-
-
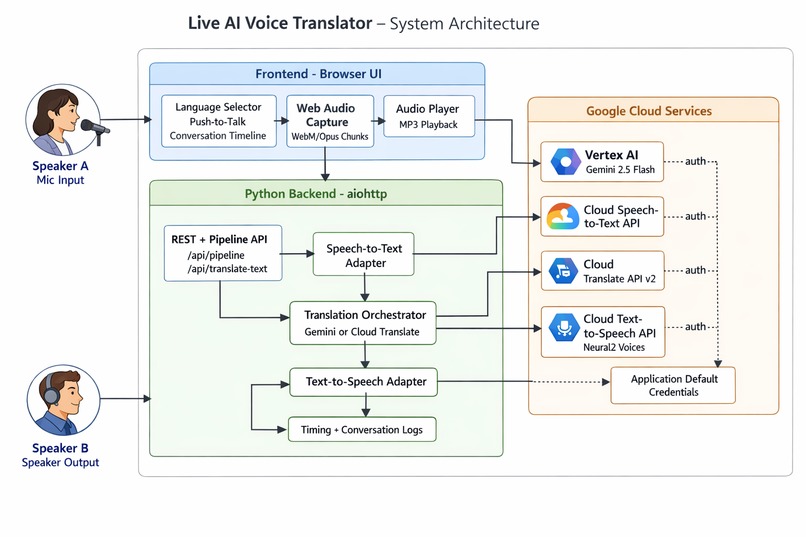
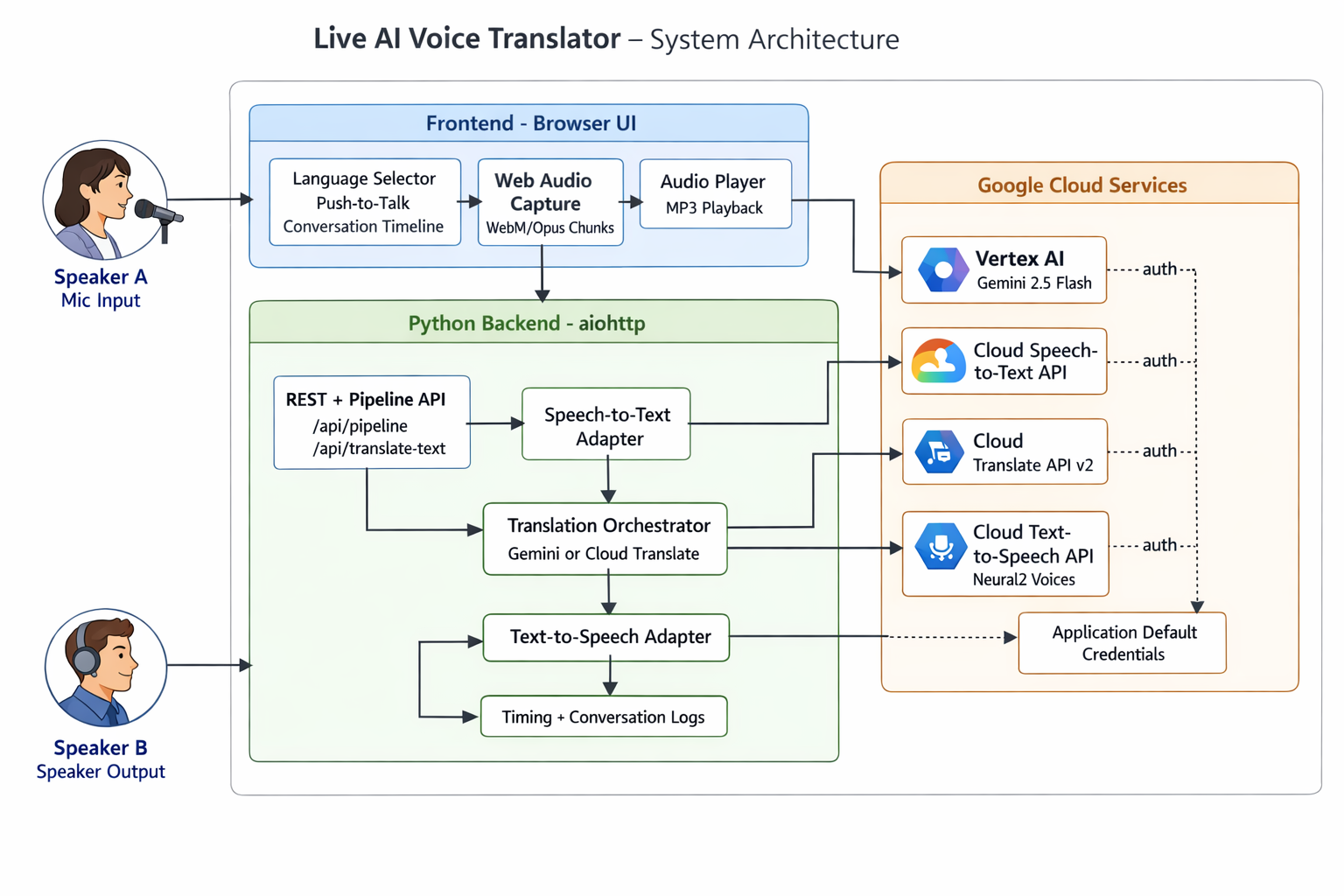
architecture
-
build logs proof of deployment
Inspiration
The inspiration for this project came directly from a real problem I experienced at work. I often get the opportunity to meet clients from different parts of the world, and while those conversations are exciting, language can become a real barrier. There were moments where I could understand the intent of the conversation, but not the words clearly enough to respond with confidence in real time. That gap made me think: communication should not break down just because two people speak different languages.
From there, I started exploring the idea of a live voice agent that could listen, understand, translate, and speak back naturally, almost like an invisible conversation bridge. I did not want to build just another translator that works after the fact. I wanted something that feels seamless during a live interaction, especially for business conversations where timing, tone, and clarity matter. Over time, that idea became broader: not only helping people speak across languages, but also moving toward a future where this could be integrated into platforms like Microsoft Teams and eventually act as an intelligent assistant that supervises audio conversations, helps with understanding, and even supports language learning.
What it does
Live-AI-Voice-Translator is a real-time multilingual conversation assistant that helps two people who speak different languages communicate more naturally.
The final prototype can:
- Capture spoken input from one speaker
- Convert speech to text using Google Cloud Speech-to-Text
- Translate the content using Gemini and Google Cloud translation services
- Convert the translated result back into natural speech using Google Cloud Text-to-Speech
- Support bidirectional conversations, where both sides can speak and hear translated responses
- Show conversation history and timing information for the translation pipeline
- Offer a text-based mode for testing when voice input is not available
