-
-
-
-
-
-
-
-
-
-
-
-
-
Dashboard
-
-
Inspiration
As large language models move from experiments into production systems, I quickly noticed a growing gap. While traditional applications are deeply observable, LLM behavior is often opaque.
Latency spikes, hallucinations, unexpected costs, or potential PII exposure can occur silently and often only surface after users are impacted. Existing observability tools capture infrastructure metrics well, but they don’t natively understand LLM-specific signals like token usage, model behavior, or safety risks.
I built LLM Guardian to close this gap and bring production-grade observability, safety, and accountability to AI systems by using the same rigor engineers expect from mission-critical services.
What it does
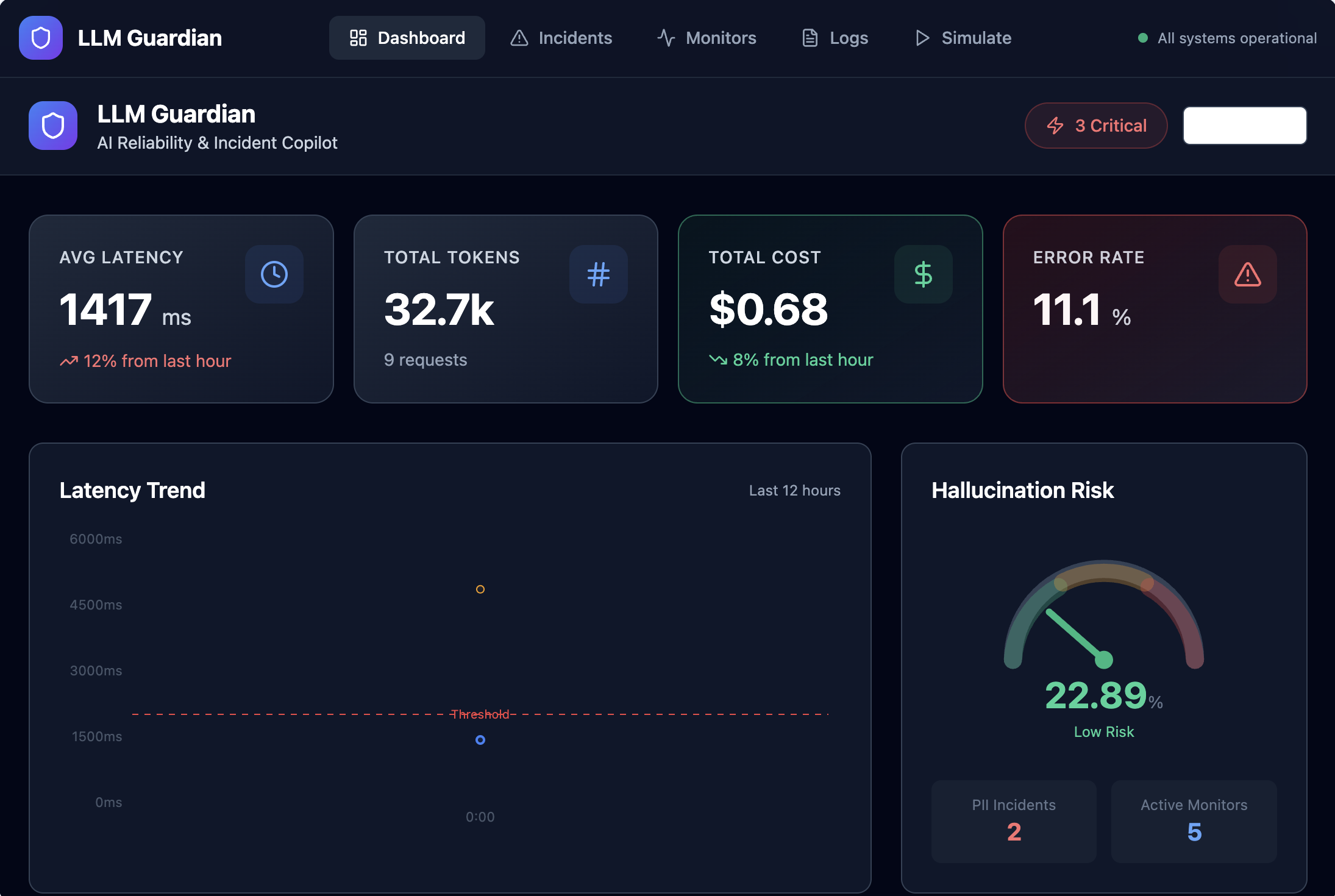
LLM Guardian is an end-to-end observability and safety monitoring platform for LLM applications.
It allows me to:
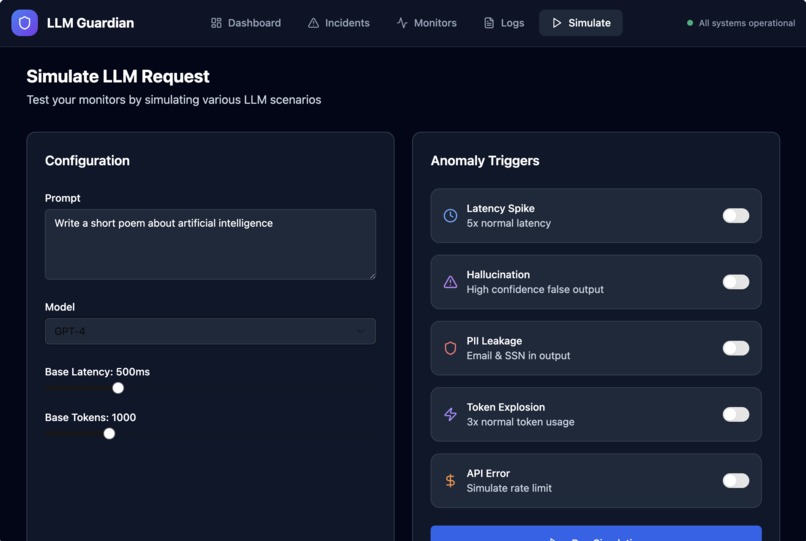
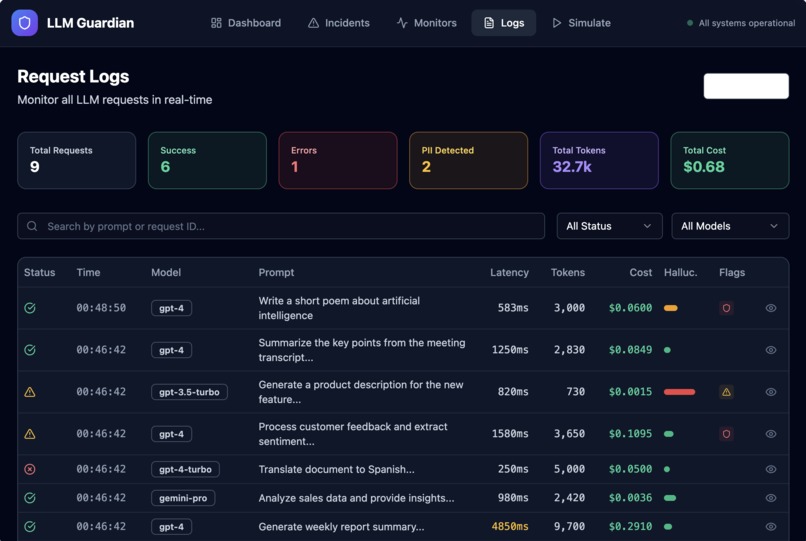
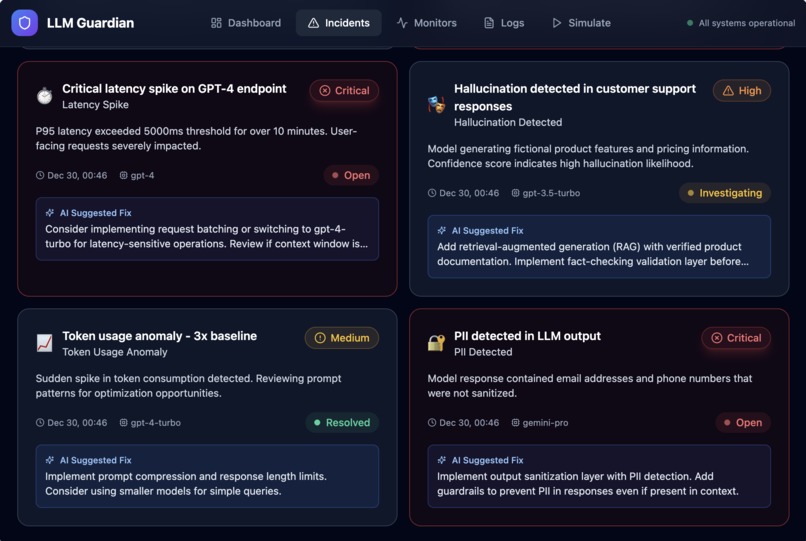
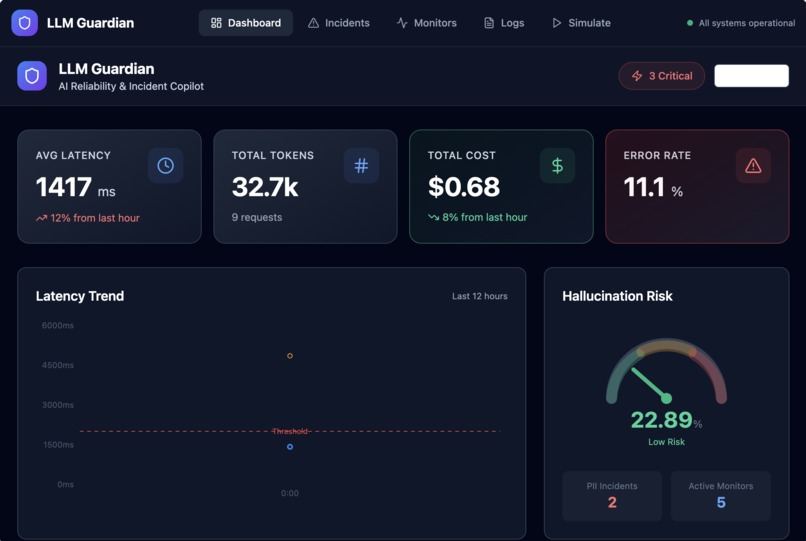
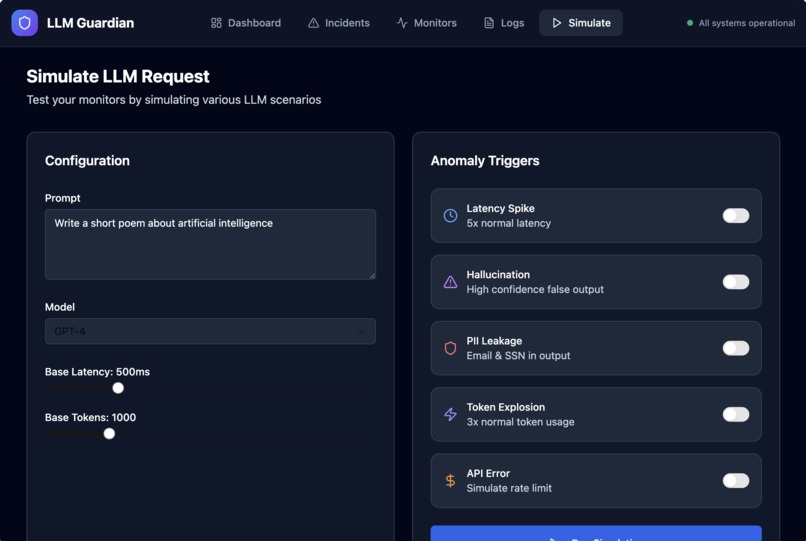
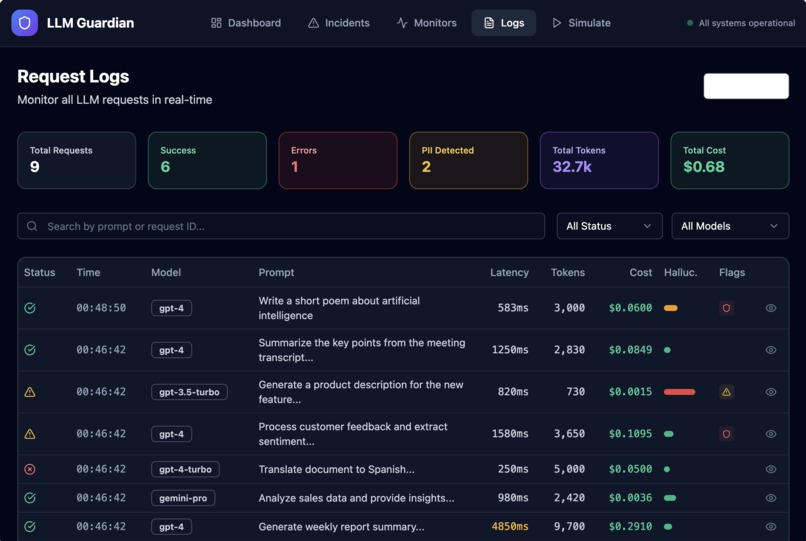
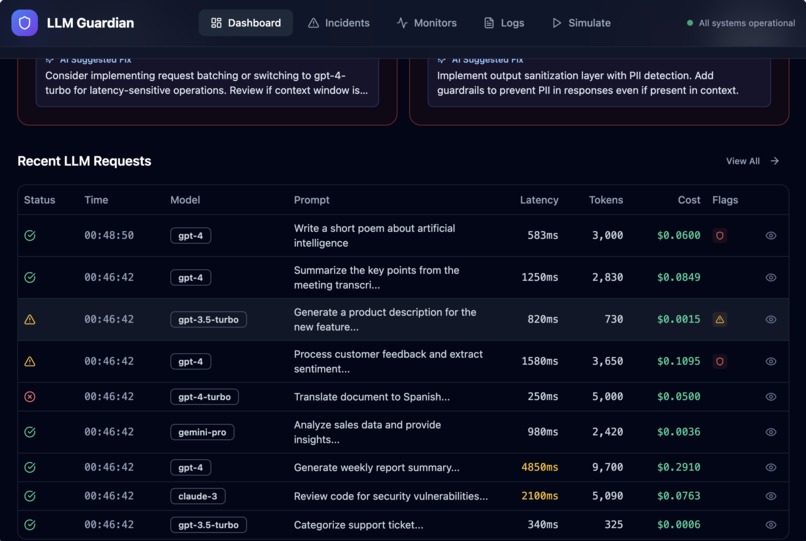
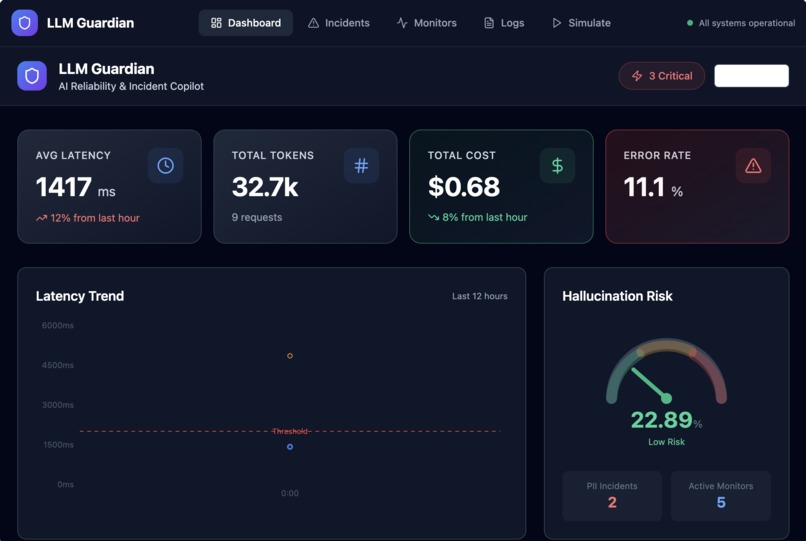
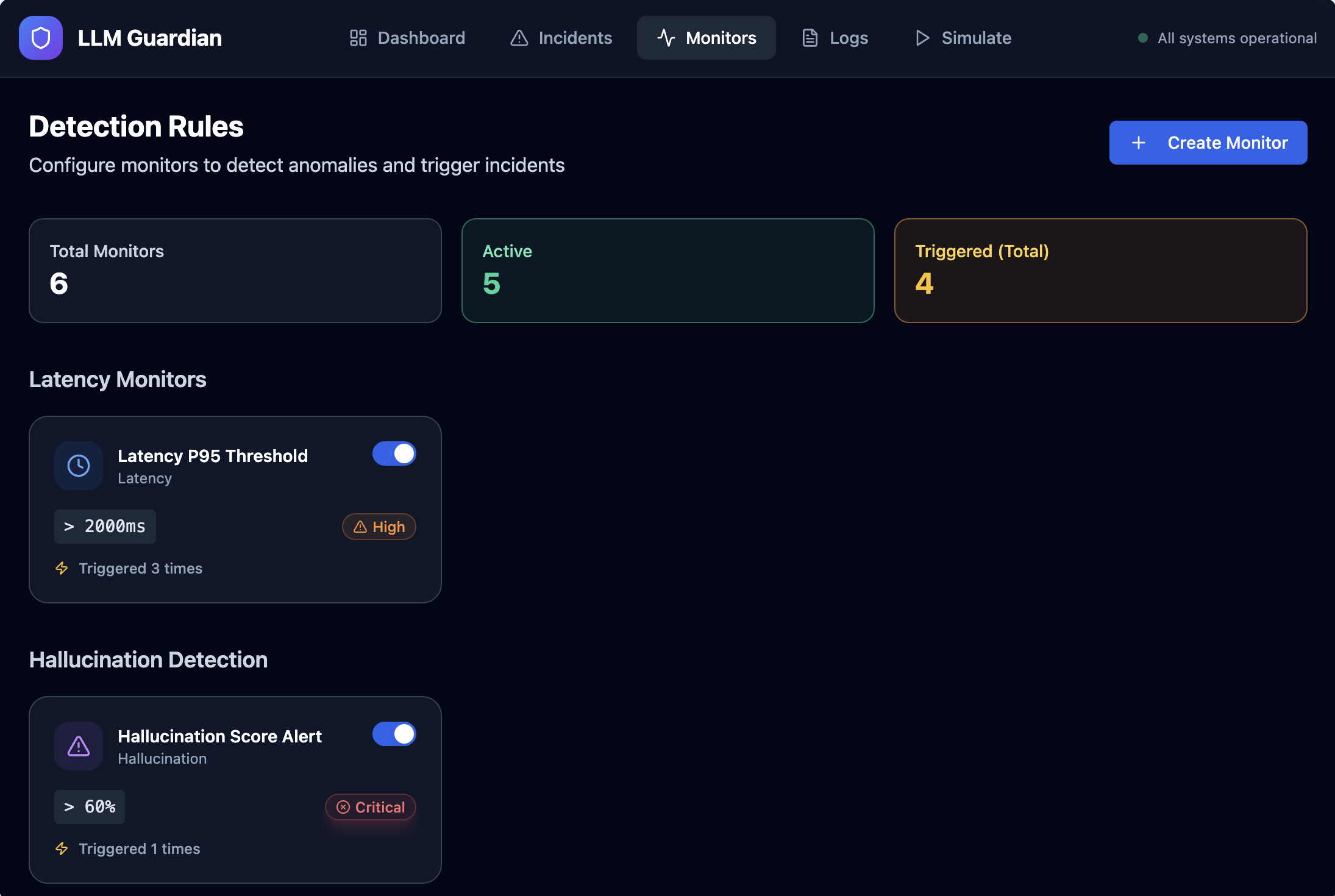
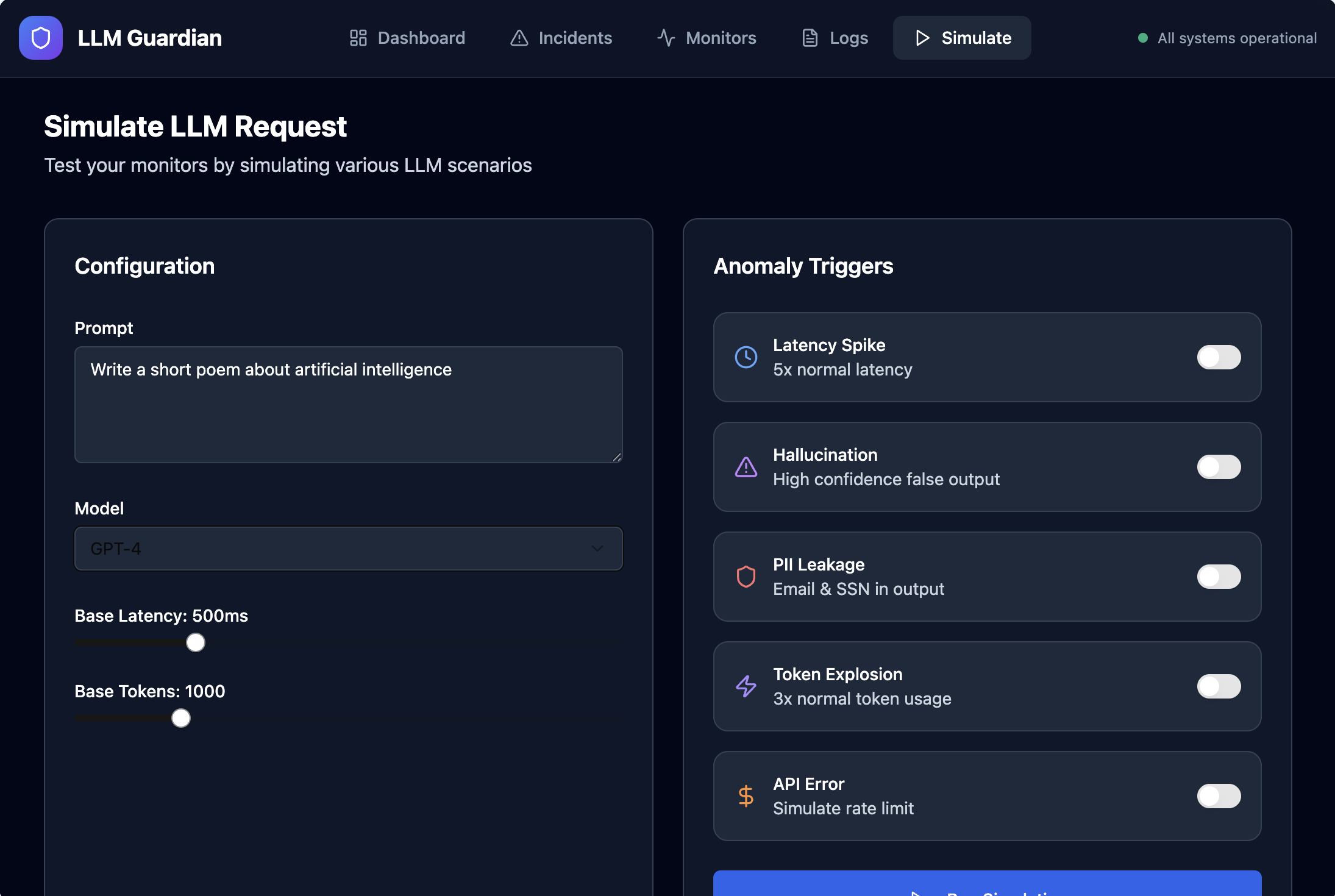
