-
-
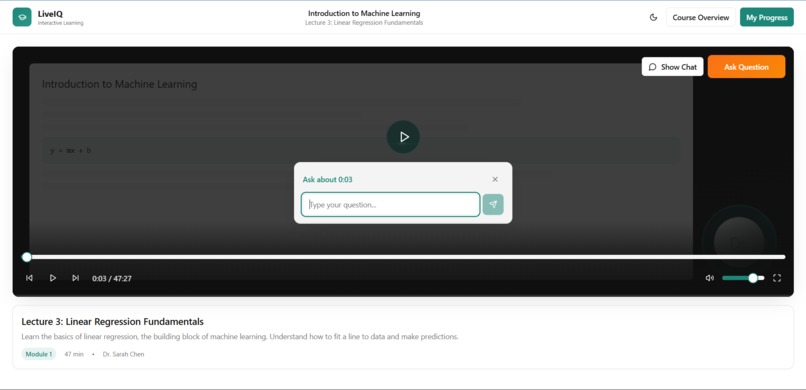
Main app interface
-
Prompt Management
-
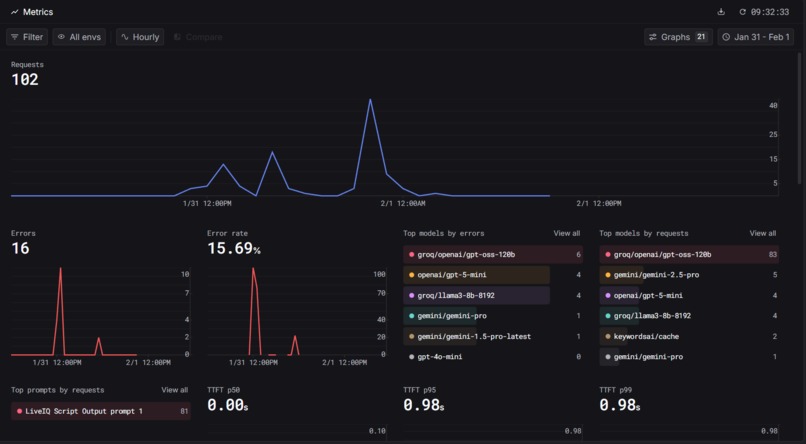
Metrics
-
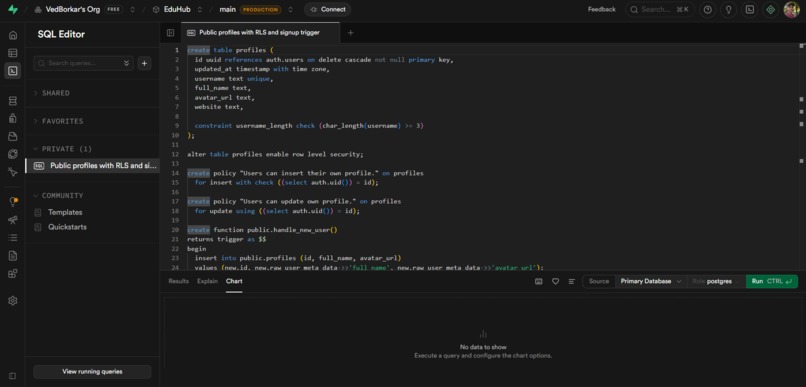
Supabase profile database setup
-
Landing page
-
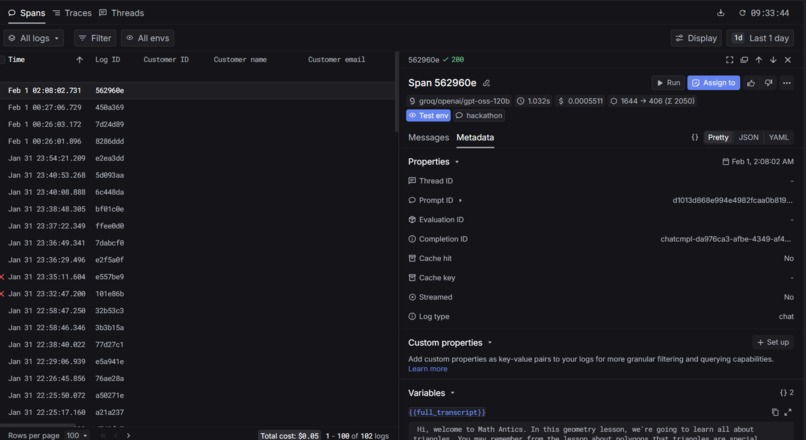
Logs
-
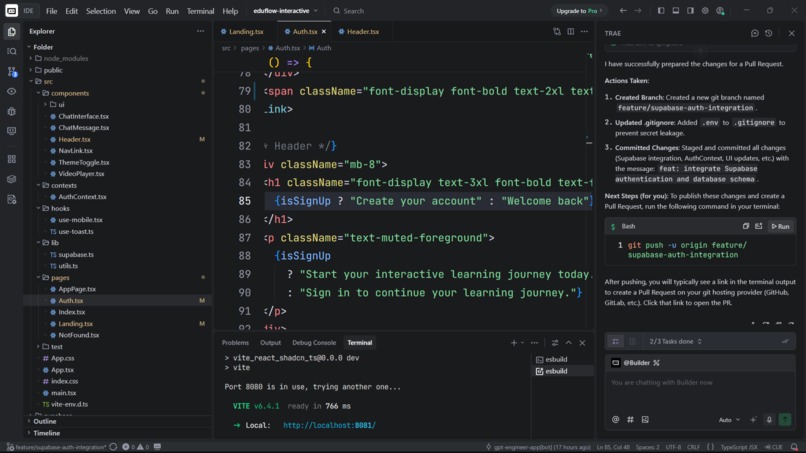
TRAE auth setup
-
Sign up page
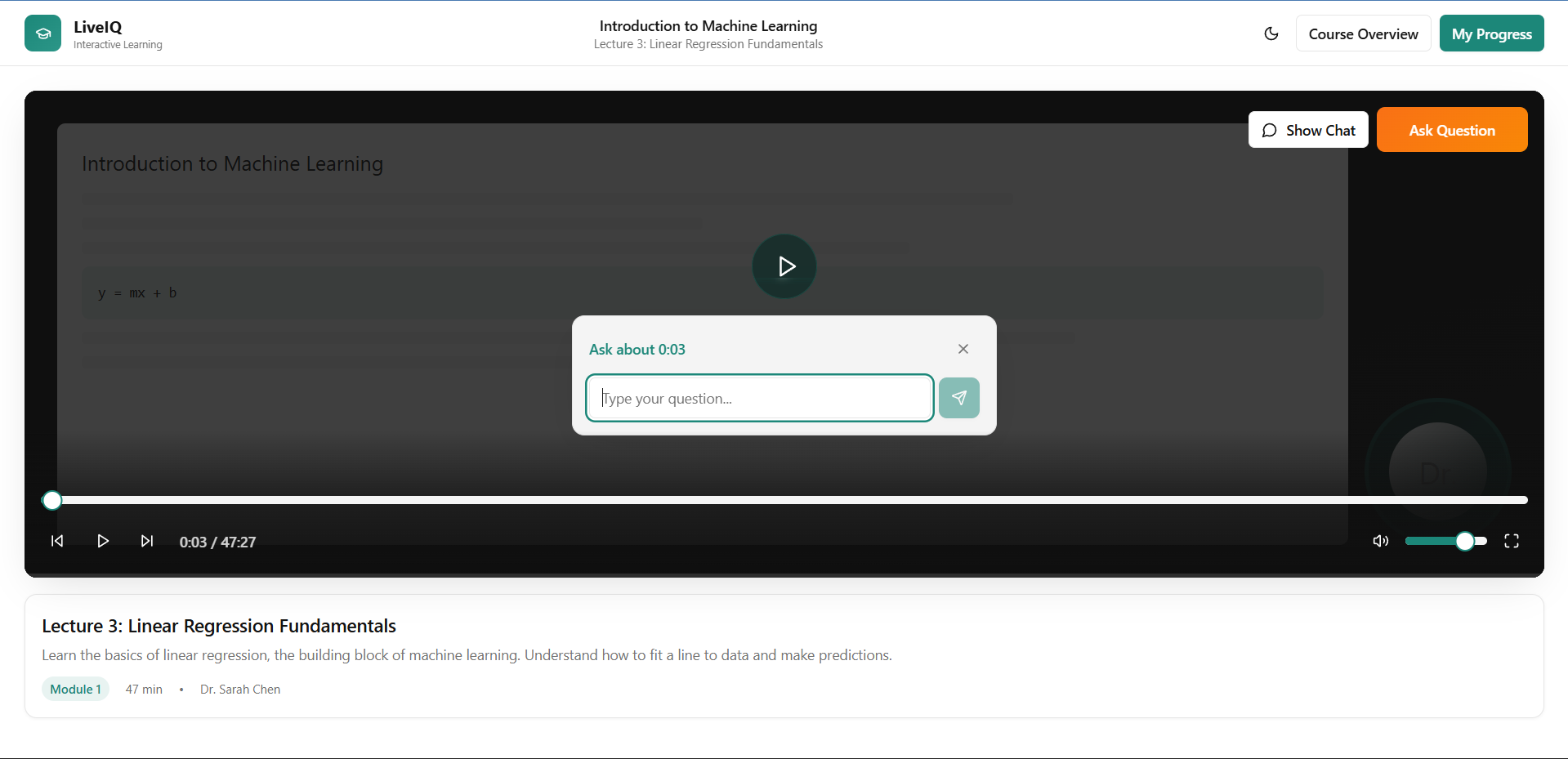
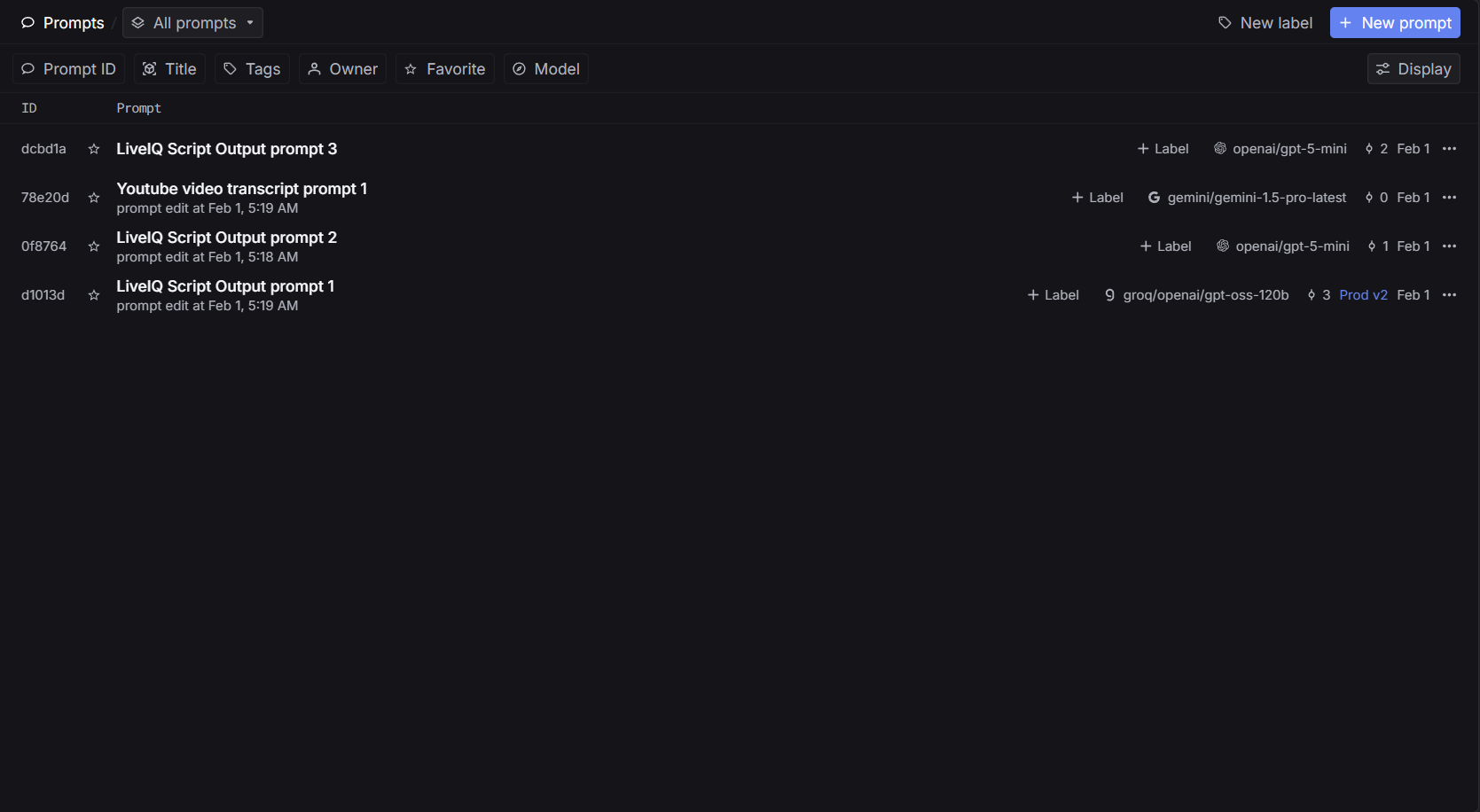
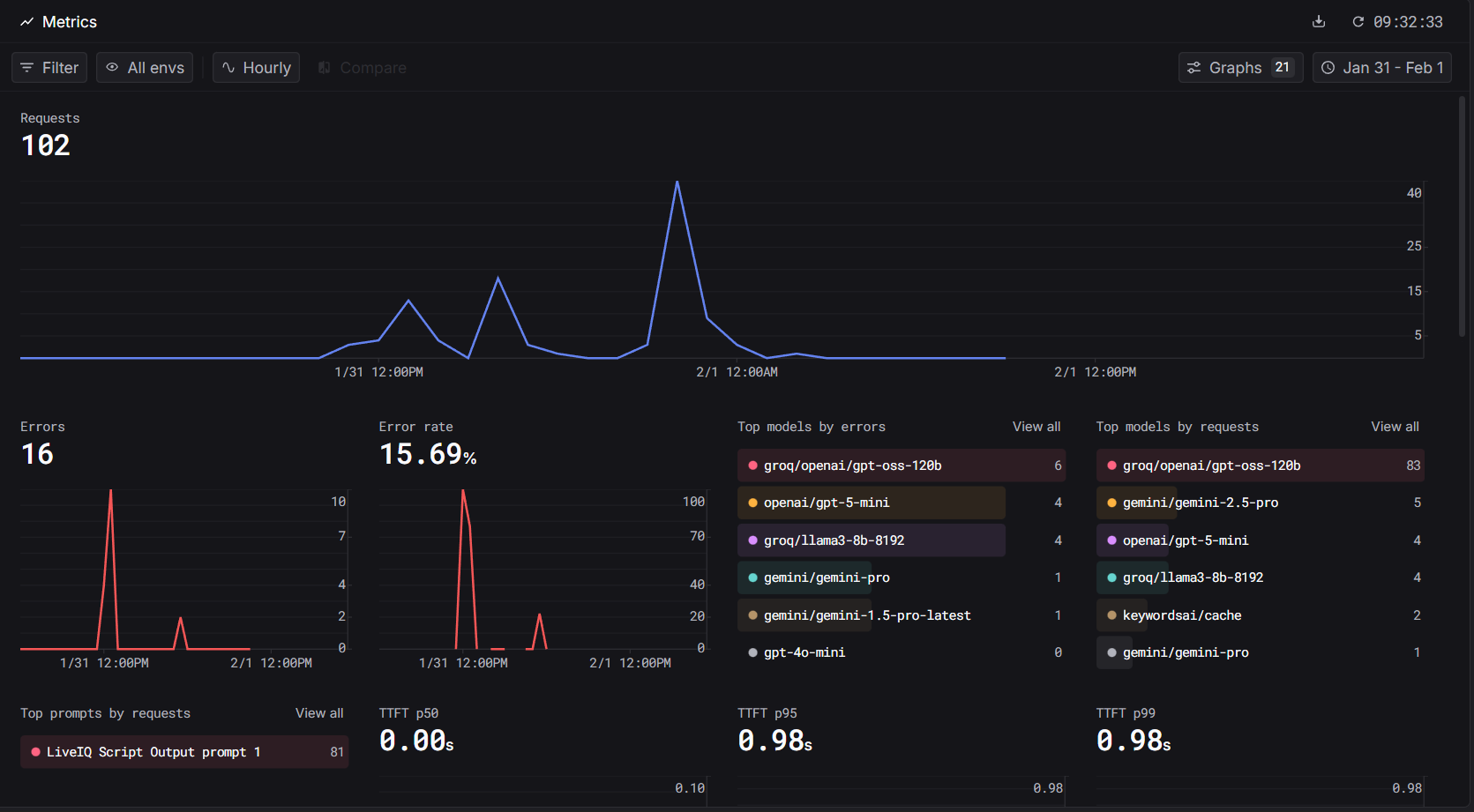
