-
-
Homepage
-
LiveTales Flow
-
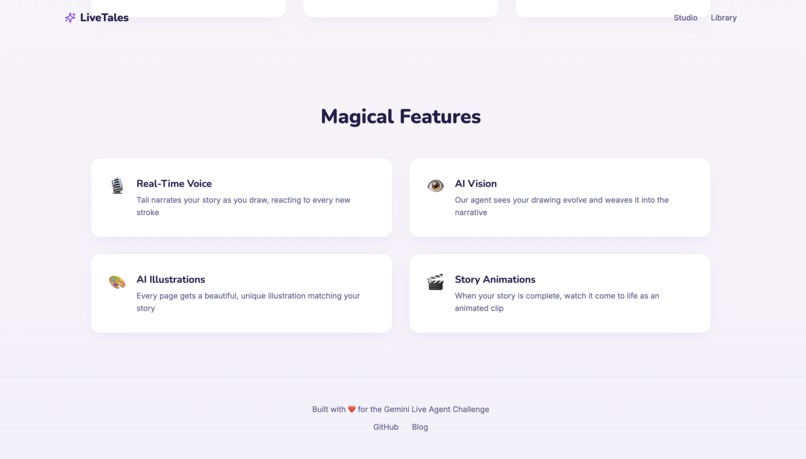
LiveTales Component
-
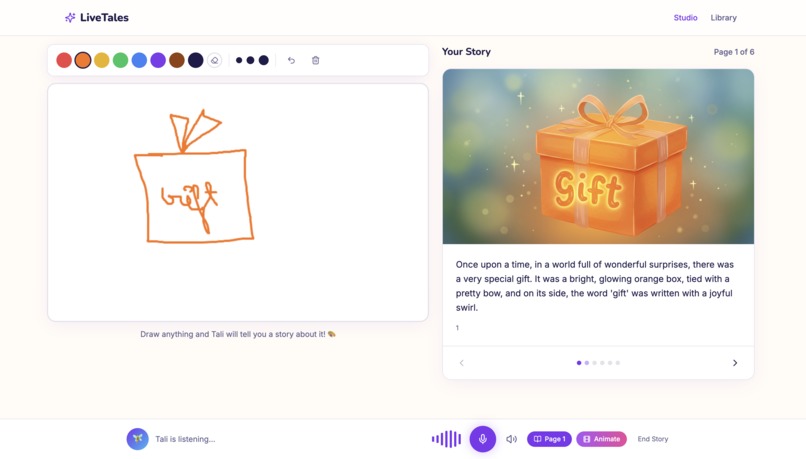
Canvas Playground
-
LiveTales Architecture
-
LiveTales Components
Inspiration
Screen time is one of the biggest concerns for parents of young children. Most apps aimed at kids are passive — children just watch, tap, and swipe. We asked: what if screen time could be creative, educational, and deeply personal?
We wanted to build something where a child's imagination drives the experience — where their drawings and