-
-
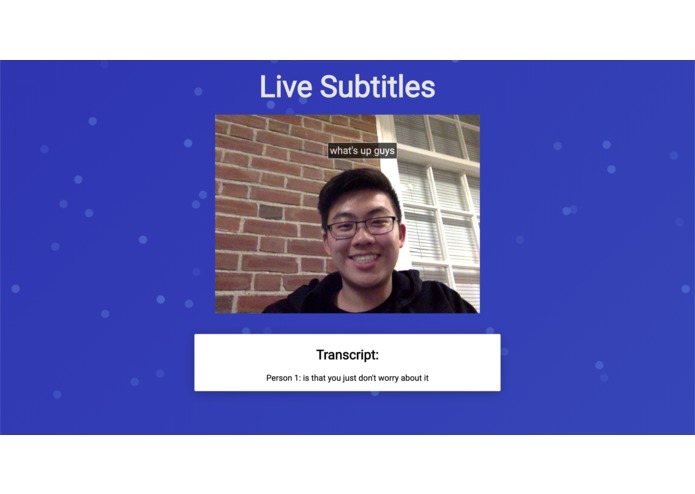
Single Person
-

Model Wireframes
-
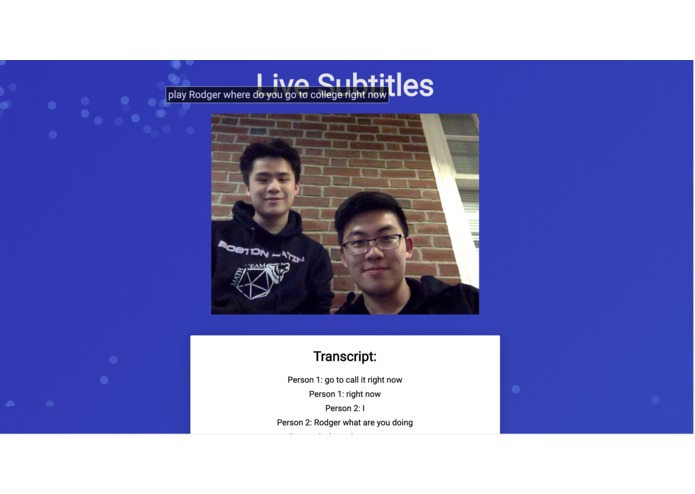
Multiple People
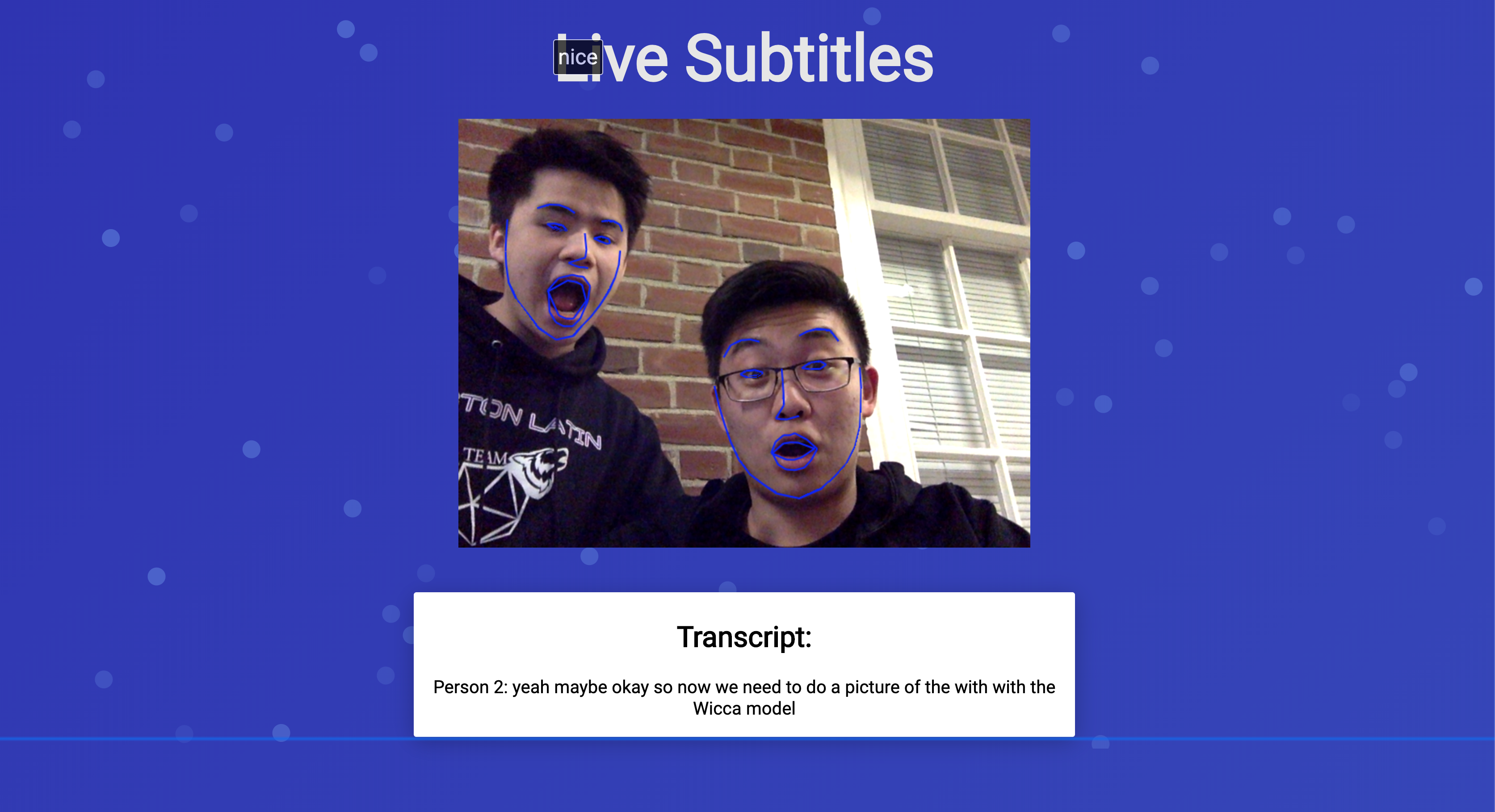
Inspiration
What it does
Our original vision was a VR mobile application
How we built it
Javascript and html was used to crate a browser based application. The face-api api was used to locate faces and facial landmarks and web audio api to text to create the project.
Challenges we ran into
The largest problem our team faced regarded the location of faces within the webcam frame. We originally began with a Computer Vision solution that was originally purposed for gesture recognition. We used a mask and binary subtraction to isolate things in the frame that were of human skin tone, and then subtracting the background of noise. Then we would look for the two largest pieces found and assumed that they were the heads of the two members. This became extremely challenging as many objects in the background had color similar to that of skin, and bad lighting affected the vision of the camera. This forced us to search for a more consistent way to find the location of faces, and we eventually stumbled upon a machine learning solution that we currently have implemented.
Accomplishments that we're proud of
We're proud that we got all the parts to work and interact with each other, and we are extremely proud of using creative methods to solve the problems we faced. We used the mouth distance during speech to determined who was talking which we got from our trained model.
What's next for Live Subtitles
While this is a good preliminary design for a project done in 24 hours, there is a lot that can be done to make this project more applicable. For example, if this were to be ported to android studio in order to use it on phones to use as an AR software rather than a web application, this can make it so that deaf people can wear an AR core or google glass and see what people are saying through the screen. On a more entertaining note, this can be used in AR or VR video games so players can see what other players are seeing in a chat bubble above players heads.
Built With
- css
- face-recognitions
- html5
- javascript
- machine-learning
- natural-language-processing
- react
- tensorflow
- tensorflowmodel




Log in or sign up for Devpost to join the conversation.