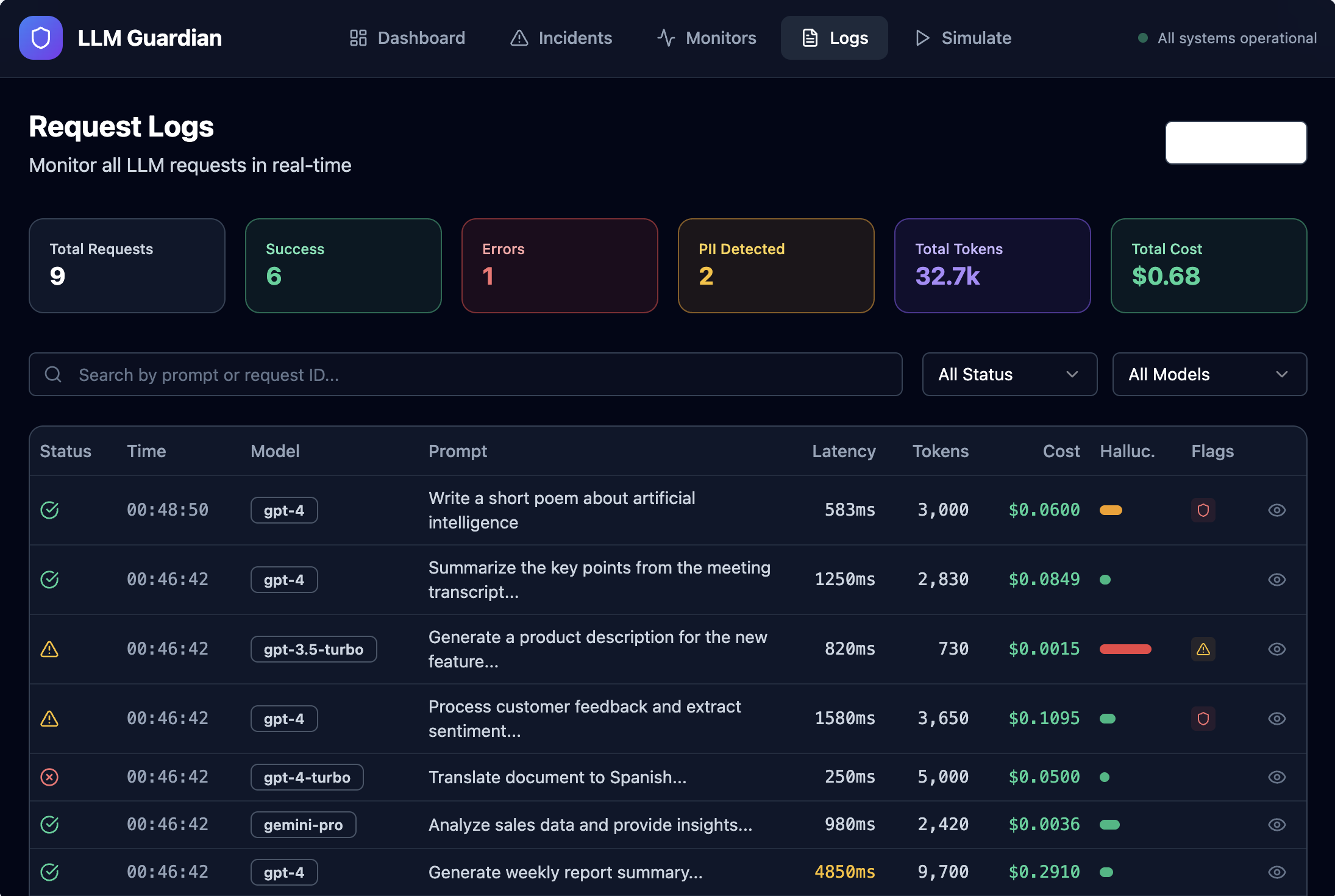
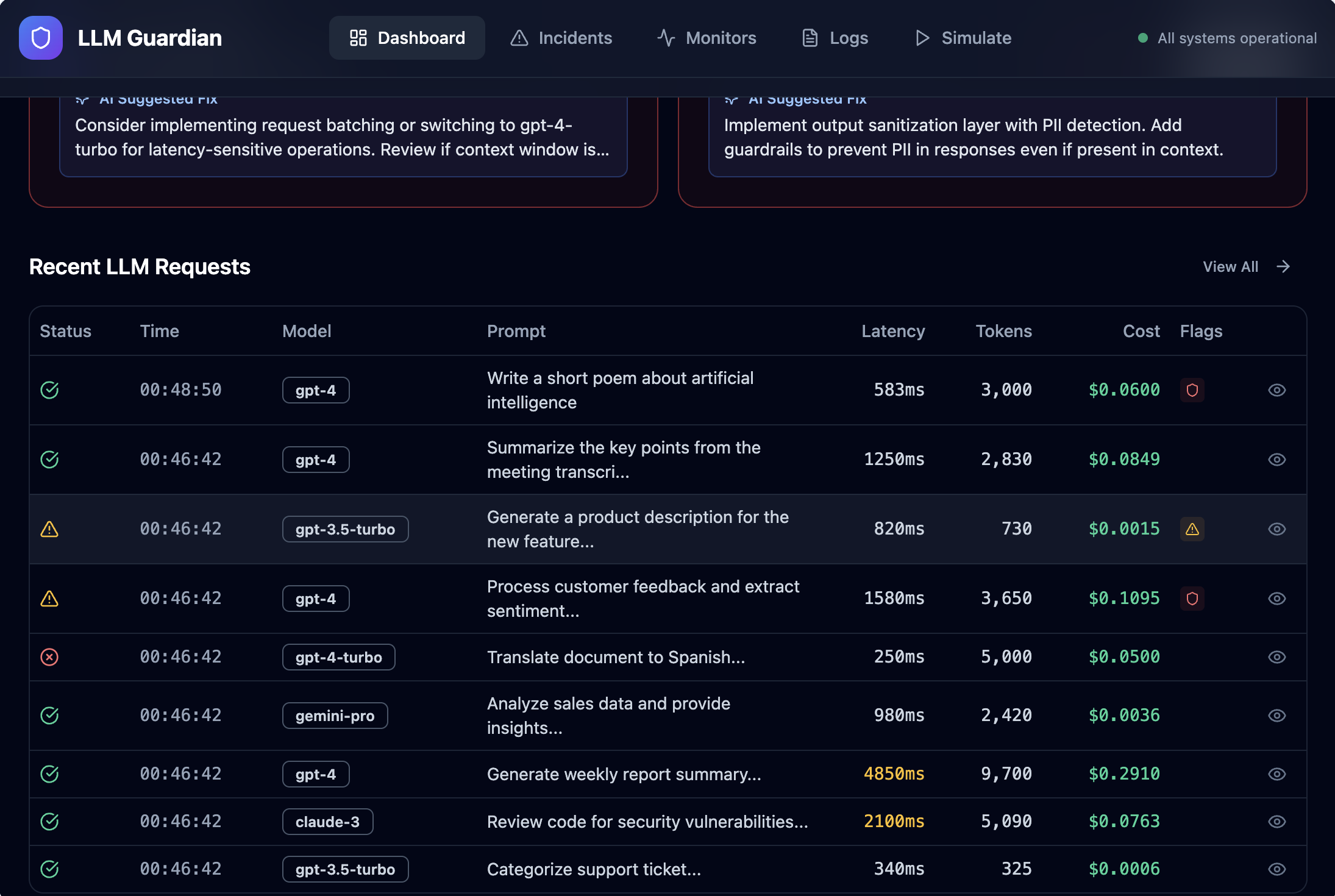
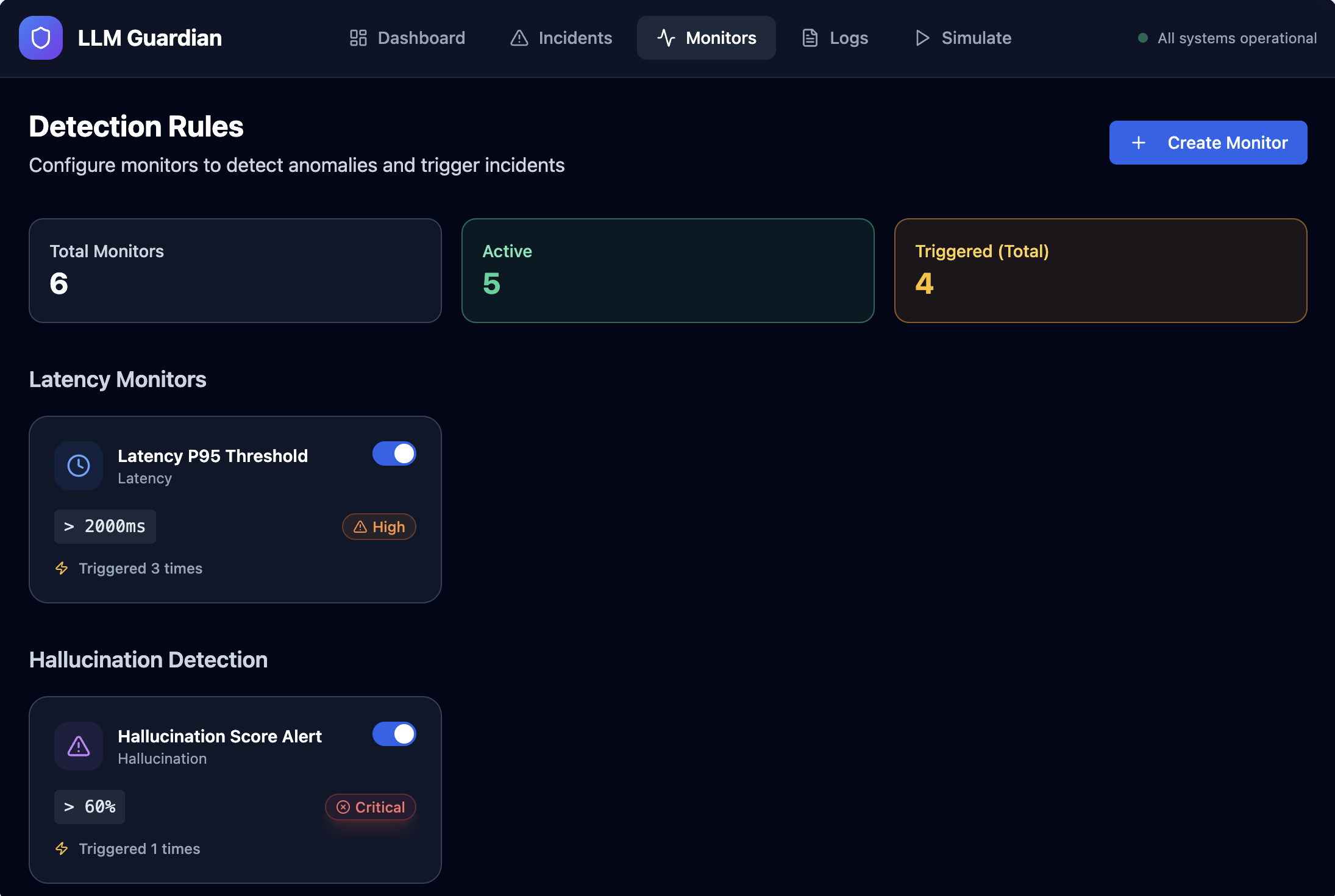
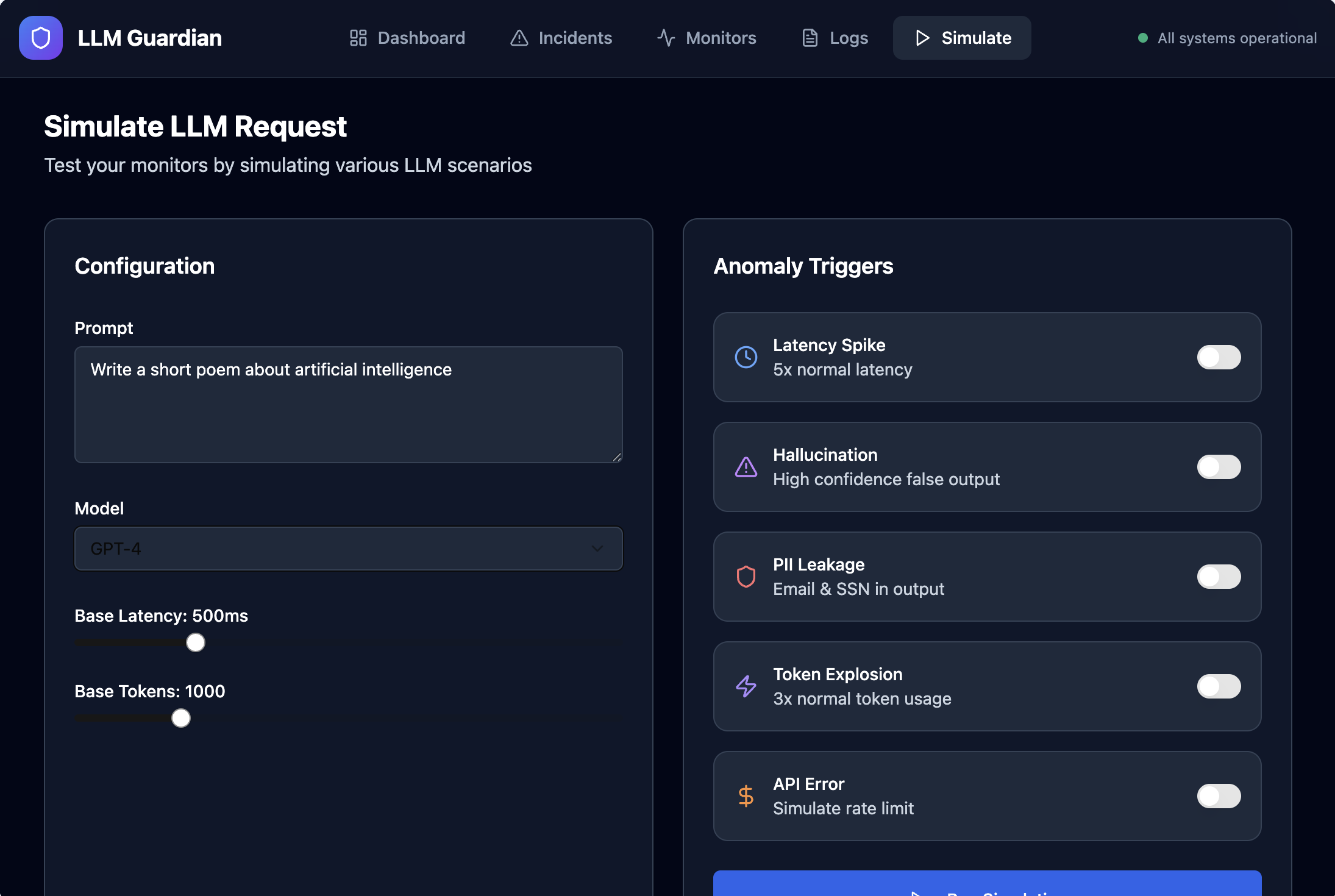
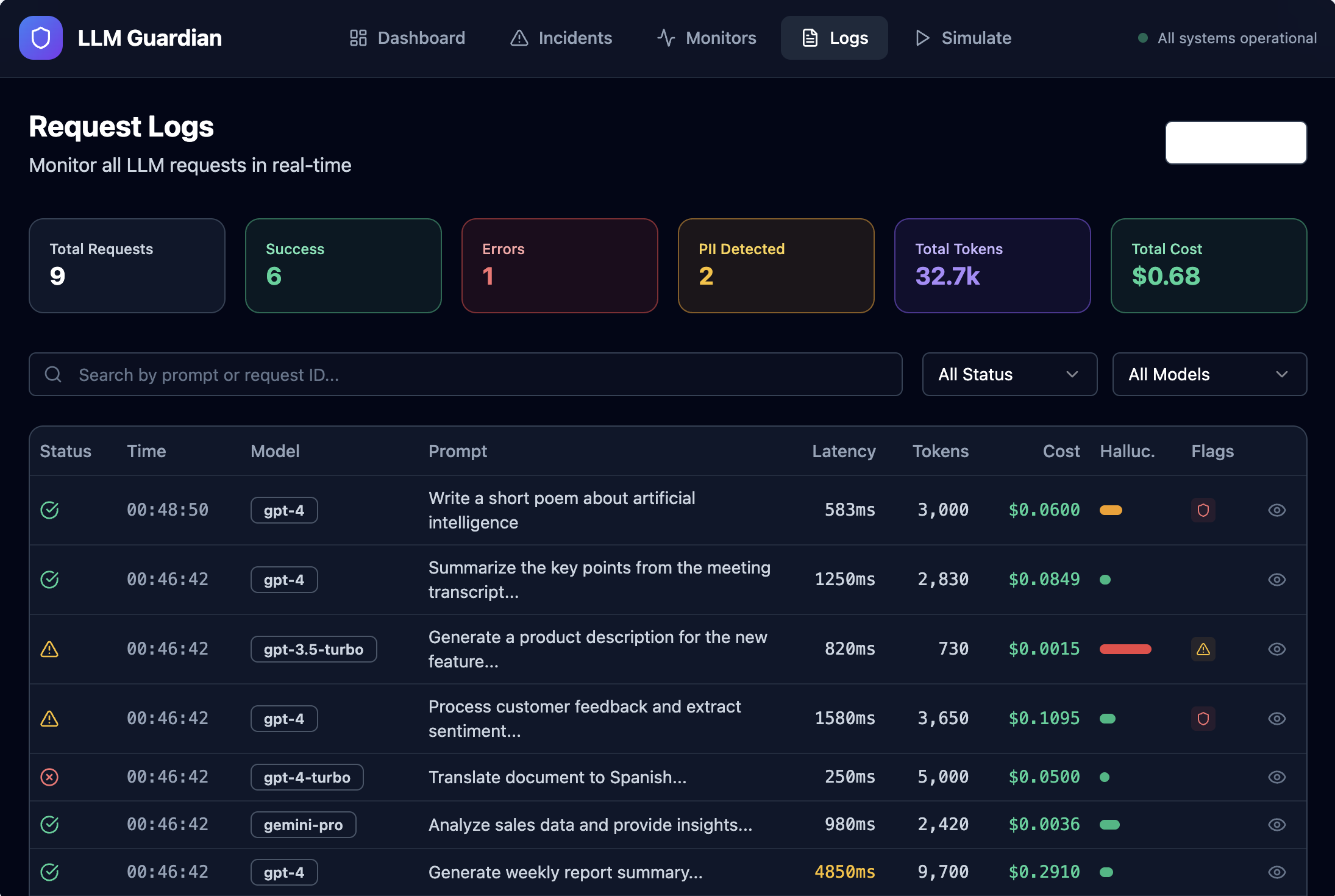
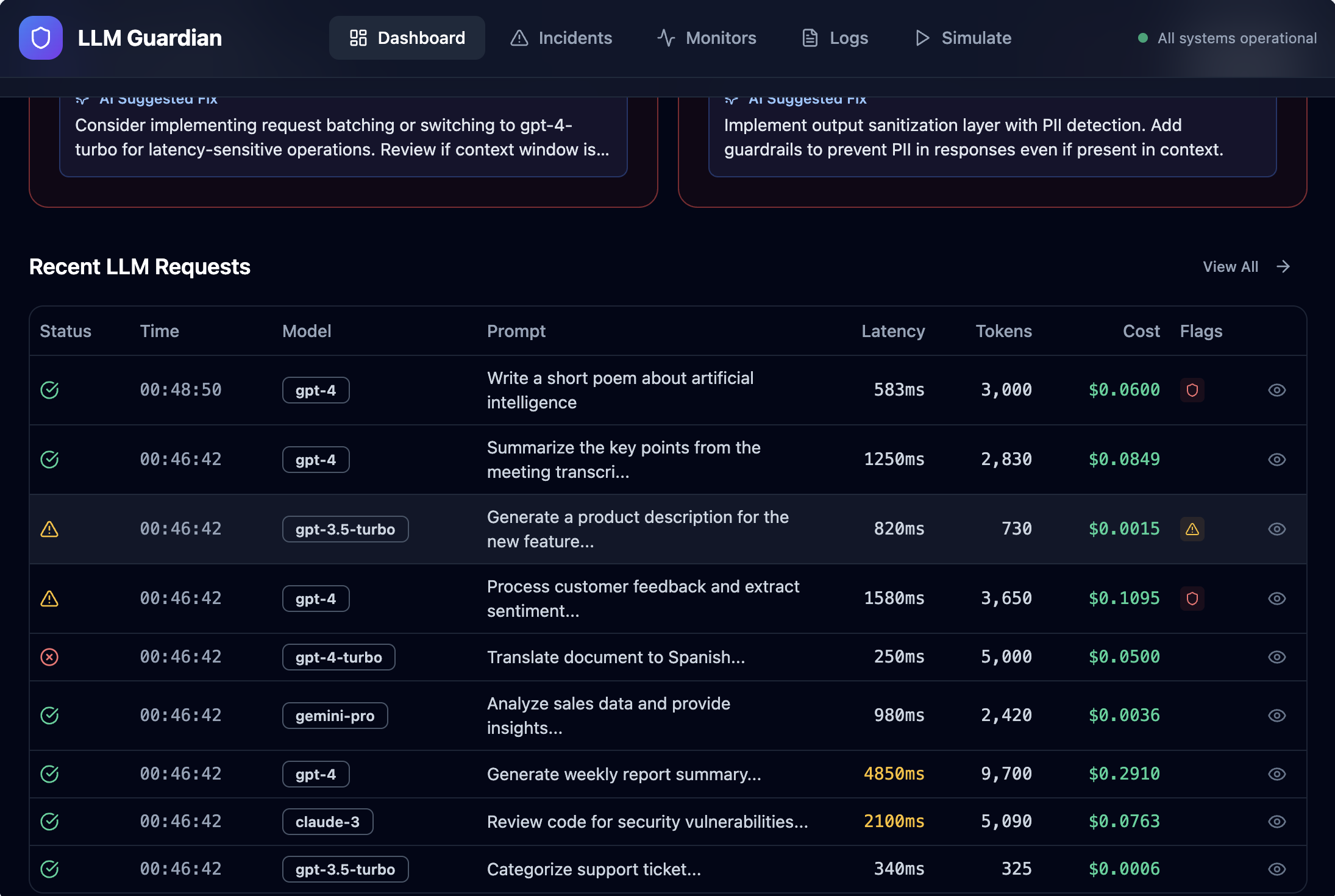
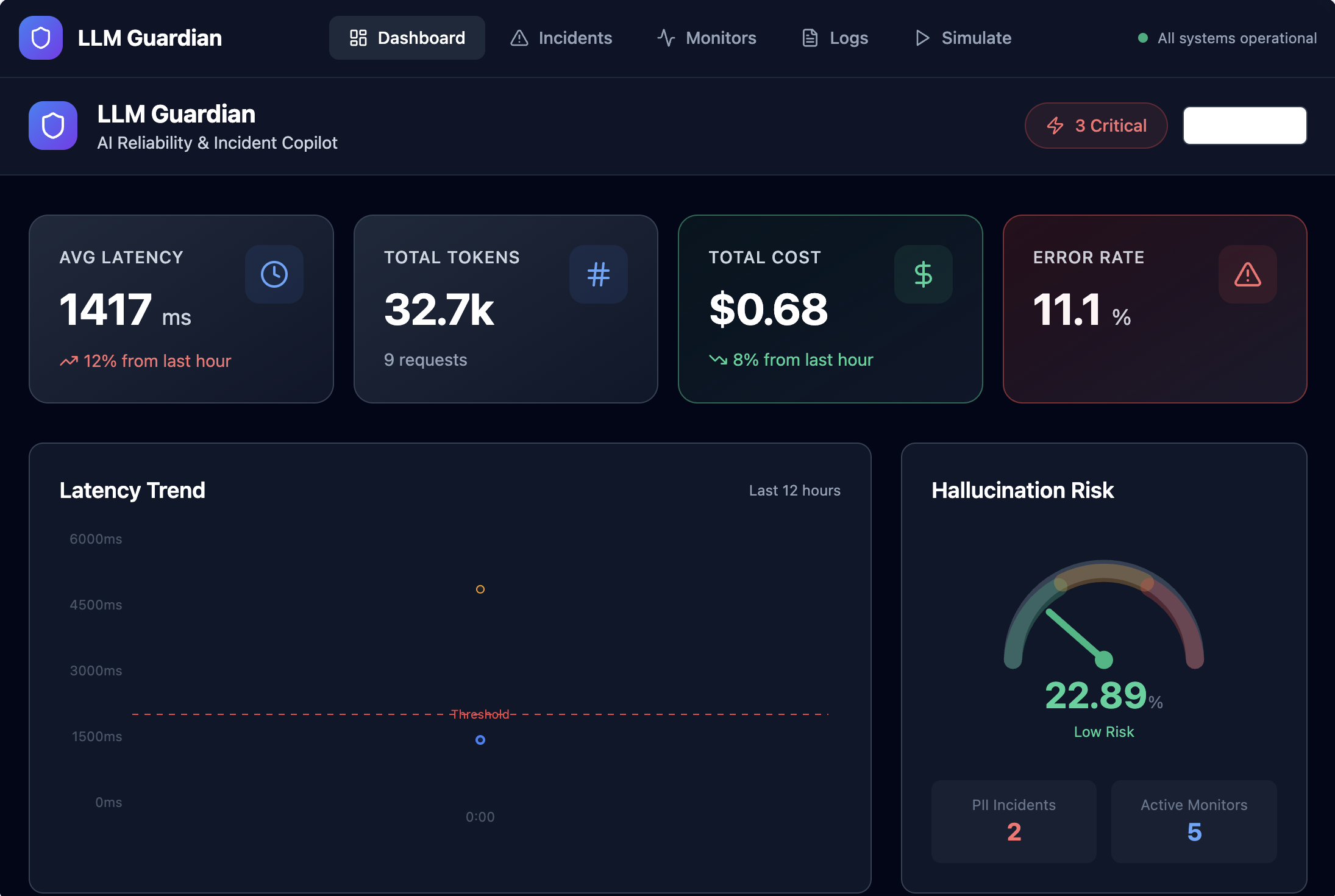
- Capture LLM runtime telemetry such as latency, token usage, cost, and errors
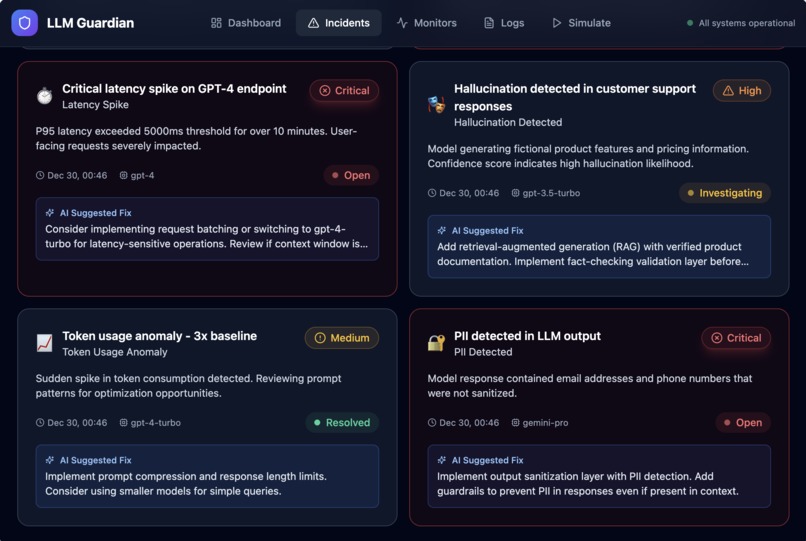
- Surface safety signals including PII detection and hallucination risk
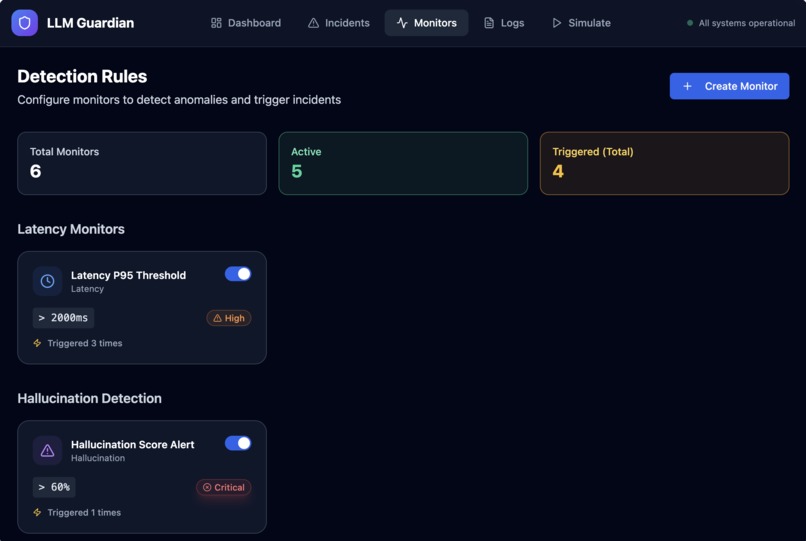
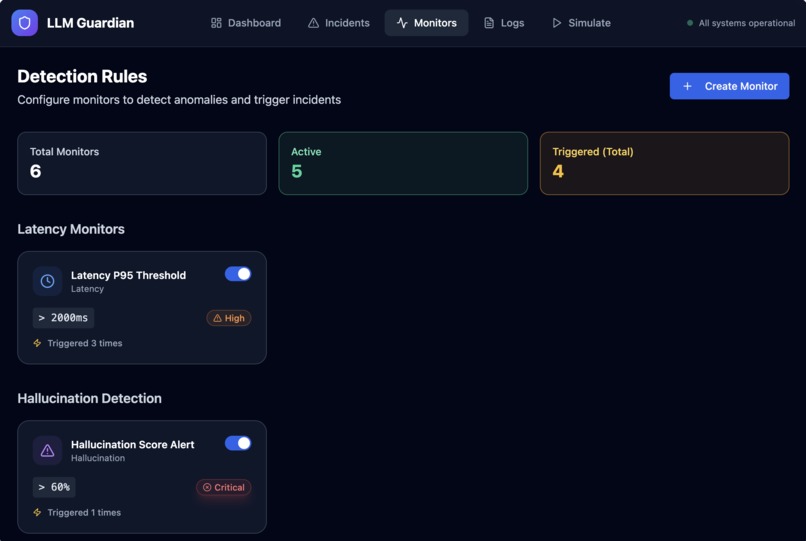
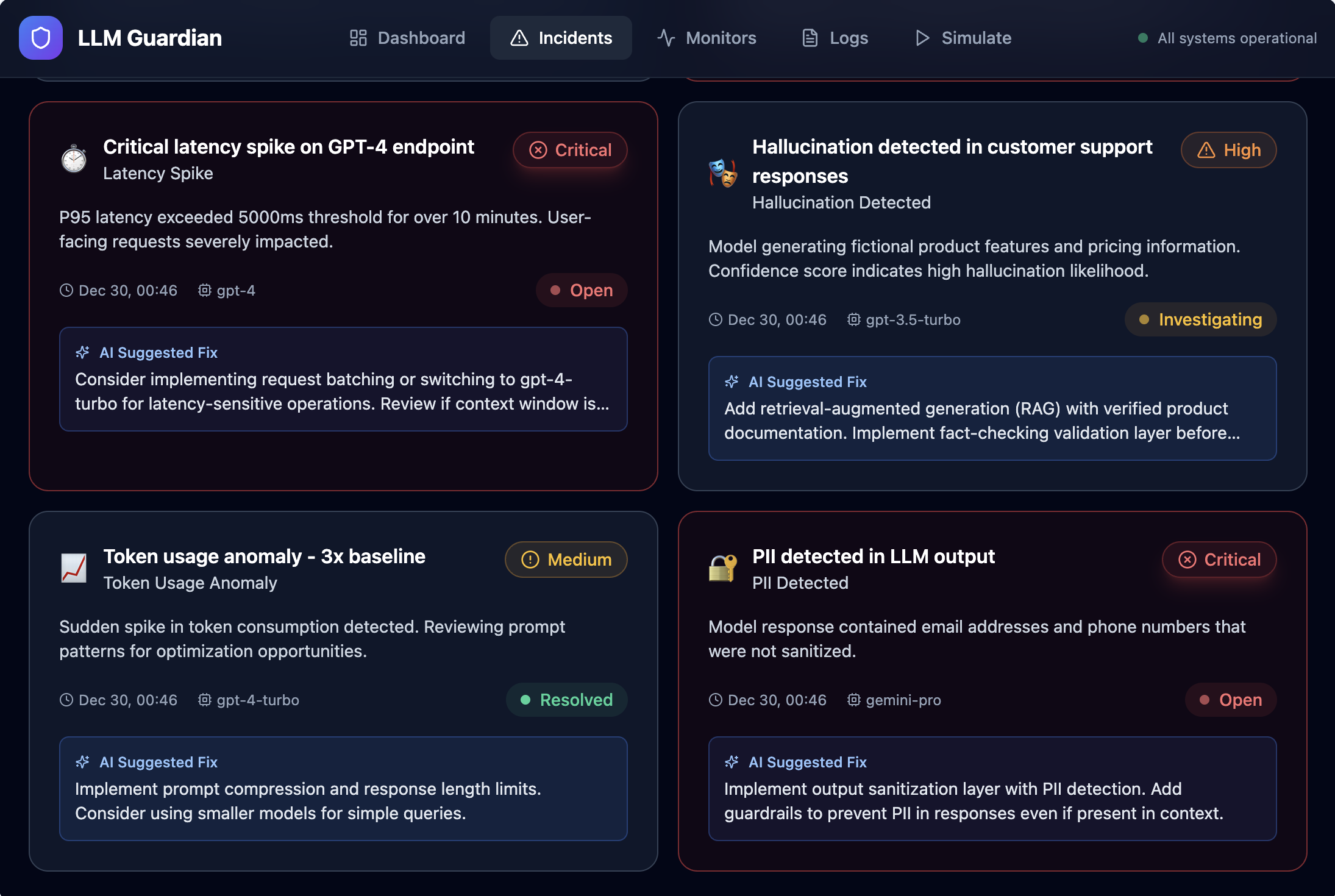
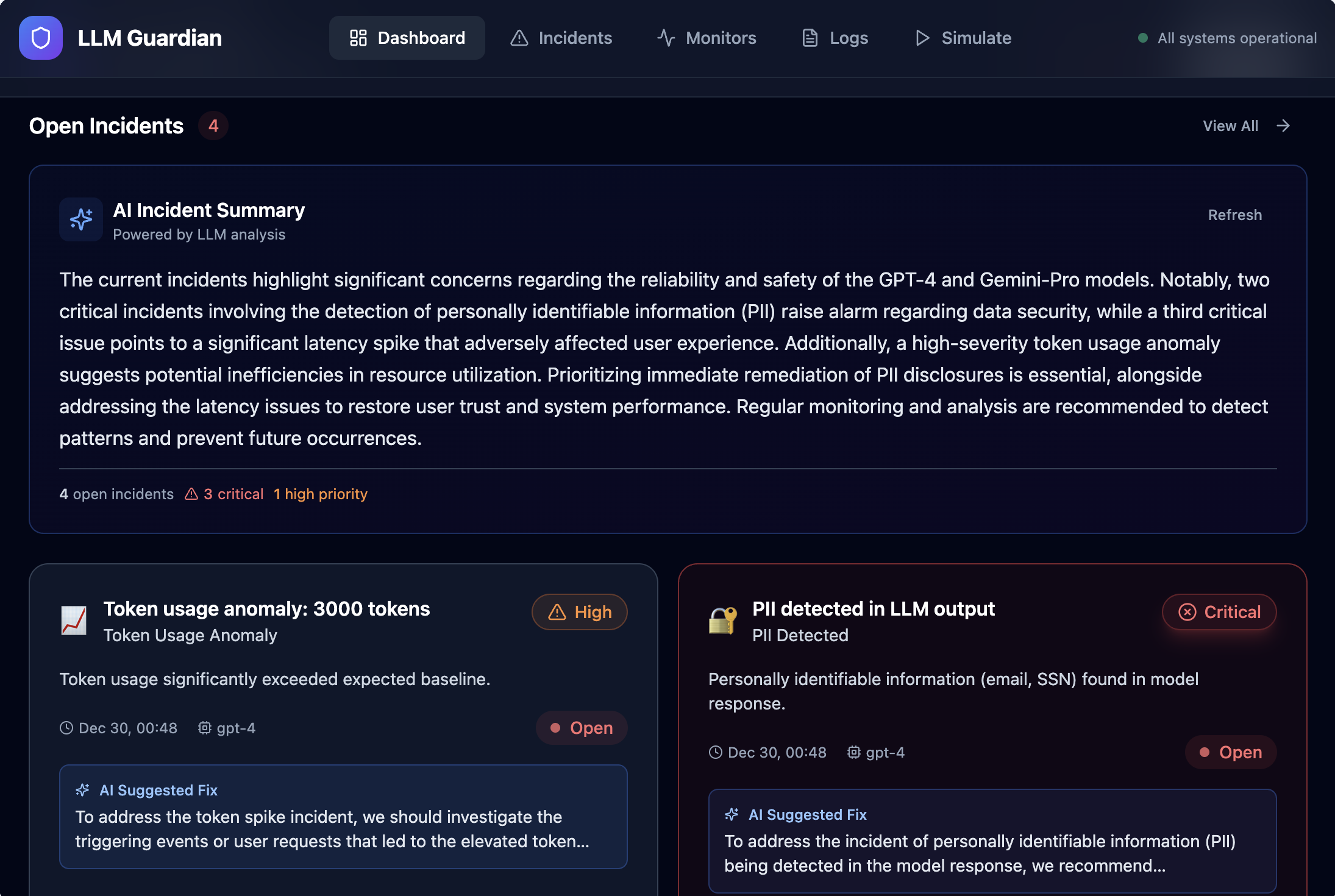
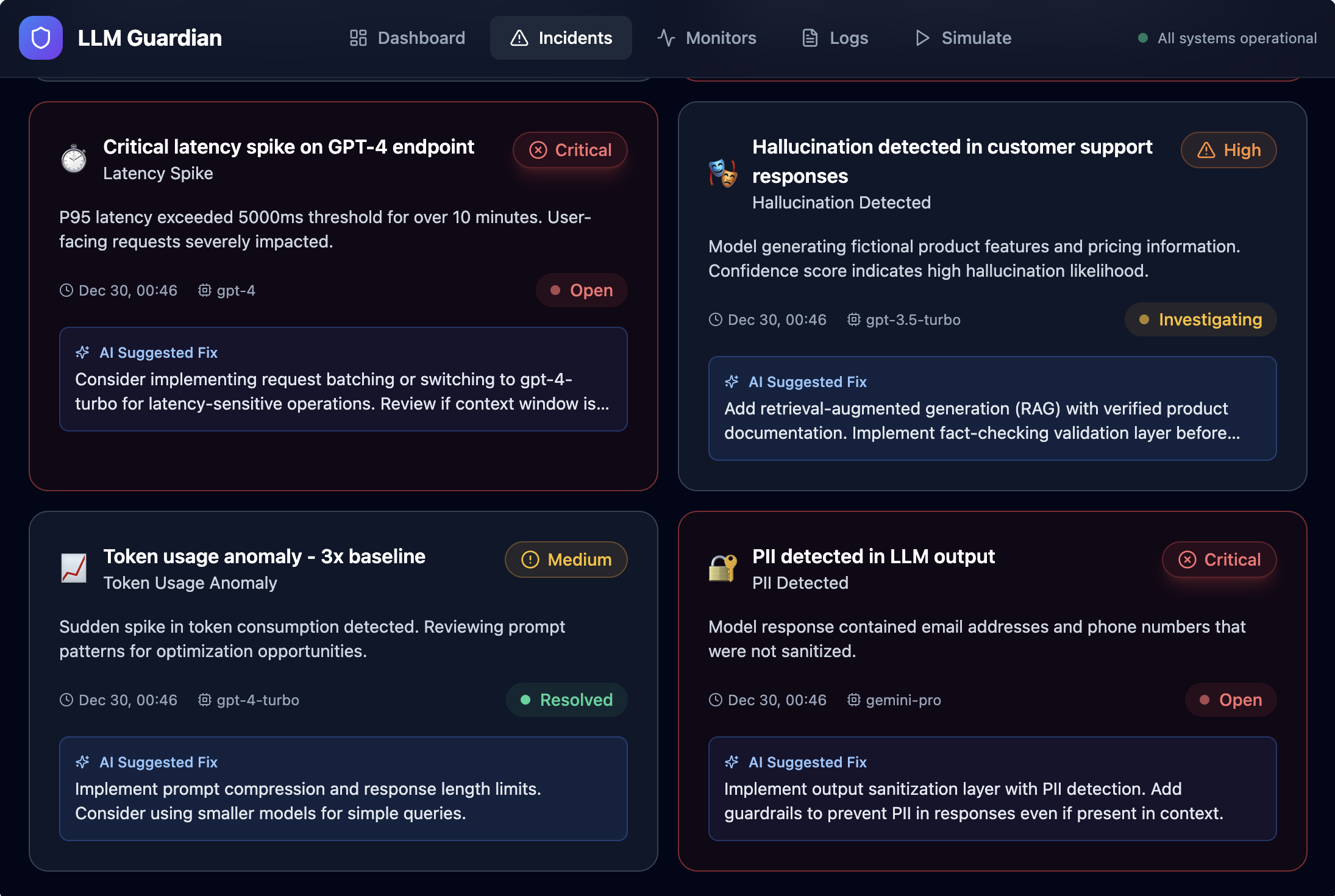
