Abstract
Alzheimer’s disease (AD) is an age-related neurodegenerative condition that places increasing strain on patients, caregivers, and the healthcare system. Although early detection is vital, it is often limited by the cost and complexity of traditional methods such as neuroimaging and lengthy cognitive assessments. Identifying AD in its early stages can help preserve physical and social function, allowing timely intervention and continued engagement in physical activity, which supports quality of life and may slow disease progression. This model proposes a semi-supervised machine learning strategy for AD diagnosis based on acoustic features from brief speech samples. The approach takes advantage of mel-spectrogram features to extract vocal patterns without manual transcription or linguistic preprocessing. Informative sound patterns are detected using a convolutional neural network (CNN) that gradually adds unlabeled speech data during training through pseudo-labeling. By emphasizing scalable, non-invasive methods that rely solely on unprocessed vocal inputs, this work presents a practical solution for large-scale cognitive screening in resource-limited settings.
Inspiration
Alzheimer’s disease affects over 55 million people globally and is not only a cognitive disorder but also a major cause of motor decline and physical disability in older adults [WHO, 2023]. As the disease progresses, individuals often experience impaired gait, postural instability, muscle weakness, and difficulty swallowing — conditions that can lead to falls, malnutrition, and aspiration pneumonia, a leading cause of death in late-stage AD [Alzheimer’s Association, 2023; Neurology, 2020].
Despite its impact, only 1 in 4 people with AD are diagnosed, primarily due to the high cost of imaging and limited access to specialists in low-resource regions [WHO, 2023; OECD, 2021]. Recent studies, however, have shown that subtle changes in speech patterns can signal cognitive decline even before formal symptoms emerge — making voice a promising low-cost screening modality [Luz et al., 2021; Haider et al., 2020].
Motivated by this, Listening Beyond The Labels introduces a speech-only, semi-supervised model that detects early signs of AD from short voice samples and mel-spectrograms. This non-invasive approach has the potential to support earlier diagnosis and intervention, helping preserve both cognitive and physical function through sustained engagement and preventive care [Cochrane, 2020].
What it does
Listening Beyond The Labels is a lightweight machine learning pipeline designed to detect early signs of Alzheimer’s disease using only short speech samples. The system first converts raw audio files (typically in MP3 format) into WAV format to preserve quality and compatibility, and then generates mel-spectrograms — time-frequency visual representations that capture acoustic features such as pitch, prosody, pause duration, and articulation. These patterns are known to shift during early cognitive decline.
The model is trained using a semi-supervised convolutional neural network (CNN). It learns from a limited labeled dataset of speech samples from the DementiaBank Pitt Corpus [MacWhinney et al., 2011] and leverages a much larger pool of unlabeled voice recordings from the Mozilla Common Voice dataset [Ardila et al., 2020]. Using pseudo-labeling, the model assigns temporary labels to high-confidence unlabeled samples, gradually improving its accuracy and generalization.
Unlike traditional screening methods that rely on neuroimaging, clinical interviews, or linguistic transcription, this system operates entirely on raw voice input. It requires no wearable devices, questionnaires, or clinical supervision. The result is a scalable, accessible tool that can be embedded in mobile health apps, remote care platforms, or community screening settings to support early detection and timely intervention in real-world, low-resource environments.
