

🛡️ LLM Guardian: The Future of Voice-Driven LLMOps on AWS
🌟 What Inspired Us
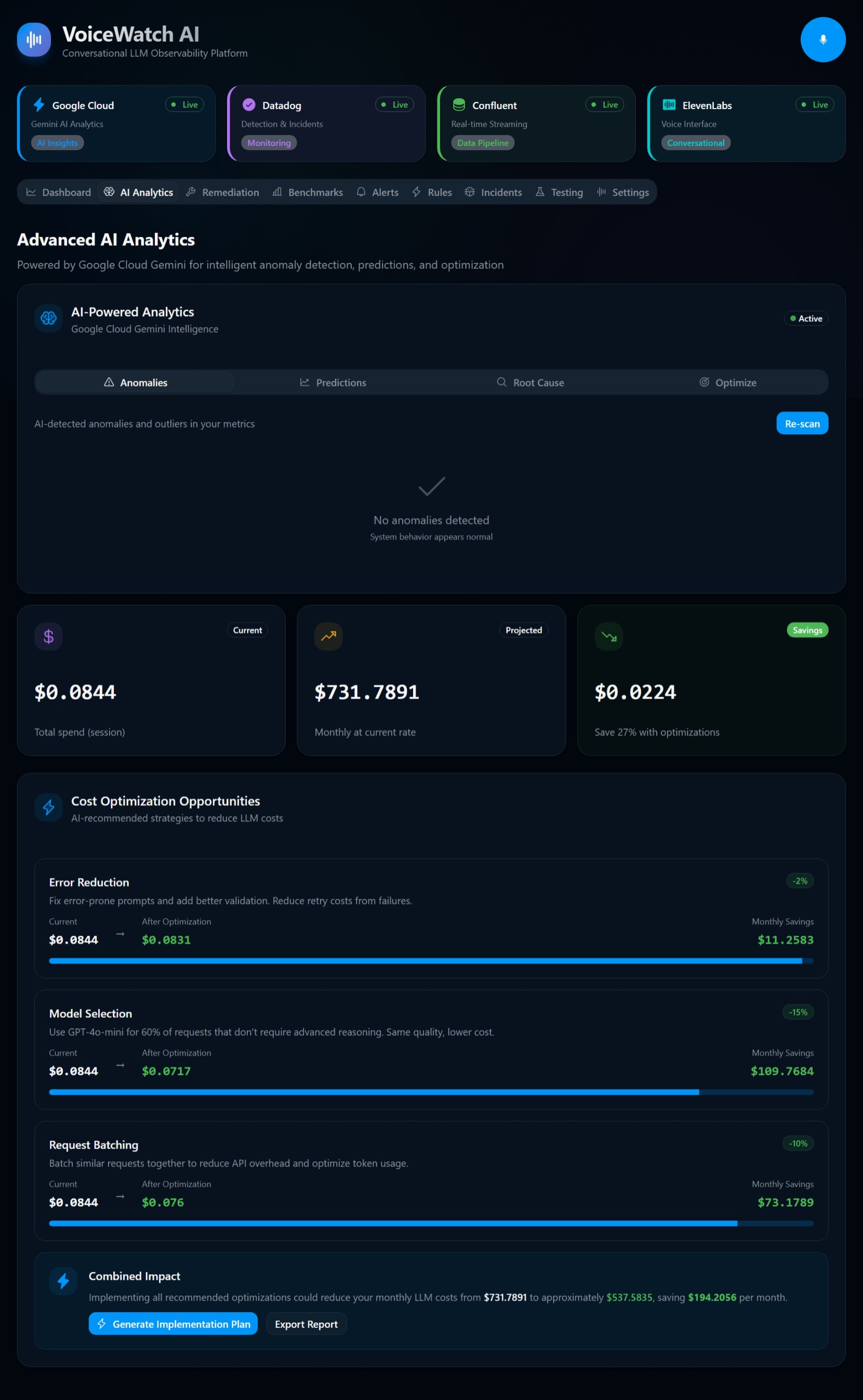
As Large Language Models (LLMs) transition from experimental playgrounds to mission-critical enterprise production, a new paradigm of observability is required. Traditional dashboards are passive; they require engineers to proactively hunt for anomalies. We asked ourselves: What if your monitoring system could talk to you, powered by the most advanced cloud infrastructure available?
