-
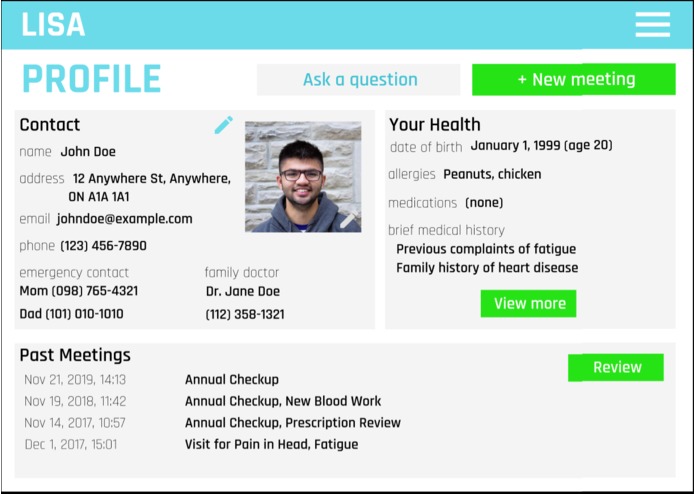
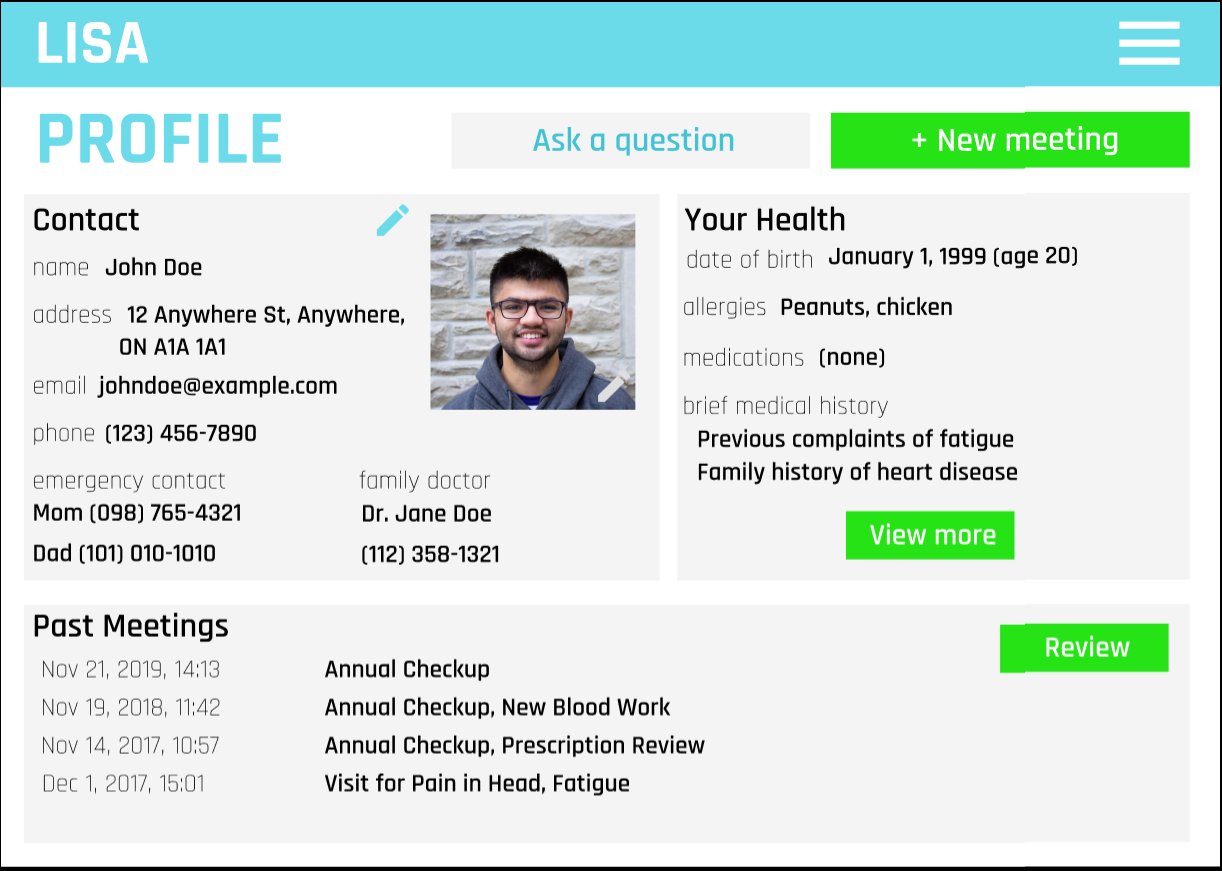
Profile view
-
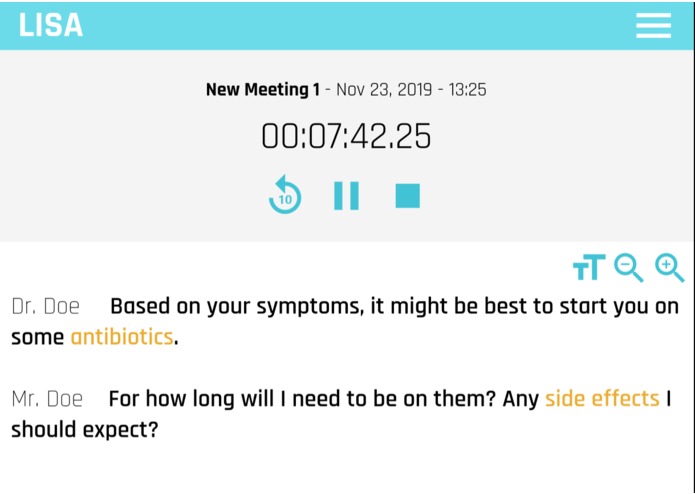
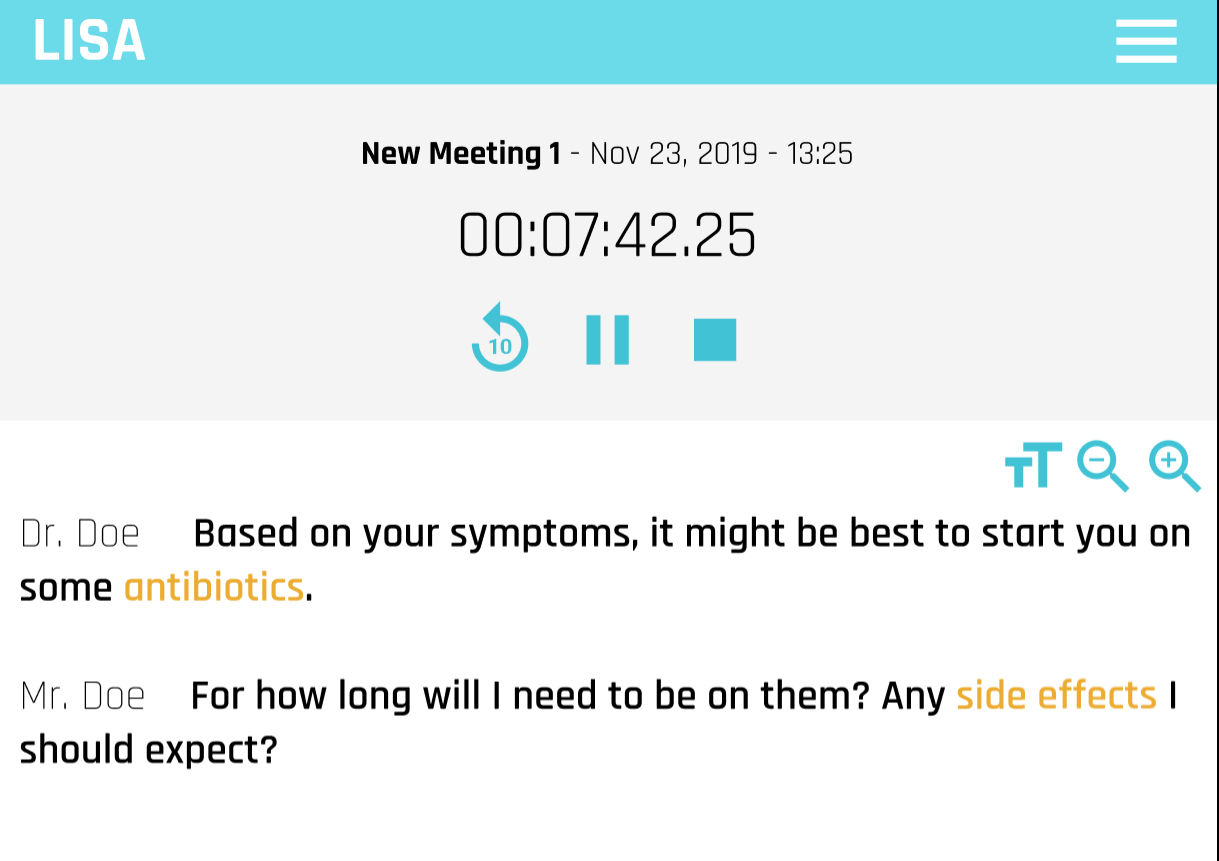
New recording view, with simultaneous transcription and highlights
-
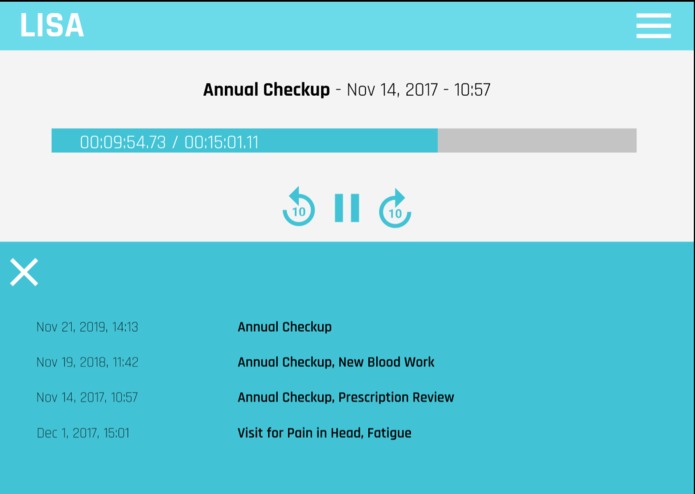
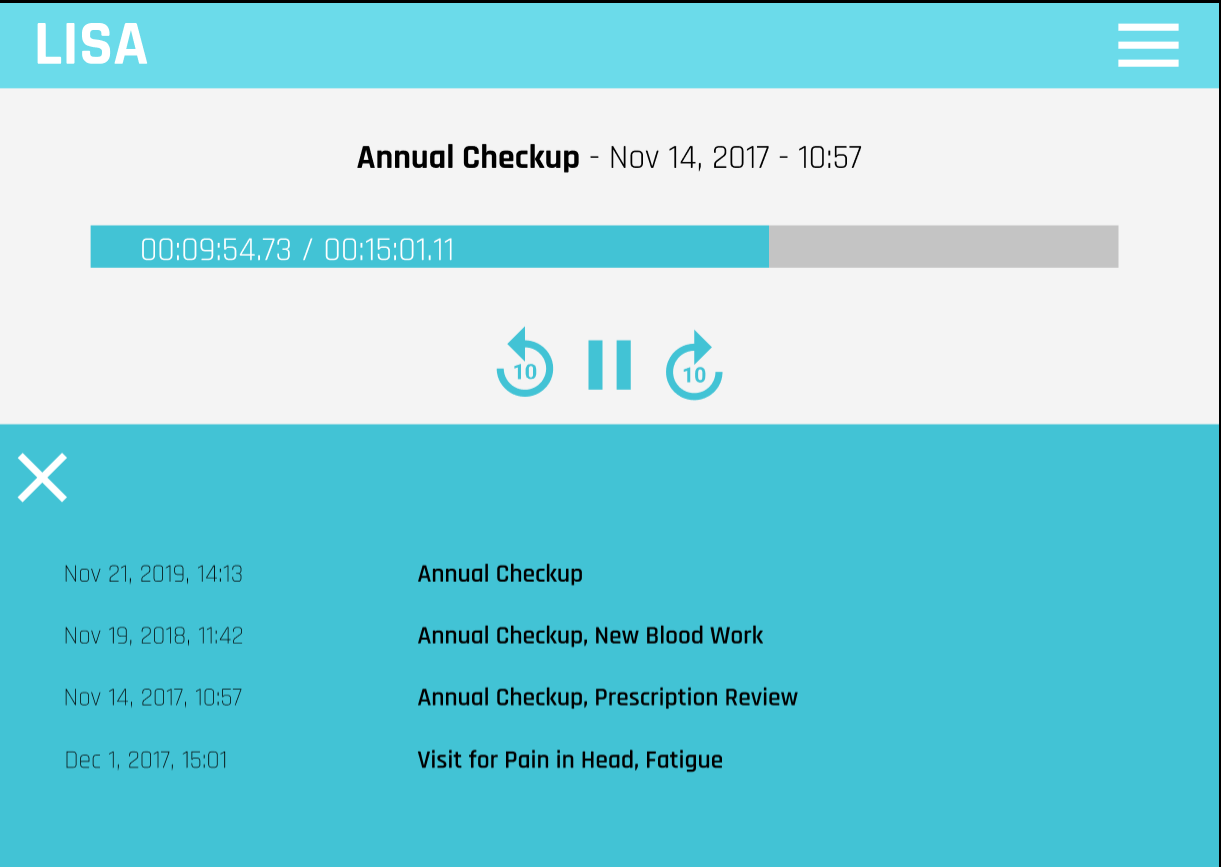
Playing past recorded meeting, with menu of other previously recorded meetings
-
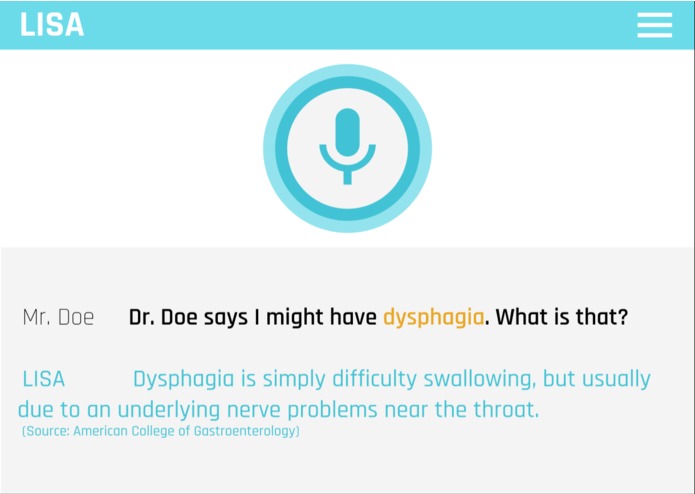
Interface for asking LISA a question

Inspiration
According to the WHO, only 50% of patients suffering from chronic diseases in developed nations follow treatments for their illnesses. This occurs mostly due to a general lack of understanding of what the doctor is saying, or uncertainty about whether what the doctor is prescribing is right of the patient's condition. To address these issues and improve transparency in the patient-physician relationship, we built LISA (Loyal Integrated Smart Assistant).
What it does
LISA addresses transparency in the patient-physician relationship on two fronts. It can listen in on the conversation and break down key information from raw audio transcripts about treatments (like medication doses and procedures) for the patient into objective, yet easy-to-understand tidbits for the patient. On the physician's side, it can flag patient information about physical characteristics (like age and sex) and key symptoms in various body systems (ranging from nausea to feeling feverish) for the doctor to note when proposing better treatment plans.
How we built it
LISA was built using Google Cloud's Dialogflow (for conversational capabilities) and Speech-to-Text (for transcription) API's to enable listening for and understanding key medical terms (notably symptoms, treatments, and medications), which are used as trained contexts in the voice-activated assistant algorithm. Speech transcripts are parsed for these terms and matched with some open-source databases (ex. DrugBank, Disease Ontology) describing disease symptoms and medications, both of which are linked as key-value pairs in tables set up in MongoDB Atlas. LISA is hosted on a web application generated using HTML5 and ReactJS, with the UI appearance and workflow prototyped using Figma.
Challenges we ran into
- Difficulties with acquiring reputable, open-source datasets and their connection with MongoDB (many are either behind paywalls or require delivery over business days only)
- Hard to find elegant ways to hard-code UI wireframes from Figma to the corresponding ReactJS syntax
- Encountering differences in audio file types in Google's Text-to-Speech API
- Difficulties with training LISA (on Google Dialogflow) to discriminate more than two speakers
- Familiarizing with potential legal implications of patient privacy and data protection
Accomplishments that we're proud of
- Generating comprehensive lists of terms to train Lisa with (over Google Dialogflow)
- Linking relevant and common drug and symptom information from Disease Ontology, DrugBank databases on MongoDB to be matched with incoming parsed audio data
- Being able to differentiate two speakers and storing information as two distinct arrays for analysis (one for the patient, one for physician)
- Creating a working UI prototype on Figma that is sizable for different screen sizes
What we learned
- Many health-related databases from highly-reputable sources can be hard to find, which just highlights the importance of accessibility to objective health information
- Not all related APIs are built the same - it is important to read the documentation regarding accepted filetypes and other common setbacks to save time down the line
- Learning new features in novel technologies (such as Google Dialogflow, MongoDB)
- Taking advantage of sponsors and mentors when dealing with setbacks, clarifying misconceptions
What's next for LISA
- Expanding to mobile interfaces (for greater portability by both doctors and patients)
- Training LISA to recognize more than two speakers in a conversation, dealing with simultaneous speakers
- Testing a greater variety of APIs, partnering with reputable health governing bodies for robust data on medications and illnesses
- Further development of the UI and functionality on the doctor's side of the conversation
- Making general structure transferable for listening in on other meetings in other industries (like business one-on-one performance meetings)
Built With
- dialogflow
- figma
- google-cloud
- google-web-speech-api
- javascript
- mongodb
- mongoose
- node.js
- react
- text-to-speech
- the-materials-project



Log in or sign up for Devpost to join the conversation.