-
-
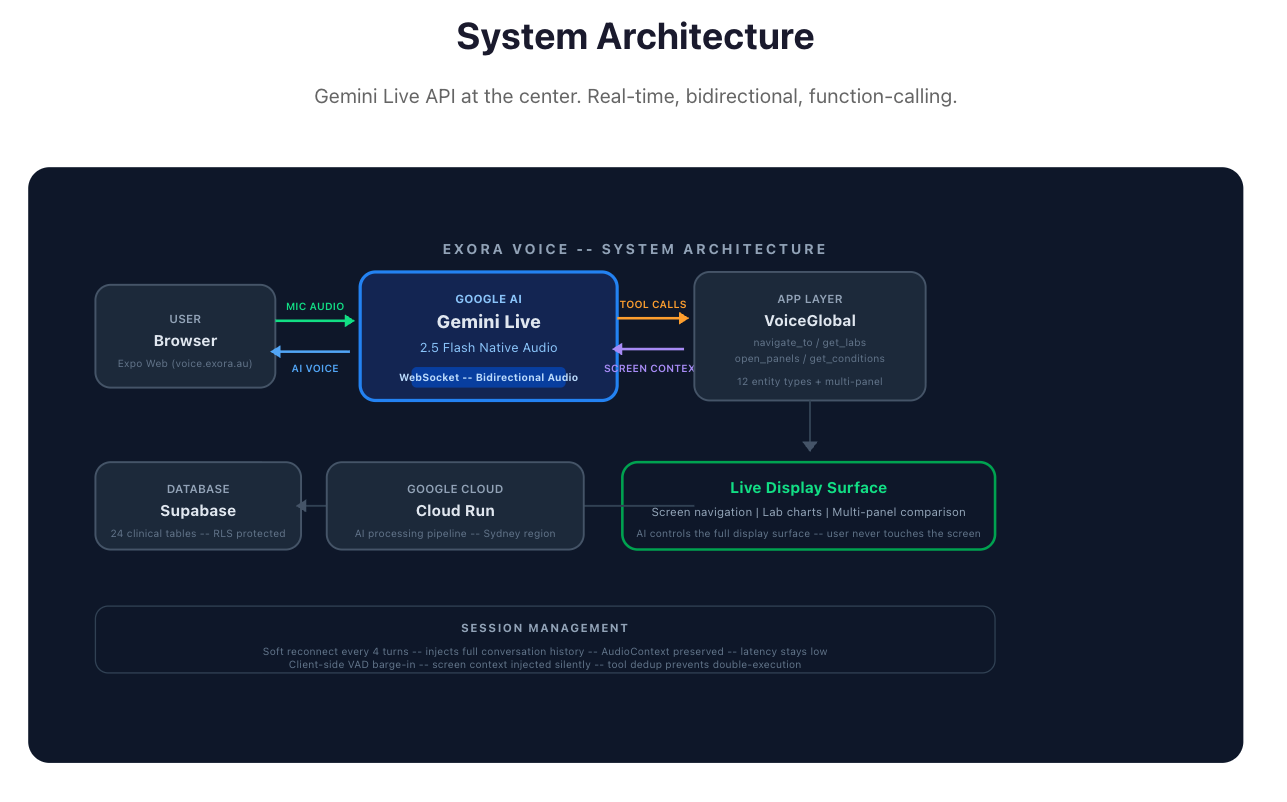
Architecture diagram
-
Landing page
-
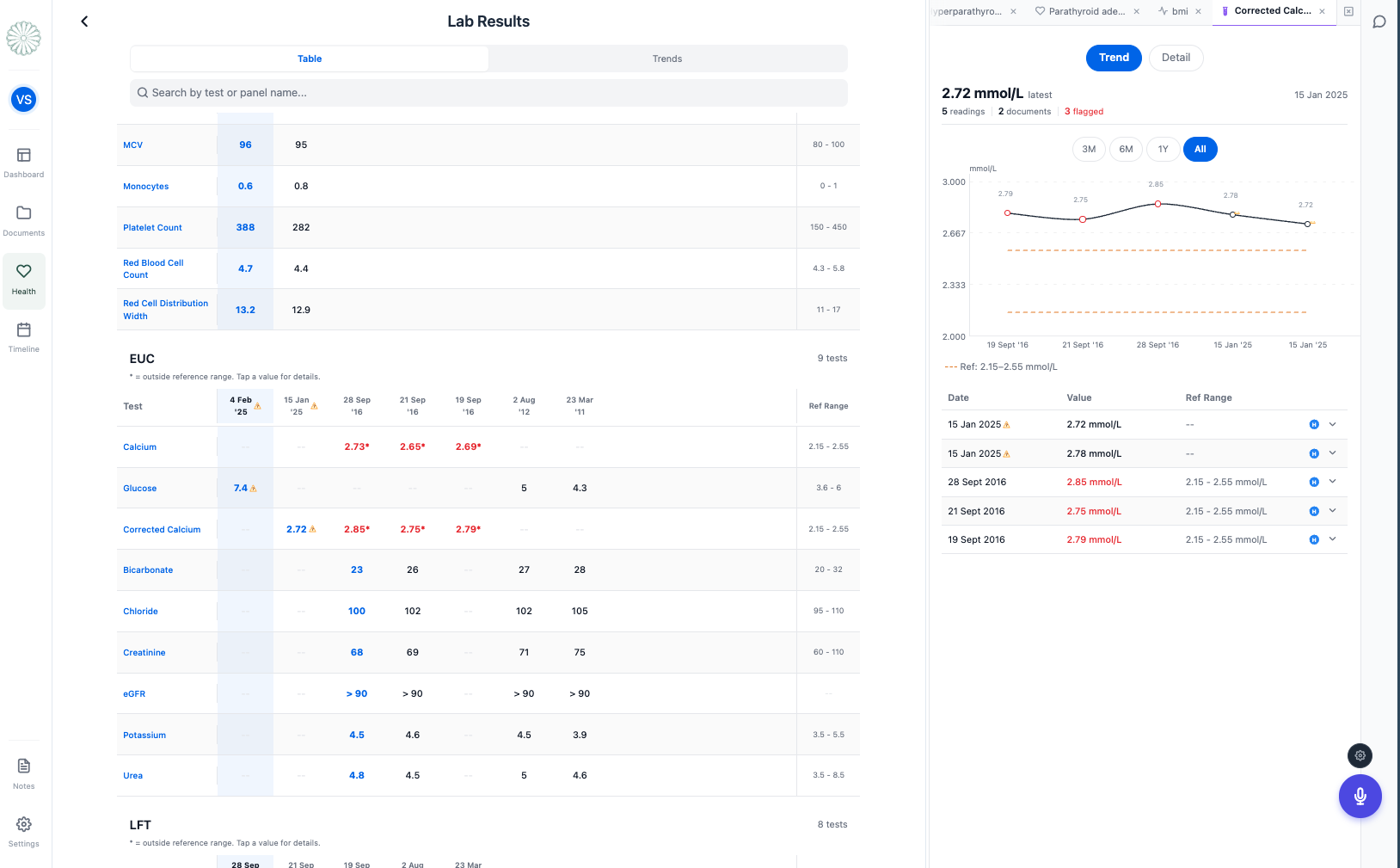
Lab results page
-
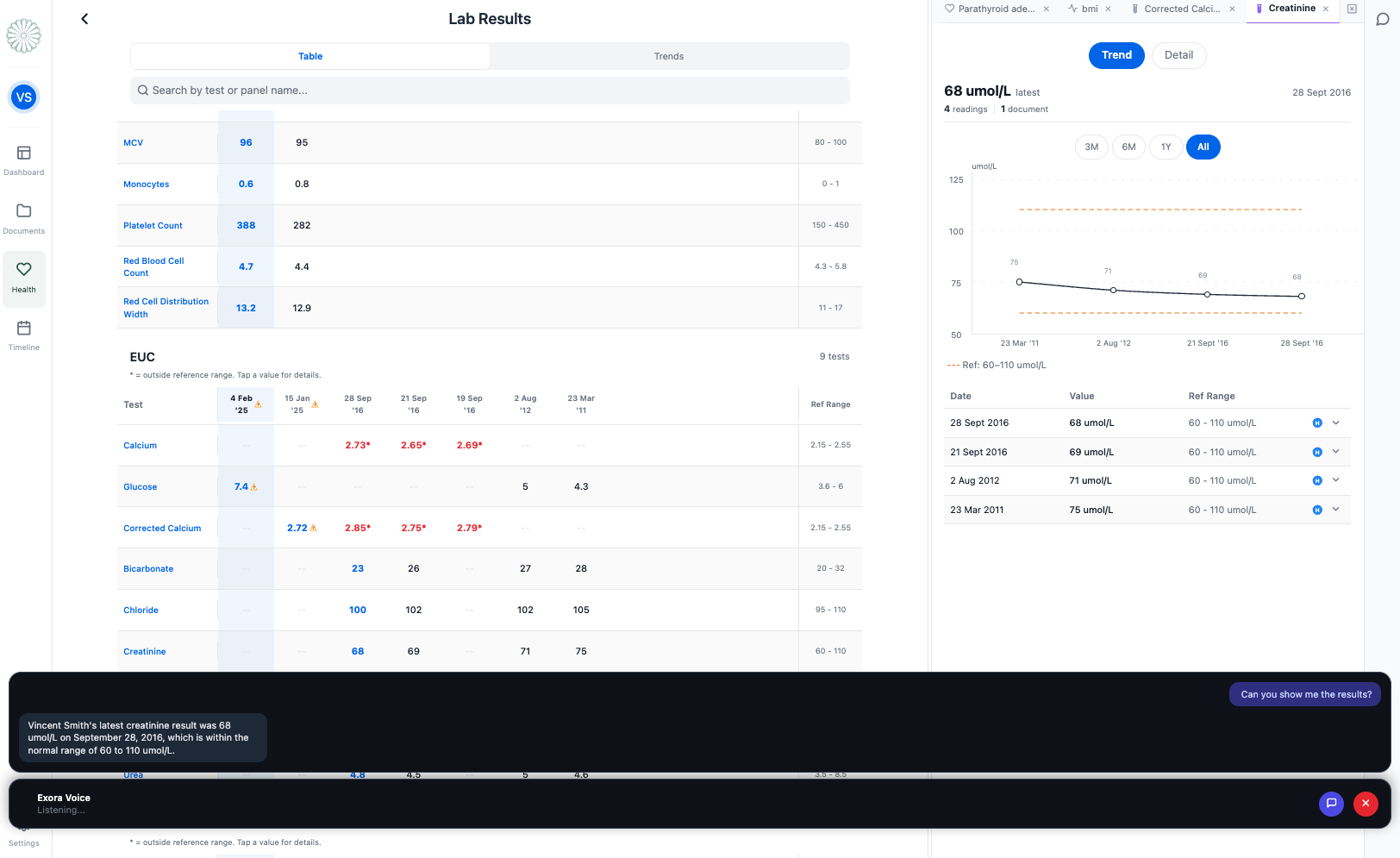
Lab results page with live chat session
Inspiration
Most people cannot read their own medical records. The data exists - labs, medications, conditions, vitals, imaging - but it is dense, clinical, and disconnected from plain language. Existing health AI tools answer questions from text, but they cannot show you anything. You still have to navigate the app yourself, find the right screen, open the right panel, and interpret a chart you may not understand.