What makes it meaningful to me is that it is not just translating words. It is trying to reduce friction in human conversations. The long-term vision is to evolve this into a meeting-friendly assistant that can plug into collaboration tools, support global teams, and eventually supervise audio interactions to help users follow multilingual discussions more confidently.
How we built it
I built this project in stages, and each version helped me move from a basic proof of concept to a more structured live agent experience.
Version 1
The first version was focused on proving that the concept works end to end. I used a Streamlit-based interface with a Python backend, Gemini for translation logic, and Google Cloud Text-to-Speech and Translation services. This version helped validate the core idea: take user input, translate it, generate speech, and present the result quickly.
At this stage, the emphasis was on functional experimentation:
- getting multilingual translation working
- testing voice and text input paths
- verifying that Gemini could improve translation quality compared to a simple direct API-only flow
- building confidence that the project was worth pushing further
Version 2
In the second version, I shifted the architecture toward real-time communication. Instead of staying in a more static prototype model, I moved to a browser-based audio flow with WebSocket communication and Gemini Live API concepts. This version was much closer to the kind of experience I originally imagined: something interactive, low-latency, and usable in live conversations.
This stage introduced more serious engineering problems:
- streaming audio from browser to backend
- handling low-latency communication
- converting audio formats correctly
- managing real-time responses cleanly in the UI
- balancing live AI interaction with stability
Version 2 was where the project started to feel less like a demo and more like a real product direction.
Final Version
The final version became a more complete live voice translator built around a stronger pipeline and an agent-oriented design. I used Google ADK concepts for the agent layer, Gemini 2.5 Flash for translation intelligence, Google Cloud Speech-to-Text for transcription, Google Cloud Text-to-Speech for voice output, and a Python web server for orchestration.
