-
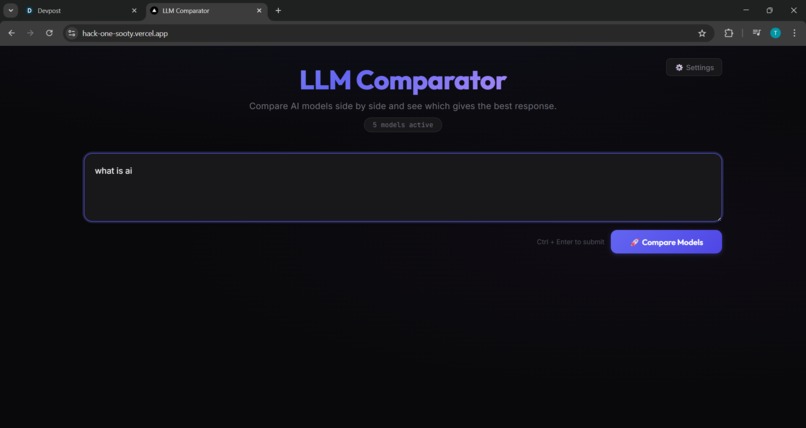
user interface
-
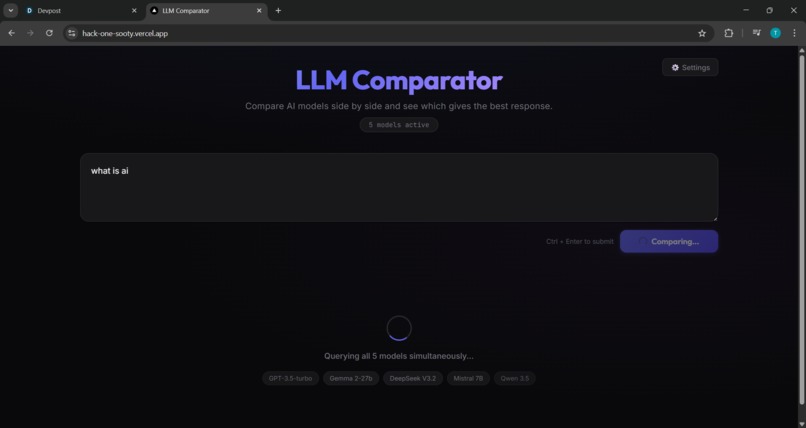
prompt to agent
-
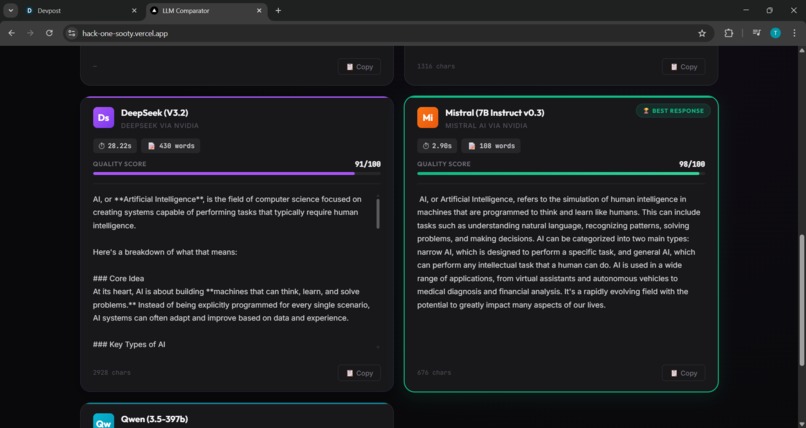
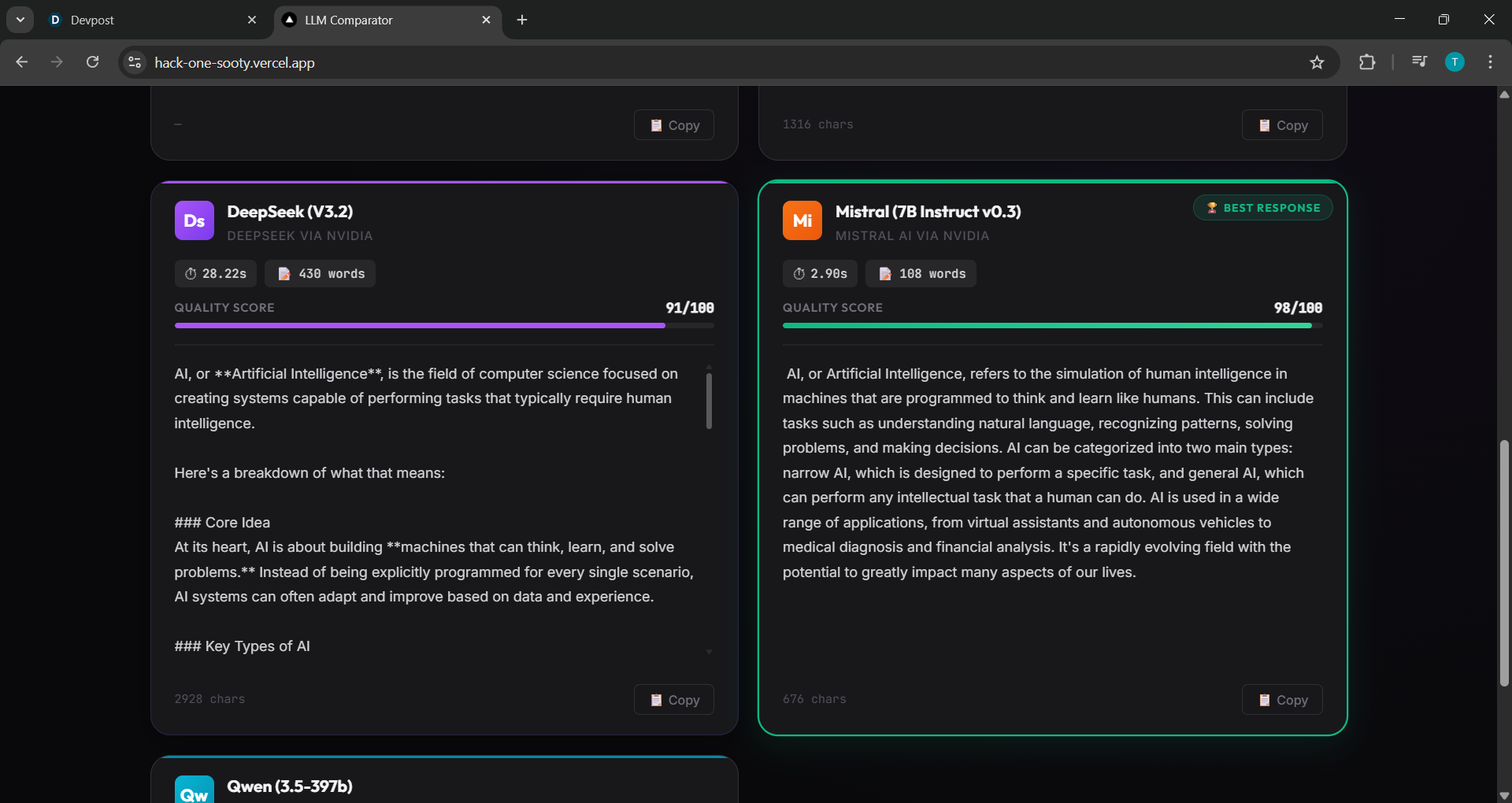
output display
LLM Comparator – Intelligent Multi-AI Answer Analyzer Inspiration
While using different AI tools like ChatGPT, Gemini, and Copilot, I noticed something interesting:
The same question often produces different answers across models.
Sometimes one model explains better. Sometimes another gives more accurate code. Sometimes one is more creative.
But there was no simple way to:
Compare answers side-by-side
Evaluate quality objectively
Automatically choose the best response
That curiosity led me to build LLM Comparator — a platform that aggregates, analyzes, and ranks responses from multiple AI models.
The Problem
Today, users manually:
Copy a prompt
Paste it into multiple AI apps
Compare answers mentally
Decide which one is better
This process is inefficient and subjective.
There is no unified scoring logic.
How I Built It Tech Stack
Next.js (App Router)
TypeScript
Secure API handling using environment variables
Modular API architecture for multi-model support
Clean responsive UI
Architecture Overview
User submits a query
Backend securely calls multiple AI APIs
Responses are collected
A scoring algorithm evaluates answers
Best answer is selected and displayed
Intelligent Scoring Logic
Instead of random selection, I designed a weighted scoring system.
Each response is evaluated on:
Relevance
Completeness
Clarity
Structure
Response length balance
Example Scoring Formula 𝑆 𝑐 𝑜 𝑟
𝑒
𝑤 1 𝑅 + 𝑤 2 𝐶 + 𝑤 3 𝐶 𝑙 + 𝑤 4 𝑆 − 𝑤 5 𝐿 𝑝 𝑒 𝑛 𝑎 𝑙 𝑡 𝑦 Score=w 1
R+w 2
C+w 3
Cl+w 4
S−w 5
L penalty
Where:
𝑅 R = Relevance
𝐶 C = Completeness
𝐶 𝑙 Cl = Clarity
𝑆 S = Structure quality
𝐿 𝑝 𝑒 𝑛 𝑎 𝑙 𝑡 𝑦 L penalty
= Length imbalance penalty
