




Inspiration
We wanted to create an interpreter that feels more natural to actual situations that may occur that require the use of a real-time translation, such as online meetings! During meetings, you would want to be able to talk to a hard of hearing person using ASL, without needing a setup specifically made for detecting your hand or resorting to an impersonal texting/messaging medium. For this reason, we have made an ASL interpreter that is able to translate words in real-time, in most environments, comfortably and naturally.
As a bonus, we also thought having an accessible ASL interpreter could potentially encourage people to practice and learn the basics of the language. Our hope is that this application will both be useful, educational, and maybe even fun!
What it does
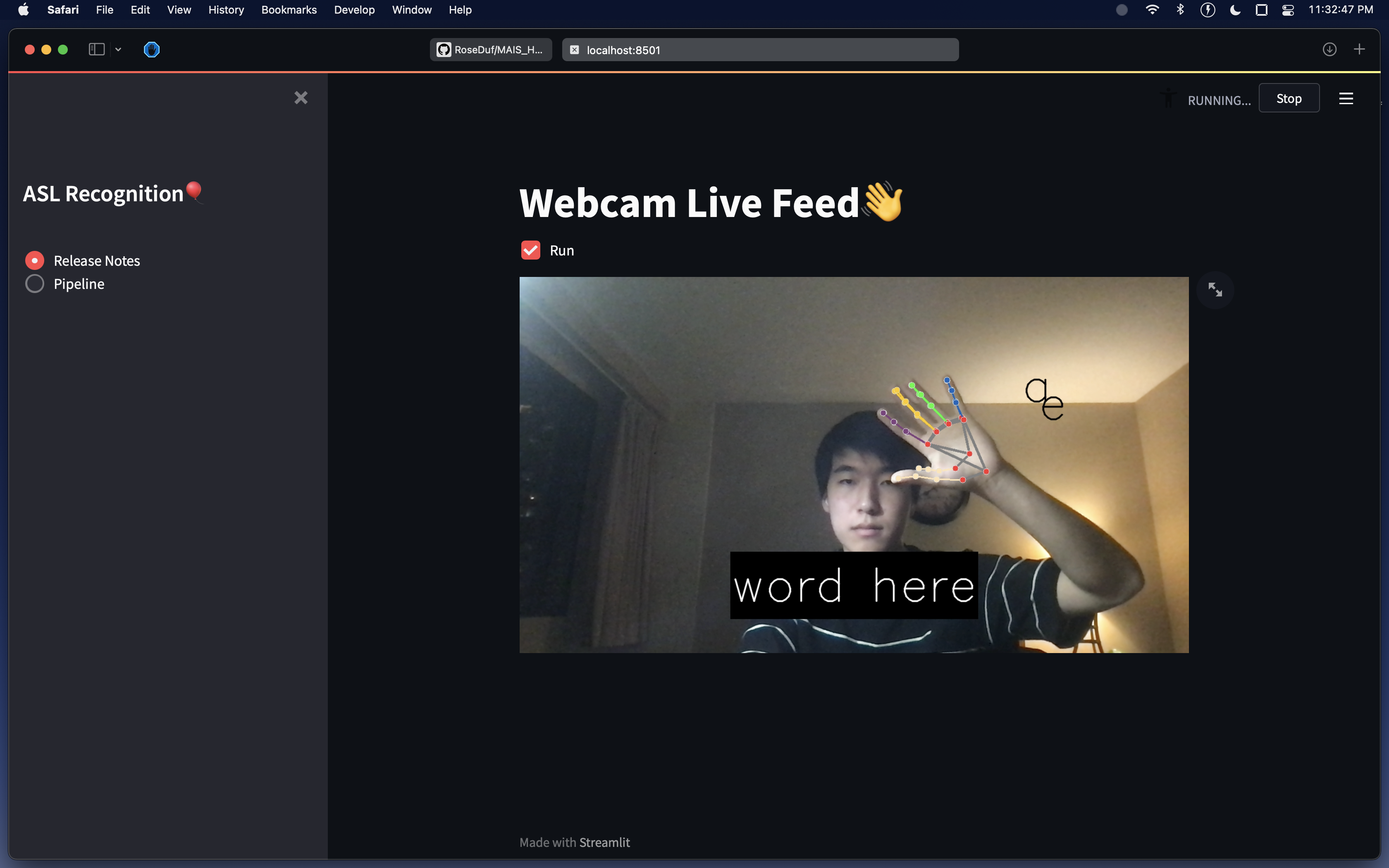
LiveSigns recognizes ASL (American Sign Language) alphabet letters through your video camera and adds your text, in real-time, on the screen for you and others to see! No worries, there's even autocorrect in case you misspell a word.
