-
-
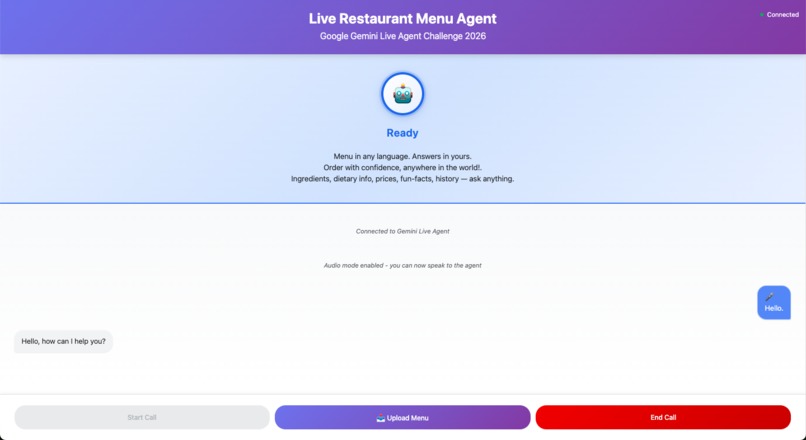
Agent - Web UI
-
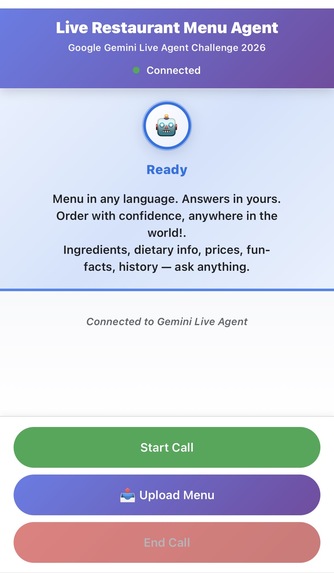
Agent - Mobile UI
-
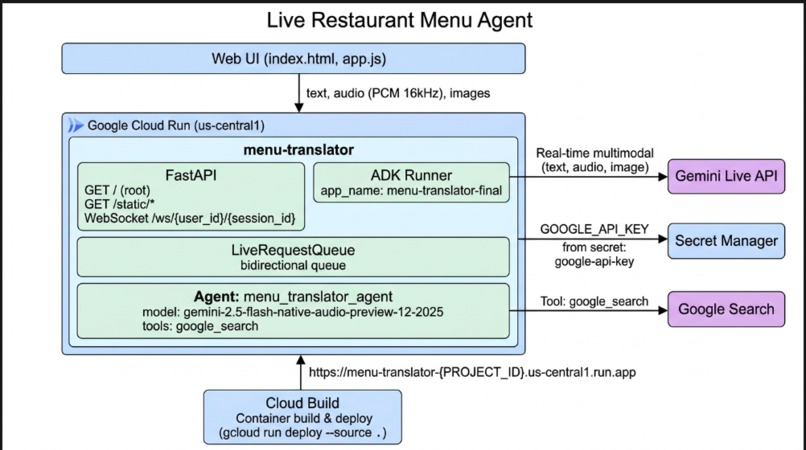
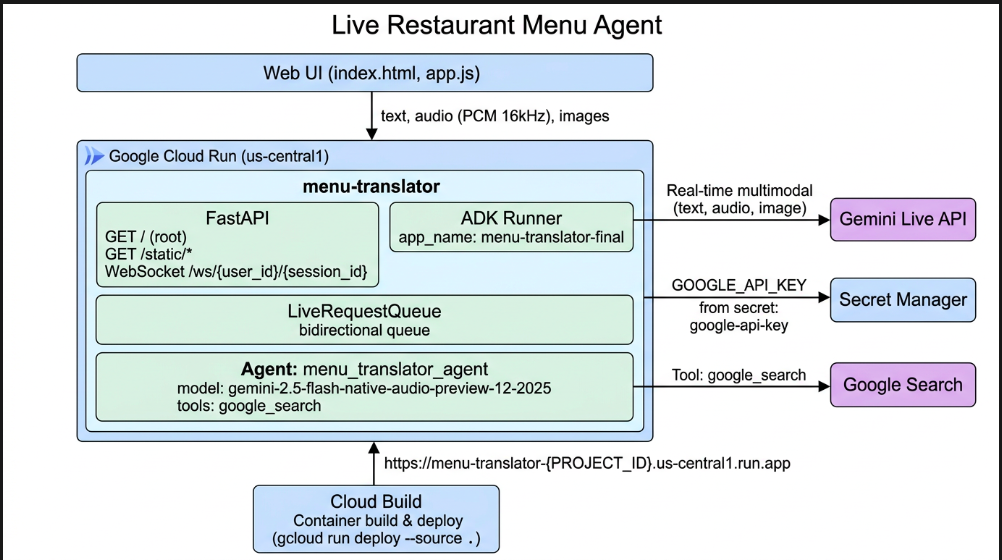
Architecture Diagram
Inspiration
For the last decade, I shipped almost a dozen AI and GenAI use cases to production, one of which was audio translation. The pipeline was battle-tested: Speech-to-Text → LLM → Text-to-Speech. Reliable. Predictable. But limited to batch processing because it could not support real-time conversation.