The inspiration for LLM Guardian was born out of the "black box" nature of AI operations at scale. We wanted to build an active, voice-driven AI monitoring dashboard that doesn't just display charts, but intelligently speaks to you about systemic health, data drift, and latency spikes. By pivoting to deeply integrate Amazon Nova AI and the broader AWS ecosystem, we set out to create the ultimate enterprise LLMOps guardian—a system deployed entirely on AWS that monitors the AI, using AI, and communicates like a human. 🧠🎙️
🏗️ How We Built It (Architecture & Fundamentals)
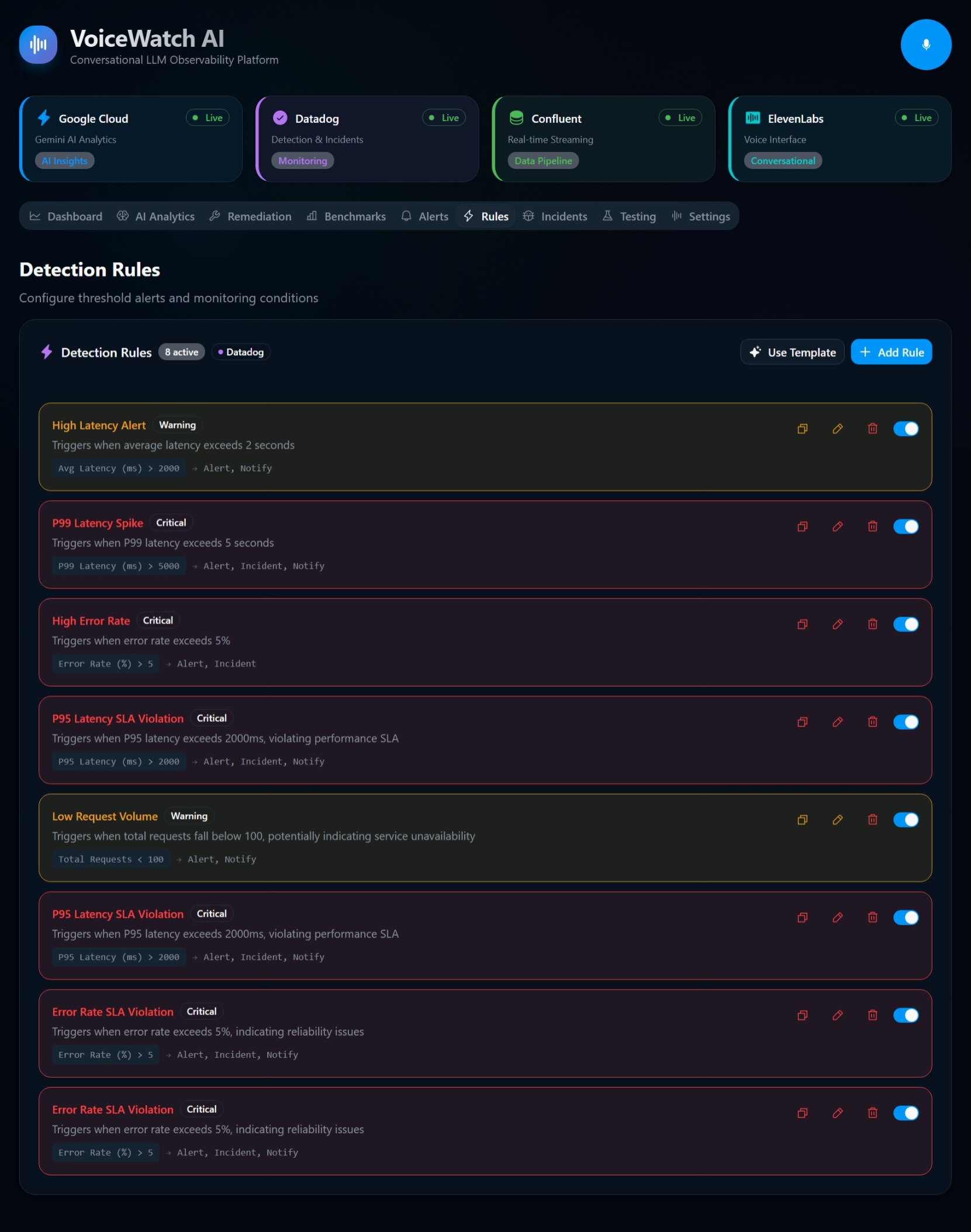
LLM Guardian is engineered primarily in TypeScript (96.6% of the codebase), utilizing a robust, serverless, and event-driven microservices architecture hosted on AWS to process high-throughput LLM telemetry.
Here is how we orchestrated our AWS-Native Tech Stack:
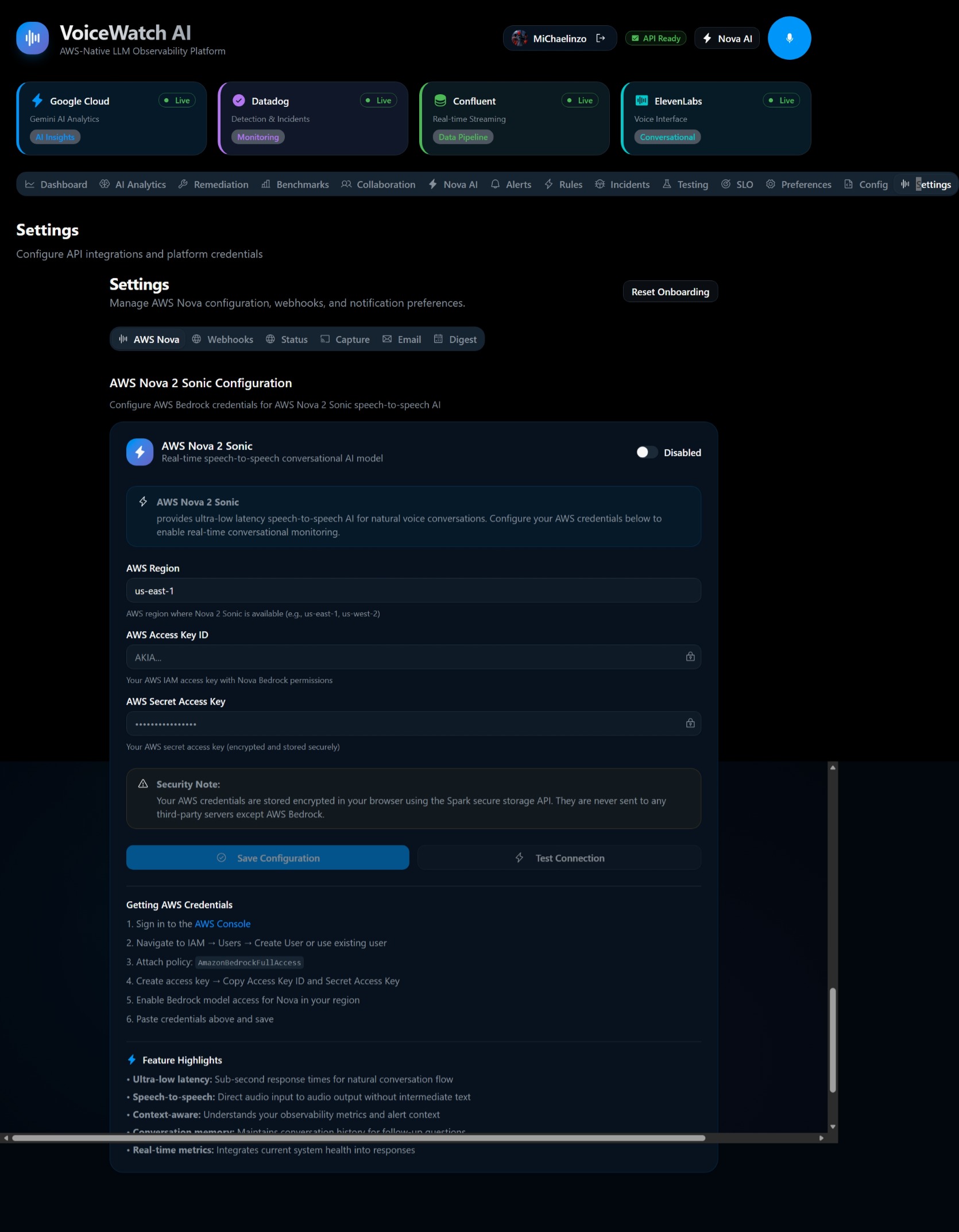
