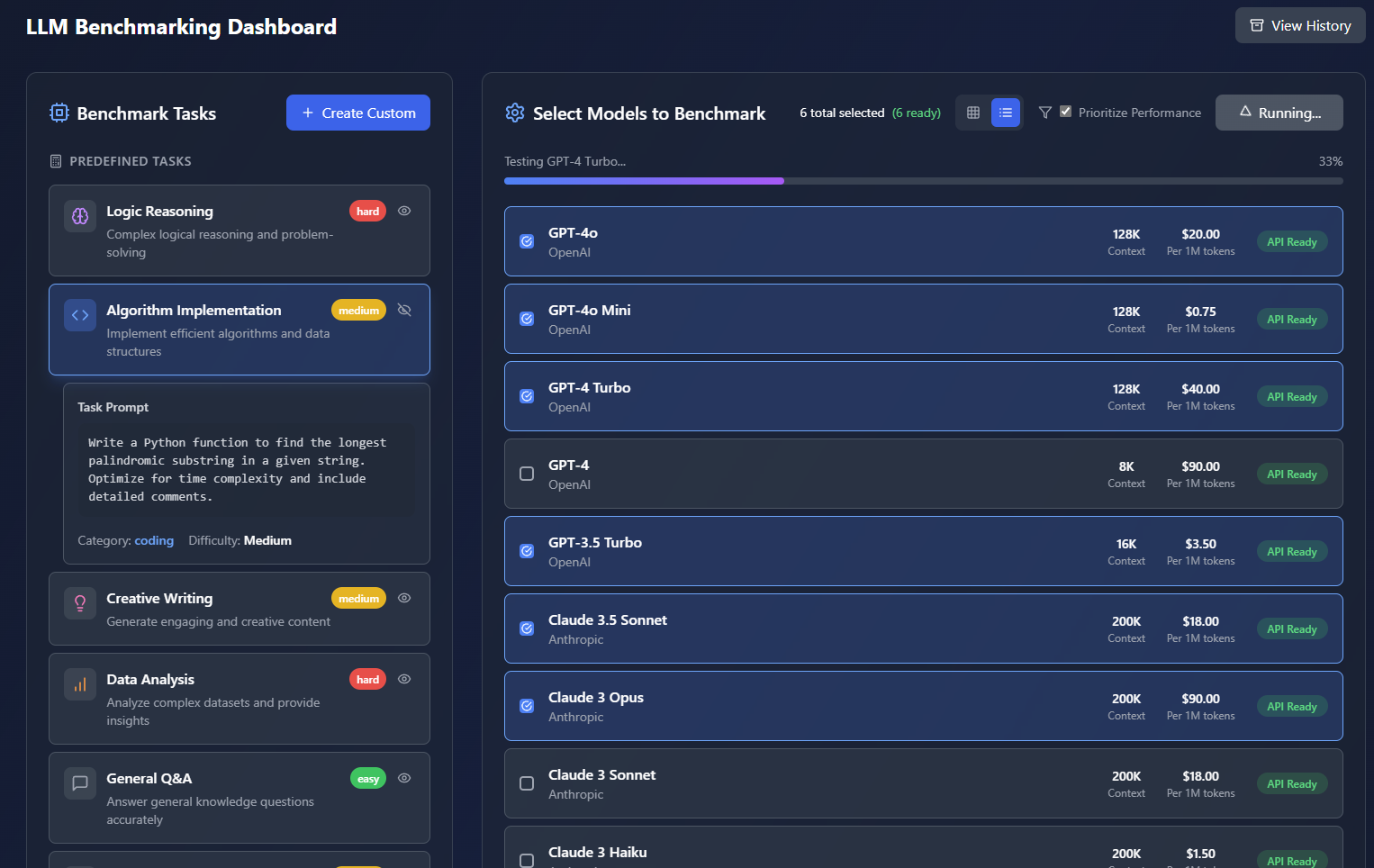
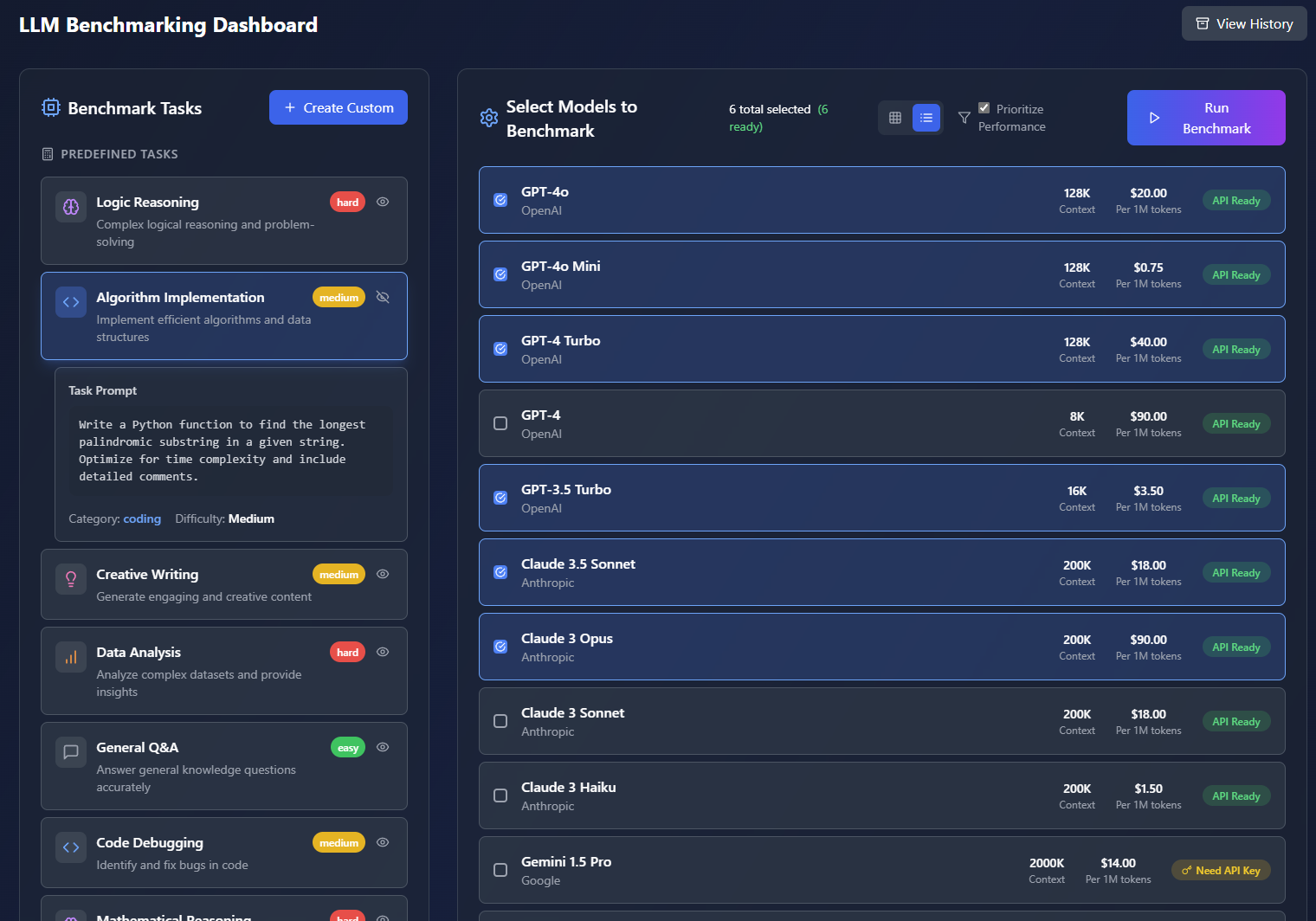
Select one or multiple models from the major companies, and select a pre-defined or custom Benchmark Task. Run the evaluation to generate a UI and PDF report that ranks each model in various categories. View the inputs, outputs, costs, etc for each model.
How we built it
Vite PWA with Bolt.new.
