-
-
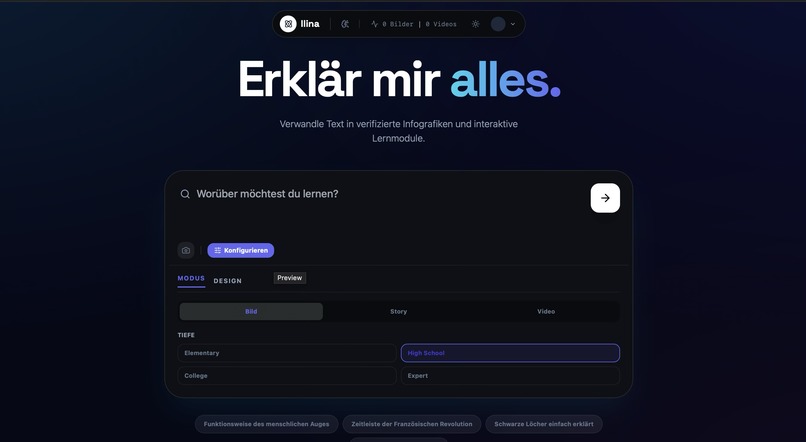
Multiple Gemini models work together to visualize and teach you anything, anywhere.
-
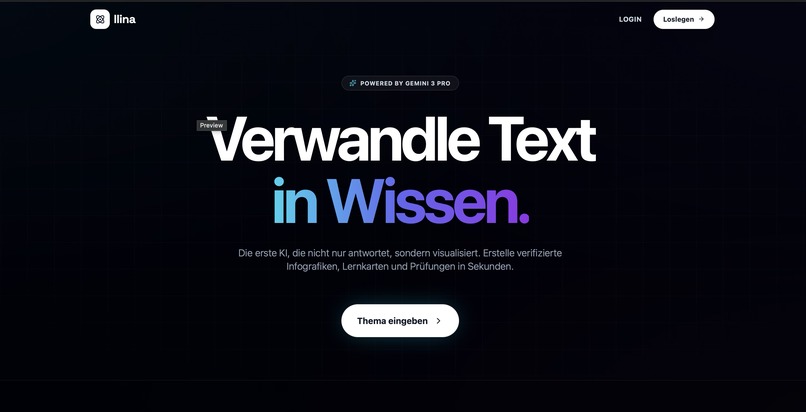
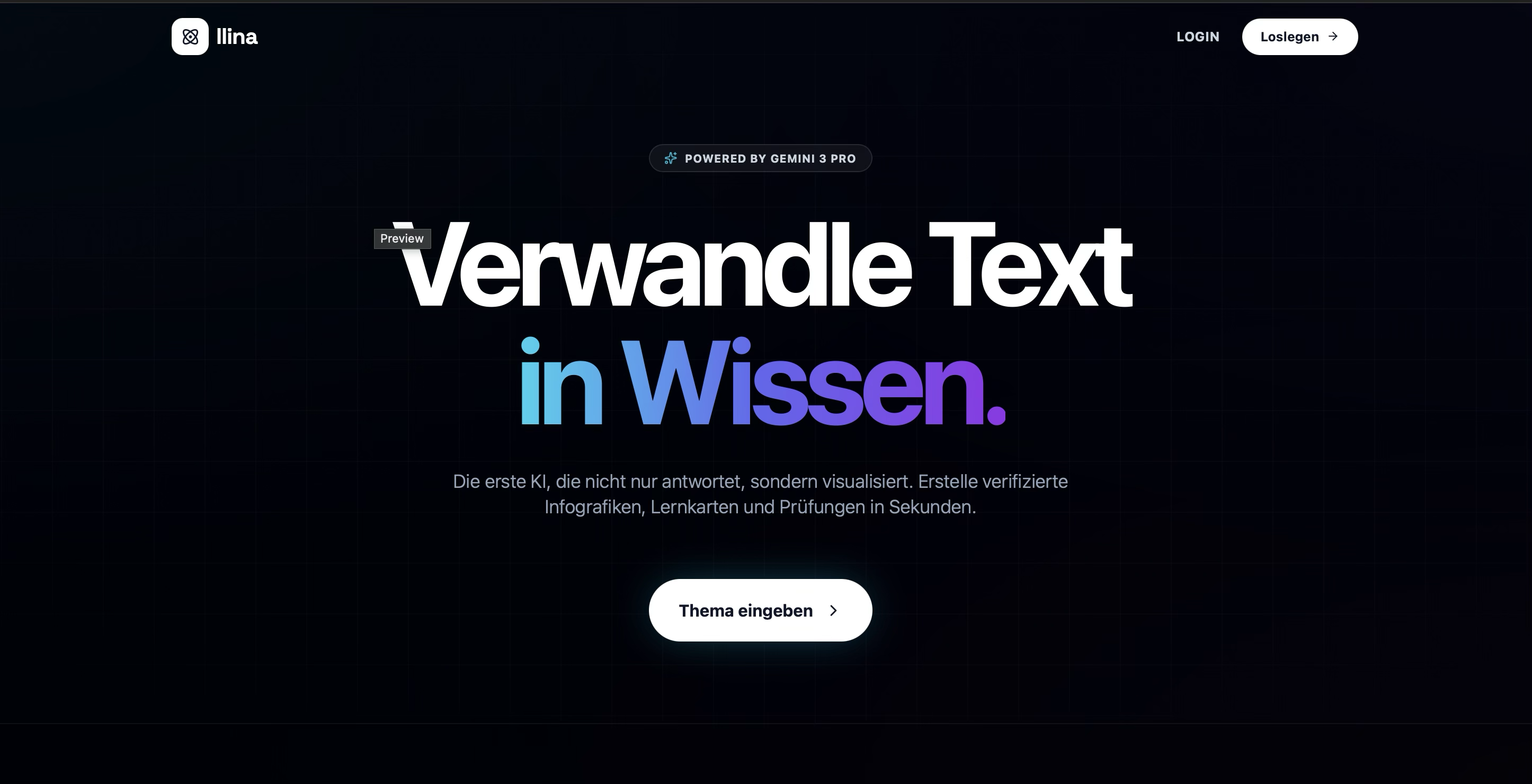
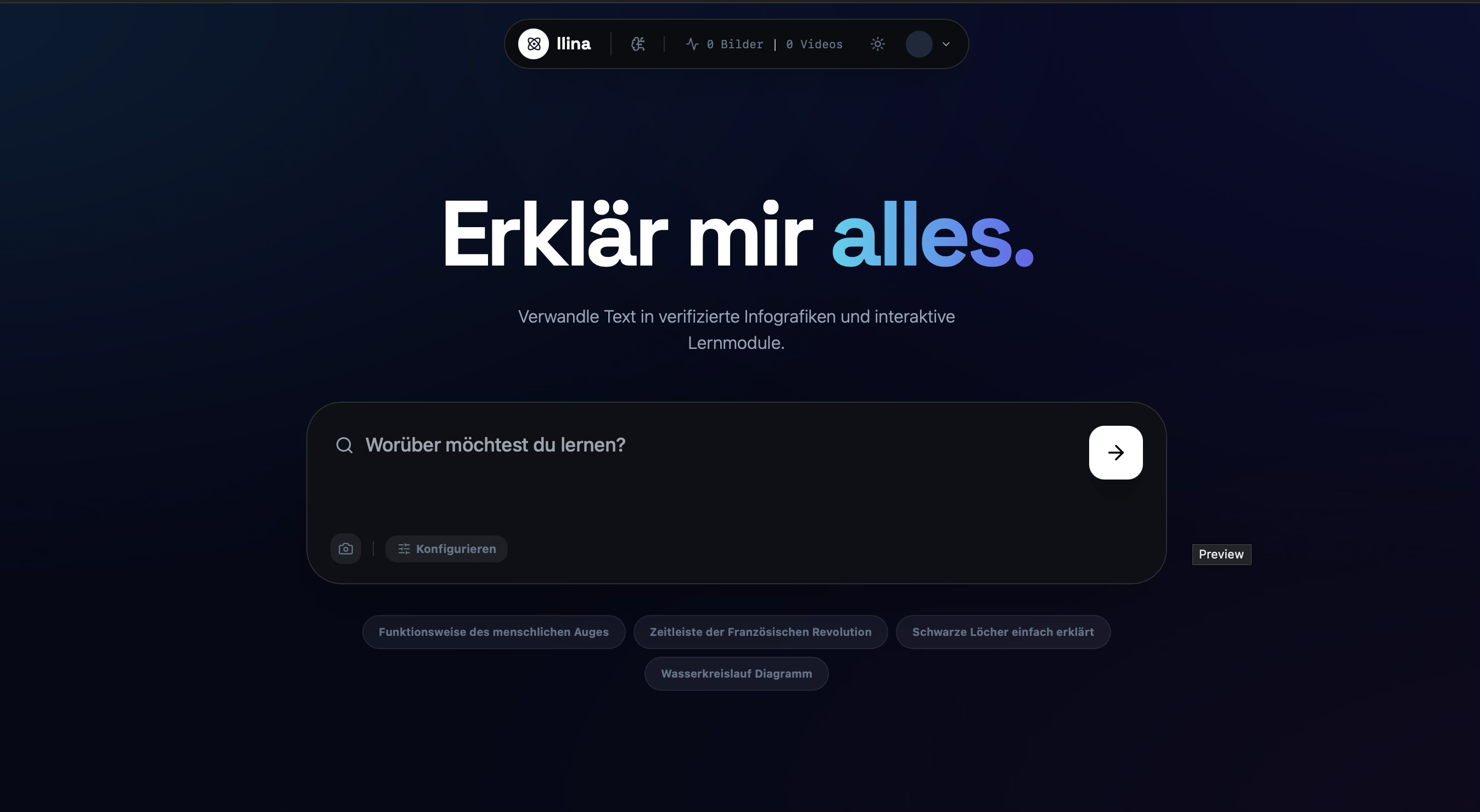