When I saw the Gemini Live Agent Challenge, I wanted to test a hypothesis: Does real-time, interruptible voice fundamentally change how we design conversational AI?
Picture this: You're sitting at a restaurant in Barcelona. The menu is entirely in Catalan. You're vegetarian, you have a shellfish allergy, and you're pretty sure that word on line three isn't "mushroom." You could guess. Or you could point your phone at the menu and ask an AI agent capable of real-time conversation—in your language, with the ability to interrupt when it gets something wrong.
What it does
Live Restaurant Menu Agent removes language friction at the moment of need:
- Point your phone at a menu in any language (image recognition + OCR)
- Ask your menu question in your native language (auto-detected multilingual)
- Get instant spoken answers about ingredients, allergens, cultural context
- Interrupt mid-sentence—barge-in protocol ensures natural conversation
- See live transcription so you verify what the agent heard
The Architecture Behind It: I evaluated three approaches:
- Traditional (Whisper → Gemini → TTS): 1.5-2.5s latency, no interruption protocol
- Native Audio alone: 600-800ms latency, but no barge-in capability
- Native Audio + Live API Protocol (chosen): <500ms latency + true barge-in support
The insight: Gemini Native Audio delivers speed. Gemini Live API's bidirectional streaming + Voice Activity Detection addresses interruption. Together: real conversation.
How we built it
Backend: FastAPI WebSocket server on Google Cloud Run handling bidirectional streams (BIDI) to Gemini Live API Agent Logic: ADK Runner with Gemini Native Audio model (gemini-2.5-flash-native-audio-preview) + Google Search tool for ingredient/allergen grounding Frontend: Web UI with live transcription, presence states (Ready/Listening/Speaking), menu photo upload, real-time chat display Deployment: One-command Google Cloud Build pipeline with Secret Manager for secure credential handling
Challenges we ran into
Challenge #1: Barge-in Protocol Support I started testing with native audio models outside the Live API. The agent would talk, I'd try to interrupt—and nothing happened. I tried tweaking prompts, adjusting client-side logic, even cutting audio chunks manually. Barge-in simply didn't work. For a conversational menu assistant, that's a dealbreaker—users need to correct themselves without waiting for the agent to finish. Solution: Switched to Gemini Live API which provides native barge-in protocol via Voice Activity Detection and bidirectional streaming. The realization: barge-in isn't a feature you add. It's a protocol the API must support.
Challenge #2: Environment-Specific VAD Sensitivity I tested perfect barge-in in quiet rooms. When testing with real users in coffee shops: agent interrupting itself from echo. High sensitivity created false positives; low sensitivity felt laggy. Solution: Implemented environment-aware tuning (start_of_speech_sensitivity + end_of_speech_sensitivity + prefix_padding_ms + silence_duration_ms). Real-world testing reveals constraints labs hide.
Challenge #3: Use Case Scope Creep Started with "build a conversational AI agent"—scope exploded immediately (12 feature ideas: proactive recommendations, memory, fine-tuning, RAG, affective dialog, etc.). Narrowed ruthlessly: "Multilingual restaurant menu with real-time voice and barge-in." That single definition unlocked all downstream decisions (model selection, infrastructure, UI design, feature prioritization).