We wanted to build something different: an AI that does not just talk about your records, but actively controls the display surface to put the right data in front of you in real time.
What it does
Exora Voice is a screen-aware health AI companion. You speak to it naturally:
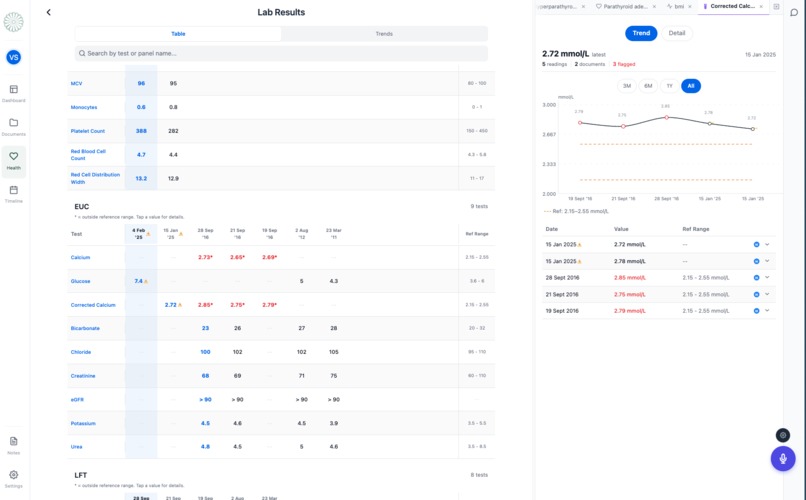
- "What are my recent cholesterol levels like?" - the AI pulls your lab history and answers in plain language
- "Show me it on a graph" - the LDL detail panel opens with your trend chart
