-
-
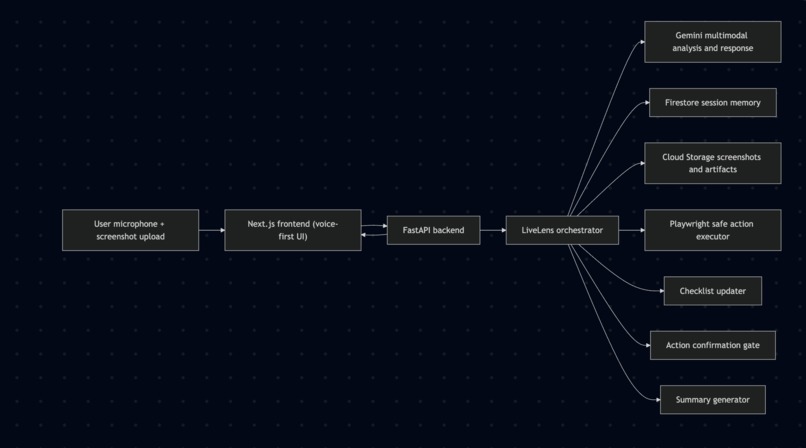
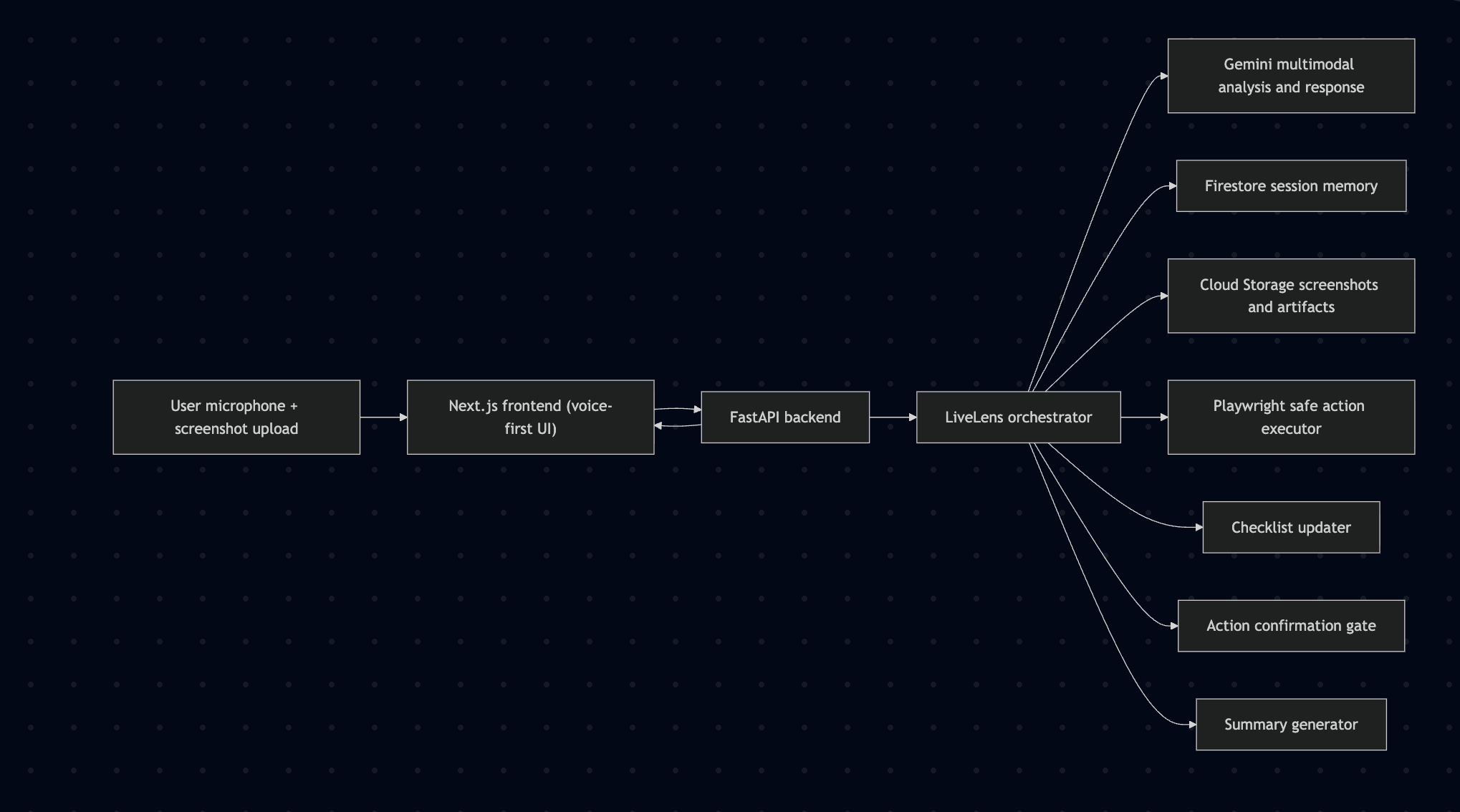
LiveLens Architecture Diagram
What it does LiveLens is a voice-first AI copilot for confusing online tasks. You upload a screenshot of wherever you're stuck — a tax form, visa portal, insurance enrollment, job application — and ask your question out loud. LiveLens reads what's visible on screen using Gemini's multimodal vision, explains it in plain language, tracks your progress on a live checklist, and can propose safe browser actions that only execute after your explicit approval.