🧠 Amazon Nova via Bedrock (The Analytical Brain): At the core of our semantic monitoring is Amazon Nova (specifically Nova Pro for deep reasoning and Nova Lite for fast triage), accessed seamlessly through Amazon Bedrock. Instead of relying on static threshold alerts, Nova processes the aggregated logs and prompt/response pairs to perform semantic anomaly detection—understanding the context of hallucinations, prompt injections, or degraded response quality rather than just counting error codes.
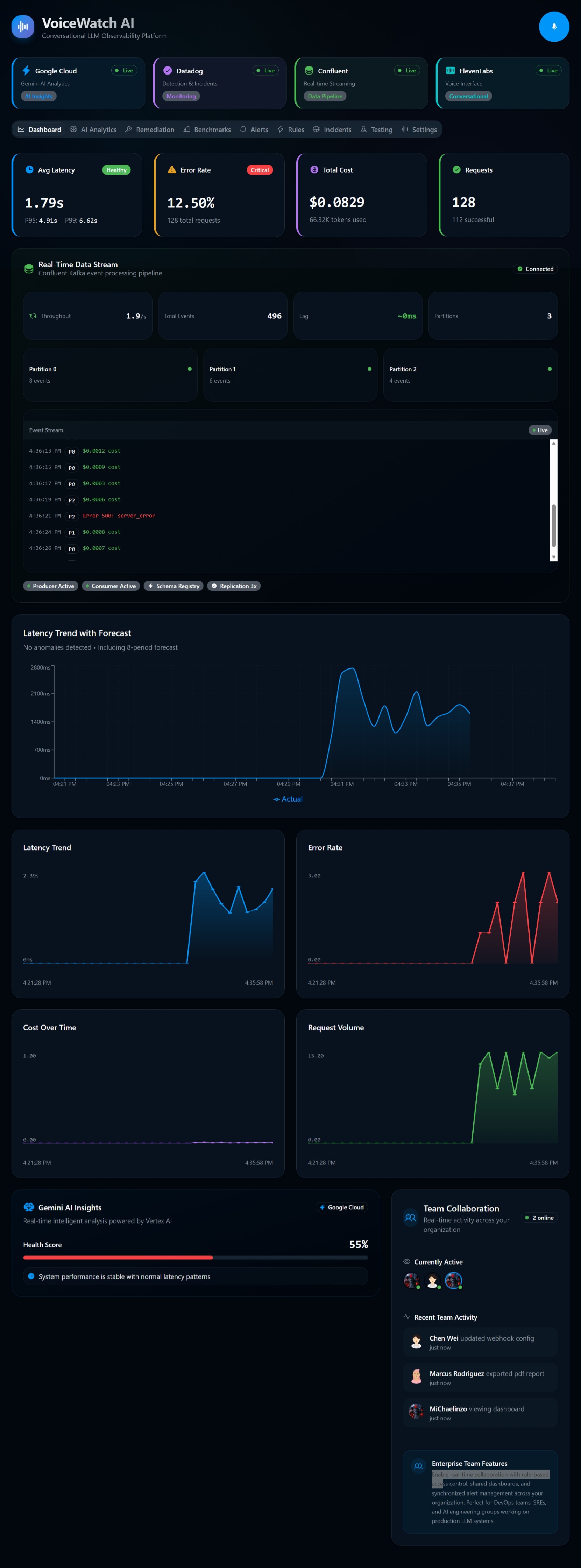
🌊 Amazon MSK & Kinesis (Real-Time Event Streaming): We treat every LLM interaction (prompt, response, latency, token count) as a discrete event. We utilized Amazon Managed Streaming for Apache Kafka (MSK) and Amazon Kinesis as the central nervous system. This highly scalable ingestion layer decouples our API endpoints from our analytics engine, ensuring that massive spikes in LLM usage don't bottleneck the monitoring pipeline.