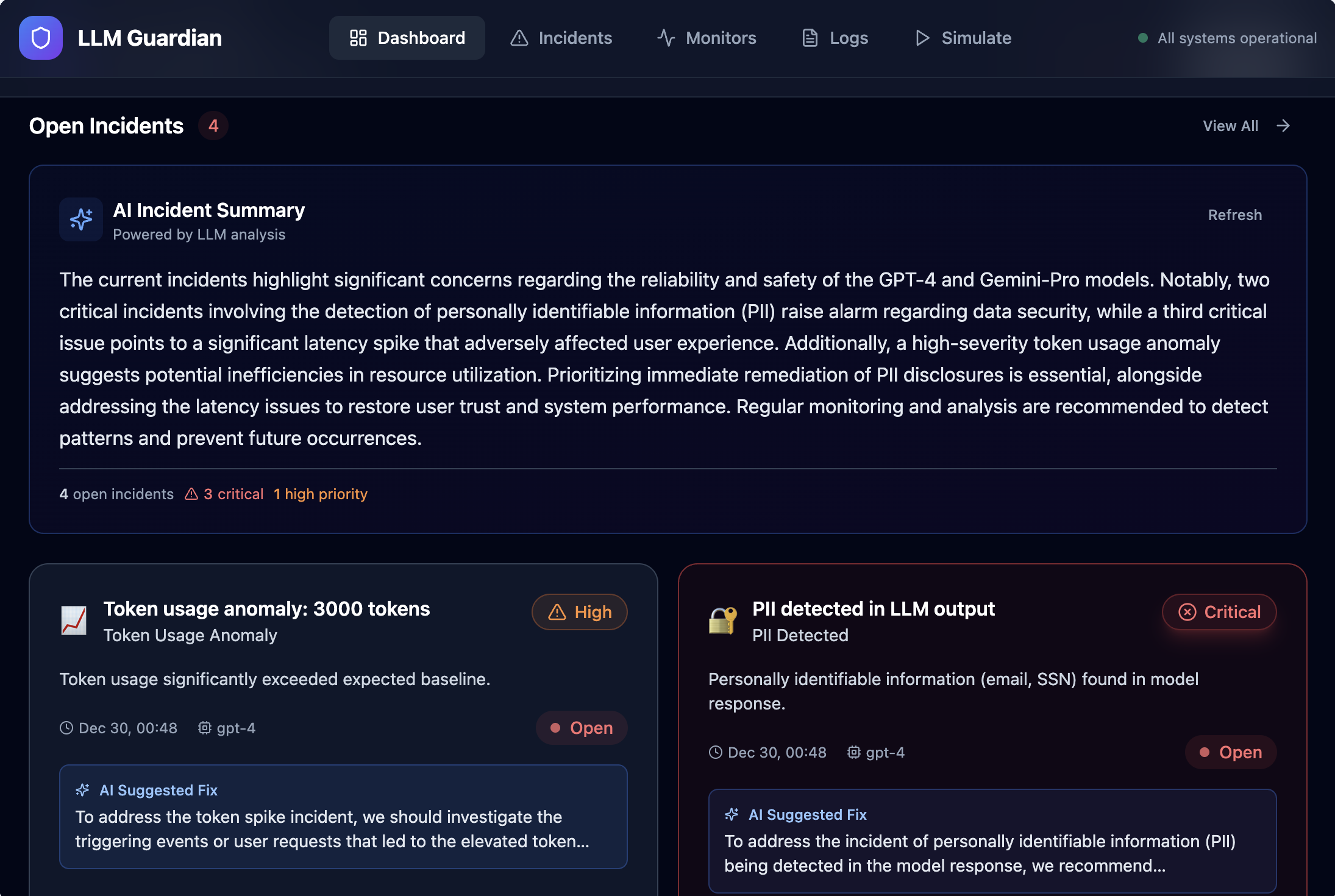
- Apply monitoring rules to detect abnormal or risky behavior
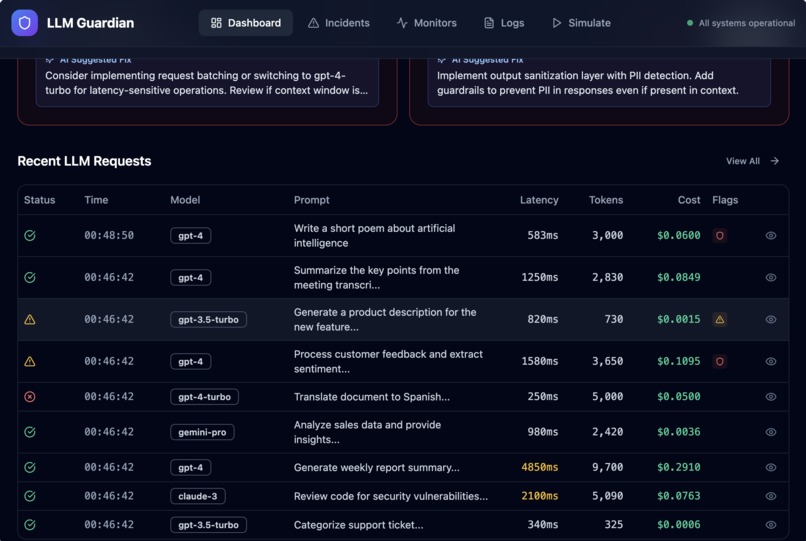
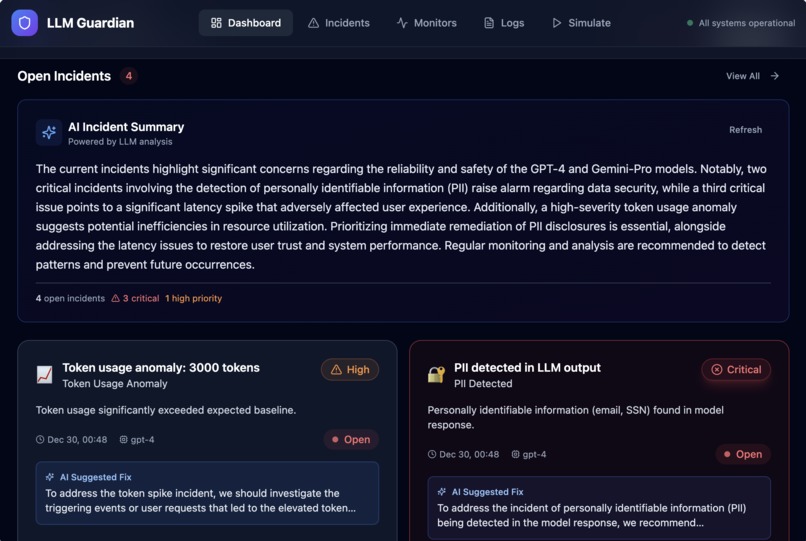
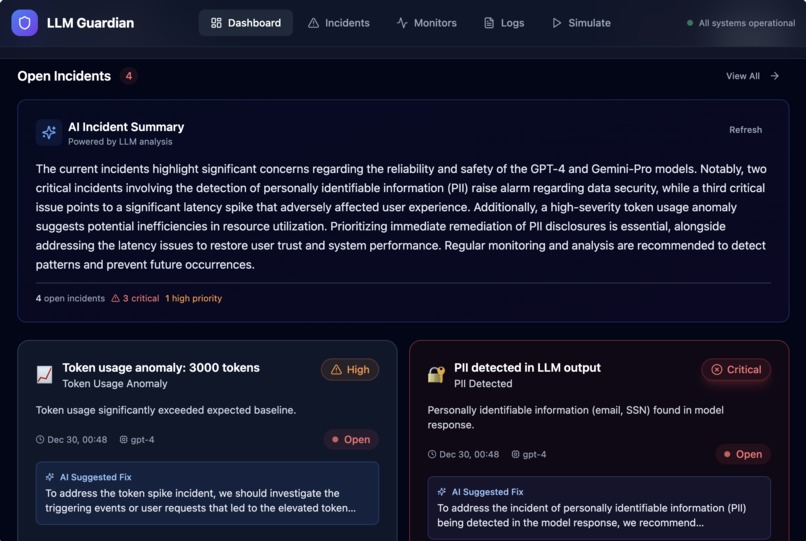
- Automatically generate actionable incidents with severity and AI-suggested fixes
- Provide a real-time dashboard that gives a clear view of LLM health
Instead of raw logs, the platform turns LLM behavior into clear, actionable signals—before issues impact users.
How I built it
- Frontend: Next.js + React with Tailwind CSS and Recharts for dashboards
- Backend: Next.js API routes for LLM requests, telemetry ingestion, and incident creation