Inspiration Every year, millions of people abandon complex online forms — not because the task is impossible, but because the interface is hostile. A field label with no explanation. A warning buried at the bottom of the page. A required attachment they didn't know about. Traditional chatbots can't help because they're disconnected from what's actually on the screen. We wanted to build something genuinely grounded — an agent that sees what you see and responds to that, not to a generic description of your problem.
How we built it The frontend is Next.js 14 with the Web Speech API for real-time voice input and speech synthesis — no third-party voice service needed. Screenshots are uploaded to the session and immediately analyzed by Gemini 2.5 Flash using multimodal prompting that returns structured JSON envelopes: a screen summary, a list of checklist items extracted from visible UI state, and an optional suggested action.
The backend is FastAPI running on Google Cloud Run, with Firestore storing session state (transcript, checklist, action log) and Cloud Storage holding uploaded screenshots. A session orchestrator manages the state machine — idle → listening → thinking → speaking → awaiting confirmation — and enforces a hard confirmation gate before any browser action is executed via Playwright.
Gemini is prompted to describe only what is visibly present on screen, with explicit instructions to return null for suggested actions when no clear target is identifiable. This keeps the agent grounded and prevents hallucinated guidance.
Challenges Structured outputs from Gemini. Early versions used keyword matching on Gemini's free-text responses to update session state. This was fragile and unpredictable. Switching to JSON envelope prompts with response_mime_type: application/json made state transitions deterministic and reliable.
CORS and deployment configuration. Getting the ALLOWED_ORIGINS env var to parse correctly through gcloud run deploy required careful escaping. The fallback in the config is silent — no error is thrown, requests are just blocked — which made this harder to diagnose initially.
Voice UX on the web. The Web Speech API behaves differently across browsers and operating systems. Safari doesn't support SpeechRecognition at all. Handling the async voiceschanged event for voice selection, and gracefully degrading to text input when speech isn't supported, required more edge case handling than expected.
Rate limits on the free Gemini tier. The free tier allows 20 requests per minute on gemini-2.5-flash. A single demo session with screenshot analysis + several utterances can hit this quickly. Enabling billing resolved this but it was an unexpected friction point during development.
What we learned Multimodal grounding is a genuine unlock for agentic UX. The difference between a chatbot that answers generically and one that can say "I can see the 'Exempt payee code' field in Box 4 — most individual freelancers leave this blank" is the difference between useful and not useful. Gemini's vision quality on form screenshots was consistently strong.
The explicit confirmation gate also turned out to be a feature, not just a safety measure. Users trust the agent more when they can see exactly what action is proposed and why, before anything happens.
Built With
- artifact
- cloud-storage-automation:-playwright-(safe-browser-action-execution)-infrastructure:-docker
- firestore
- framer-motion
- frontend:-next.js-14
- google-cloud-build
- pydantic
- python-3.11
- react-18
- tailwind-css
- typescript
- uvicorn-ai:-gemini-2.5-flash-(multimodal-screenshot-analysis-+-structured-response-generation)-google-cloud:-cloud-run
- web-speech-api-backend:-fastapi

Log in or sign up for Devpost to join the conversation.