Challenges we ran into
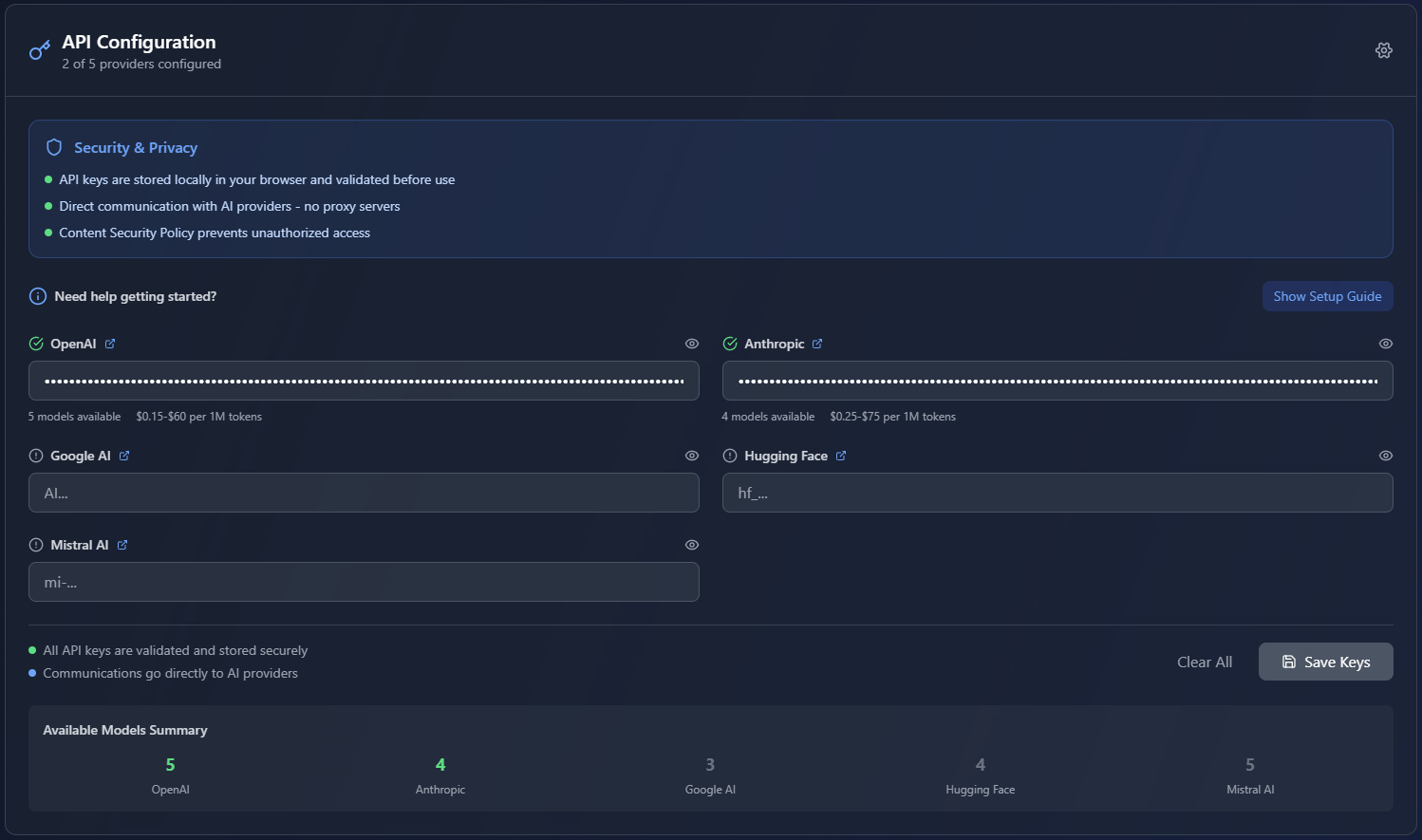
Securely managing the user's API keys.
Accomplishments that we're proud of
- Simple 3 click workflow for running an evaluation and outputting a report.
- Detailed docs on generating API keys.
- Detailed analysis through the UI as well as a printable PDF report
What we learned
- Each model has strengths and weaknesses, not easily described until seeing them compared to other models.
What's next for LLM Lab
- Organization-level account features
- Sharing outputs easily across the internet
- 'Best Fit' features that will find the perfect model based on user preferences
Built With
- anthropic
- openai
- react
- vite

Log in or sign up for Devpost to join the conversation.