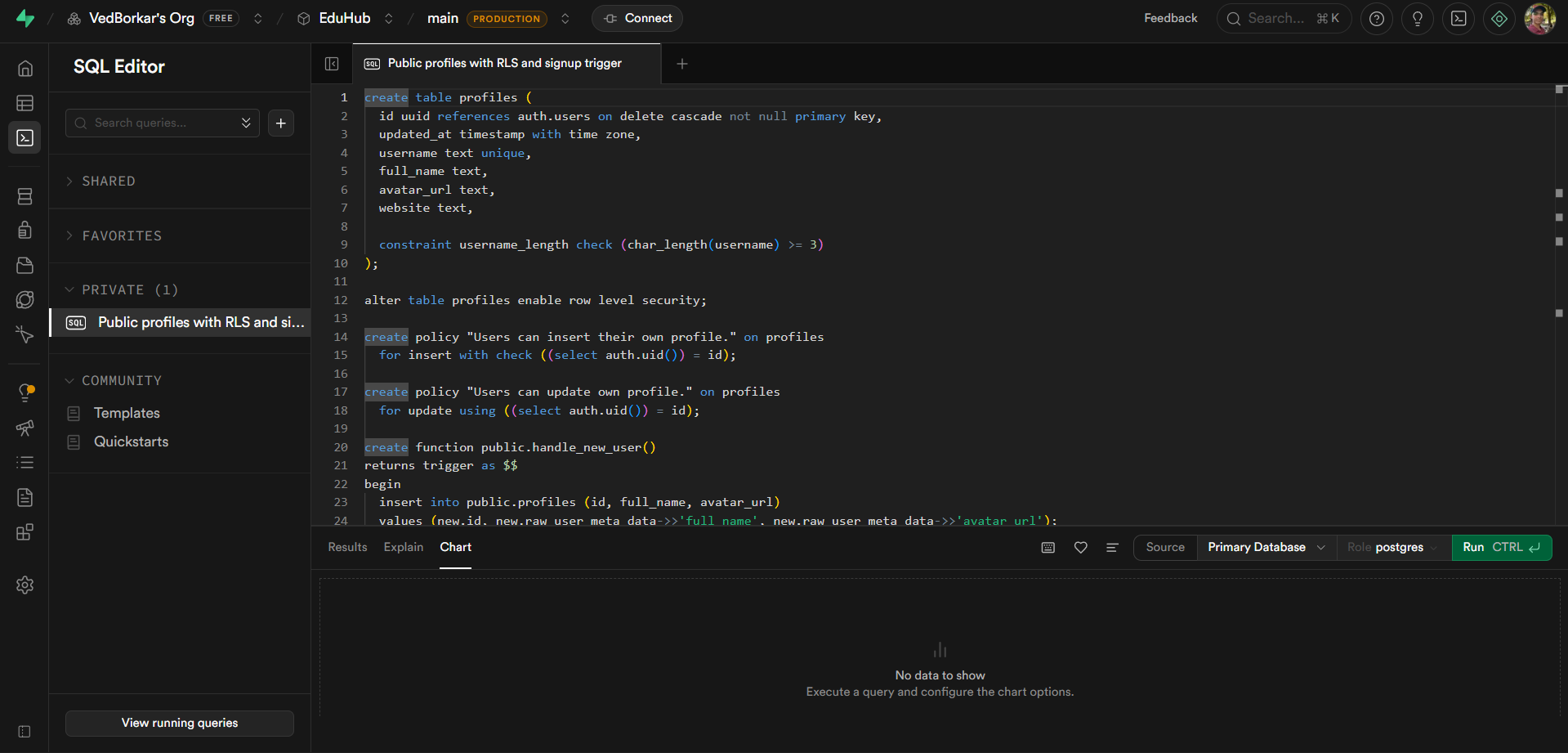
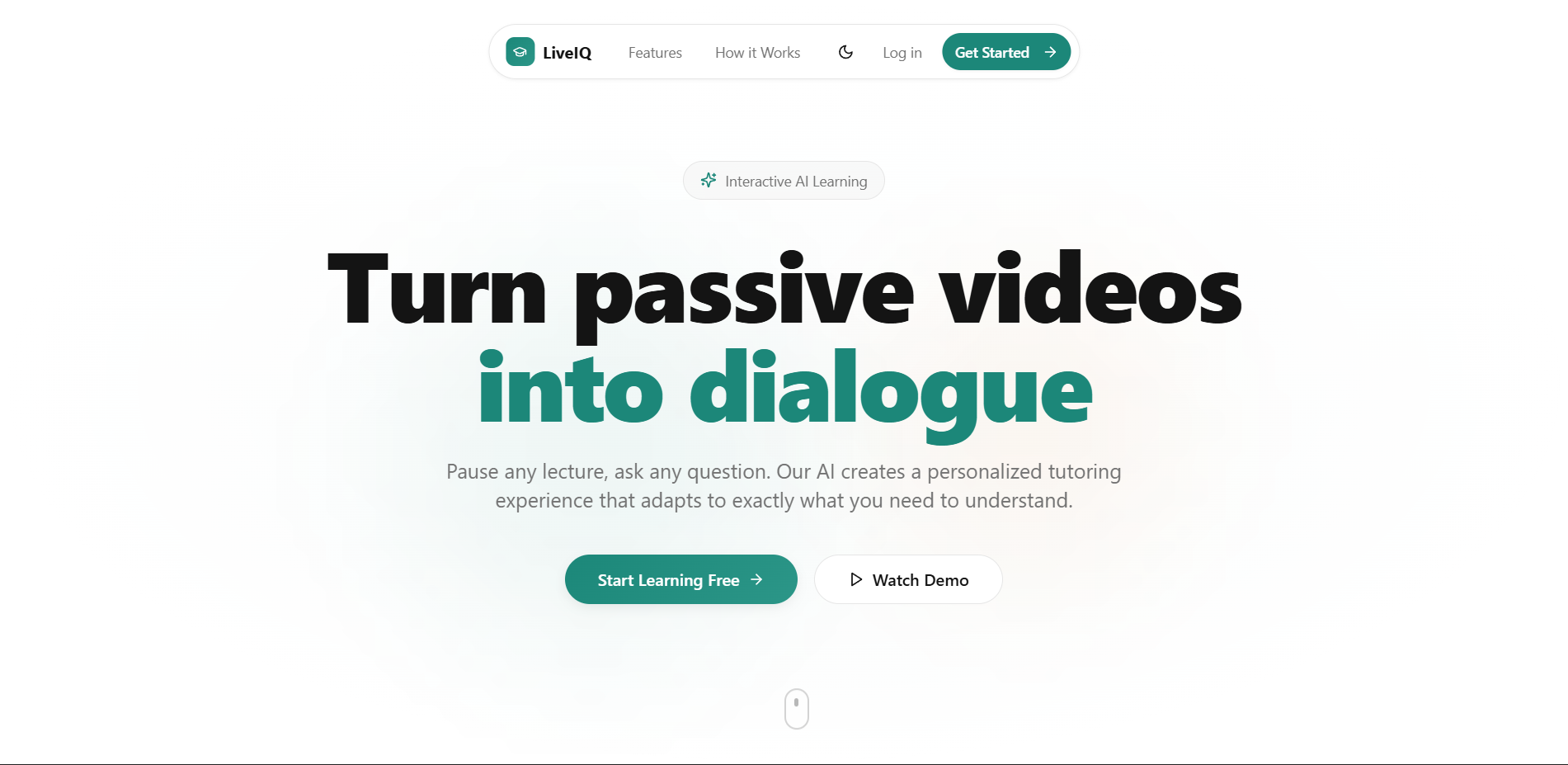
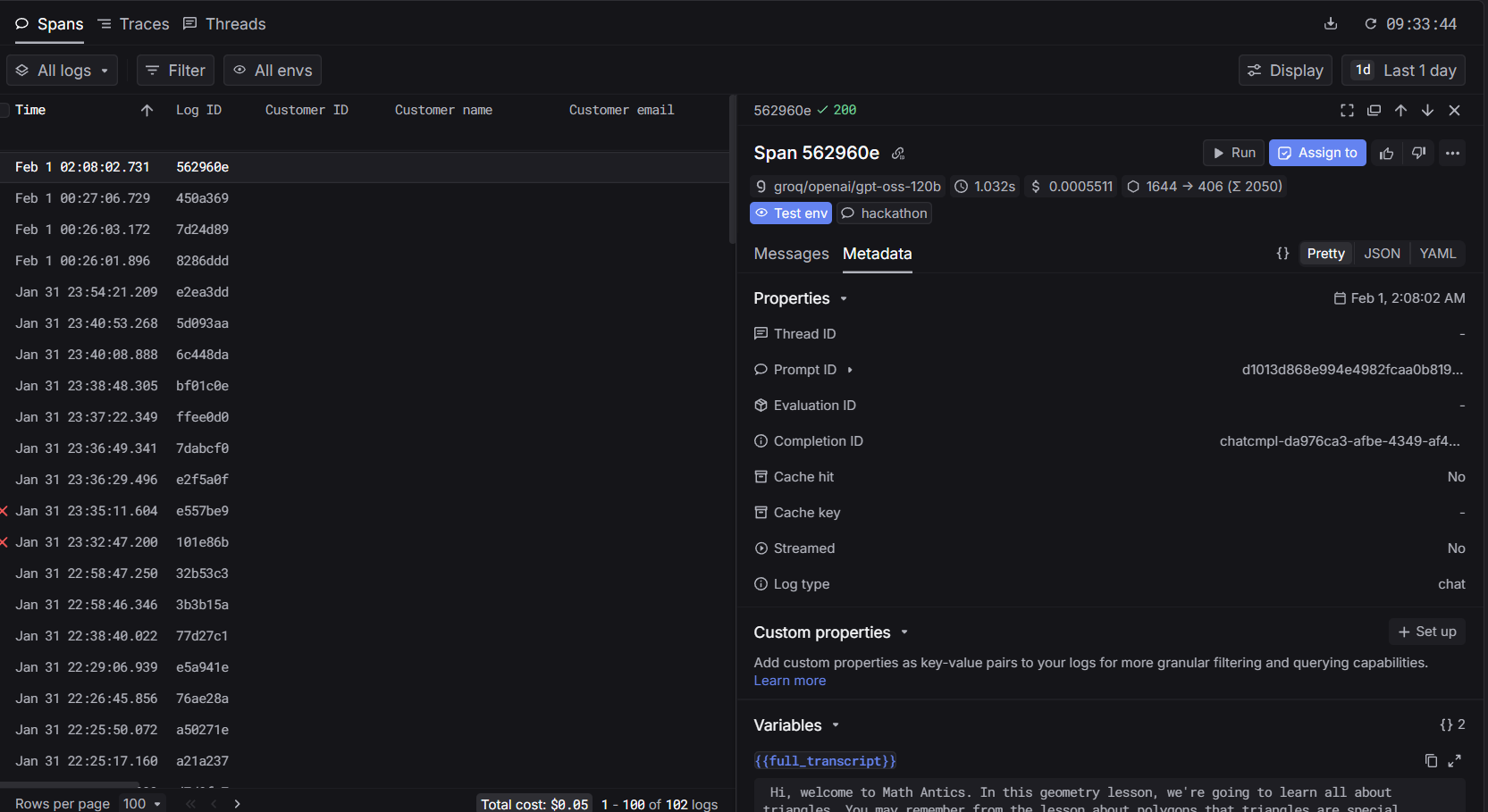
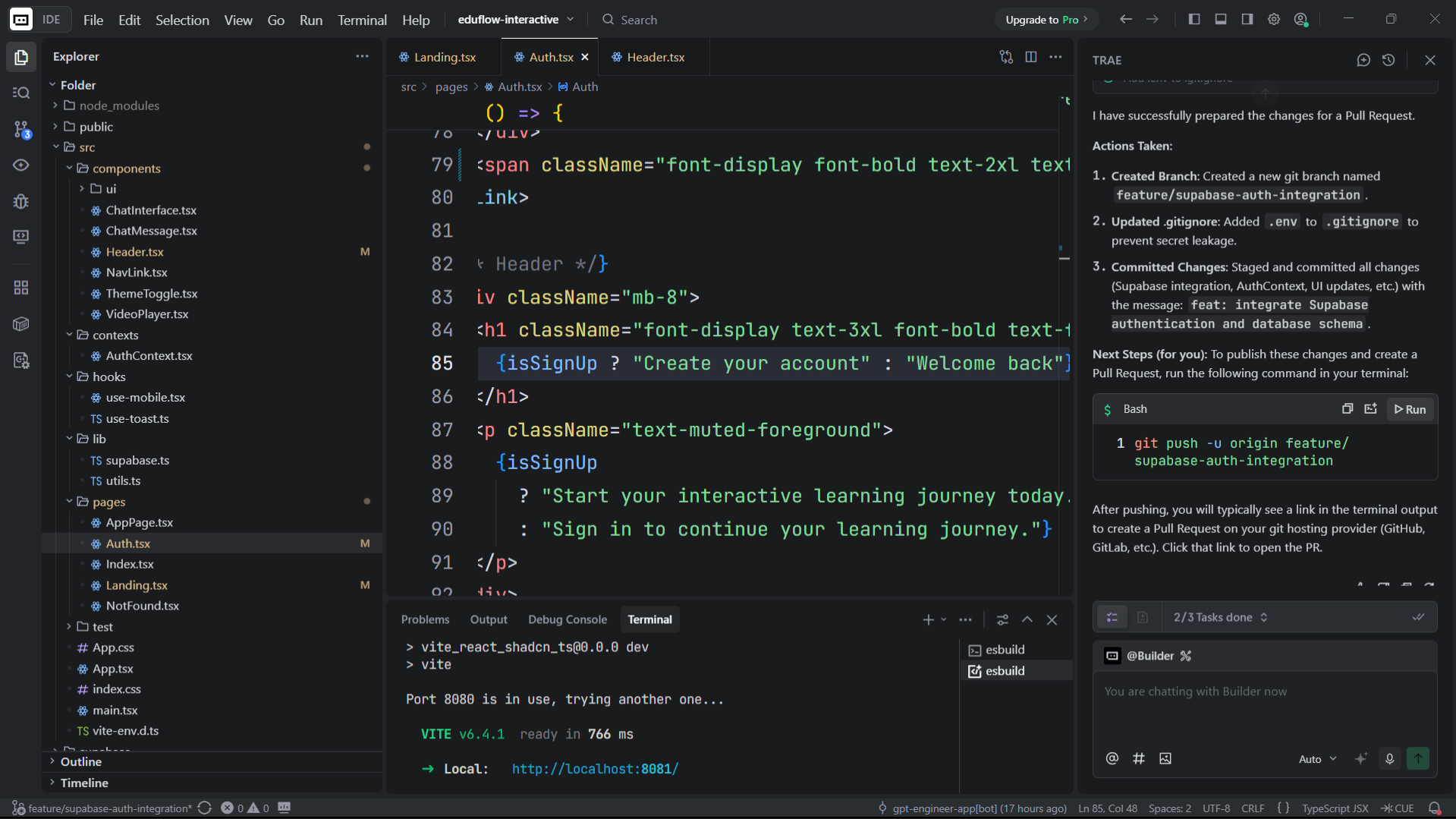
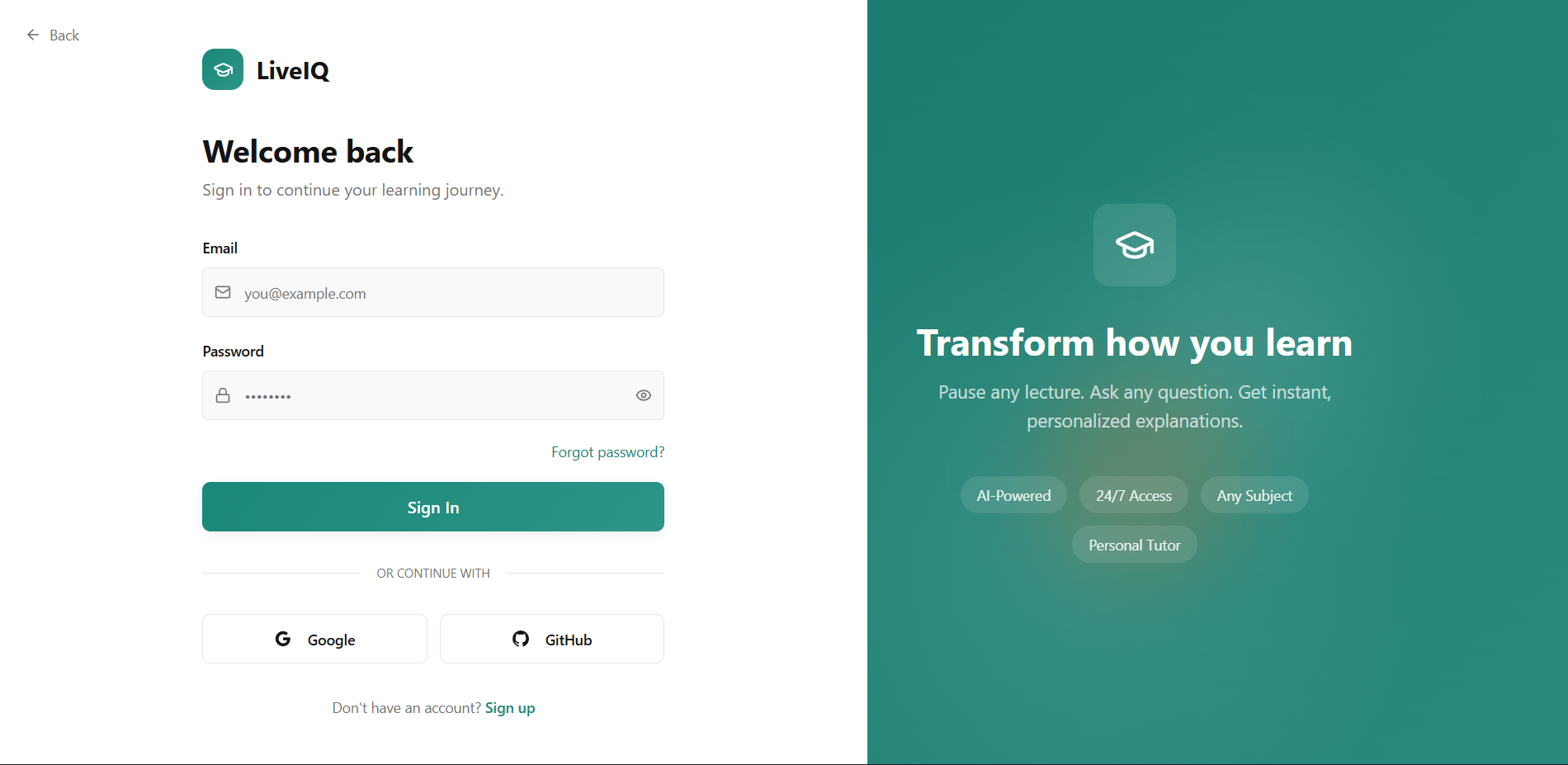
Inspiration: Watching recorded lectures has always felt like a one-way street. You pause, rewind, and still walk away confused with no one to ask. We wanted to recreate the feeling of being in a live Google Meet call, where raising your hand and getting