Accomplishments that we're proud of
As a product manager, I shipped a production-ready AI agent in two weeks—from concept to deployed live product. That's remarkable. More importantly, Google's stack made it possible.
Concept to Deployment in 14 Days: Built, tested, refined, and deployed to production—not a prototype or demo, but a live agent handling real requests on Cloud Run with secure credential management, zero-downtime deployment pipeline, and observability metrics. The speed was possible because I didn't have to build infrastructure from scratch. ADK handled agent orchestration. Live API handled real-time streaming. Cloud Run handled scaling.
Real-Time Voice AI is Now Accessible: Proved that conversational AI isn't reserved for massive enterprises. One person. Two weeks. The barrier to entry for voice agents just dropped significantly.
Google Solutions Made This Frictionless Gemini Live API: Native barge-in support. No custom protocol building. ADK:Agent orchestration abstraction. Focus on product, not plumbing. Cloud Run: Deploy with one command. Auto-scaling. Security built in. Cloud Build: Every git push triggers tests and deployment. Iteration speed is a competitive advantage.
What we learned
Learning #1: Real-time, interruptible voice is a new category, not a feature. I tested with real users and watched them interrupt mid-sentence when the agent misunderstood dietary restrictions. They didn't marvel at the technology—they expected it to work. This interaction pattern is how people want to collaborate with AI today.
Learning #2: Real-world testing reveals the 1% that matters. Lab tests showed 99% accuracy. Real users in coffee shops revealed critical constraints: latency spiked to on WiFi, iPhone speakers caused false interrupts, language detection confused Mandarin with Japanese. A/B testing prompts, response lengths, and UI transcription placement drove continuous improvement. Continuous testing with actual users is non-negotiable.
Learning #3: Use case definition gates everything downstream. Narrowing to "multilingual restaurant menu with real-time voice and barge-in" unlocked model selection (native audio), infrastructure choice (Live API), UI design (presence states, transcription), and feature prioritization. Definition → feasibility → design is the disciplined order.
Learning #4: Coherence beats feature abundance. Shipped five polished features (real-time voice, barge-in, menu vision, multilingual, live transcription) instead of partial versions of twelve. Users perceived the complete system as "production-ready future tech." A complete solution to a narrow problem outperforms a partial solution to a broad problem. Prioritize alignment, not abundance.
Learning #5: DevOps and observability drive iteration speed. One-command deployment changed everything. Tracked barge-in success rates, latency percentiles, language detection accuracy per language pair. Quality metrics became the product roadmap. DevOps + observability aren't overhead—they're how you ship responsibly and iterate fast.
What's next for Live Restaurant Menu AI Agent
Phase 1: Mobile App & Feature Expansion Build out the mobile experience with offline menu caching, saved preferences, dietary profile management. Pilot with restaurant partners in Barcelona, Madrid, and Tokyo. Gather user feedback and refine the core experience based on real usage patterns.
Phase 2: Expand to Other Industries Real-time, interruptible voice agents solve problems beyond restaurants. Hotels (room service menus, local recommendations), healthcare (medication verification, allergy checking), customer support (instant troubleshooting), accessibility (vision-impaired navigation). The underlying architecture applies across industries.
The market opportunity is massive because the user experience finally feels natural. Users don't think about the technology. They just have a conversation. That's the shift.
Built With
- adk
- cloud-build-frontend:-web-audio-api-(audioworklet)
- cloudbuild
- cloudrun
- docker
- fastapi
- gcloud
- gemini-2.5-flash-native-audio-preview-12-2025
- gemini-2.5-flash-native-audio-preview-12-2025-apis:-gemini-live-api
- gemini-live-api
- genaisdk
- google-genai-sdk-cloud:-google-cloud-run
- javascript
- javascript-frameworks:-fastapi
- python-3.12
- secret-manager
- uv
- vanilla-javascript-ai-/-agent:-google-agent-development-kit-(adk)
- webaudioapi
- websocket
- websocket-tools:-google-search-(adk)-package-manager:-uv-deployment:-docker

Log in or sign up for Devpost to join the conversation.