




Living Memory
Inspiration
Every family has a box of old photos somewhere — faded prints, creased Polaroids, black-and-whites nobody can explain anymore. The people who lived those moments are getting older, and the stories behind the photos live only in their heads. When they're gone, the photo becomes just a photo.
This isn't a niche problem. Remento, a family storytelling startup, secured a deal on Shark Tank and has generated over $3 million in sales — proving massive consumer demand for preserving family stories. The global digital photo preservation market is projected to reach $5.2 billion by 2028, and the genealogy market (Ancestry, MyHeritage) is already worth over $3 billion.
But existing solutions are either low-tech (printed books from prompted questions) or purely storage-focused (Google Photos, iCloud). None of them combine real-time AI conversation, photo understanding, animation, and narrated film generation into one experience.
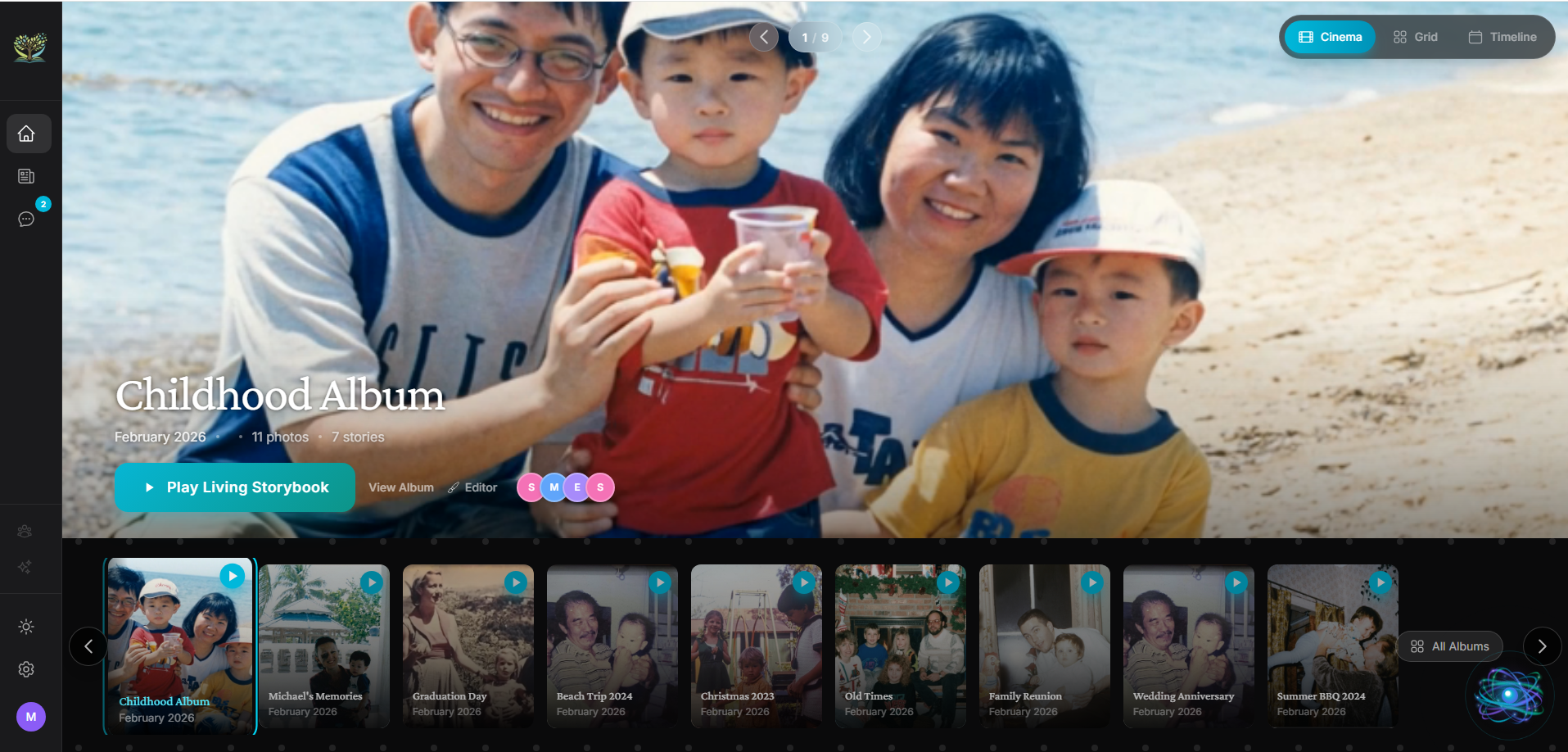
We built Living Memory to fill that gap: an AI companion named EVA who sits with you, looks at your photos, asks the questions that pull real stories out, and transforms everything into cinematic memory films your grandkids can watch in 30 years.
