Inspiration
Literature and debate subreddits are uniquely demanding to moderate. Unlike image-heavy communities, they attract long-form posts where the problems aren't obvious at a glance — a post might look substantive but be a thinly-sourced factual claim, a sweeping generalisation, or the fifteenth "what should I read next?" thread that week. Moderators in these communities spend a lot of time making the same judgment calls repeatedly, often without tooling designed for text-heavy content.
We wanted to build something that could do the first pass for them — not removing anything automatically, but surfacing why a post might deserve a second look, in plain language a mod could act on in seconds.
What it does
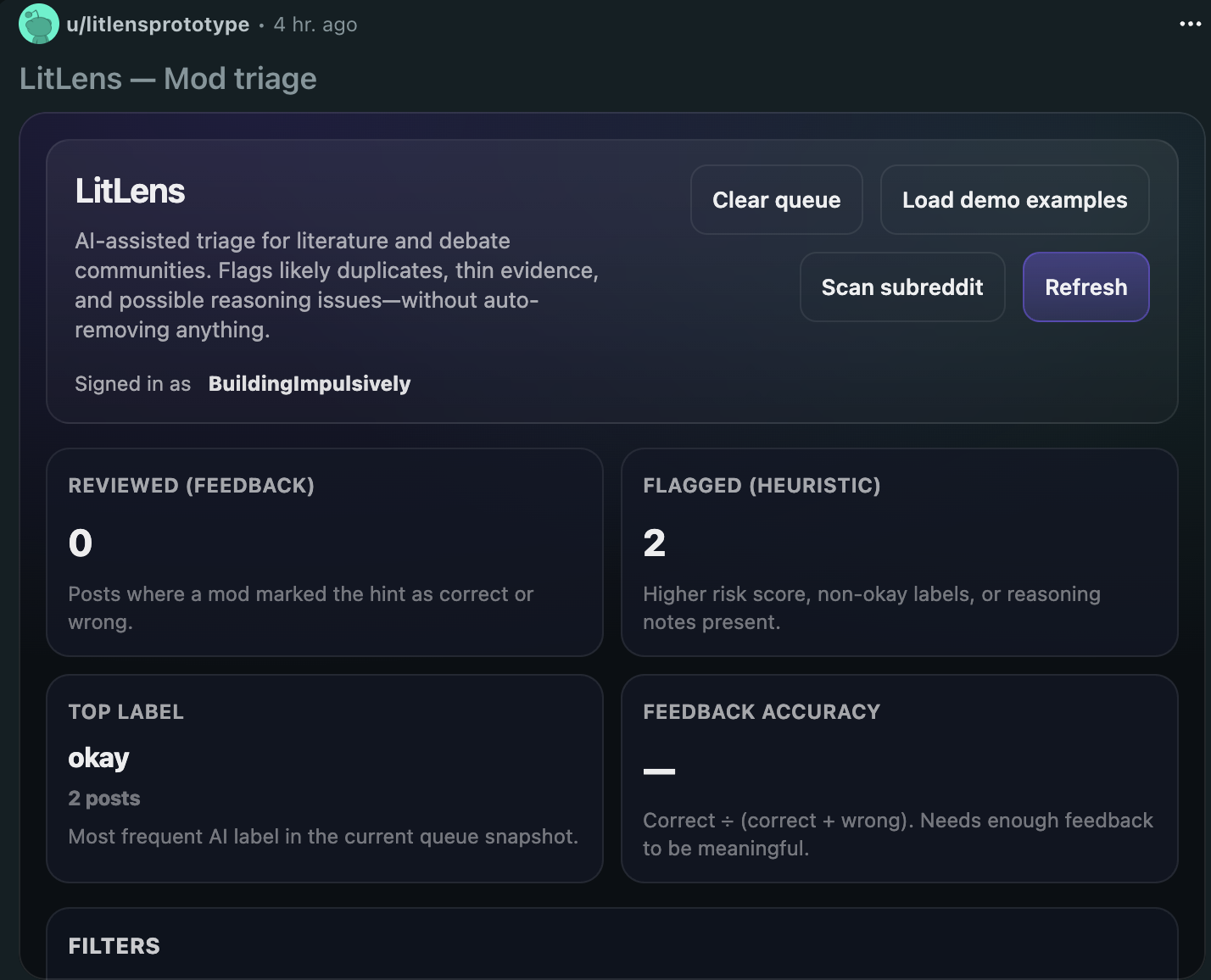
LitLens is an AI-assisted moderation triage dashboard built directly into Reddit as a Devvit app. When posts come into a subreddit, LitLens classifies them and queues them for review with:
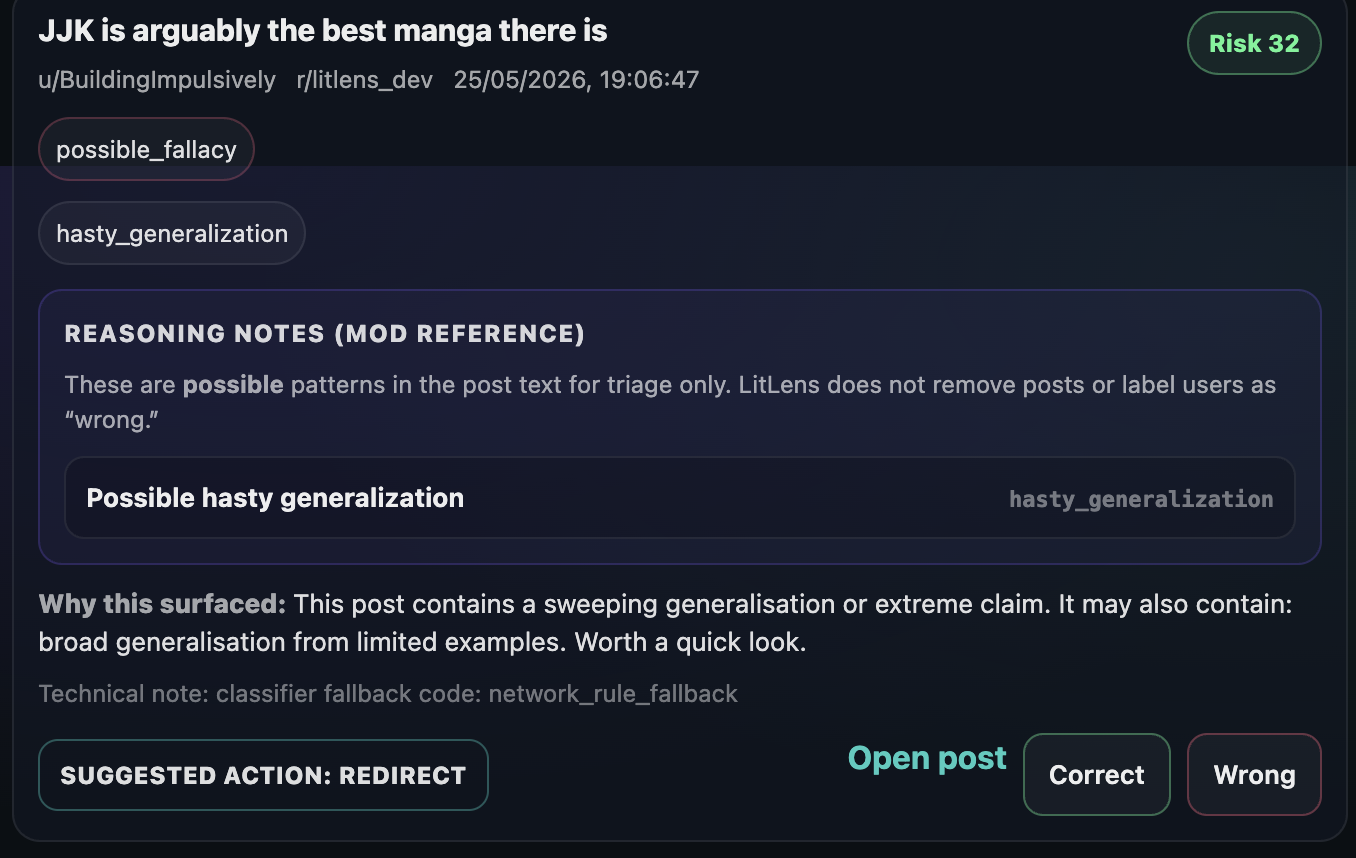
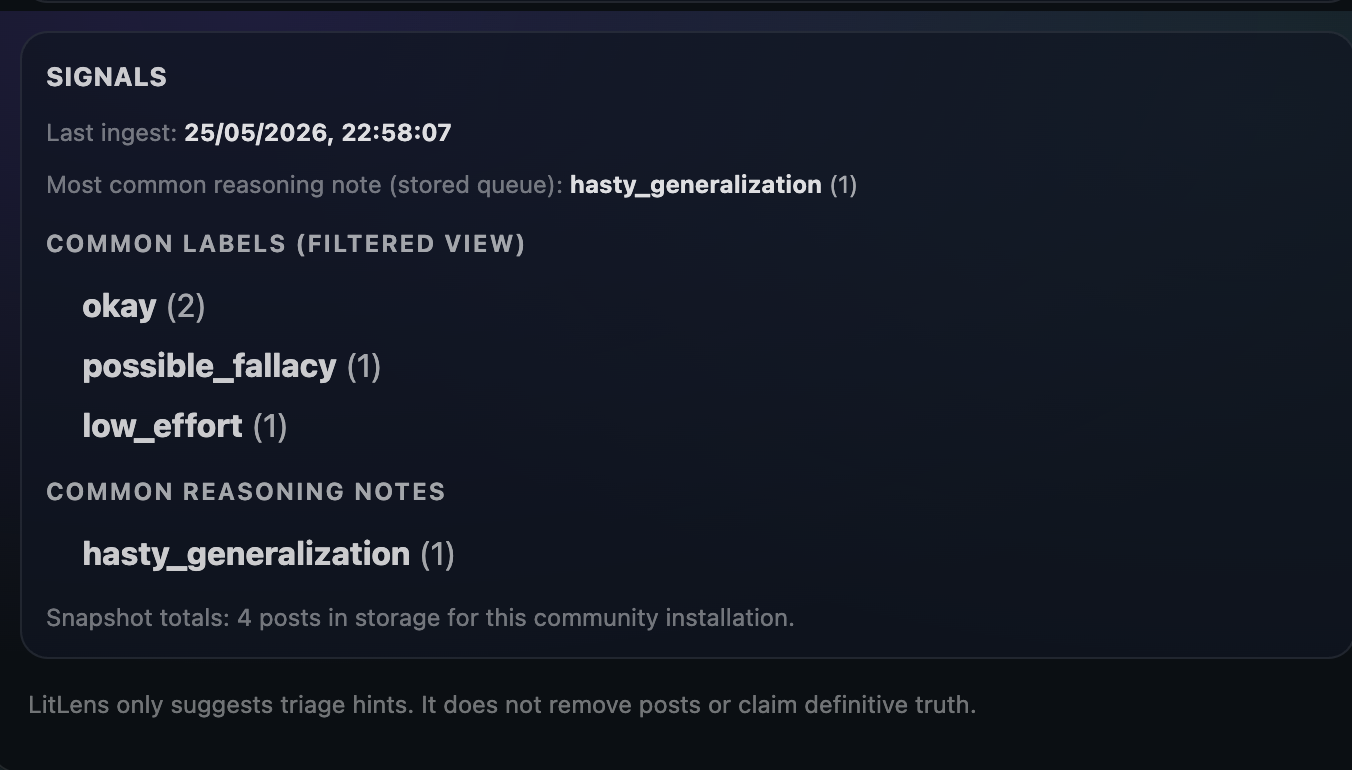
Labels — duplicate, low_effort, needs_evidence, possible_fallacy, rule_clarification_needed, meta_discussion, or okay Reasoning issues — specific logical problems detected in the text: strawman, hasty_generalization, unsupported_claim, percentage_misuse, cherry_picking, and more A risk score (0–100) and a suggested action: review, redirect, or ignore A plain-English explanation of why the post was flagged, written to be readable at a glance Moderators can filter by label, reasoning issue, risk threshold, or keyword search; sort by risk or recency; and mark classifications as correct or wrong to track accuracy over time. There's also an optional bot-comment feature that posts a soft, hedged note on flagged posts to prompt the author toward better sourcing or framing — without making any accusations.