- "What conditions do I have that may be causing those results?" - the app navigates to conditions, AI explains the relevant ones
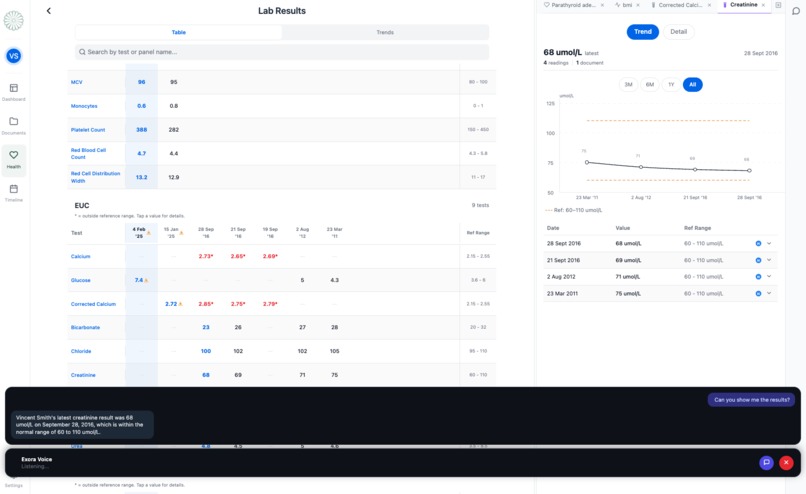
- "Am I taking any medications for that condition?" - it checks your medications and answers directly
- "Bring up my medications and tell me when I started the cholesterol drug" - the medications screen opens, AI finds the entry and gives you the start date
Each follow-up builds on what is already on screen. You can interrupt the AI mid-sentence at any point and it stops immediately. You never touch the screen.