Transform walls of text into interactive, visual knowledge instantly with Llina.ai.
-
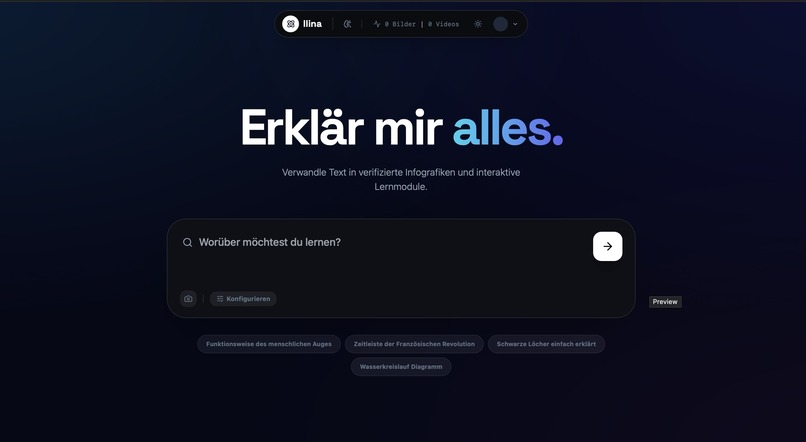
Simply enter any topic. Our AI handles the research so you can focus on learning.
-
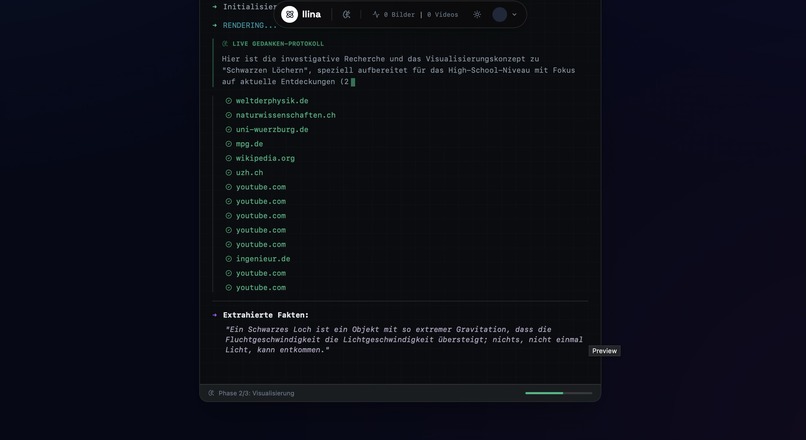
Say goodbye to boring text blocks. Get rich, interactive insights tailored to you.