What it does
Living Memory is a full-stack web app that transforms family photos into narrated, animated memory experiences — powered by real-time AI conversation and generative media.
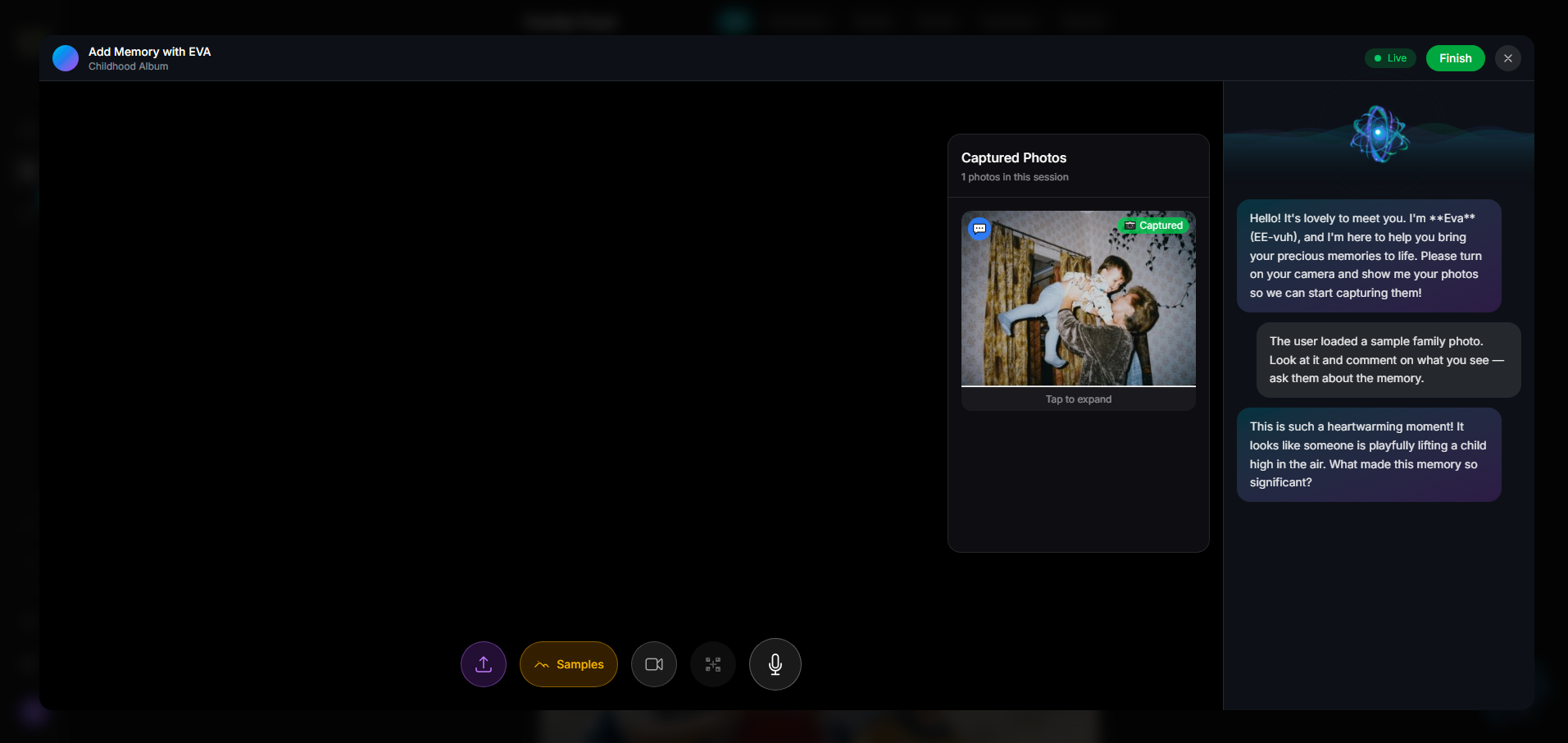
Meet EVA — Your AI memory companion, powered by Gemini Live API. She speaks naturally, sees your photos, and guides you through preserving your stories via real-time voice conversation.
Capture — Upload photos or point your camera at a physical album. The app detects, crops, and extracts individual photos in real-time using Gemini Vision. "Nano Banana" (Gemini's native image output) cleans up camera captures into pristine extracted photos.