an answer is natural. LiveIQ bridges that gap by letting viewers ask questions during a video, and having the speaker respond seamlessly animated in real time. What it does: LiveIQ transforms pre-recorded lectures into interactive sessions. A viewer can type or speak a question at any point in the video. The system pauses playback, generates a natural-language answer, lip-syncs and animates the speaker's video using AI, and then resumes the original lecture, as if the speaker had just answered you live. How we built it: We combined several AI layers into one pipeline. Speech-to-text captures the viewer's question. A large language model generates a contextual answer based on the lecture's topic. A lip-sync and video generation model (Veo 3.1) animates the speaker's face and creates audio. Finally, a media player orchestrates the flow. Detecting questions, swapping in the AI-generated clip, and resuming the original video at the right timestamp. Challenges we ran into: The hardest part was making the transition between the original video and the AI-generated response feel seamless. Any visual jump or audio mismatch broke the illusion entirely. Latency was another wall generating a video clip in real time is computationally expensive, so we had to optimize aggressively and manage user expectations with a brief loading state. Keeping the AI's answer relevant and grounded to the lecture's actual content (rather than hallucinating) also required careful prompt engineering. Accomplishments that we're proud of: We built a working end-to-end pipeline from question input to animated speaker response within a single cohesive application. The core USP works: it genuinely feels like the lecturer is talking back to you. Stitching together speech recognition, LLM reasoning, audio synthesis, and video animation into one smooth experience was very challenging. What we learned: We learned that the user experience around AI-generated media matters just as much as the model quality. Smooth transitions, natural pacing, and contextual accuracy are what make or break the illusion. We also gained deep hands-on experience with the current state of lip-sync and talking-head generation, and where the real bottlenecks still live. What's next for LiveIQ: Next, we want to support real-time or near-real-time responses to eliminate the loading gap entirely. We're also exploring multi-turn conversations so a viewer can ask a follow-up without restarting. Long-term, LiveIQ could work with live streams, not just recordings, turning any lecture into a truly interactive classroom.
Built With
- google-cloud
- groq
- openai
- postgresql
- python
- react
- supabase
- tailwind-css
- trae
- typescript
- veo-video-converter


Log in or sign up for Devpost to join the conversation.