What’s next for Listening Beyond The Labels
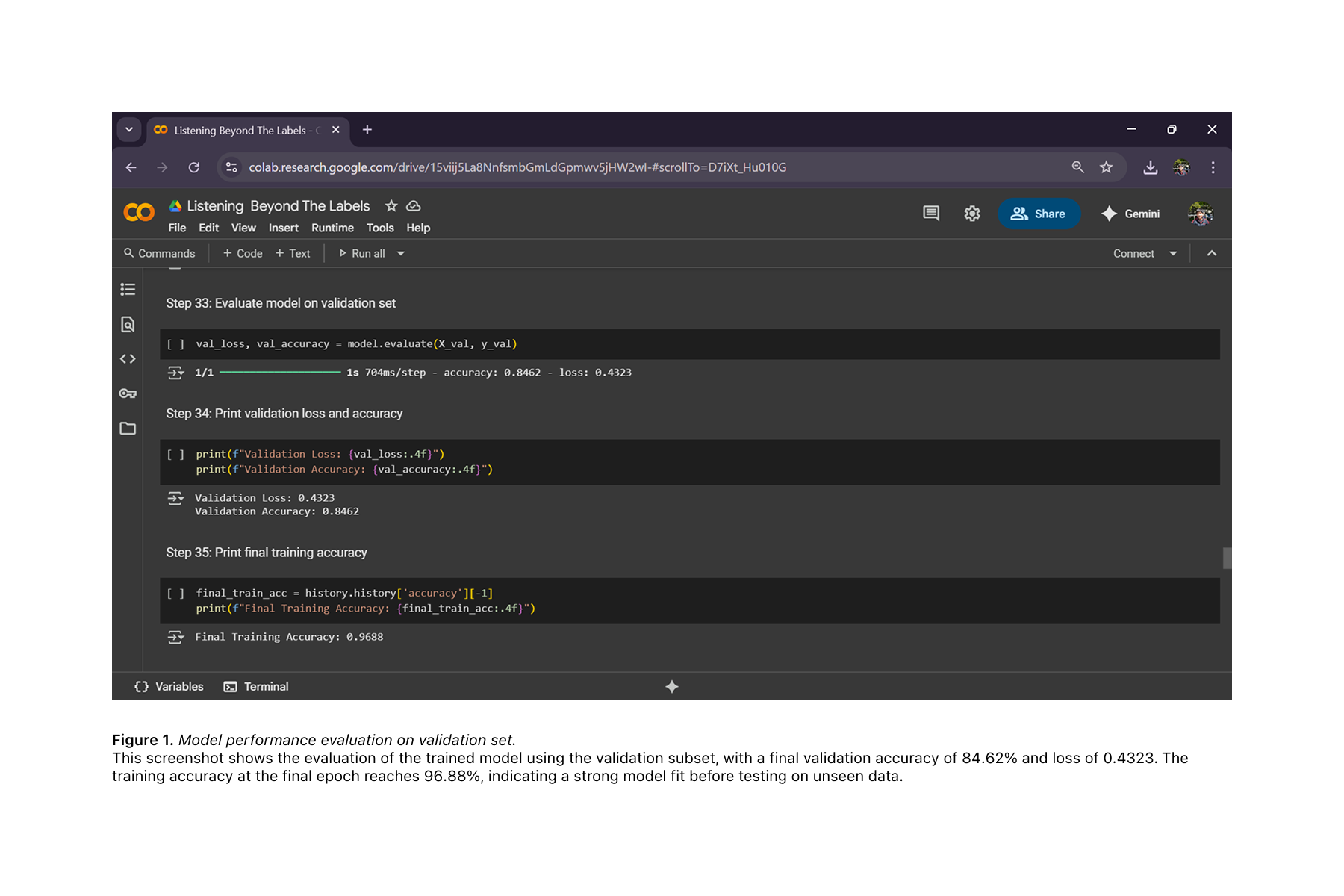
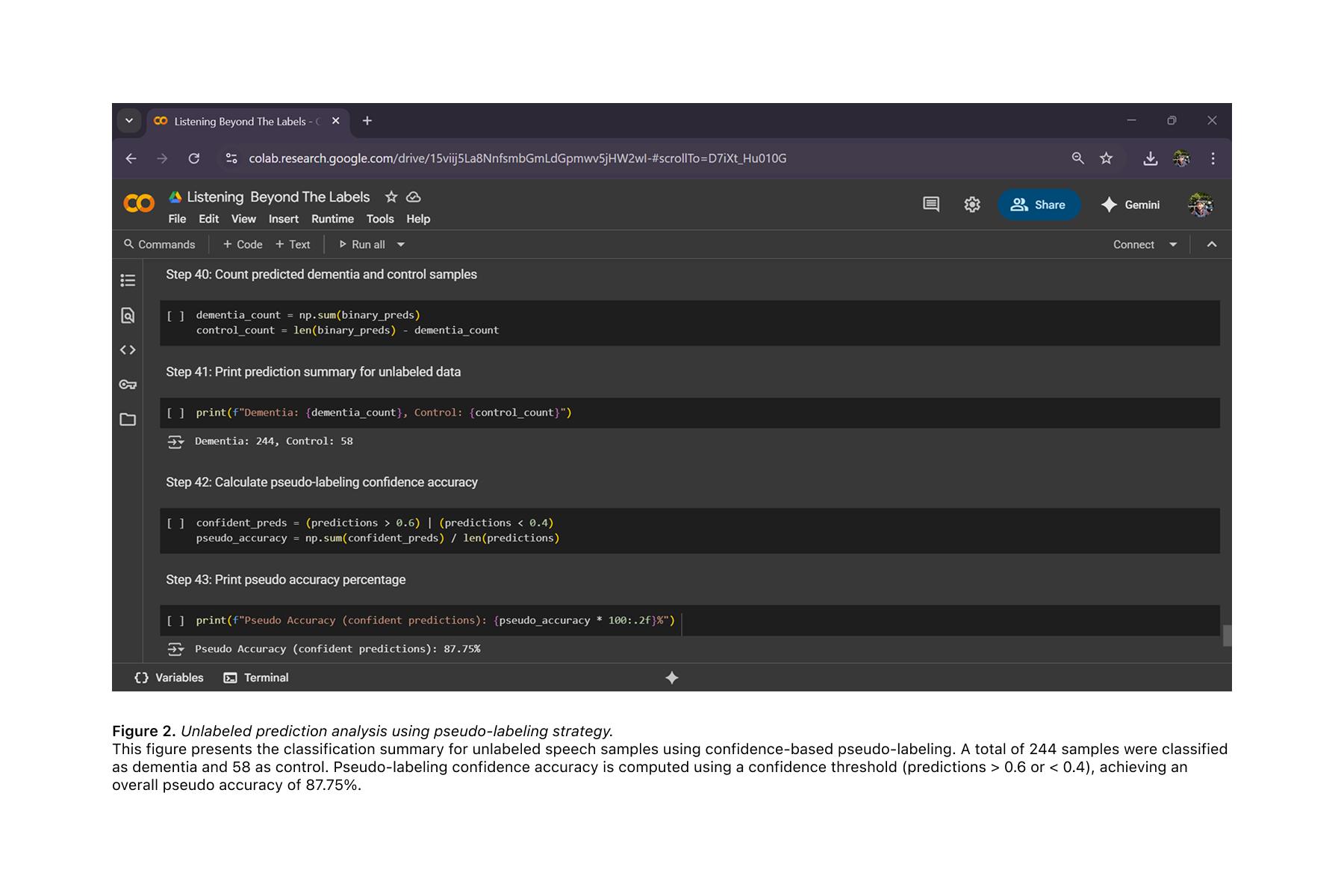
I aim to integrate this model into wellness platforms that promote physical activity and cognitive health in older adults, such as smart assistants, mobile fitness apps, and telehealth portals. In these contexts, passive speech input can serve as a continuous, non-intrusive screening mechanism. At its current research stage, the model achieves approximately 87.75% pseudo accuracy, referring to confident predictions generated through pseudo-labeling of unlabeled speech data using only brief voice samples and acoustic features. I plan to document these results in a formal manuscript or preprint in the near future to contribute to the broader research community.
Looking ahead, I am initiating collaborations with clinicians and public health experts to test the model in real-world care environments, especially in underserved and remote communities. I also intend to create an open, privacy-conscious speech dataset that includes diverse genders, accents, and age groups to help mitigate algorithmic bias and improve global generalization. Furthermore, I plan to deploy the model on local edge devices, allowing users to run screenings offline without uploading voice data. This approach ensures privacy, user control, and digital sovereignty.
As Listening Beyond The Labels continues to evolve, I envision it as a voice-first cognitive health companion that empowers people to stay mentally and physically active through early detection, personalized insights, and accessible, speech-driven diagnostics.
Built With
- colab
- keras
- librosa
- matplotlib
- numpy
- os
- pydub
- python
- scikit-learn
- shutil
- soundfile
- tensorflow
- threadpoolexecutor
- tqdm



Log in or sign up for Devpost to join the conversation.