words become the raw material for a unique story that only they could create. That's how LiveTales was born.
What it does
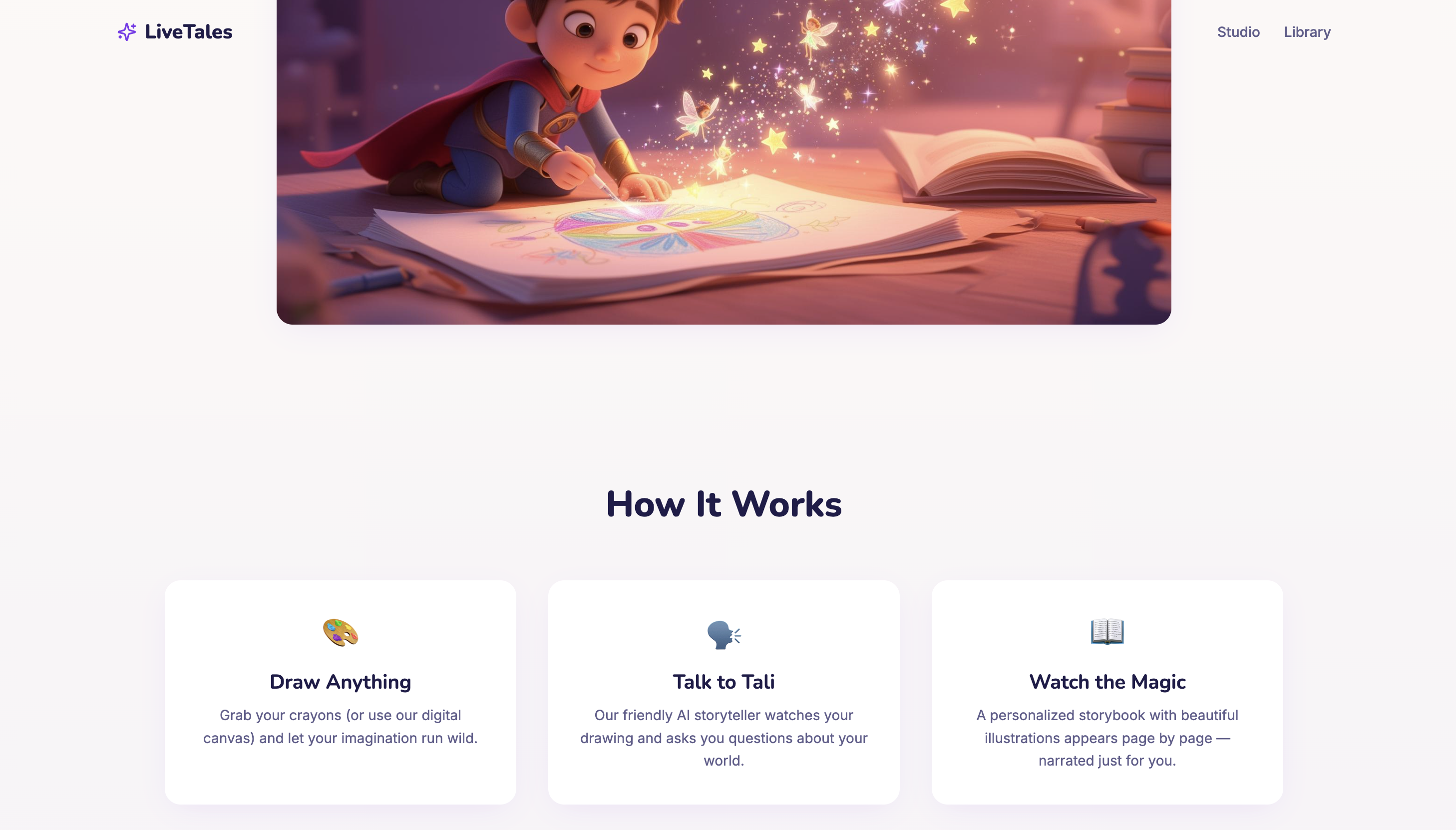
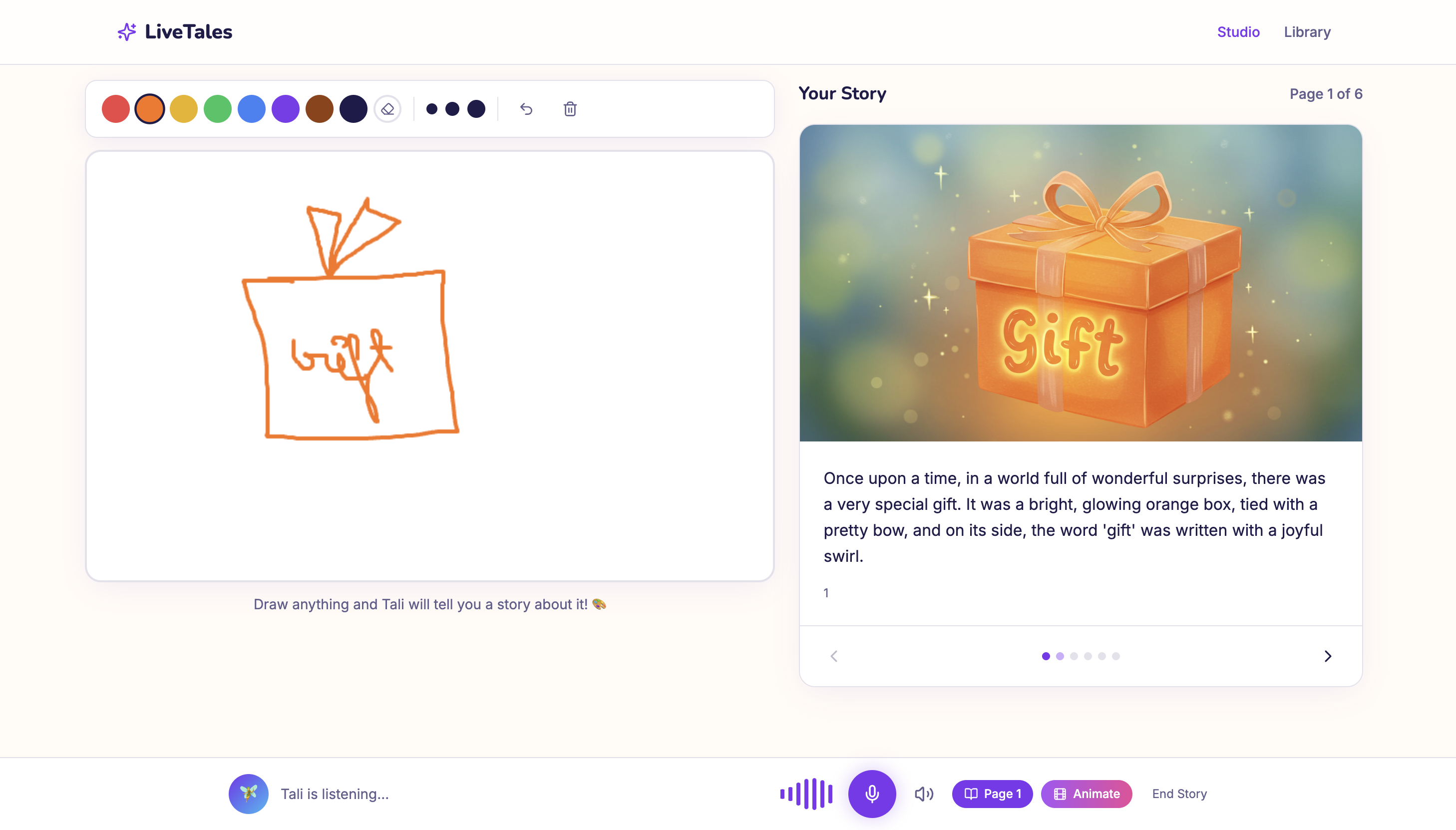
LiveTales is an interactive AI storytelling app for children ages 3–13. Kids draw on a canvas and talk in real-time with Tali — an AI friend who sounds like an excited 7-year-old. Tali watches the child draw, reacts with genuine enthusiasm ("Ooh is that a dragon? I love dragons!"), asks imaginative questions, and helps co-create a story.
When the child is ready, LiveTales transforms their drawings and conversation into a fully illustrated, narrated, animated 6-page storybook:
- Draw on an interactive canvas with colors and brushes
- Talk with Tali in real-time — she responds instantly with voice
- Generate a 6-page story based on the drawing + conversation
- See watercolor-style AI illustrations for each page
- Listen to the full story narrated expressively
- Watch gentle animated video clips of each illustration
Every story is unique because it comes from the child's own imagination.