-

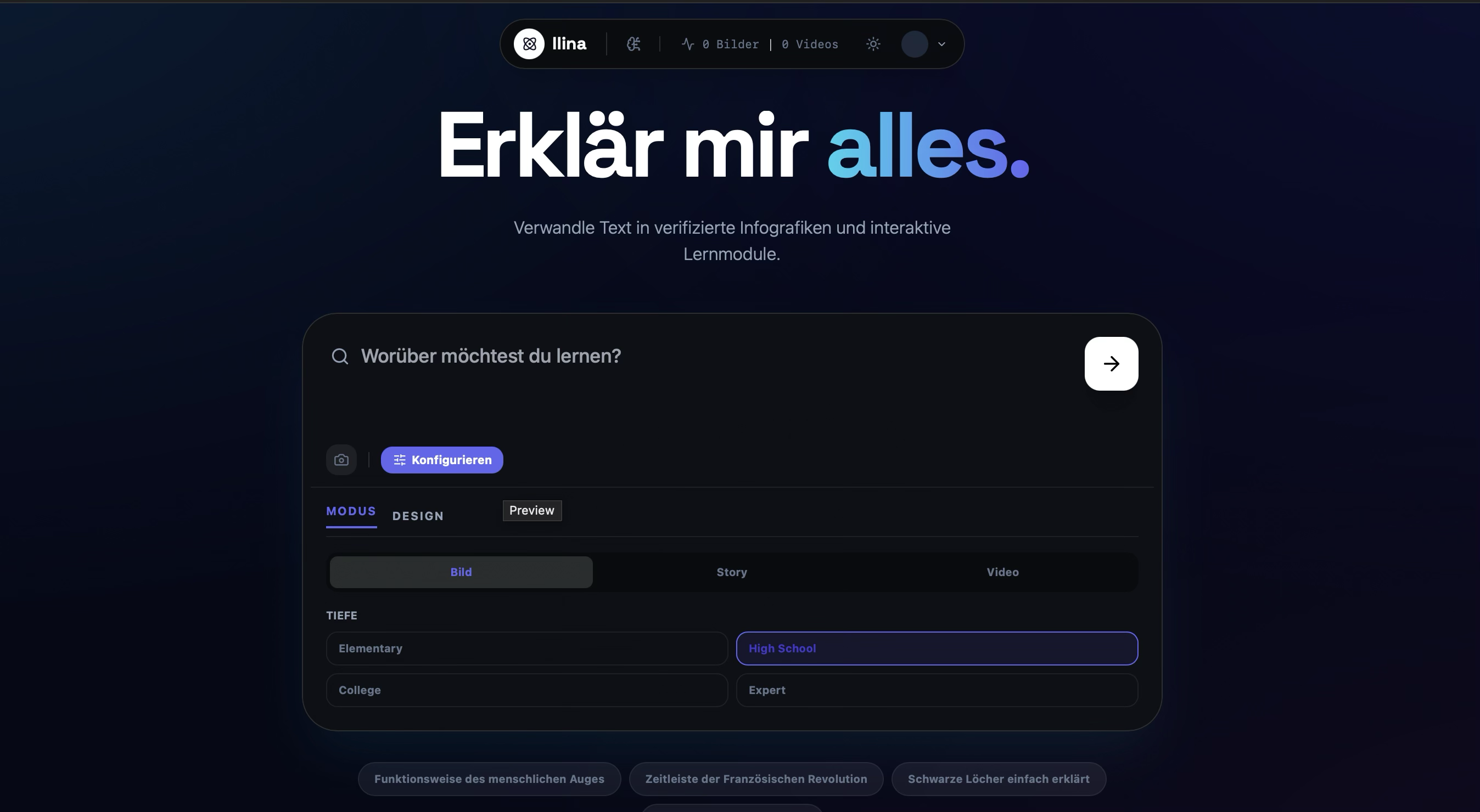
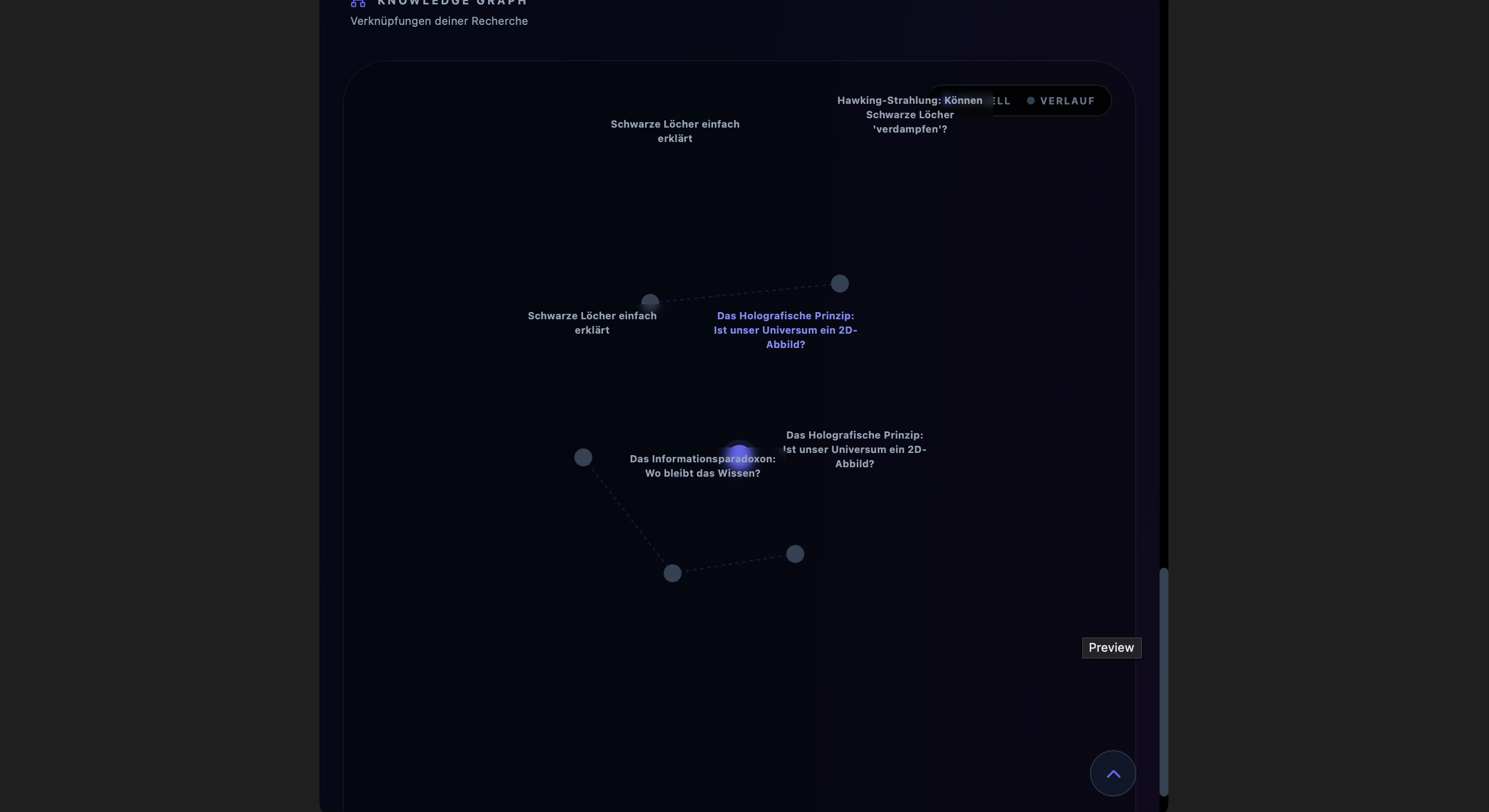
Mind Map: See the big picture. Explore how different ideas connect through interactive relational maps.