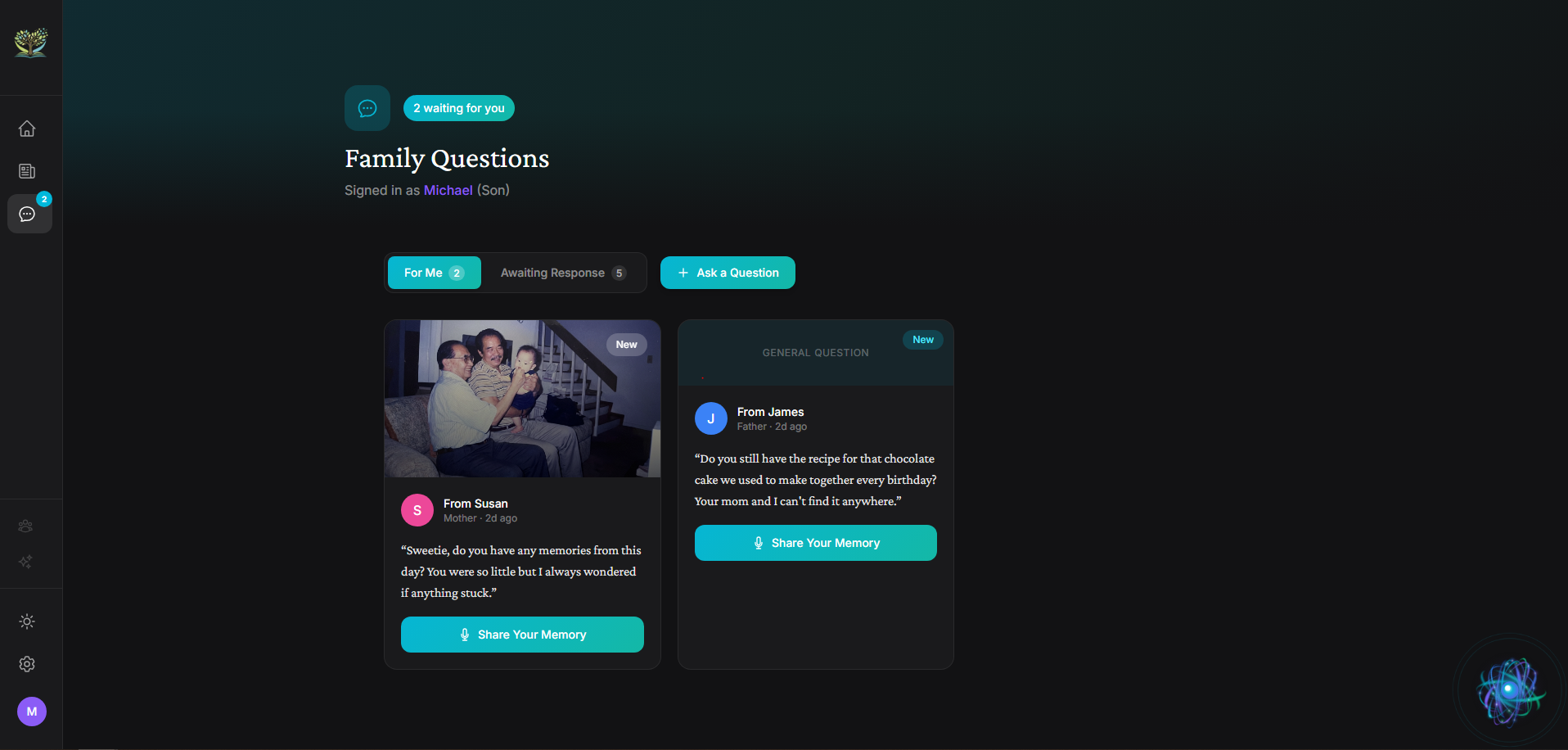
Remember — Talk to EVA about your photos. She analyzes each image — identifying the era, setting, expressions — and asks adaptive questions that spark real memories. Every family member can add their own perspective. Ask questions across generations through the family prompts system.