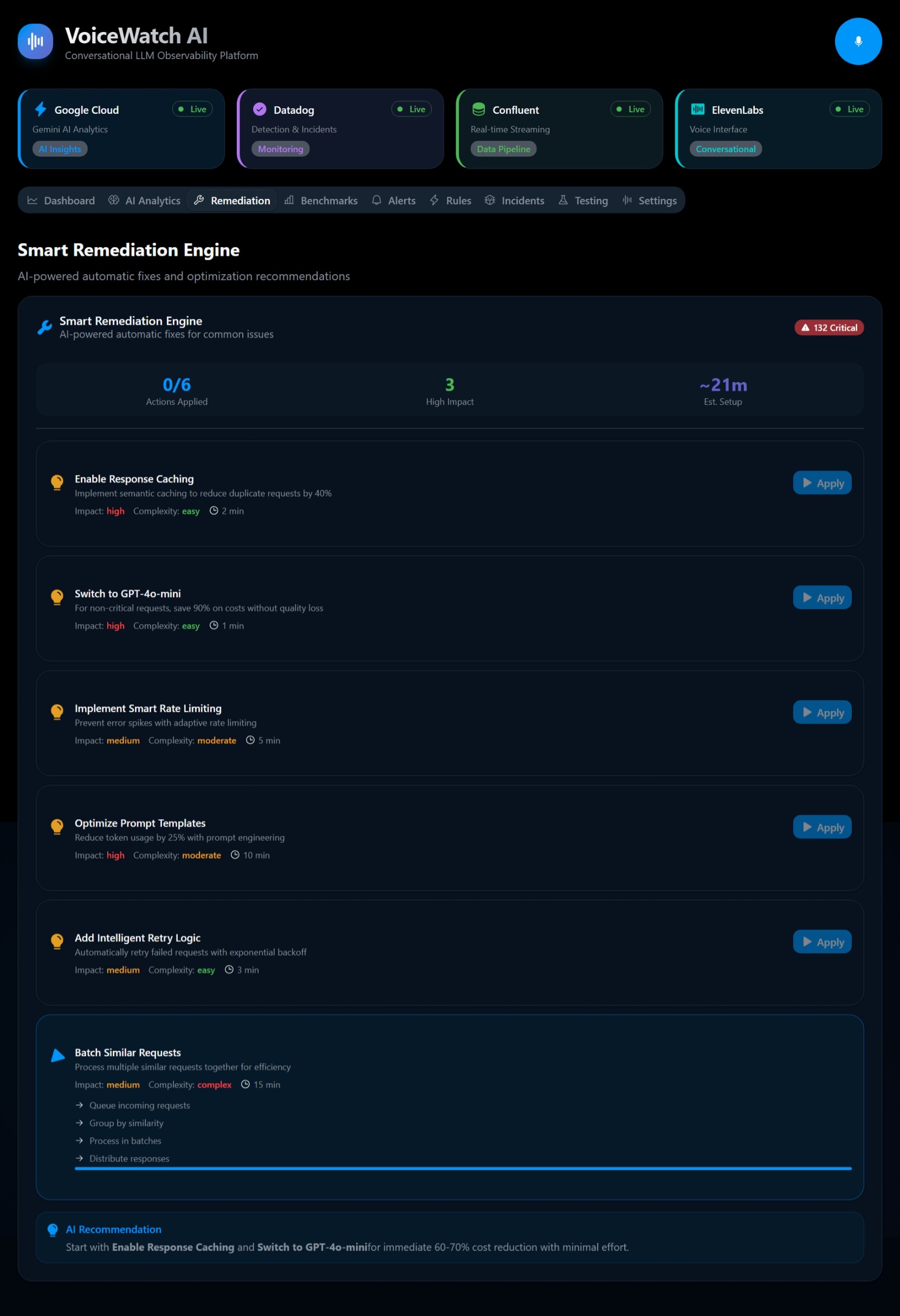
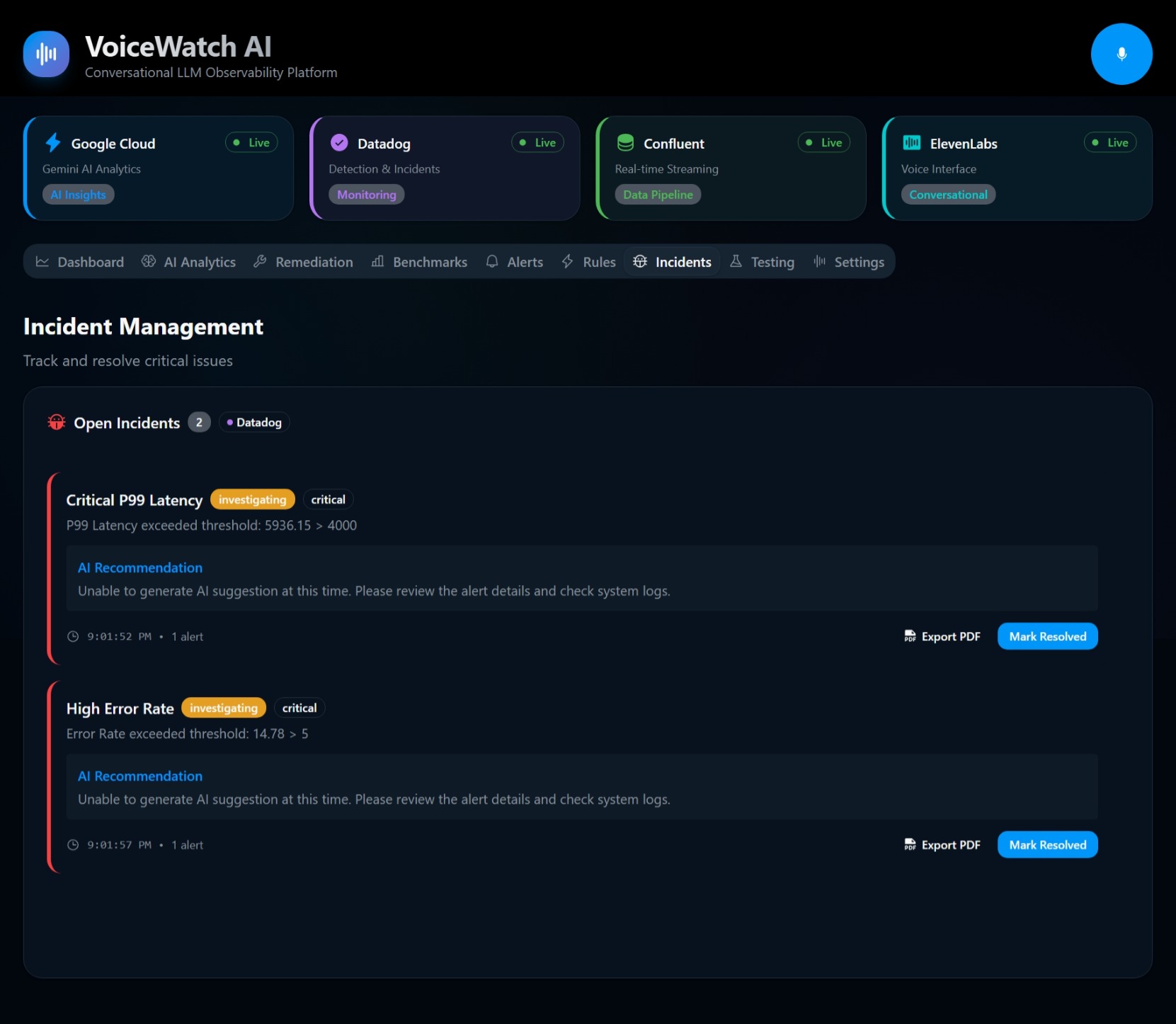
⚡ AWS Lambda & EventBridge (Serverless Orchestration): Our TypeScript microservices run on AWS Lambda, triggered by Amazon EventBridge. This serverless architecture allows us to scale out infinitely based