Inspiration
LLMs are powerful but operate like a "black box" in production. We noticed teams couldn't answer simple questions like:
- "Why did our AI costs spike 10x yesterday?"
- "Is our LLM giving wrong answers without us knowing?"
- "How do we catch unsafe content automatically?"
We built LLM Black Box to give teams real visibility into their AI systems.
What it does
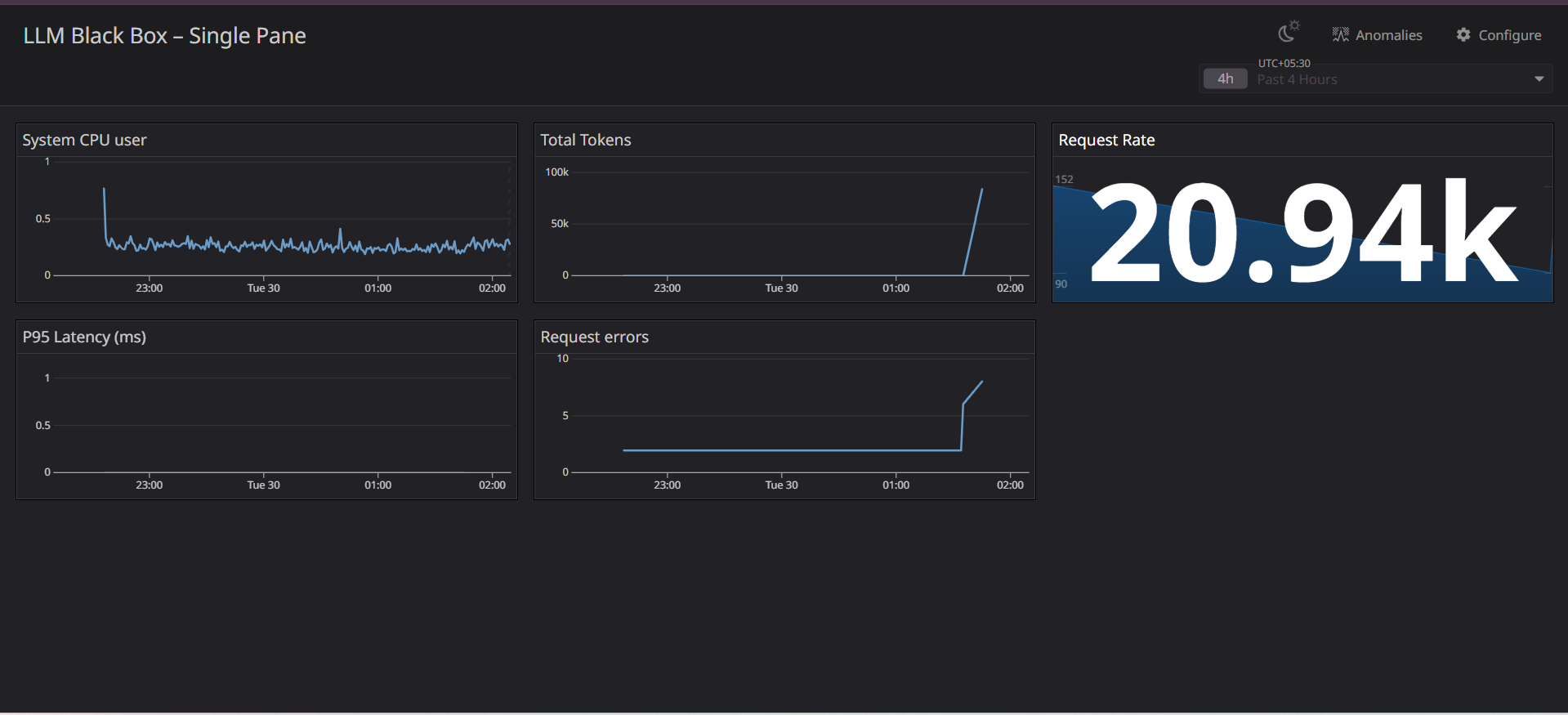