How we built it
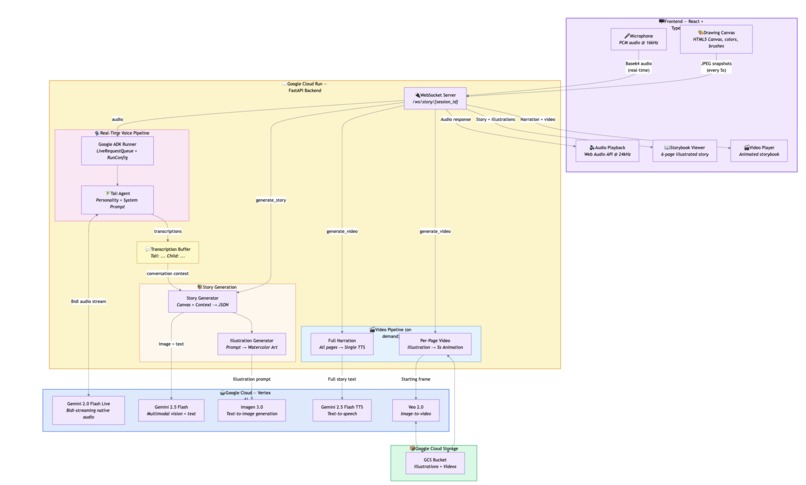
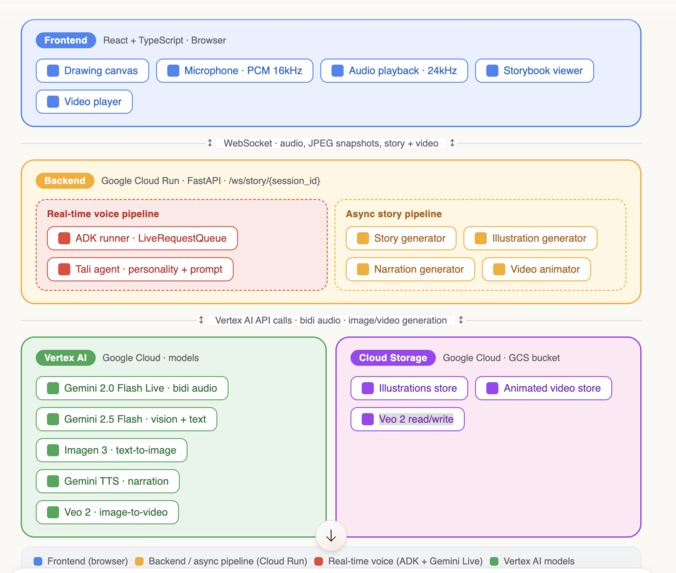
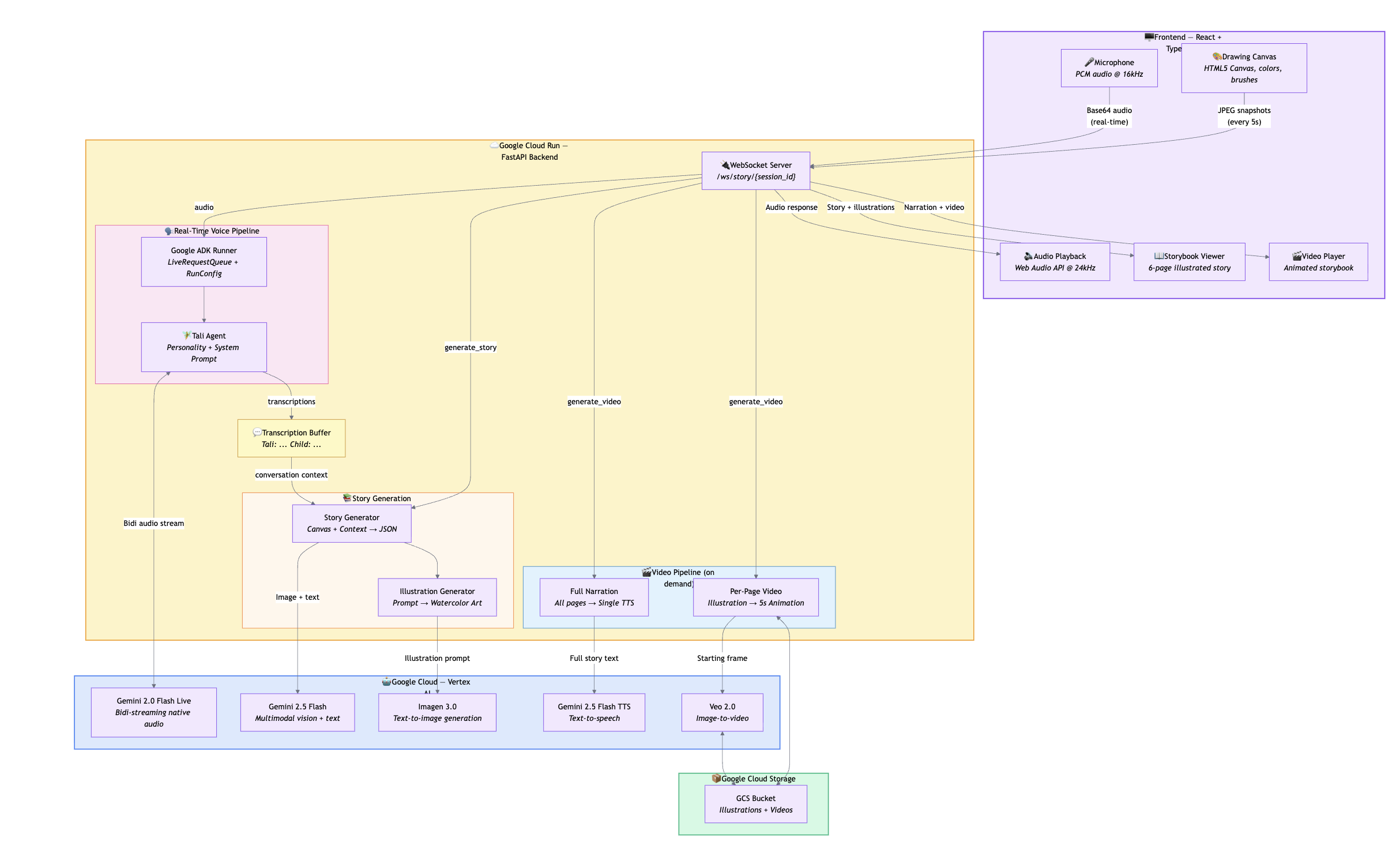
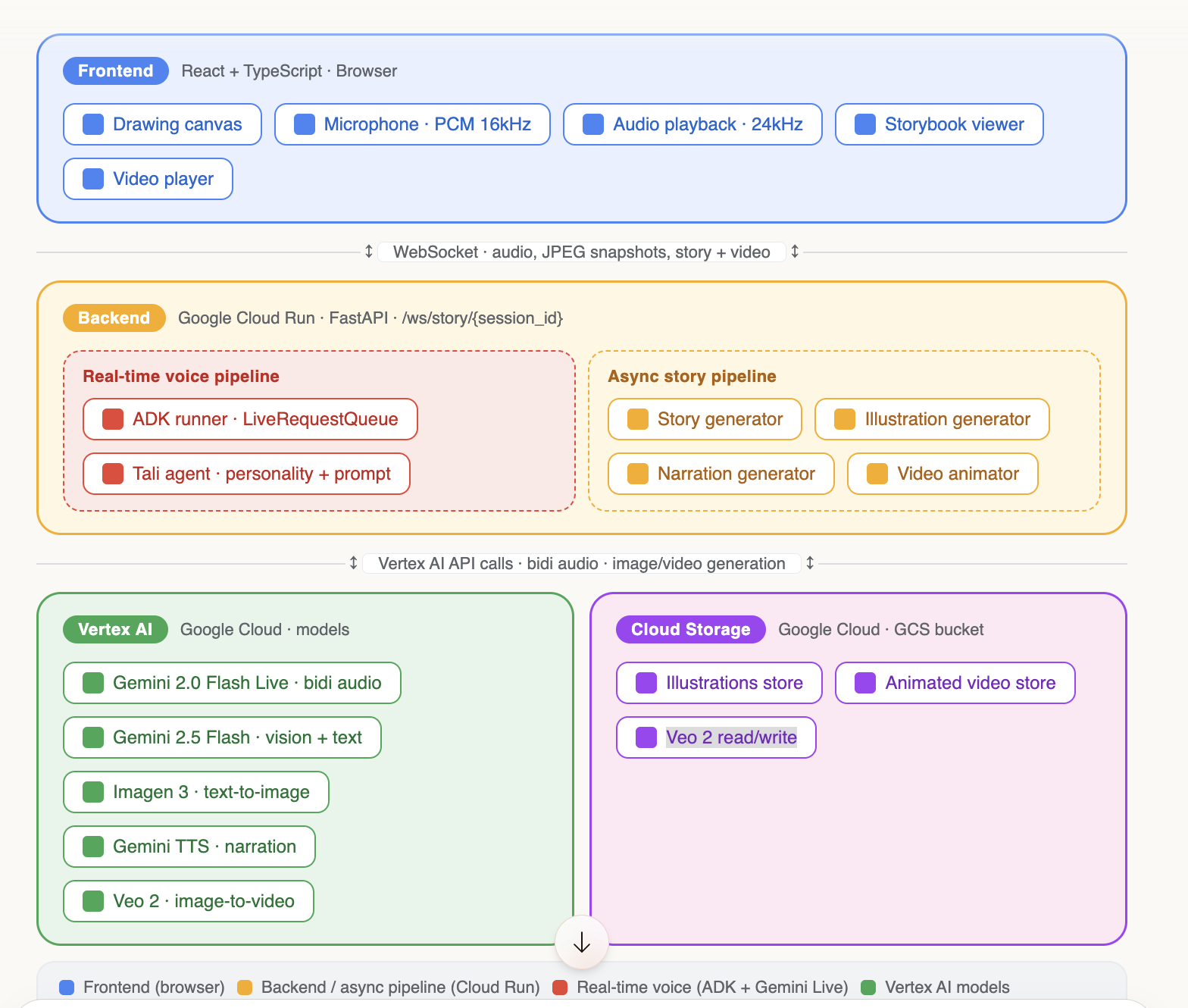
Tali is a Google ADK Agent. We used the Google Agent Development Kit (ADK) to define Tali as an Agent with a personality-driven system prompt and run her via Runner.run_live() with LiveRequestQueue for real-time bidirectional audio streaming. ADK handles session management, streaming lifecycle, voice configuration, turn-taking, and interruption handling — letting us focus on the experience rather than low-level API plumbing.