-
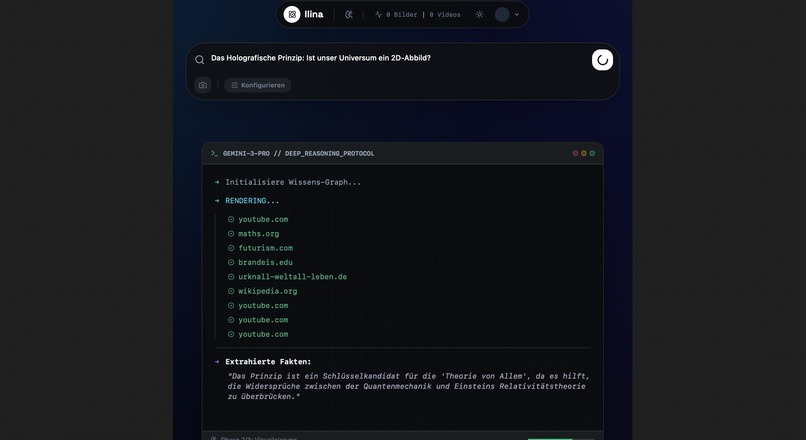
Structured Info: Get clear, structured summaries that break down complex topics into digestible pieces.
-
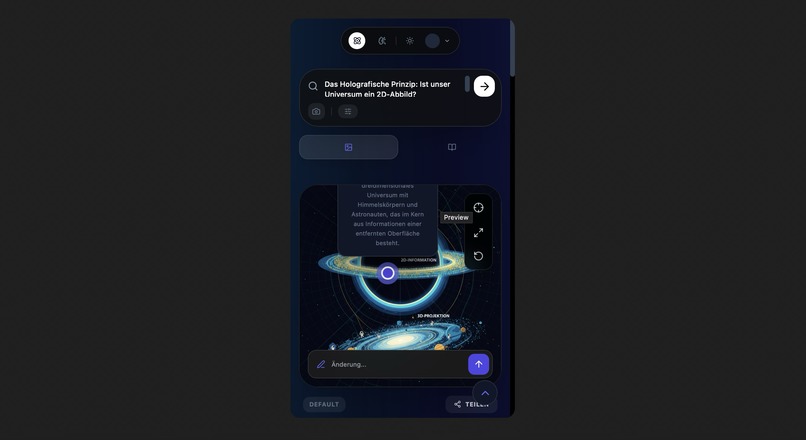
Mobile View: Learn on the go. Llina.ai provides a seamless, interactive experience on any device.
-
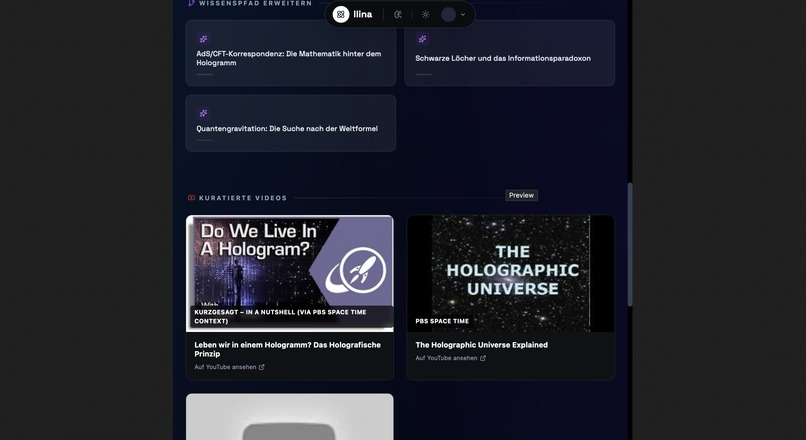
Topic Dashboard: Organize your research. Manage multiple topics and learning modules in one sleek interface.
-

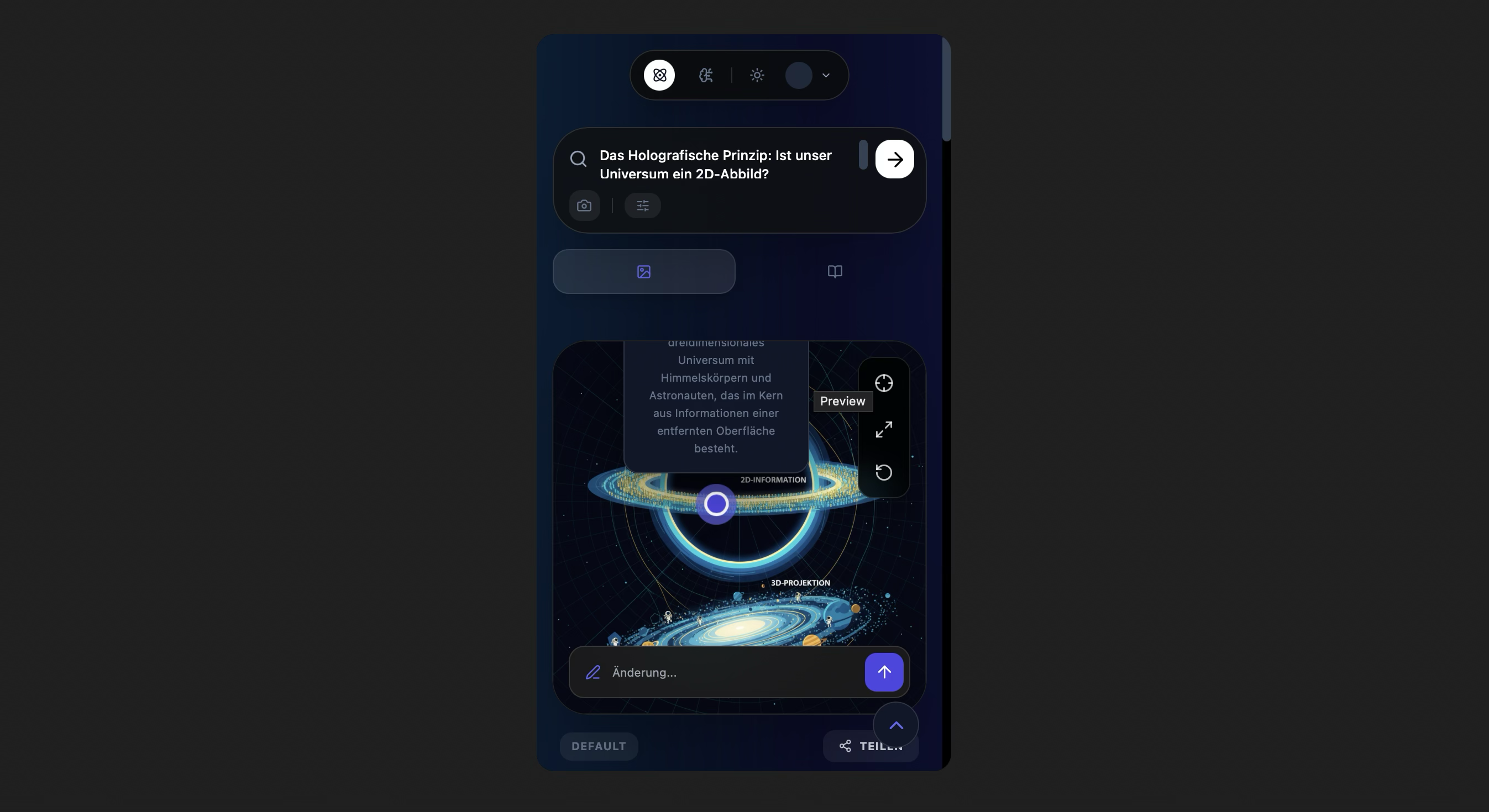
Image Gallery: Dive deep with rich visual assets generated to illustrate even the most abstract concepts.