𝑤 𝑛 w n
= Weight values
This allows intelligent ranking instead of subjective guessing.
Security Improvements
One major learning was secure API handling.
Instead of exposing keys:
I moved all API keys to environment variables
Implemented server-side calls
Ensured no sensitive data is pushed to GitHub
This made the app production-ready.
What I Learned
This project helped me deeply understand:
Multi-LLM architecture design
API orchestration
Response normalization
Secure key management
Deployment workflows using Vercel
Performance optimization in Next.js
Most importantly, I learned how to move from idea to architecture to production deployment.
Challenges I Faced
- Handling Different Response Formats
Each AI provider returns structured data differently. I had to normalize responses into a common schema.
- Latency Differences
Some models respond faster than others. I implemented parallel API calls to optimize response time.
- Scoring Bias
Designing a fair scoring formula required experimentation.
- Secure Deployment
Managing environment variables correctly during deployment was critical.
Future Improvements
Add more LLM providers
Add user login and history tracking
Add analytics dashboard
Implement reinforcement-based ranking
Introduce fine-tuned scoring using meta-LLM evaluation
Final Vision
LLM Comparator is not just a comparison tool.
It is a step toward building an intelligent AI meta-layer that evaluates and selects the best intelligence available.
In a world of multiple AI models, the future is not choosing one.
The future is intelligently orchestrating many.
Built With
- api
- architecture
- clean
- environment
- for
- handling
- modular
- multi-model
- next.js
- responsive
- secure
- stack
- support
- tech
- typescript
- using
- variables

Log in or sign up for Devpost to join the conversation.