- Database: Supabase Postgres
- ORM: Prisma for schema management and database access
- State & Data Fetching: TanStack React Query
- AI: Google Cloud AI (Gemini / Vertex AI integration)
- Observability: Datadog for metrics, logs, and LLM-focused telemetry
Telemetry is captured at request time, evaluated against monitoring rules, and written as structured incidents to the database. These incidents are visualized in the dashboard and sent to Datadog for monitoring and alerting.
Challenges I ran into
- LLM observability is still emerging: Defining meaningful signals like hallucination risk required going beyond traditional metrics.
- Serverless and database migrations: Getting Prisma migrations to run reliably in a serverless environment required careful configuration.
- Balancing safety and usability: I focused on making safety signals actionable without overwhelming engineers with noise.
- Integrating multiple platforms: Coordinating Google Cloud AI, Datadog, and Supabase while keeping the architecture clean and maintainable.
Each challenge pushed me to design a more robust, production-ready system.
Accomplishments that I’m proud of
- Built a fully functional, end-to-end LLM observability platform
- Transformed raw telemetry into actionable incidents, not just dashboards
- Successfully integrated Datadog for monitoring and alerting
- Designed a clean, intuitive UI that makes complex AI behavior understandable
- Delivered a solution that feels enterprise-ready, not just a prototype
What I learned
- Observability for LLMs must go beyond infrastructure metrics and include domain-specific AI signals
- Safety and reliability are operational challenges, not just model-level problems
- Clear incident context is far more valuable than raw data
- Production AI systems benefit greatly from the same monitoring discipline used in traditional software systems
What’s next for LLM Guardian
- Deeper Datadog integration: custom dashboards, alerts, and automated remediation
- Advanced safety models: improved hallucination and PII detection using AI-driven scoring
- Multi-model support: comparing behavior across models and versions
- Enterprise features: role-based access, audit logs, and SLA tracking
- Streaming telemetry: real-time insights using event pipelines
My goal is to make operating LLMs in production as reliable, transparent, and accountable as operating any critical cloud service.
Built With
- datadog
- github
- google-cloud-ai-(gemini-/-vertex-ai)
- next.js
- node.js
- prisma
- react
- recharts
- supabase-postgresql
- tailwind-css
- tanstack-react-query
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.