-
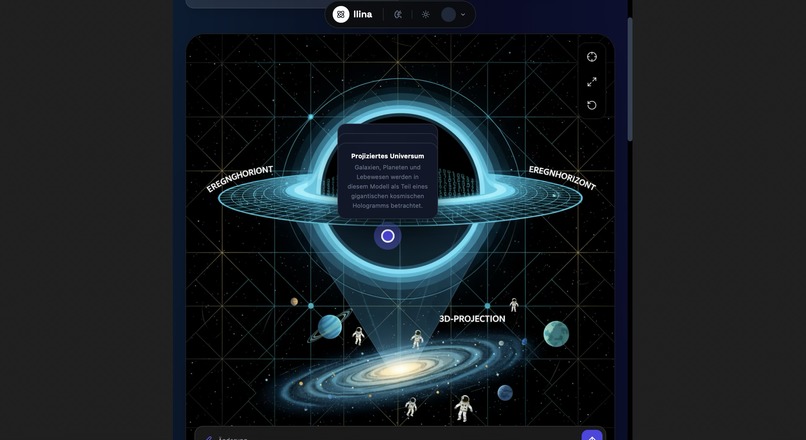
Hero Visualization: Experience knowledge. Llina.ai creates stunning visuals to make learning intuitive.
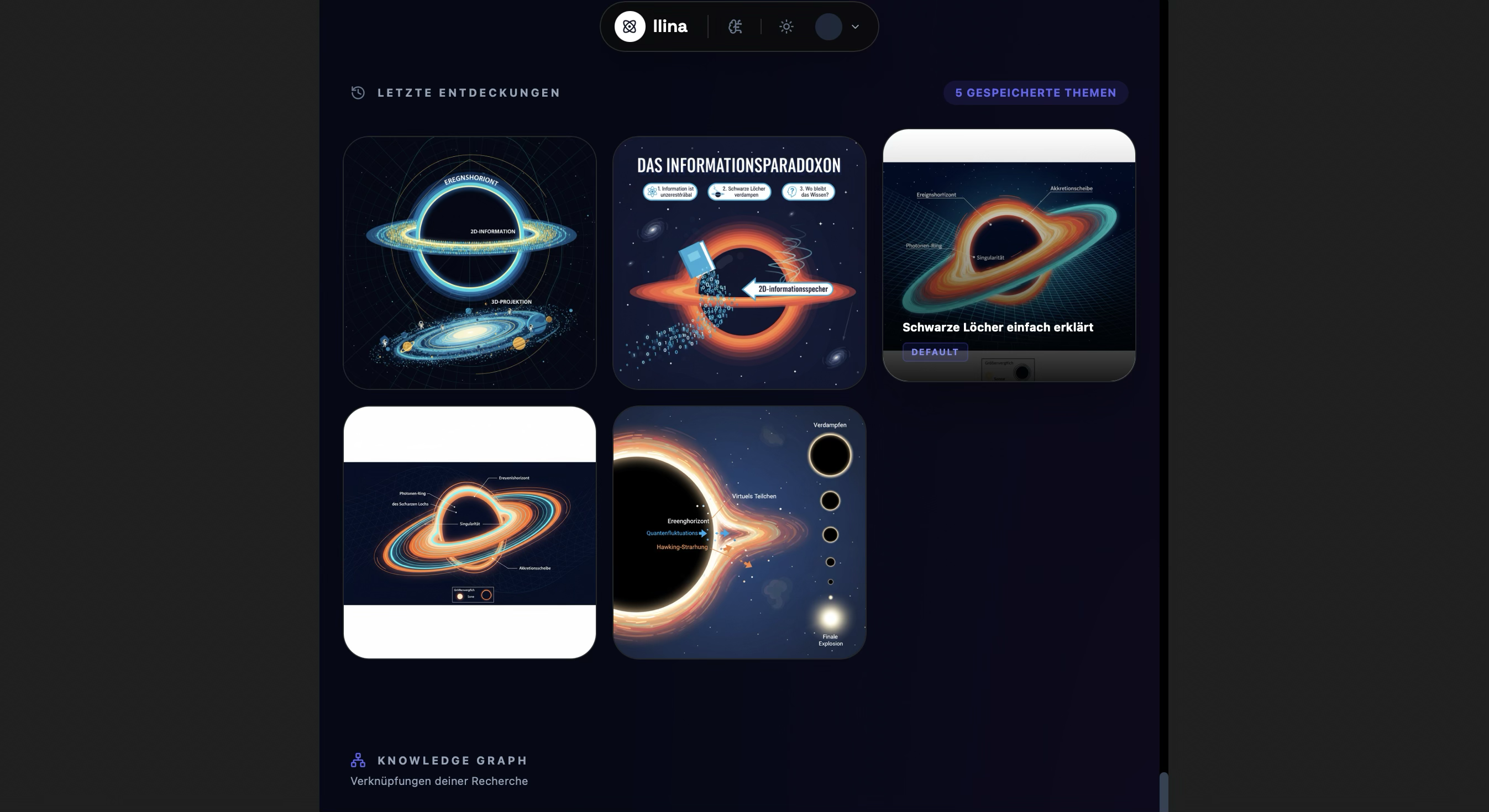
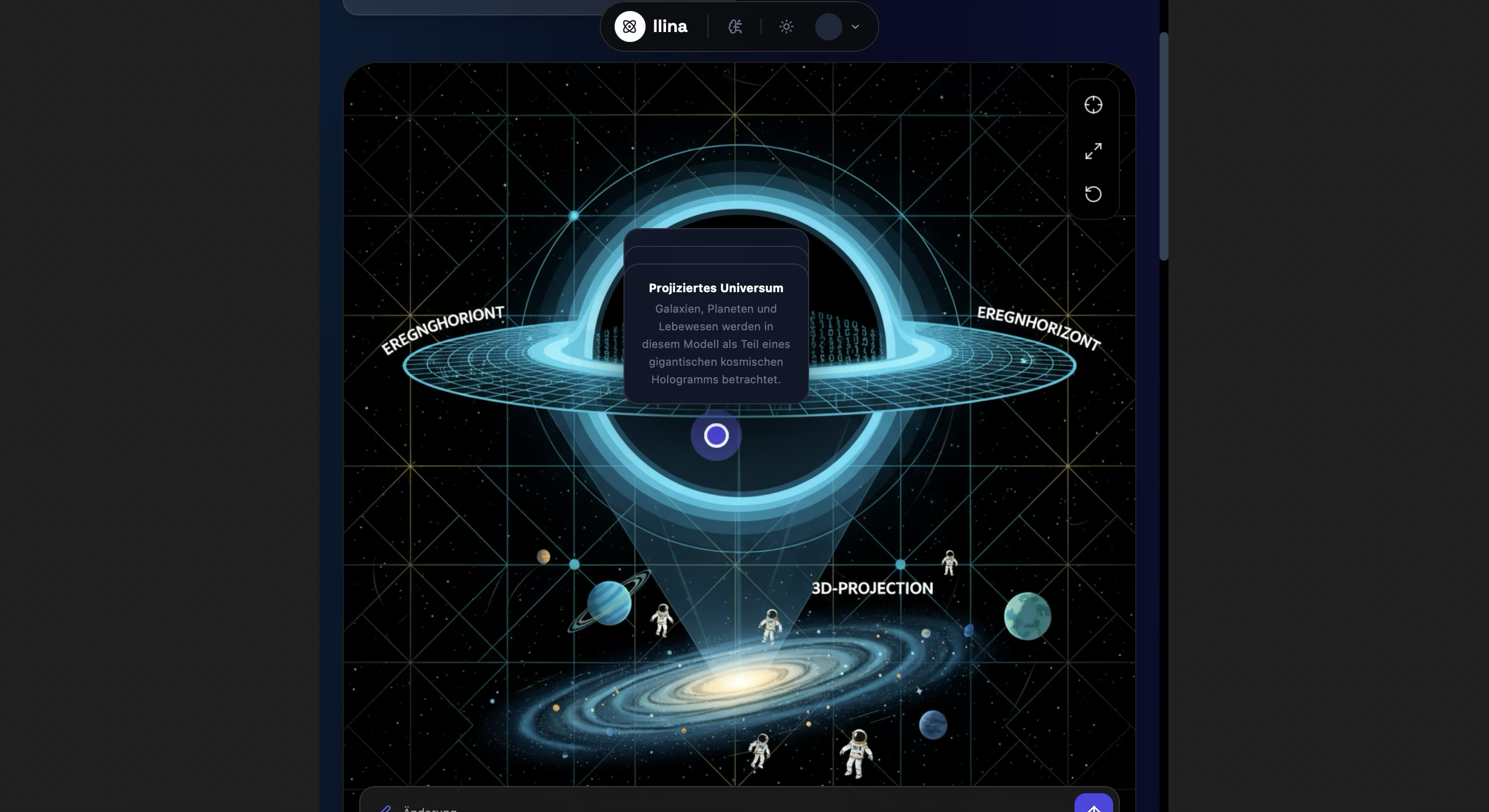
Inspiration
We are currently facing a paradox in the digital age: We are drowning in information, but starving for knowledge.
Traditional education and standard LLMs often present the same problem: the "Wall of Text." While accurate, text-heavy responses are difficult to retain. Cognitive science tells us that the human brain processes visual information 60,000x faster than text.