LiveSigns has a web demo to try it out without any download, no commitments! LiveSigns can also be helpful for you to practice and learn the ASL alphabet (our team has surely learned quite a bit of it while making this project). You can even use LiveSigns for video calls, from Zoom meetings to Discord video calls.
We highly recommend you watch our video demo to better understand what LiveSigns can do for you 😃.
How we built it
1. Manipulating a Virtual Camera
The OpenCV library was used for its fast speed and how intuitive it is to use.
2. Detecting Hands
For detecting hands, we used the mediapipe library, which not only detects hands in the frame but creates 22 3D coordinates of the entire hand, giving us rich data to work with.
3. ASL Alphabet Recognition
We then used this hand-detection model to extract the coordinate data from an ASL alphabet dataset. Using this coordinate data, we tried 6 different machine learning models. We ended up choosing the Random Forest Classifier model as it was the most effective one, with 99.1% accuracy.
4. Output to Virtual Camera
OpenCV allowed us to display text and images onto the virtual camera. However, as an extra step, we needed to use a library called pyvirtualcam on top of OpenCV for video calls, and the streamlit library's image function for the website.
5. Autocorrect
Some words will sometimes have mistakes, especially when someone is learning the language for the first time. We would hate to require the person to completely rewrite their word from scratch every time they do a mistake. So, much like when we are typing using a keyboard, we will correct the word they were trying to spell to the closest estimated word.
6. Showcase on the Web
We used a super awesome library called streamlit to create a lightweight and beautiful looking website all in Python, thus allowing us to embed our camera GUI into the website.
Challenges we ran into
- Creating the dataset was tough due to how large the dataset was (taking one hour to generate one model)
- Choosing the proper model for the dataset, since many of the models had low accuracy, and different models had to be tried.
- Attempting to make a more accurate autocorrect system made in accordance to more common mistakes that may occur using ASL. For example, some letters that are similar to each other (i.e., M and N) should be taken into account when choosing the most appropriate correction. This differs from the conventional autocorrect system. However, after struggling through making the dataset and making sequence-to-sequence models, we were unable to find a satisfactory solution. Therefore, we resorted to an already built, general-purpose spell checker.
- We want to implement text-to-speech, but the package we trying to implement didn't allow us to automatically output the spoken word as they were being made.
Accomplishments that we're proud of
- The entire project! 😁
- Making LiveSigns work for any video conference platform (tested on Zoom, Meet, Discord, and Gather)!
- Having LiveSigns work on a website, no download necessary!
What we learned
- Eduard: I learned how to work with very big datasets and making machine learning models; the mediapipe library was so cool to learn.
- Jinho: I learned a lot of cool technology during this hackathon: the mediapipe library, OpenCV, and sequence-to-sequence models (30% understood); having never worked on a computer vision project, seeing the end results were incredible.
- Rose: Seq2Seq models (to a certain extent), object detection and mediapipe. Was introduced to a whole new array of things we can do with OpenCV and AI which opened me to so many new ideas. This event also was a great motivator to refresh my memory on AI.
- Bridget: ways to tell if a model is overfitting and possible solutions. Explored streamlit library for web outputs. Live video capturing and processing with OpenCv is also pretty cool.
What's next for LiveSigns
- An educational version of LiveSigns, focused on learning the alphabet: for instance, given a random word on the screen, you need to spell it in a certain amount of time.
- Generate entire sentences/transcripts; create a more accurate autocorrect system (using a sequence-to-sequence model) to help with correcting sentences with the most common mistakes with ASL.
- Add motion for more complex ASL vocabulary, as ASL words require shape and motion as a part of the word, unlike the letters, which only require shape.
DEMO: http://35.203.92.29:8502/ It is recommended for this build to deploy locally (web2.py file) to avoid any browser security issues.
Built With
- asl
- machine-learning
- mediapipe
- opencv
- python
- scikit-learn
- streamlit
- web











Log in or sign up for Devpost to join the conversation.