on traffic. When an anomaly is detected, Lambda functions orchestrate the workflow between Bedrock, our time-series databases, and the voice synthesis layer.
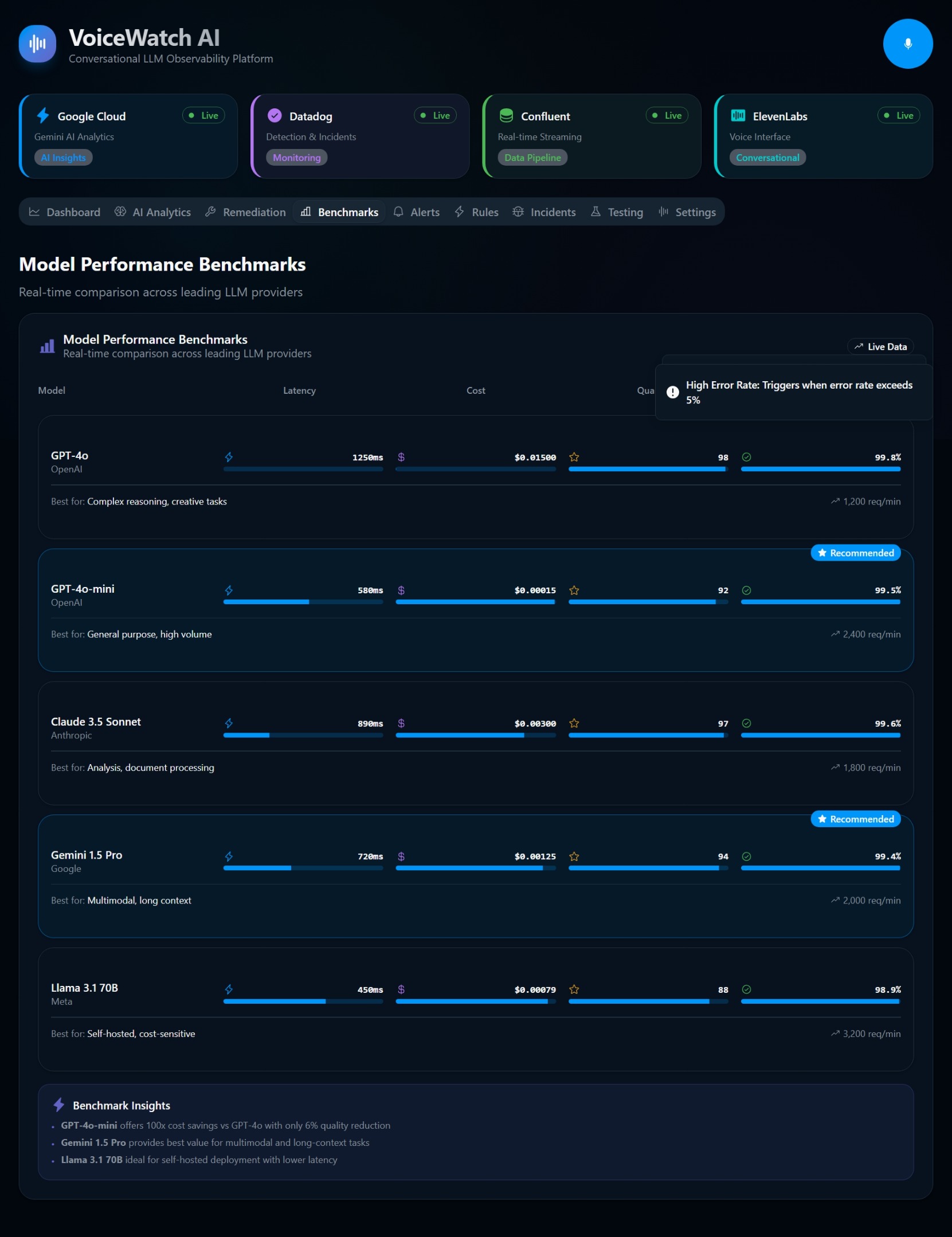
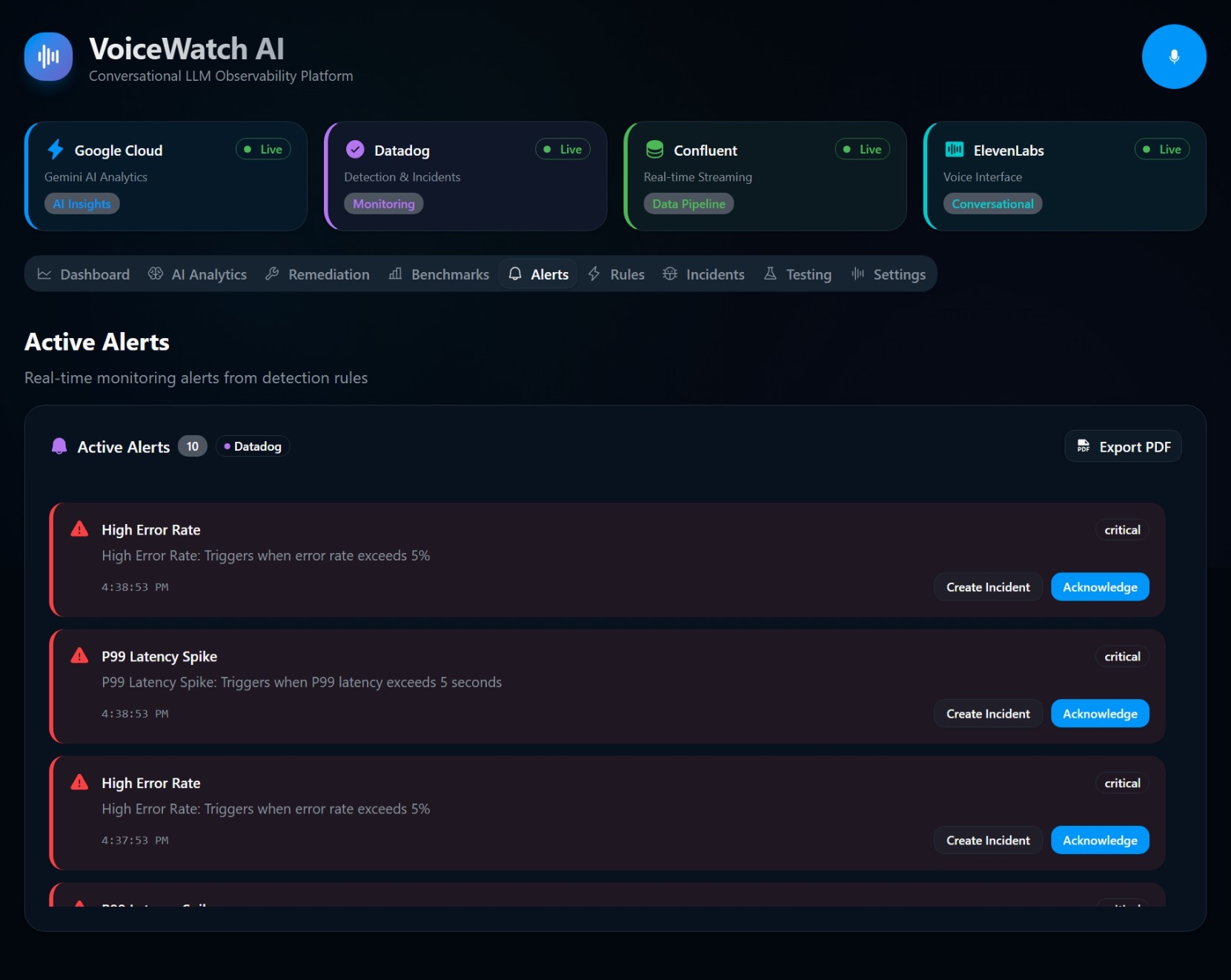
📊 Datadog & Amazon CloudWatch (Observability & APM): Events from MSK are piped into Datadog and Amazon CloudWatch. We utilize APM and custom CloudWatch metrics to track exactly what's happening at the infrastructure layer. We monitor key LLMOps metrics like Time to First Token (TTFT), token generation rates, and Nova API costs.