In the final build, I focused on:
- a cleaner end-to-end voice pipeline: audio -> STT -> translation -> TTS -> playback
- support for multiple languages
- bidirectional conversation flow between Speaker A and Speaker B
- push-to-talk and silence-aware interaction design
- better error handling for short or invalid audio
- fallback translation options for reliability
- a more usable interface with conversation history and timing metrics
This final version is the closest representation of the original vision: a live AI voice translator that can assist real human conversations across language barriers.
Challenges
One of the biggest challenges was real-time audio itself. Voice projects sound simple in theory, but in practice they are very sensitive to audio encoding, chunk sizes, browser capture behavior, silence handling, and latency. A small issue in one part of the pipeline can break the full experience.
Another major challenge was moving from a basic prototype to a genuinely live interaction model. In early versions, it was easier to process text or pre-recorded input, but much harder to build a smooth real-time flow where audio is captured, interpreted, translated, and played back without feeling too delayed.
I also had to think carefully about reliability. Translation systems are not just about accuracy; they must also behave consistently. I needed to balance Gemini’s context-aware capabilities with cloud translation fallback mechanisms so the system stayed usable even when one approach was not ideal.
There was also a product-design challenge: how to make the interaction feel natural. A live voice tool should not feel like the user is fighting the interface. It should feel like the technology disappears into the conversation. That meant iterating on the flow, UI clarity, user prompts, and response timing.
Accomplishments
I am proud that this project evolved through multiple serious iterations instead of stopping at a one-screen prototype. Each version taught me something new, and the final result is a much stronger system because of that progression.
Some accomplishments I am especially proud of:
- turning a real workplace pain point into a usable AI product concept
- building a working end-to-end multilingual voice translation pipeline
- moving from a simple prototype to a more real-time live agent architecture
- integrating Gemini, speech recognition, translation, and speech synthesis into one experience
- creating a bidirectional conversation flow instead of a one-way translator
- designing the project with a clear future path toward collaboration tools and meeting assistance
I am also proud that this project is not only about technology. It is about inclusion, accessibility, and helping people feel more confident when speaking to someone from another language background.
What we learned
This project taught me that building AI products is not only about model capability. It is about orchestration. A strong user experience comes from connecting many pieces well: audio capture, speech recognition, prompt design, translation quality, voice output, latency management, and interface design.
I also learned the value of iterative development. Version 1 helped me validate the idea quickly. Version 2 helped me understand the complexity of live streaming and real-time systems. The final version helped me combine those lessons into something more stable and more intentional.
On the technical side, I learned a lot about:
- handling real-time audio pipelines
- managing browser-to-backend communication
- working with Gemini for context-aware translation
- using fallback systems to improve resilience
- designing AI interactions around human conversation patterns rather than just raw model output
On the product side, I learned that the strongest ideas often come from very personal problems. This project started from a simple frustration during international client conversations, but it grew into a broader vision for how AI can reduce communication barriers in global work environments.
What's next for Live-AI-Voice-Translator
The next step is to turn this from a strong prototype into a workplace-ready communication assistant.
My future roadmap includes:
- integrating the translator into Microsoft Teams or similar meeting platforms
- adding a supervisor mode that can monitor ongoing multilingual conversations and surface key points
- supporting meeting summaries, action items, and multilingual notes
- improving speaker tracking and contextual memory across longer conversations
- expanding language coverage and improving accent robustness
- adding a language-learning mode so users can not only understand others but also gradually learn from each conversation
- making the system more production-ready with better deployment, observability, and scalability
Ultimately, I want Live-AI-Voice-Translator to become more than a translator. I want it to become a real-time communication companion for global collaboration, helping people speak, understand, learn, and connect across languages with much less friction.
Built With
- aiohttp
- cloud
- css
- docker
- gemini-2.5-flash
- gemini-live-api
- google-adk
- google-cloud-speech-to-text
- google-cloud-text-to-speech
- google-cloud-translation-api
- html
- javascript
- python
- websockets


Log in or sign up for Devpost to join the conversation.