How we built it
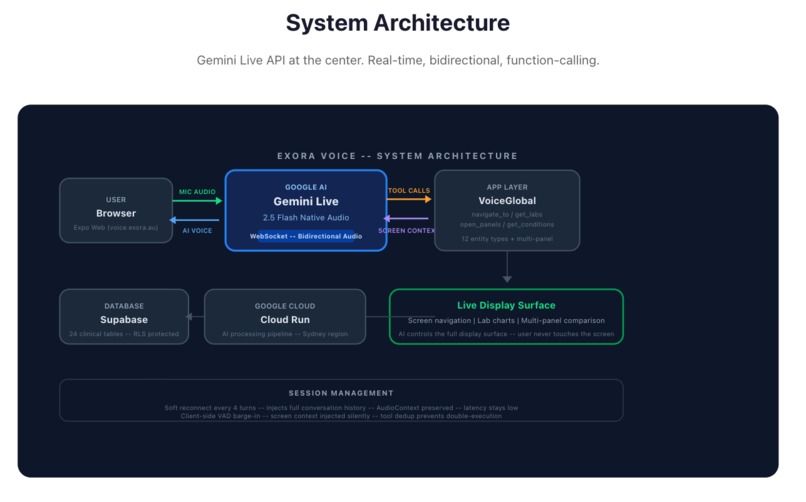
Voice layer: Gemini Live API with native audio streaming. The model receives and emits raw audio directly - no STT/TTS round-trips, which keeps latency low and the conversation natural.
Screen context injection: Rather than screenshotting pixels and asking the model to parse the UI, we query the database directly and inject structured JSON into the system prompt - lab values, reference ranges, dates, units, status flags. The AI always has precise, structured clinical data. No hallucination risk on the numbers.
Function calling for display control: The AI drives the app via silent tool calls - navigate_to, open_panels, show_list. It acts on the display without announcing what it is doing. When you ask to compare two lab results, both detail tabs open simultaneously without any narration.
Multi-panel comparison: A custom open_panels tool opens 2-3 entity detail panels simultaneously. Tabs are additive - new panels append to the right, with a blue dot indicator on unviewed AI-injected tabs.
Barge-in: A client-side voice activity detector stops audio playback the moment speech is detected, with no server round-trip. The AI stops mid-sentence.
Soft reconnect: Rather than a single long-lived WebSocket session (which accumulates latency and context bloat), the session reconnects silently every 4 turns with conversation history preserved in the new system prompt.
Backend: Google Cloud Run in Sydney (australia-southeast1) for data sovereignty. Supabase PostgreSQL for patient health data with row-level security.
Challenges we faced
Context window management: Injecting full health records into every system prompt hits token limits fast. We solved this by injecting only the current screen's data plus summary counts for other sections, expanding to full detail only for the active entity.
Barge-in latency: True barge-in requires stopping audio before the server responds. We implemented client-side VAD that immediately mutes playback on speech detection, giving the perception of instant interruption even when the server is mid-stream.
SPA routing on Vercel: Expo web exports static HTML per route. Getting the SPA fallback to work correctly with a custom landing page at the root required explicit routing rules in the Vercel Build Output API config.
"New Projects Only" rule: Exora the platform predates this contest. Exora Voice - the voice AI companion - was built entirely within the contest window. The public repo git history reflects this cleanly.
What we learned
Structured data injection beats vision for clinical accuracy. Screenshotting a lab result and asking the model to read it introduces error. Querying the database and formatting the result as JSON gives you precision - exact values, exact units, exact reference ranges - with a fraction of the token cost.
Native audio models change the interaction model entirely. With Gemini 2.5 Flash Native Audio, the conversation feels like talking to a person who can also control a computer, not like issuing commands to a voice assistant.
Built With
- expo.io
- gemini
- react-native
- supabase
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.