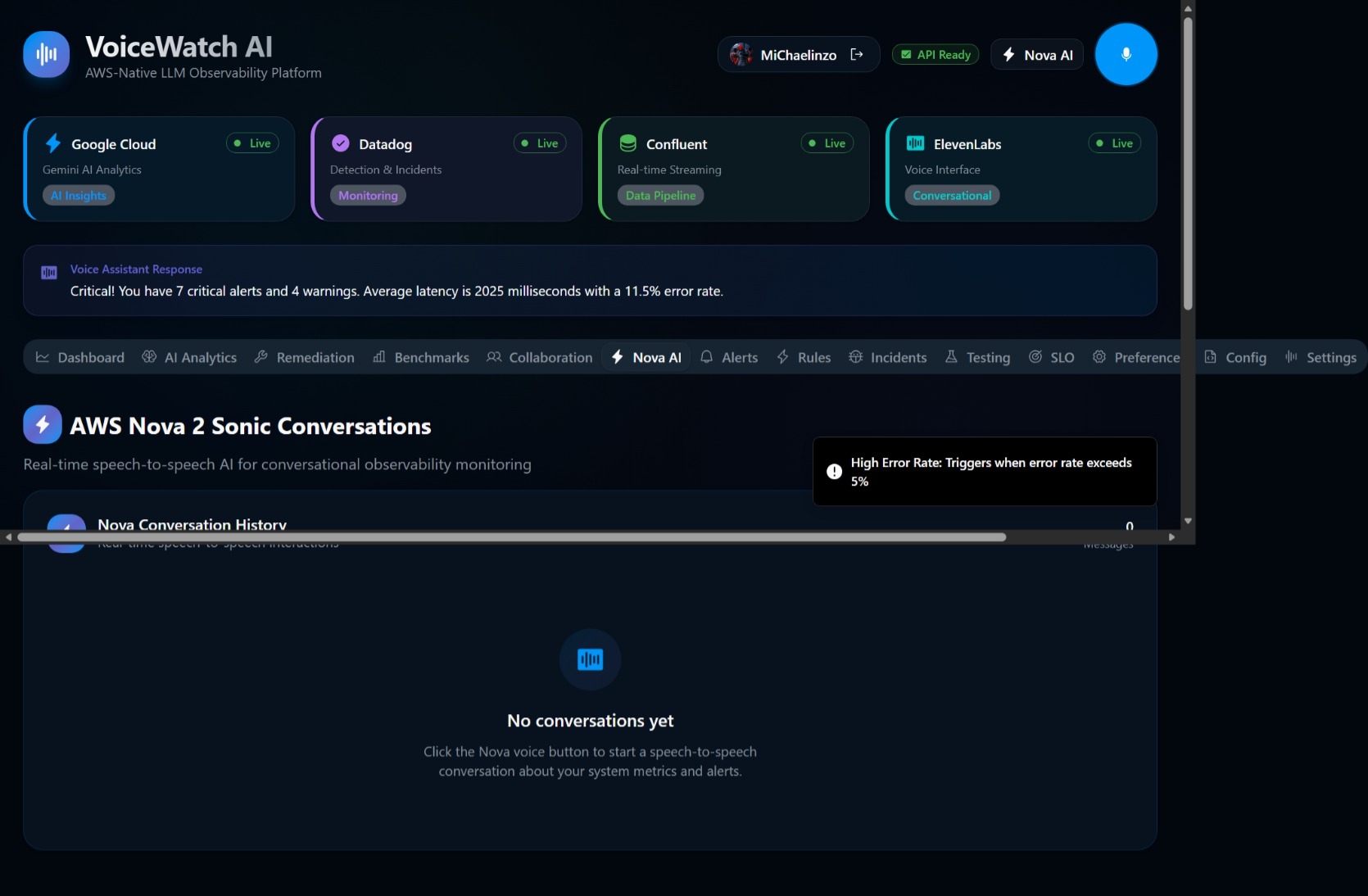
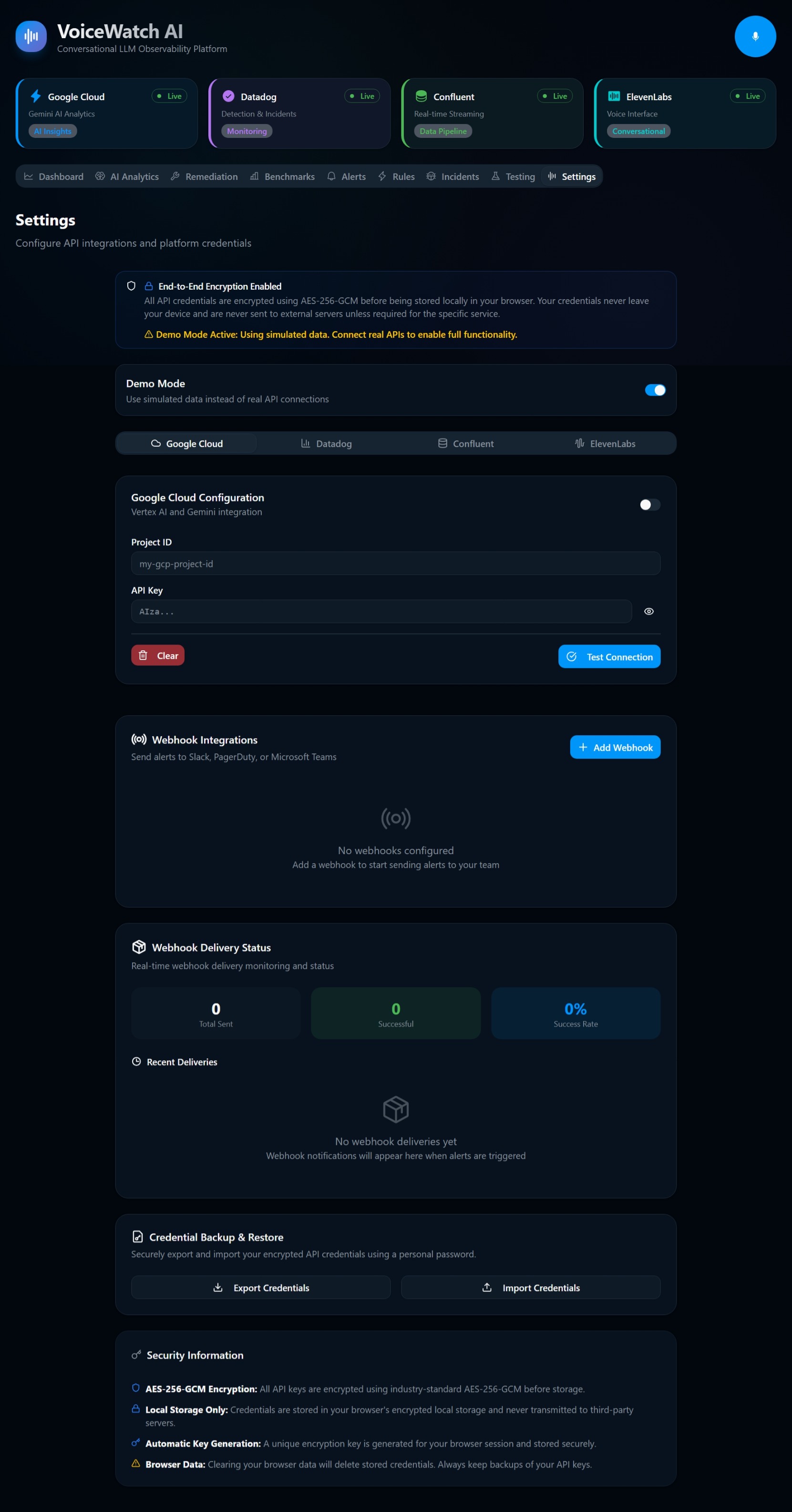
🗣️ Voice Integration: When Amazon Nova identifies a critical anomaly, it generates a concise, conversational summary of the root cause. This text is then passed to our Text-to-Speech engine (combining AWS audio processing with ElevenLabs for ultra-realistic TTS), converting the telemetry into an urgent, human-like voice alert for the on-call engineer.
🧮 The Math Behind the Monitoring
To prevent alert fatigue, we rely on statistical foundations rather than hardcoded thresholds. For example, to detect latency anomalies in token generation, we compute the exponential moving average (EMA) and variance of the Time to First Token (TTFT).
An alert is evaluated by Amazon Nova only when the current latency $x_t$ deviates significantly from the moving average $\mu_t$, calculated via a dynamically updating Z-score:
$$ Z_t = \frac{x_t - \mu_t}{\sigma_t} $$
Where $\mu_t$ and the variance $\sigma_t^2$ are updated iteratively: $$ \mu_t = \alpha x_t + (1 - \alpha)\mu_{t-1} $$ $$ \sigma_t^2 = \alpha (x_t - \mu_t)^2 + (1 - \alpha)\sigma_{t-1}^2 $$
If $Z_t > 3$ (a 3-sigma event) and the traffic volume meets a minimum threshold, AWS Lambda triggers a high-priority event, Amazon Nova synthesizes the contextual root cause, and the voice engine speaks the alert. 🚨
🧗 Challenges We Faced
Building a multi-tenant, real-time audio-visual dashboard strictly within the AWS ecosystem was no easy feat.
- Navigating IAM & VPCs: Securing the pipeline across Amazon MSK, Lambda, and Bedrock required rigorous IAM role structuring and VPC endpoint configurations to ensure zero public internet exposure for our sensitive telemetry data.