How we built it
LitLens runs entirely inside Reddit's Devvit platform using the new @devvit/web framework (v0.12.23):
Server: Hono (Node 22) handling /api/* routes for the dashboard and /internal/* routes for Devvit triggers and menu actions Client: React 19 + Tailwind CSS v4, rendered as a tall inline post on the subreddit Storage: Redis via Devvit's built-in key-value store, with a sorted set for fast newest-first and risk-sorted queries Classification: A dual-path system — OpenAI gpt-4o-mini as the primary classifier, with a hand-built rule-based fallback that fires automatically when AI is unavailable Ingest: An onPostSubmit trigger ingests new posts automatically; a "Scan subreddit" button uses reddit.getNewPosts() to pull in the 25 most recent posts on demand TypeScript end-to-end, with Zod schema validation on all AI output
Challenges we ran into
The hardest part of the build was Devvit's networking layer. Devvit intercepts all outgoing TCP at the OS/kernel level through a gRPC proxy — which means even node:https calls are caught and re-encoded. For HTTP GET requests this works fine, but POST requests with JSON bodies are mangled in transit, causing OpenAI to return HTTP 400 errors on every request regardless of how the body was constructed (string, Buffer, Uint8Array — we tried them all). DeepSeek's domain wasn't in Devvit's platform allowlist at all.
This meant our primary AI classifier couldn't make outbound API calls. We pivoted to building a robust rule-based fallback classifier — regex patterns for common signals like percentage misuse, sweeping generalisations, unsupported claims, and recommendation requests — that produces sensible triage results without any network calls.
Debugging was also harder than expected: server-side console.log goes to Reddit's remote logging infrastructure, not the local terminal, so errors had to be surfaced through the UI itself.
The onPostSubmit trigger also had reliability issues we couldn't fully diagnose without log access, which led us to build the "Scan subreddit" button as a dependable alternative.
Accomplishments that we're proud of
The rule-based classifier works surprisingly well for the use case. "What should I read next?" gets caught as duplicate + low_effort. "Clearly, science proves readers are 40% more empathetic" gets flagged for needs_evidence and unsupported_claim with a note explaining why that specific phrasing is a flag, not just that it is one. Posts with multiple percentages get flagged for possible percentage_misuse.
We're also proud of how the system degrades gracefully — a missing API key, a network failure, or a mangled request all end up at the same rule-based path with a sensible result and a raw_error field for debugging, rather than silently producing nothing.
The plain-language reason text ("This post looks very short or thin on content and matches a common recurring question type. Worth a quick look.") makes the output feel like a colleague's note rather than a system label.
What we learned
Devvit's infrastructure has real constraints that aren't visible until you hit them — particularly around outbound networking. Building for a constrained runtime pushed us to make the rule-based system much more thorough than we'd originally planned, and that turned out to be a feature: the app works fully offline from any external API.
We also learned that trigger-based ingest is fragile when you can't see logs. The "scan on demand" pattern is more reliable and gives moderators control over when new posts enter the queue.
What's next for LitLens
Real AI classification — once Devvit's outbound POST proxy issues are resolved, the OpenAI path is already wired in and will activate automatically Cross-post duplicate detection — comparing new posts against the existing queue to surface near-duplicates, not just pattern matches Per-subreddit rule configuration — let moderators define their own trigger phrases and label weights via the Devvit settings panel Mod action integration — surface flair suggestions and removal reason drafts directly in the dashboard so a moderator can act in one click Trend tracking — weekly rollups of what's being flagged most, to help mods update their wiki and pinned posts proactively
Built With
- claude
- devvit

Log in or sign up for Devpost to join the conversation.