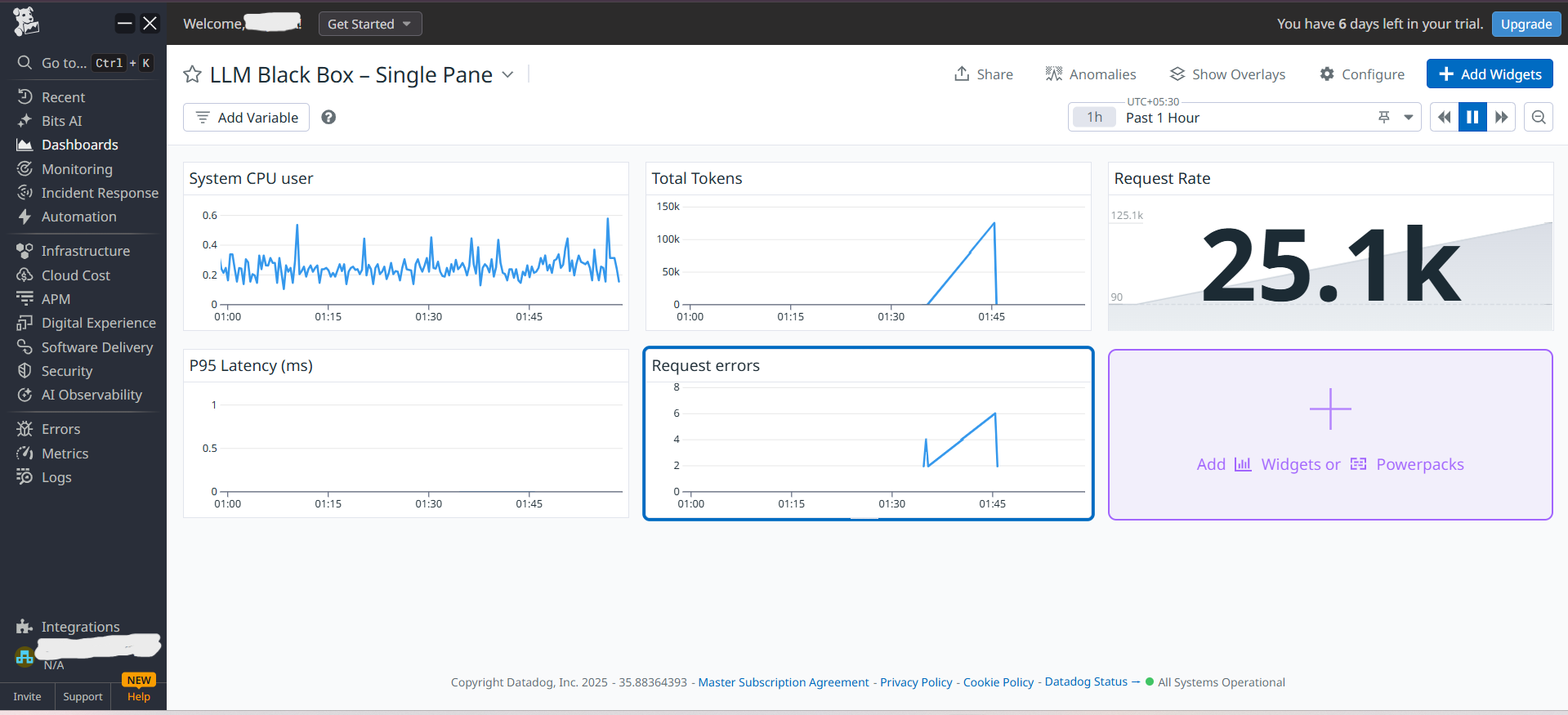
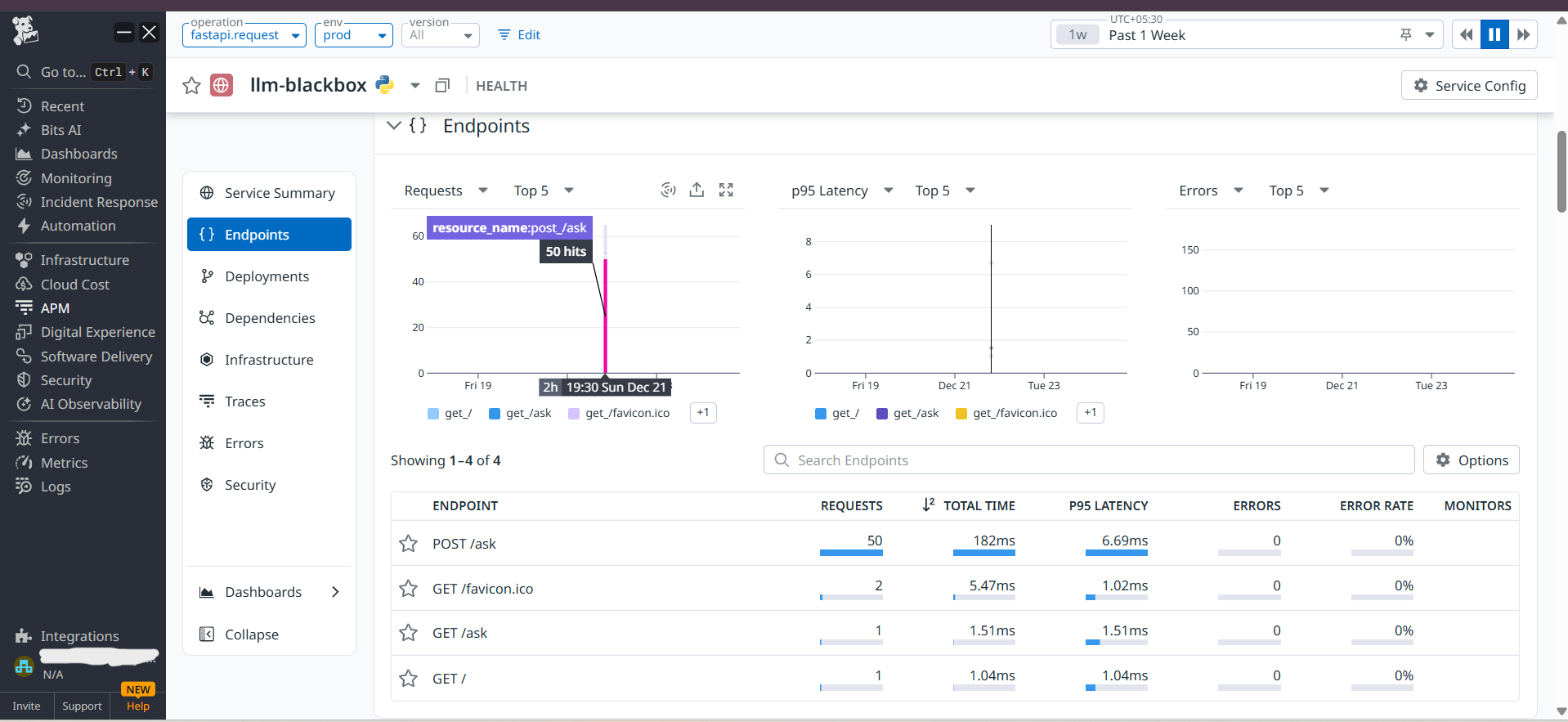
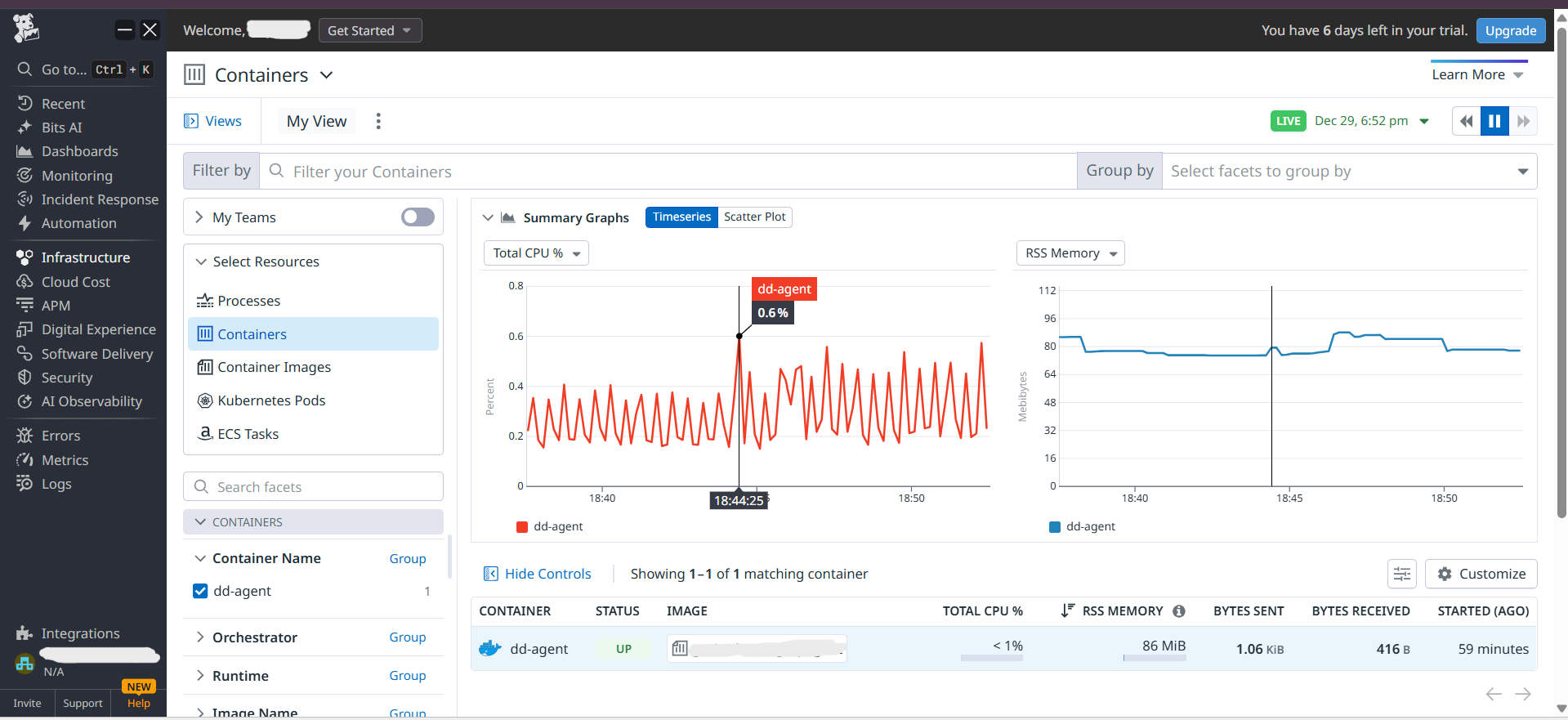
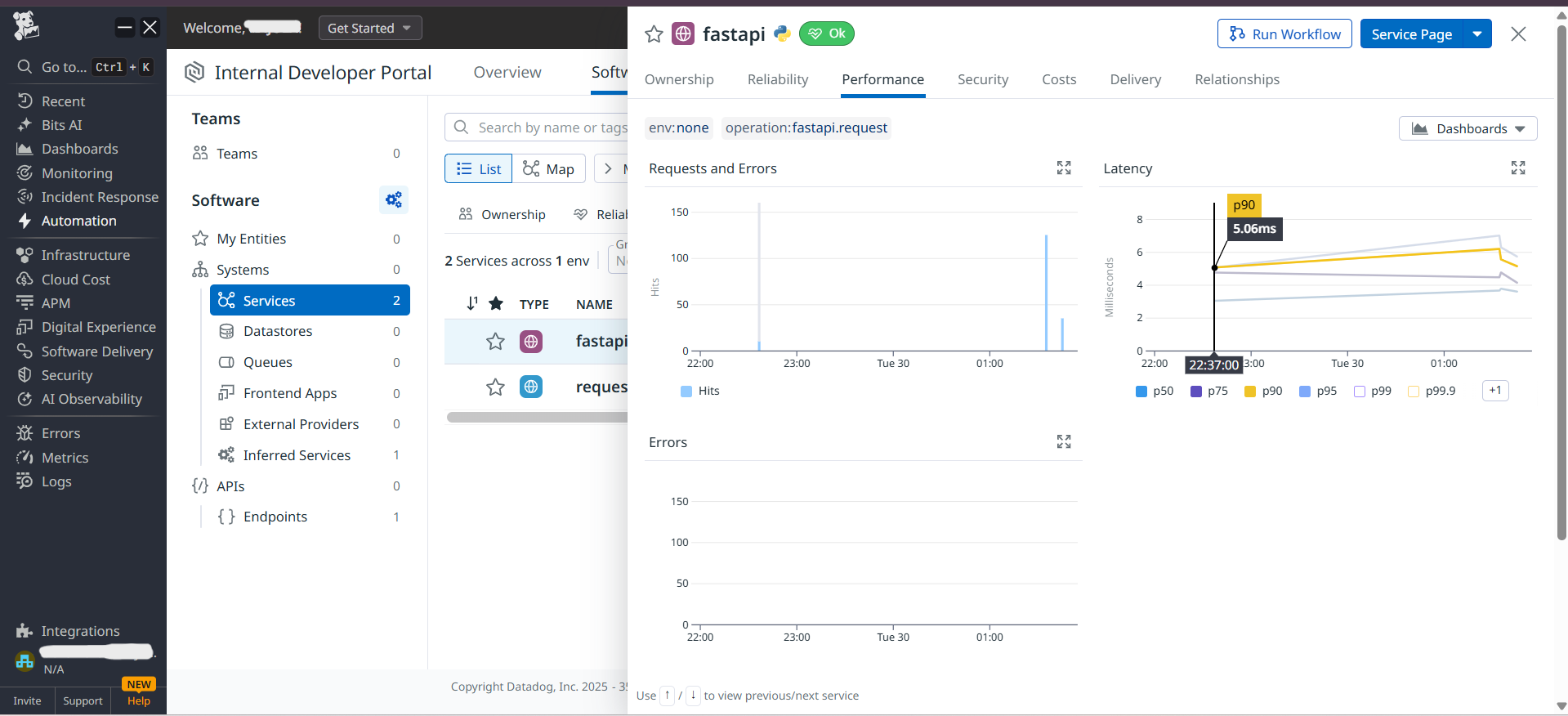
Think of it like a car dashboard, but for AI applications. It shows you:
- Costs in real-time (token usage = your AI bill)
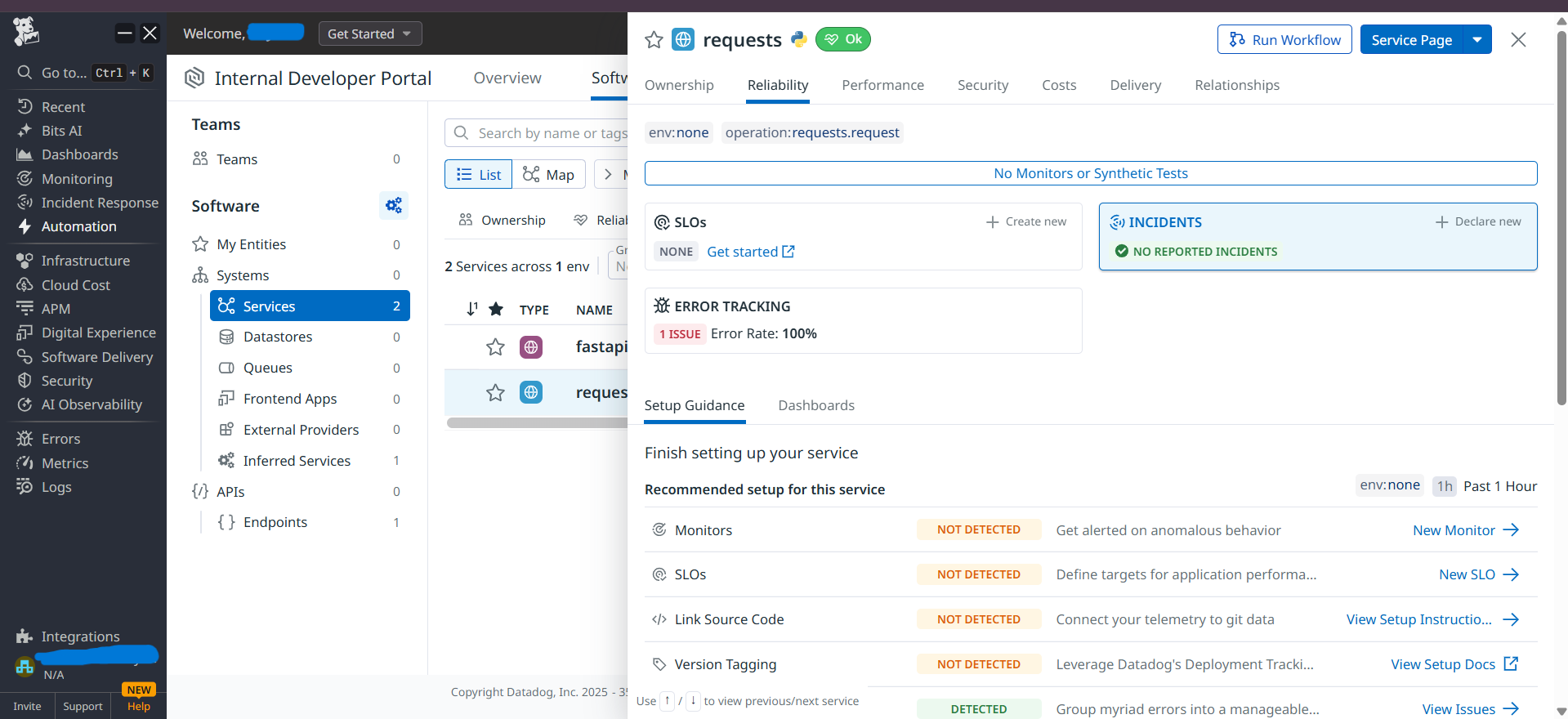
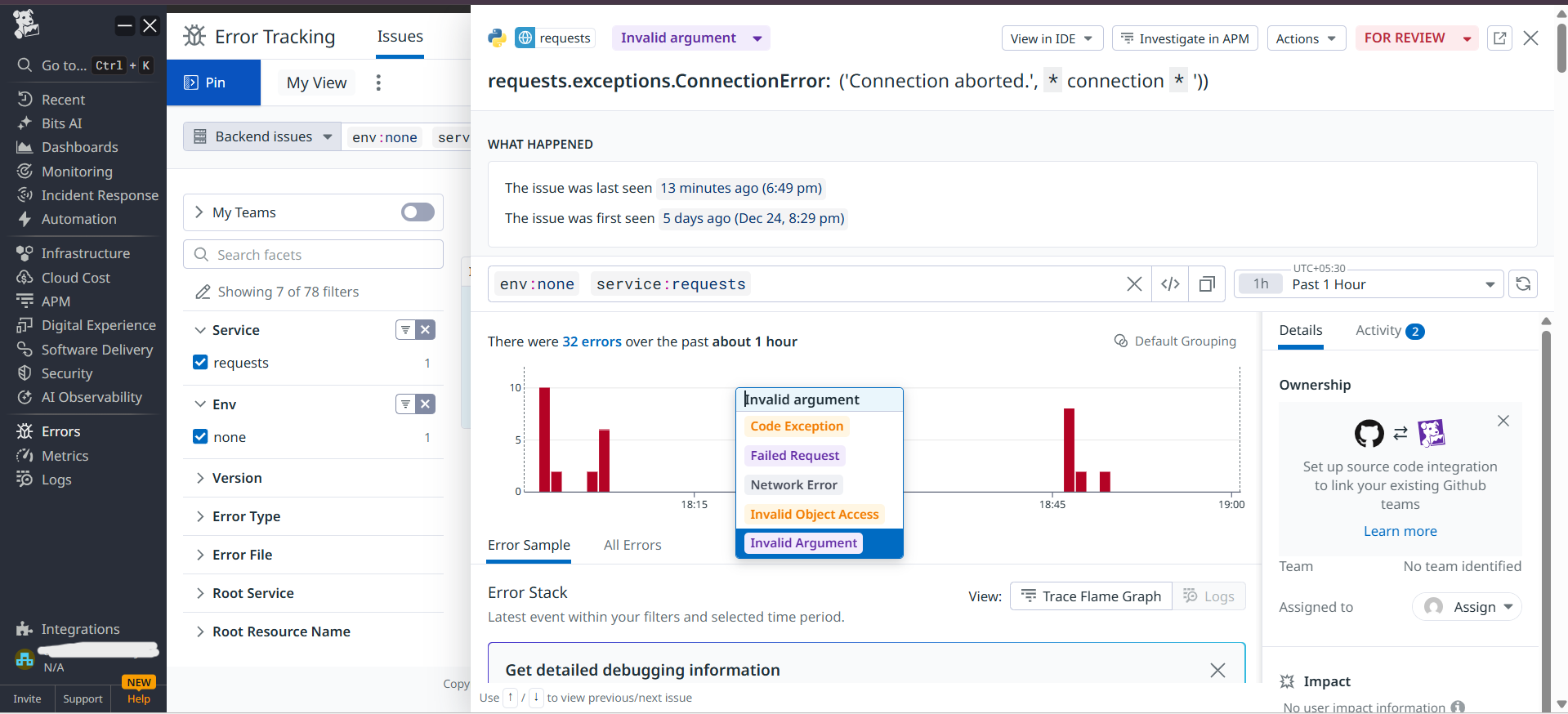