We asked ourselves: What if an AI didn't just summarize a topic, but actually taught it like a world-class visual educator?
We wanted to build llina.ai to be the bridge between raw complexity and instant clarity. We were inspired by the visual storytelling of creators like Kurzgesagt and the rigor of academic curricula, aiming to synthesize them using the new multimodal capabilities of Gemini.
What it does
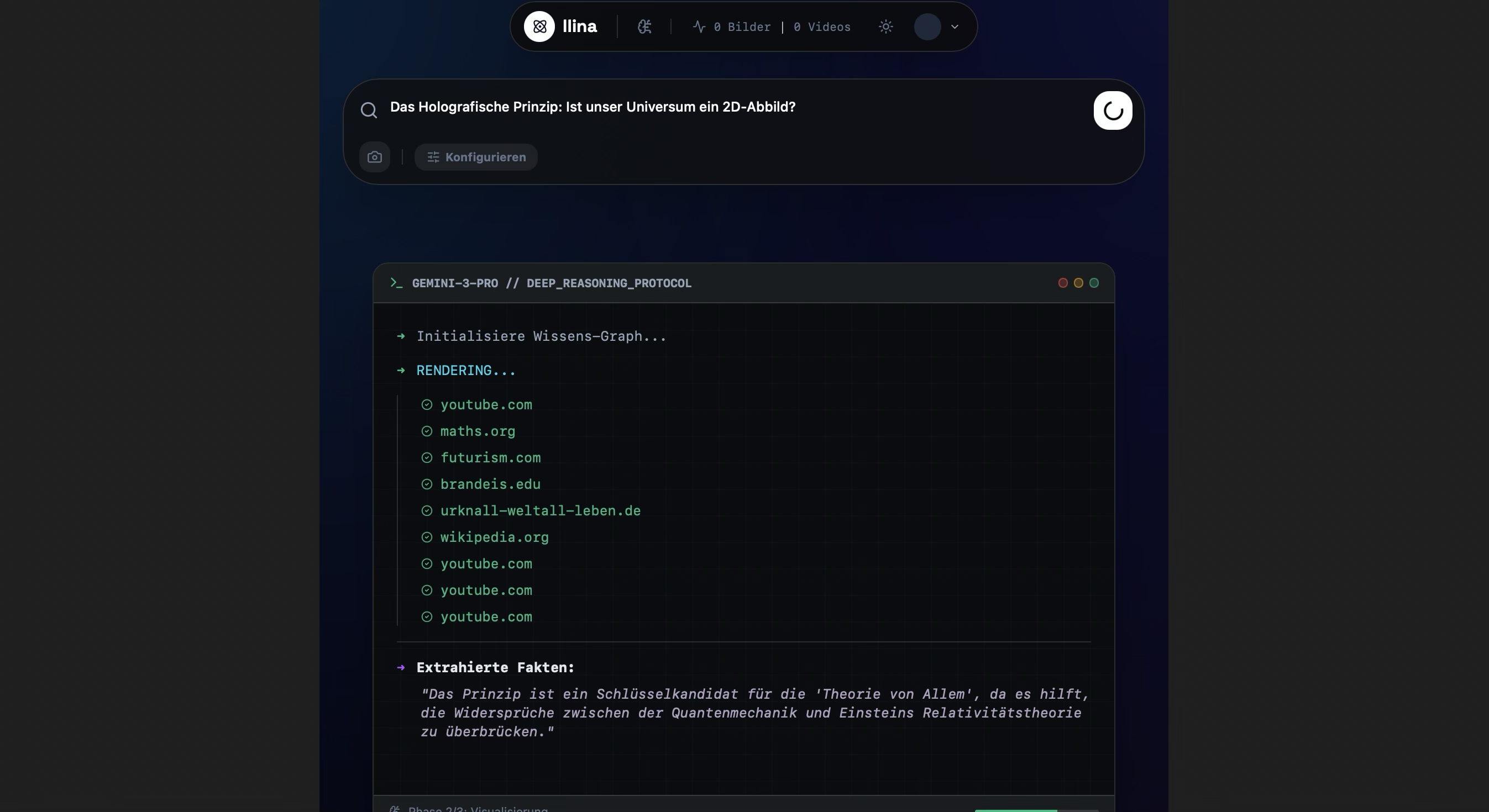
llina.ai is a multimodal cognitive engine that transforms any text prompt into a comprehensive, verified visual learning experience in seconds.