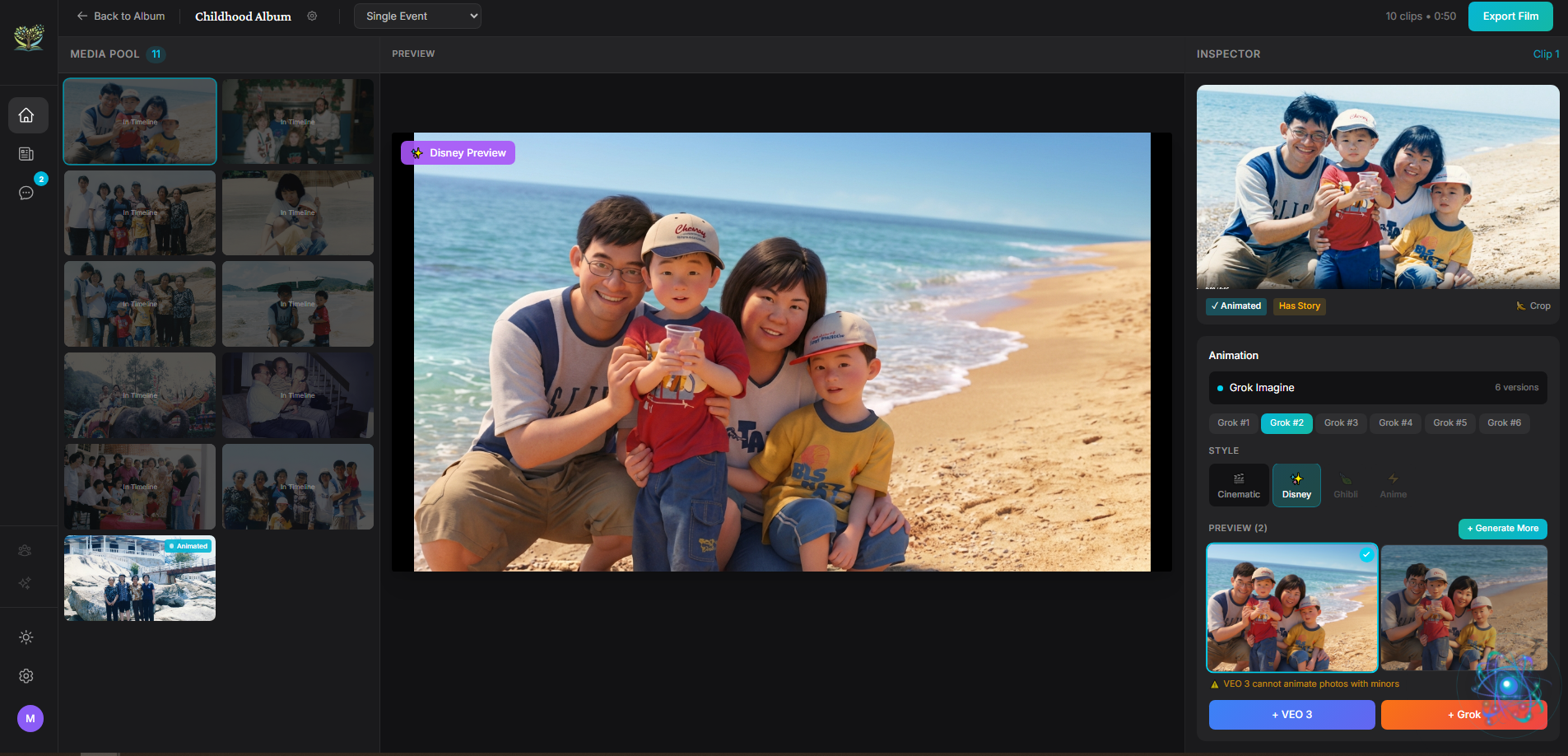
Animate — Transform photos into art styles (Disney/Pixar, Ghibli, Anime) using Gemini 3 Pro Image Preview, then bring them to life with VEO 3.1 video generation. Choose cinematic realism or stylized animation.
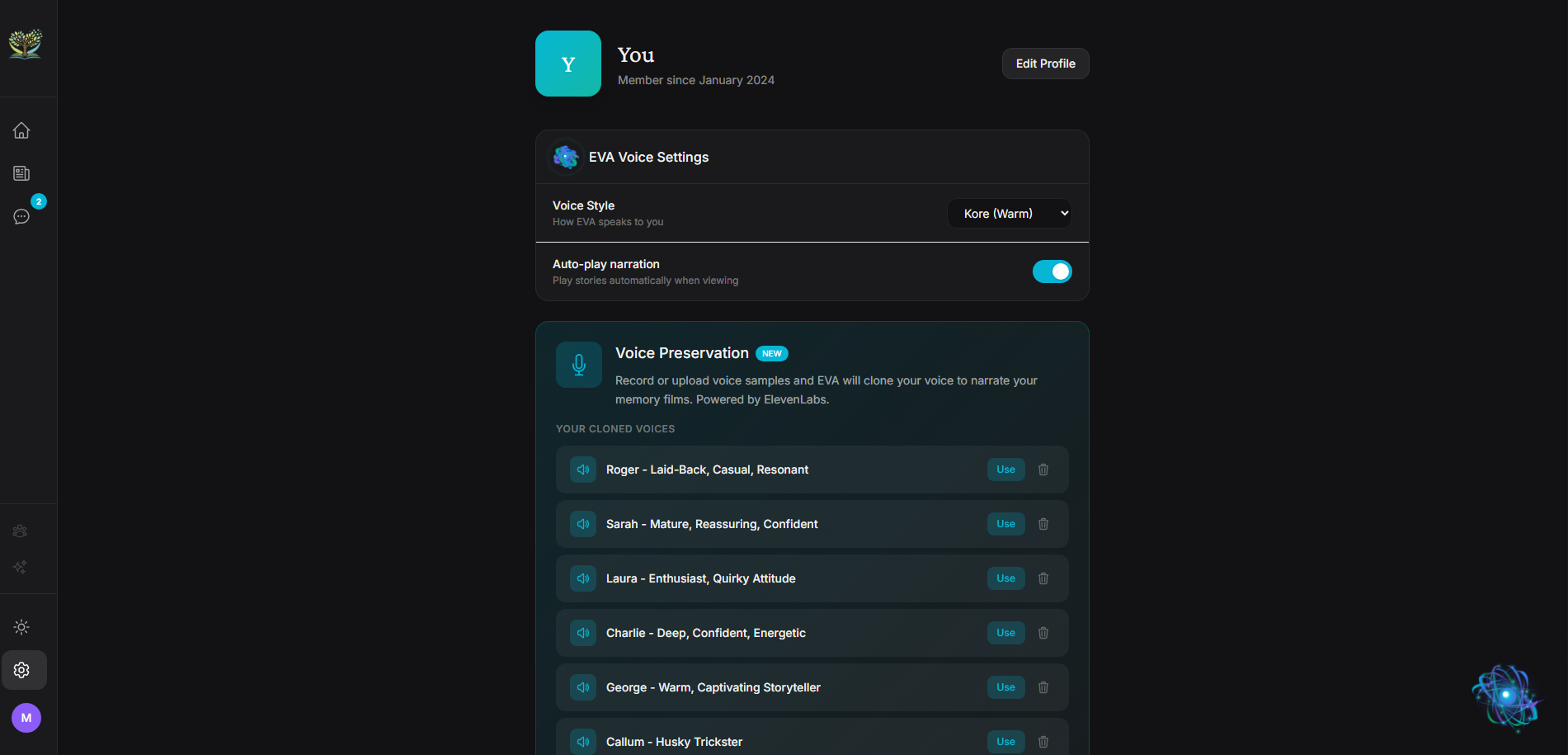
Preserve Your Voice — Clone your voice with a short sample. Your stories get narrated in your voice, not a stranger's.
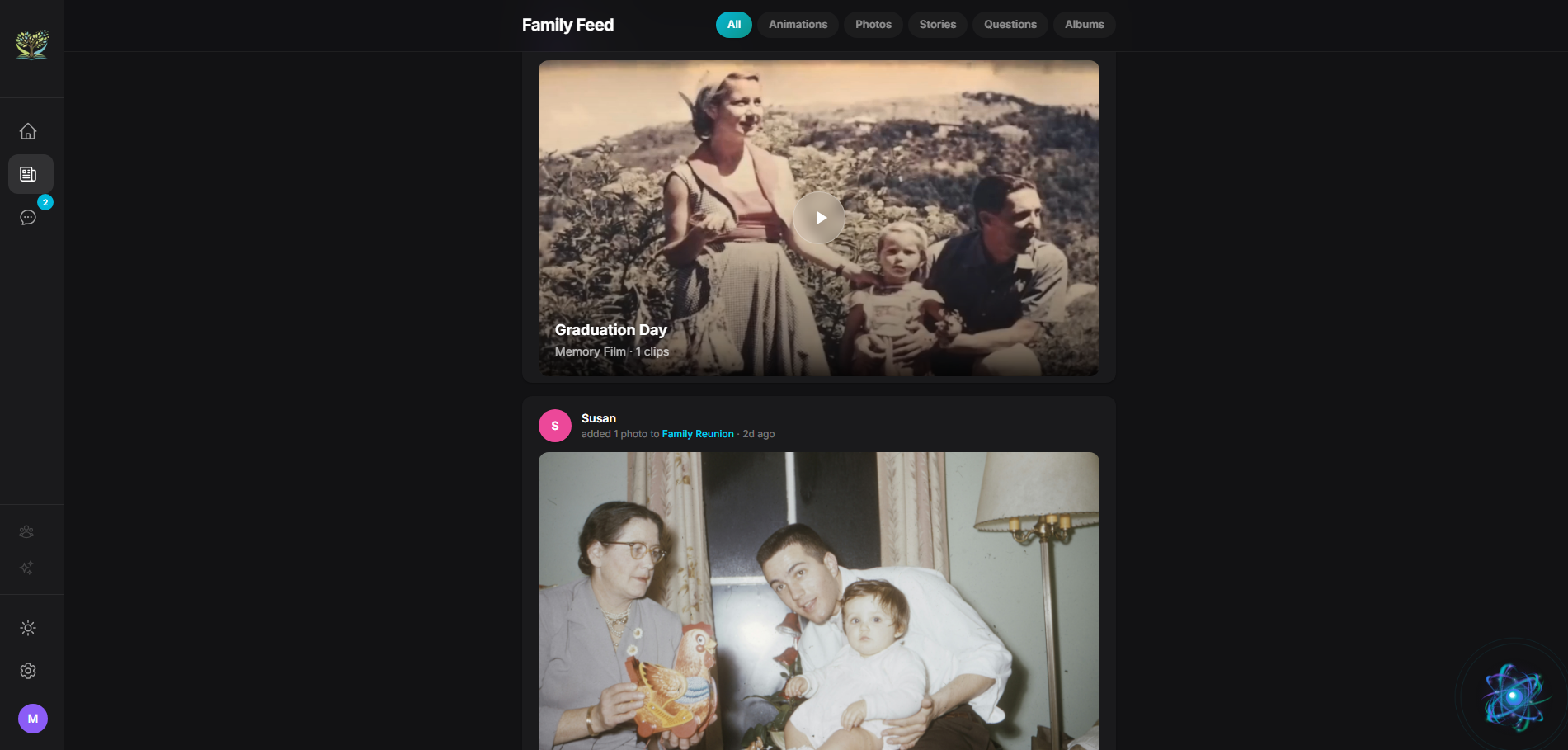
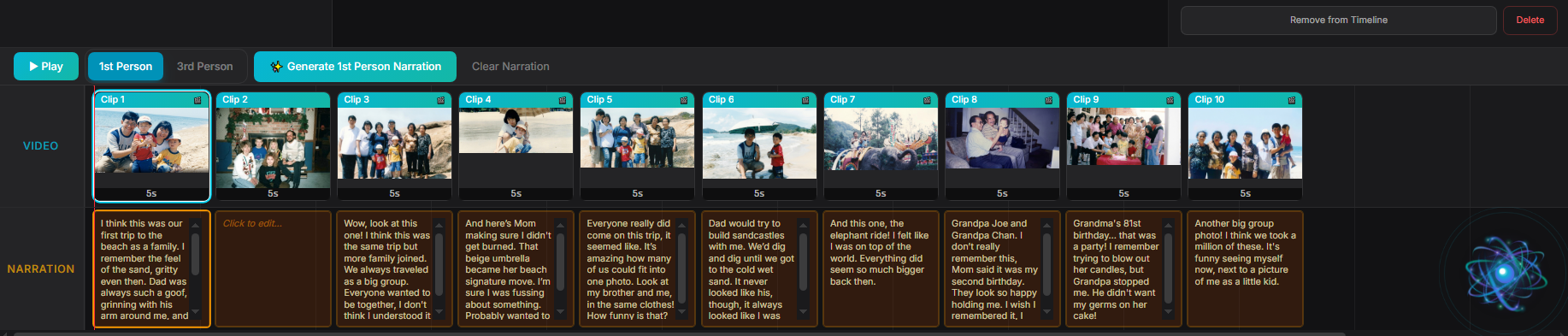
Create Films — Gemini generates context-aware narration by actually seeing each photo alongside your conversation transcripts. Reorder clips and the narration adapts. Export real video files with animated photos, voiceover, transitions, and title cards — all rendered in-browser.
Experience — Four viewing modes: Cinema carousel, Animated Slideshow, narrated Living Storybook (watch/read/film), and a page-flipping Scrapbook.
How we built it
Stack: Next.js 14+ (App Router), Supabase (Postgres + storage), Tailwind CSS (dark/light themes), TypeScript end-to-end.
Five Gemini capabilities power the core experience:
Gemini Live API (
gemini-2.5-flash-native-audio-preview) — Real-time bidirectional voice conversations with EVA via WebSocket. Used in onboarding, photo capture, answering family questions, and album creation. Kore voice, multimodal input (audio + images + text).Gemini 3 Pro Image Preview — Two key features: Nano Banana extraction (cleans camera captures of physical prints into full-frame photos) and style transfer (transforms photos into Disney/Pixar, Ghibli, Anime art styles before animation).
Gemini 3 Flash — The multimodal backbone: photo analysis, fact extraction (who/what/when/where/why), context-aware narration generation (sends actual photo images alongside text), storybook narrative weaving, and photo-level chat.
