-
-
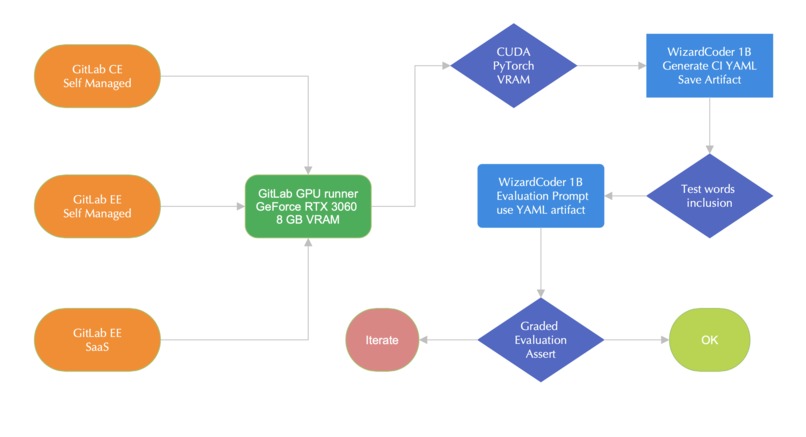
Code LLM graded evaluation with gitlab GPU runner (pseudo-)logic diagram of infrastructure components alongside CI pipeline stages and jobs.
Inspiration
The recently added feature of running machine learning experiments within Gitlab was the starting inspiration for this project. Extending this from running classical ML algorithms with MLfLow UI towards running and measuring the output quality of recently popular LLMs is also an inspiring prospect. One that comes with both technical challenges and limitations, and potential for large benefits to the Gitlab MLops community and even the entire society, given how widespread the use of LLMs has become.
What it does
Within the emerging field of LLMOps, measuring the quality of LLM generation is not a trivial task. It is often the case that human evaluators do not always agree on how to grade the generated text. Automating this process is even more challenging given the infrastructure resources needed to run LLM inference, nevertheless, integrating such an evaluation in a tight iterative development cycle can have enormous benefits when developing AI applications. This MVP shows a way to do all these by integrating a GPU gitlab runner with only consumer level resources into a continuous integration pipeline that evaluates the quality of a code LLM.
How we built it
We first setup a local Gitlab runner with integrated GPU resources needed to run inference using a code LLM. Then we make the runner available to both locally managed and SaaS running Gitlab instances. With these infrastructure elements in place, we proceed towards developing the stages and jobs of a continuous integration pipeline that runs increasingly complex quality checks for the output of the LLM. To make the POC even more interesting, we prompt a code LLM to generate a gitlab-ci.yaml template file and check the quality of the generated output using both a simple words inclusion, to test that the main expected elements of the structure are present in the text, and a second level of quality control, which uses the LLM graded evaluation technique. This consists in employing a second code LLM, called the Grader, to evaluate the quality of the output from the first LLM. This can be a very efficient technique as it allows for faster iteration and early detection of any degradation in output quality during the development process.
Challenges we ran into
The main challenge was finding a way to meet the resources requirements needed to run not one, but two LLM inference steps, within the confines of a gitlab GPU runner with 8GB of VRAM. Orchestrating the pipeline stages in a way that does not exceed the amount of available GPU memory while running two code LLM inference steps, the generation and the evaluation, was also a challenge. We had to compromise on the size of the model, "only" 1 Billion parameters, and employ a clever use of pipeline artifacts in order to overcame these limitations. Aligning the configuration of the local GPU runner with the Gitlab GPU runners available in the SaaS offering was another challenge that we have only partially overcome, within the timeline of the POC.
Accomplishments that we're proud of
Probably the main accomplishment is the fact that we have managed to achieve all these using only open source software libraries, and one consumer level grade GPU. This shows that, with the coordinated effort and support of the wider MLops and LLMops community, useful AI appications are possible even on a personal laptop, or single board computer infrastructure, and low resources consumer level GPUs can support this journey a long way before larger datacenter-grade infrastructure becomes necessary.
What we learned
We learned many new details about various Gitlab components, especially the Gitlab runner and how to use a GPU inside a CI pipeline. Also we learned a lot about the tradeoffs needed in order to shift left an end to end LLM workflow, especially when local infrastructure is employed. Also we learned many prerequisites that will be useful in the future to furhter align local and cloud based configurations for runners using a Docker executor.
What's next for LLM evaluation with gitlab GPU runners
Several directions for further work have opened while putting together this POC. The setup can be further scaled to handle larger code LLMs, 3 and 7 Billion parameters models can become possible by scaling the GPU vertically: with 16GB, 32GB and 48GB we can improve the size and quality of LLMs we can use, while still remaining in the range of consumer grade GPUs. Using quantization can also help with the vertical scaling. Beyond this, we also plan to scale horizontally inside runners with multiple GPUs and leverage data and model parallelism. With at least two 48GB GPUs we can also scale up from LLM inference tasks towards approaching fine tuning (see the spinoff twin project for an early illustration) and other efficient training techniques with more powerful code LLMs. Enriching the tests with retriever augmented generation and vector embedding search is also a direction the project can grow towards in the future. We already mentioned working towards closer alignment with cloud based and container based runners setups. Developing a component that can also display the evaluation metrics in the merge request GUI would also be a useful addition.



Log in or sign up for Devpost to join the conversation.