- Safety alerts when content gets blocked
- Performance issues before users complain
- Automatic trouble tickets with all the details AI engineers need
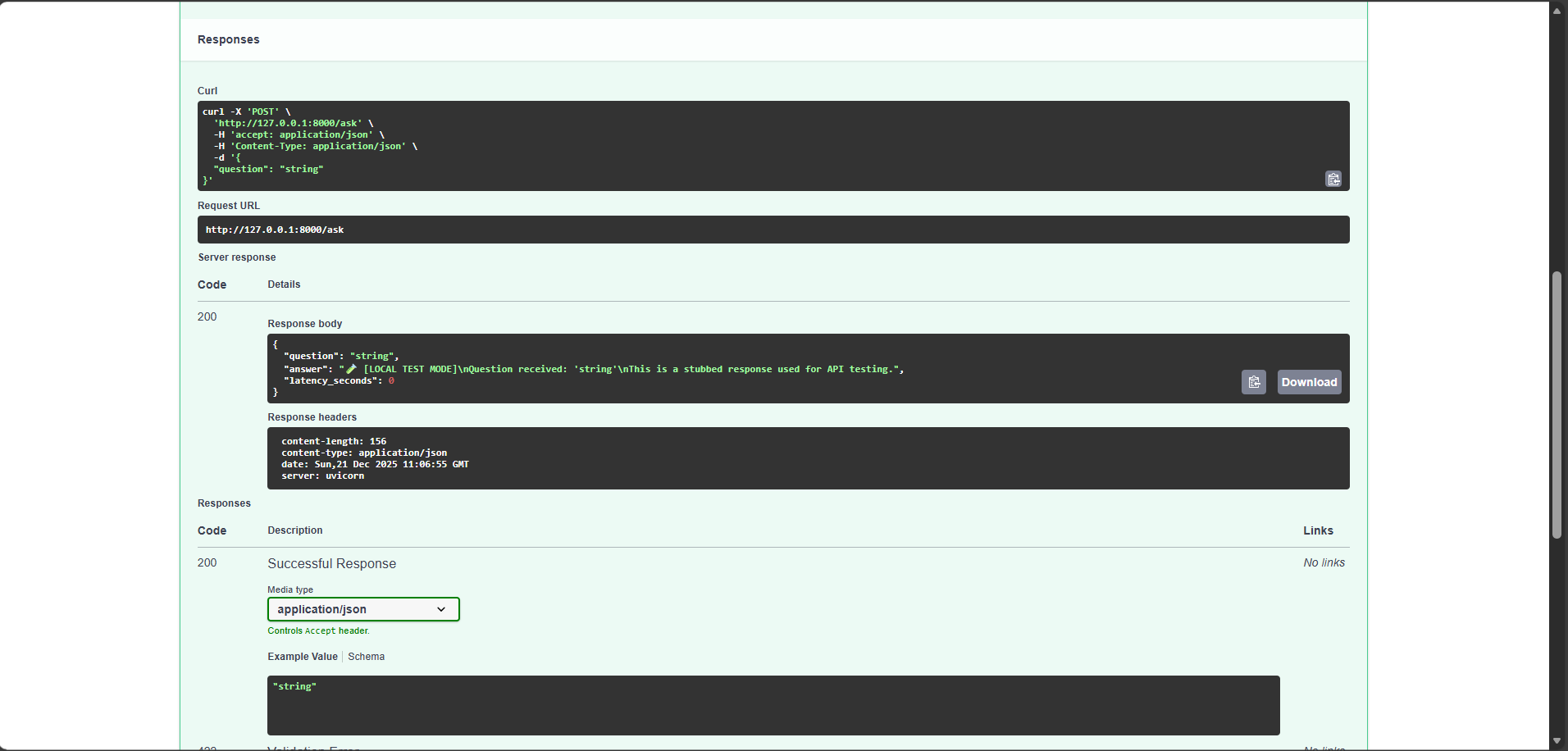
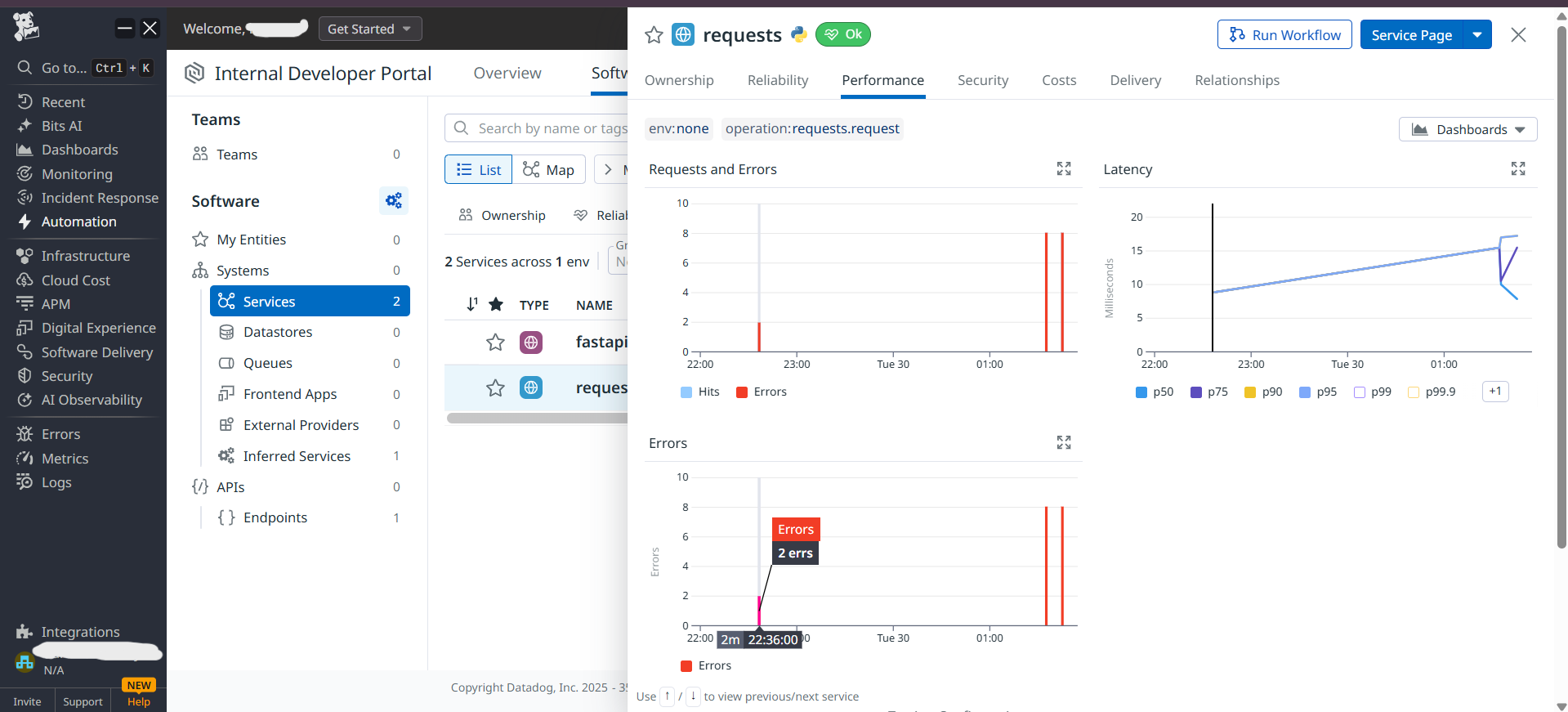
When something goes wrong, it doesn't just say "something's wrong" – it shows exactly what prompt caused it, how many tokens it used, and what the AI replied.
How we built it