VEO 3.1 (
veo-3.1-generate-preview) — Video generation from still images. Configurable duration, includes Gemini Vision minor-detection safety check.Gemini Vision — Photo detection in camera frames, bounding box computation, minor detection before animation, and photo analysis during conversations.
Key decisions: All AI calls server-side. Gemini Live connects directly from client (server-fetched key). Video export entirely client-side via Canvas API + MediaRecorder + Web Audio API. Face detection with face-api.js. ElevenLabs integration for voice cloning.
Challenges we ran into
Gemini Live API lifecycle management — WebSocket connections need careful handling for disconnects, audio buffering, and turn-taking. On Vercel's serverless environment, we had to connect directly to Gemini's endpoint rather than proxying through API routes.
VEO 3.1's minor restrictions — VEO refuses to animate photos containing children, which is a lot of family photos. We built a Gemini Vision pre-check to detect minors and gracefully fall back to Ken Burns CSS animations.
Camera photo extraction — Detecting a photo within a camera frame (photo of a photo) requires handling perspective, glare, and occlusion. Our pipeline tries Gemini-powered bounding box detection first, then falls back to smart center crop, with duplicate detection via image hashing.
Audio sync in video export — Mixing VEO-animated segments with narration audio and Ken Burns fallbacks into one coherent video, all in-browser, required precise timing with requestAnimationFrame and Web Audio API.
Prompt engineering — Getting EVA to feel natural took dozens of revisions. One question at a time, specific visual references, using recognized names, knowing when to stop probing — each context (intro, capture, questions, album creation) has its own tuned system instruction.
Accomplishments that we're proud of
EVA feels real. The combination of Gemini Live's natural voice, carefully crafted prompts, and the Aurora Orb visual creates something that feels like talking to a caring friend — not an AI tool. When she references specific details in your photo, it genuinely moves people.
The end-to-end pipeline works. Physical photo album → camera scan → AI conversation → story synthesis → style transfer → animation → narrated storybook → exported memory film. Every step is connected and functional, not mocked.
Five Gemini capabilities in one app. Live API, Gemini 3 Flash, 3 Pro Image Preview, VEO 3.1, and Vision — each serving a distinct purpose, working together to create an experience impossible with any single capability.
Multimodal narration is the differentiator. Gemini doesn't just read text about your photos — it sees each photo alongside conversation transcripts and generates narration that references specific visual details. Reorder your clips and the narration rewrites itself to bridge them naturally.
Camera-mode photo scanning. Pointing your camera at a physical album while having a voice conversation with EVA — and the app automatically detects, crops, and extracts photos in the background — feels like the future.
The family questions system. A grandchild asks their grandmother about a specific photo, grandmother answers by talking to EVA, and that answer gets woven into the photo's story. That's multi-generational preservation actually working.
What we learned
Voice changes everything. When we switched from text chat to Gemini Live voice, people told longer, more emotional, more detailed stories. Speaking out loud — especially to a warm, patient voice — unlocks memories differently than typing.
Multimodal AI changes the design space. One ecosystem handles vision + conversation + voice + image generation + video generation. It let us focus on the experience instead of stitching together separate models.
The hardest part isn't the AI — it's the UX around it. When should EVA speak? How long should she wait? What happens during silence? These interaction design questions took more iteration than any API integration.
Browser-based video rendering works. Canvas API + MediaRecorder + Web Audio API can produce decent video entirely client-side — zero server cost for rendering.
Gemini 3 Pro Image Preview opens creative possibilities. Style-transferring a family photo into Disney/Pixar 3D while preserving composition and identity, then animating it with VEO 3.1 — that creates output that feels genuinely cinematic.
Gemini Integration
Living Memory is built on Google Gemini as its core intelligence layer — not as a feature add-on, but as the foundation that makes the entire experience possible.
Gemini Live API (gemini-2.5-flash-native-audio-preview) powers EVA's real-time voice conversations. Users talk naturally about their photos via bidirectional WebSocket, with EVA speaking in the Kore voice and receiving multimodal input (audio + images + text simultaneously). Used across five contexts: onboarding, photo capture, family questions, family tree, and album creation.
Gemini 3 Pro Image Preview powers Nano Banana extraction (cleaning camera captures of physical prints into pristine photos) and style transfer (transforming photos into Disney/Pixar, Ghibli, and Anime art styles before animation).
Gemini 3 Flash handles multimodal photo analysis, structured fact extraction from transcripts, context-aware narration generation (sending actual images alongside text), storybook narrative weaving, and conversational chat.
VEO 3.1 brings photos to life — generating cinematic video from still images with gentle motion and soft camera movements.
Gemini Vision provides image understanding across the app: detecting photos in camera frames, computing bounding boxes, and performing minor detection for VEO safety compliance.