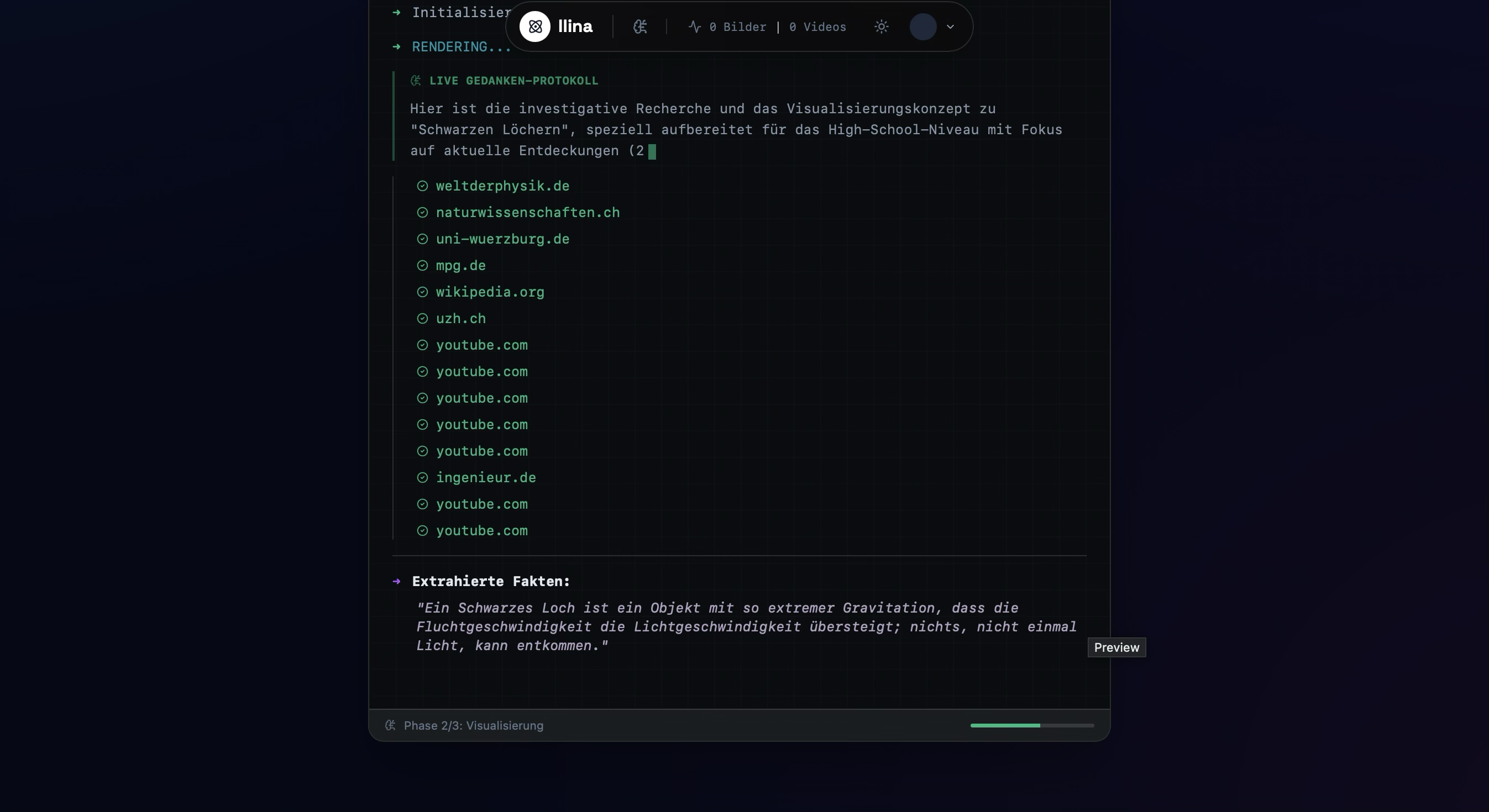
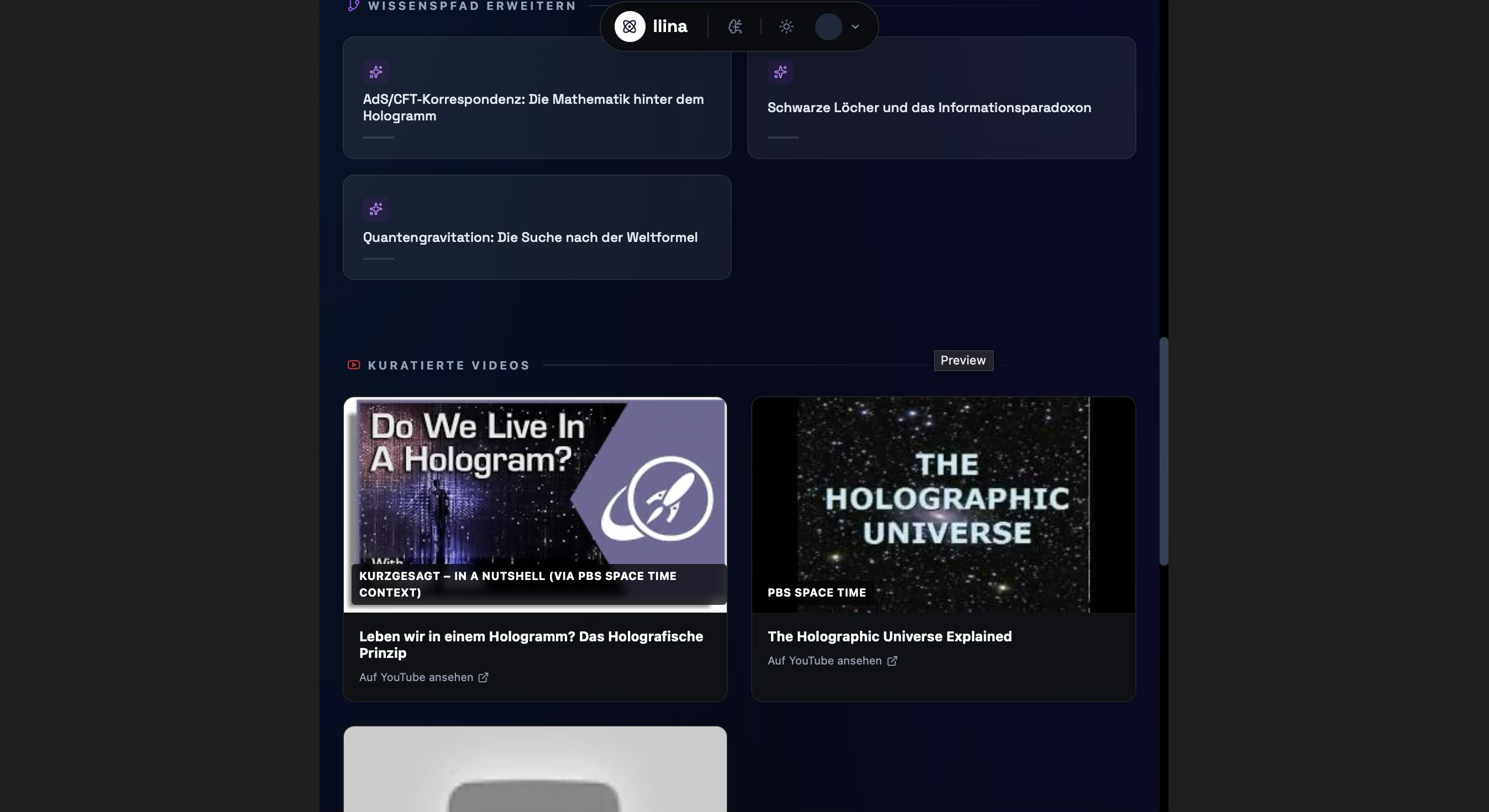
Deep Research & Verification: Unlike standard chatbots, llina uses Gemini 3 Pro combined with Google Search Grounding to research topics, verify facts, and cite sources, ensuring the content is hallucination-free. Instant Infographics (Imagen 3): It generates high-fidelity, 4K educational infographics customized to specific styles (e.g., Minimalist, Blueprint, Sketch) and complexity levels (Elementary to Expert). Generative Video (Veo): We integrated Veo to transform static concepts into cinematic motion graphics for complex process visualization. Interactive Vision: Users can upload their own diagrams or photos. llina uses Gemini Vision to analyze the image and generate interactive hotspots, explaining specific parts of the visual. The AI Teacher: llina generates entire lesson plans and assessments. It includes an Auto-Grader that uses a generated rubric to grade student open-text answers, providing pedagogical feedback. Neuro-Science Based Retention: It features a built-in Spaced Repetition System (SRS) based on the SM-2 algorithm, tracking what you learn and scheduling reviews right before you are likely to forget.
How we built it
We built llina.ai as a high-performance, client-side application using React, TypeScript, and TailwindCSS, orchestrating the Google GenAI SDK directly for maximum speed.
The Multimodal Pipeline The core of the application is a sophisticated chaining of models:
Reasoning Layer: When a user asks a question, we use Gemini 3 Pro (with fallback to Gemini 2.5 Flash) to perform deep reasoning. We enabled googleSearch tools to fetch real-time data and grounded citations. Visual Prompting: The model outputs a structured JSON object containing verified facts and highly detailed image prompts optimized for Imagen 3. Generation Layer: For images, we call imagen-3.0-generate-001 (via the Gemini API) to create text-rich infographics. For videos, we utilize the Veo model (veo-3.1-generate-preview) to generate 1080p educational clips. Vision Analysis: For interactive elements, we feed the generated (or uploaded) image back into Gemini 1.5 Pro to identify coordinate-based regions of interest. The Math behind Memory To ensure long-term retention, we implemented a variation of the SuperMemo-2 (SM-2) algorithm. The interval for the -th repetition is calculated as:
Where (Ease Factor) is dynamically adjusted by Gemini based on the user's self-assessed recall quality.
Challenges we ran into
JSON Instability: Getting consistent JSON for complex structures (like lesson plans with nested rubrics) from LLMs can be tricky. Solution: We implemented a "Safe Parse" logic and strict schema prompting to ensure the UI always renders, even if the model output is slightly malformed.
Text Rendering in Images: Early iterations of image generation struggled with legible text. Solution: We fine-tuned our prompt engineering to leverage Imagen 3's superior text rendering capabilities, specifically requesting "vector illustration styles" and "clear labels."
Accomplishments that we're proud of
Veo Integration: We are one of the first educational apps to successfully integrate the Veo video generation model into a production-like flow.
Search Grounding: We successfully implemented Google Search Grounding to provide clickable citations, solving the "trust issue" in AI education.
The UI/UX: We built a beautiful, "Glassmorphism" interface that feels like a futuristic operating system, featuring a dynamic Knowledge Graph that visualizes the connections between your search topics.
Auto-Grading: Building an AI teacher that doesn't just check "A, B, or C" but actually reads a student's essay and grades it against a rubric feels like magic.
What we learned
Multimodality is the future: Text alone is insufficient. The ability to chain Text -> Image -> Video -> Interactive Data creates a learning experience that feels orders of magnitude more effective.
Flash is incredibly capable: While we started with Pro, we learned that gemini-2.5-flash is surprisingly capable at complex reasoning tasks when given clear system instructions, making it a viable production model.
Grounding is essential: For educational tools, the ability to trace an AI's claim back to a source URL is non-negotiable.
What's next for llina.ai – The Multimodal Knowledge Engine
Gemini Live Integration: We want to add a real-time voice mode where you can "talk" to the infographics you generate.
Classroom Mode: A dashboard for teachers to push generated lesson plans directly to students' devices. Export to Anki: Direct export of our flashcards to the popular Anki ecosystem.
Built With
- gemini-2.5-flash
- gemini-3-pro
- google-search-grounding
- imagen-3
- react
- tailwindcss
- typescript
- veo


Log in or sign up for Devpost to join the conversation.