- Optimizing Bedrock Quotas: Streaming large batches of telemetry into Amazon Nova models meant we had to carefully manage API rate limits. We implemented intelligent exponential backoff and jitter algorithms in TypeScript to handle
ThrottlingExceptionerrors gracefully. - LLM Latency vs. Voice Latency: Generating the analysis via Amazon Nova and then piping it for TTS introduced multi-second latency. We had to utilize Amazon Bedrock's streaming response capabilities (
InvokeModelWithResponseStream) and pipe the chunks directly into our audio processing buffer to ensure the dashboard felt truly real-time.
🧠 What We Learned
This project was an incredible masterclass in Enterprise LLMOps on AWS.
- The Power of Amazon Nova: We were blown away by the speed and reasoning capabilities of the Nova models. Using Nova Lite for fast categorization and Nova Pro for deep root-cause analysis proved to be a highly cost-effective and powerful architectural pattern.
- Serverless Streaming: We leveled up our understanding of AWS MSK and Kinesis, learning how to build resilient, distributed event-driven systems using pure TypeScript and AWS CDK.
- Semantic Observability: We discovered that monitoring AI requires a shift from deterministic rules to probabilistic guardrails. Combining mathematical drift detection (like our Z-score implementation) with Nova's semantic evaluation creates an incredibly robust safety net.
LLM Guardian isn't just a dashboard; it's a living, breathing sentinel powered by AWS and Amazon Nova for the next generation of enterprise AI applications. 🚀🌌
Built With
- amazon-web-services
- confluent
- datadog
- elevenlabs
- framer-motion
- kafka
- nova
- nova-ai
- react
- shadcn-ui
- tailwind-css
- typescript
- vite
- web-speech-api








Log in or sign up for Devpost to join the conversation.