- Built a simple AI app using FastAPI + Google's Gemini (Vertex AI)
- Added monitoring hooks to capture token counts, response times, safety ratings
- Sent everything to Datadog for dashboards and alerts
- Created smart rules that spot unusual patterns (like sudden token spikes)
- Automated incident creation so engineers get tickets with all the context they need
Tech stack: FastAPI (Python), Google Vertex AI, Datadog (APM, Logs, Metrics, Monitors), OpenTelemetry, Docker.
Challenges we ran into
- Getting token counts and safety ratings from Vertex AI responses (the data was nested deep)
- Making Datadog Agent work smoothly with our local setup
- Setting the right thresholds for alerts (what's "normal" token usage?)
- Linking incidents back to specific user queries automatically
- Making it easy for judges to test without complex setup
Accomplishments that we're proud of
- Created a working system that actually catches AI-specific problems
- Made it simple enough that teams could use it tomorrow
- Built realistic test scenarios (token explosions, safety blocks, latency issues)
- Got all the pieces talking to each other: Google Cloud → FastAPI → Datadog
- Documented everything so others can build on it
What we learned
- LLMs need different monitoring than regular apps (tokens ≠ CPU usage)
- Safety monitoring can't be "set and forget" – needs constant checking
- Engineers need different info for AI incidents (prompts/responses, not just logs)
- Cost visibility changes how teams use AI (when you see tokens = dollars, you optimize)
- OpenTelemetry is great for traces but needs extensions for AI data
What's next for LLM Black Box
- Make it easier to deploy (one-click Google Cloud Run setup)
- Add more AI providers (OpenAI, Claude, open-source models)
- Better cost forecasting ("at this rate, you'll spend $X this month")
- Community contributions – we want others to help improve it
- Real customer testing – see what actual AI teams need



Log in or sign up for Devpost to join the conversation.