Remove Gemini and there is no EVA, no voice conversations, no photo extraction, no style transfer, no narration, no animation, no storybook. Every core experience flows through Gemini.
What's next for Living Memory
Knowledge Base — EVA will build a deep understanding of your family over time. Faces, relationships, and context from every conversation feed into a persistent knowledge base. Each story becomes richer than the last as EVA connects memories across decades.
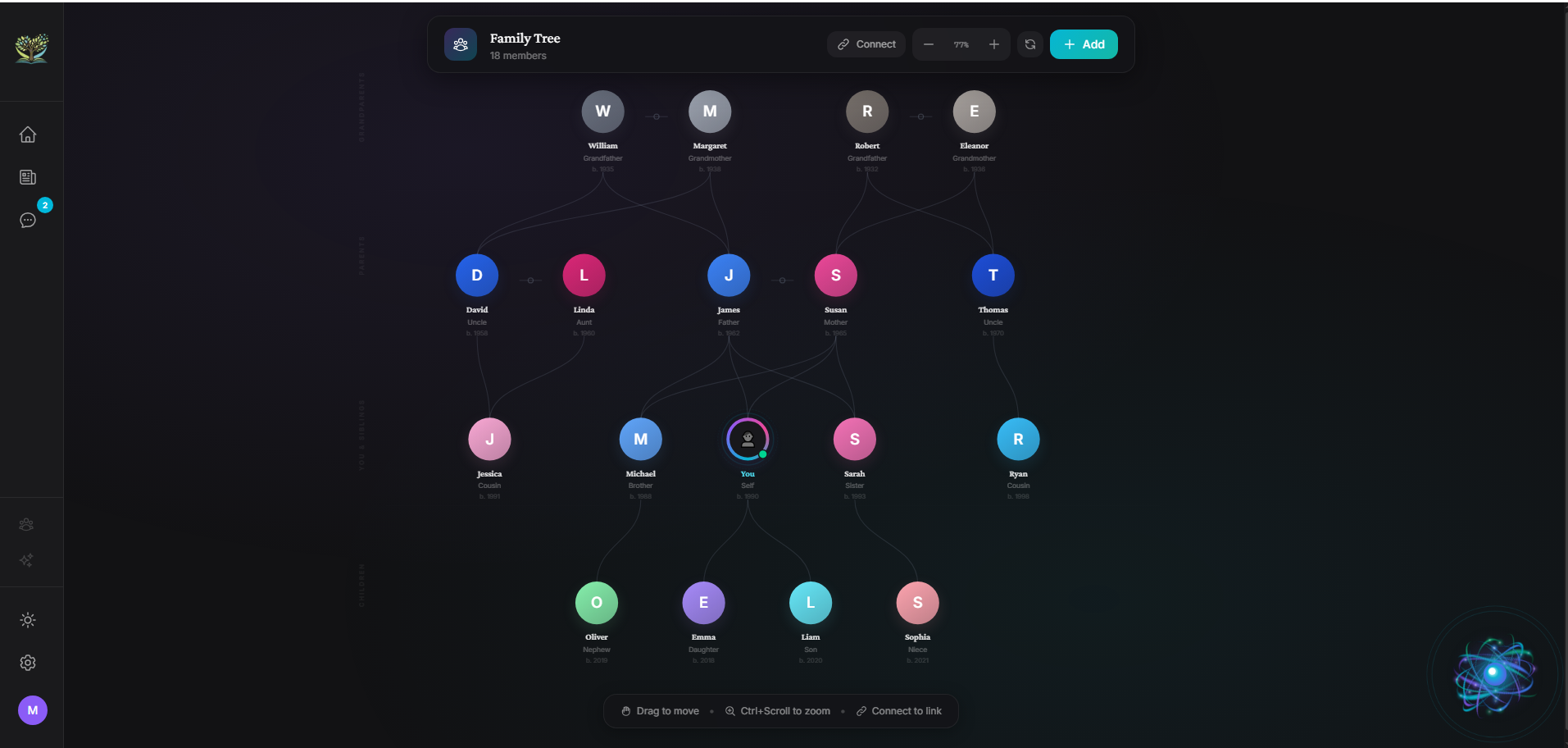
Family Tree — A visual, interactive family tree where EVA understands who's who — linking memories with relationship-aware narration. Your family tree informs every story she tells.
Google Genie — Step inside your photographs. Genie will transform flat images into explorable 3D worlds — walk through grandma's kitchen, revisit a childhood playground, experience your memories spatially.
Built With
- next.js
- supabase
- typescript











Log in or sign up for Devpost to join the conversation.