The architecture has three pipelines:
Voice Pipeline (real-time): Browser microphone → WebSocket → ADK Runner + LiveRequestQueue → Gemini 2.0 Flash Live → audio response back to browser. Three concurrent async tasks in a
TaskGroupkeep this responsive at all times.Story Pipeline (async): Triggered on demand. The child's canvas snapshot (JPEG) + tagged conversation context (
Tali: ... Child: ...) is sent to Gemini 2.5 Flash, which generates structured story JSON. Each page's illustration prompt is then sent to Imagen 3.0 to generate watercolor-style children's storybook art.Video Pipeline (async, parallel): Triggered after the story is complete. Gemini 2.5 Flash TTS generates a single expressive narration for the full story. Simultaneously, Veo 2.0 animates each illustration into a 5-second video clip via Google Cloud Storage.
Frontend: React 18 + TypeScript with Tailwind CSS, shadcn/ui, Zustand for state management, and Framer Motion for animations. The useVoiceSession hook manages the entire WebSocket + Web Audio API lifecycle.
Backend: Python 3.12 + FastAPI, deployed on Google Cloud Run with Vertex AI.
Challenges we faced
Keeping Tali responsive during heavy generation. Story generation, illustration, and video are slow calls. We had to strictly decouple them from the live voice pipeline — ADK handles voice, a separate Vertex AI client handles everything else as async background tasks.
WebSocket lifecycle with long-running video generation. Veo can take 1-3 minutes per page. We added keepalive progress messages and task tracking to prevent WebSocket timeouts, and wait for pending video tasks before closing connections.
Child-safe content at every layer. No single safety mechanism is enough. We combined Imagen's
block_low_and_abovesafety filter, carefully scoped prompts ("watercolor style, warm colors, safe for children"), and Tali's personality rules ("never be scary or negative") for defense in depth.Making conversation context useful for story generation. We tag transcriptions as
Tali:andChild:in a rolling buffer, so when Gemini 2.5 Flash generates the story, it knows what the child actually said vs. what Tali said — making stories feel truly personal.
What we learned
Google ADK makes real-time voice agents accessible. The Agent + Runner + LiveRequestQueue pattern gave us production-grade bidi-streaming with minimal boilerplate.
Latency is everything when your user is 5 years old. Gemini 2.0 Flash Live's sub-second response time is what makes the experience feel magical. Progressive delivery (text first, then illustration) keeps children engaged while heavier models work in the background.
Multimodal orchestration = decoupled pipelines. Live streaming and traditional API calls require fundamentally different patterns. Keeping them separate was the key architectural decision.
What's next for LiveTales
- Multi-language support (Tali already speaks English, but kids everywhere deserve a creative AI friend)
- Collaborative storytelling (multiple children drawing and talking together)
- Story sharing and a parent dashboard
- Expanding to more age groups with adaptive difficulty
Built With
- 2.5
- adk
- ai
- cloud
- css
- docker
- fastapi
- flash
- framer
- gemini
- imagen
- live
- motion
- python
- react
- run
- storage
- tailwind
- typescript
- veo
- vertex
- vite
- websockets




Log in or sign up for Devpost to join the conversation.