-
-
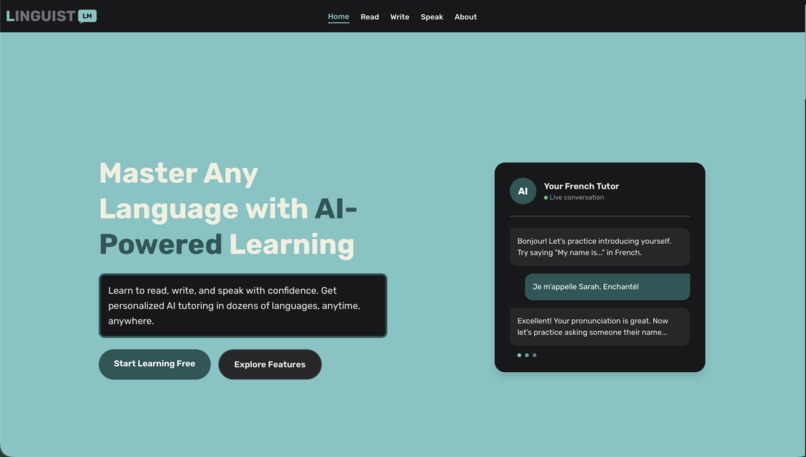
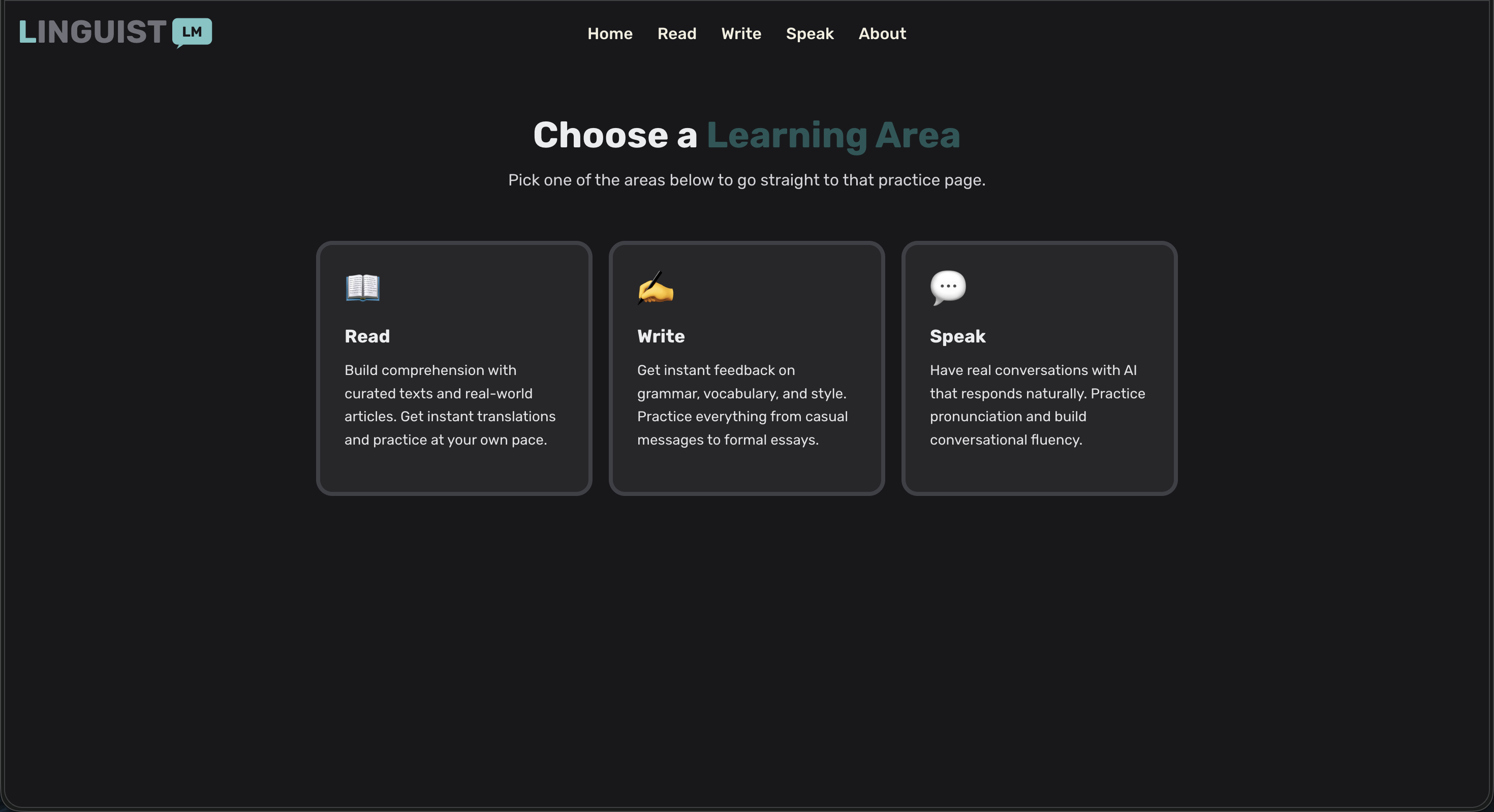
Home page
-

Home Page 2
-

Home Page 3
-

Home Page 4
-
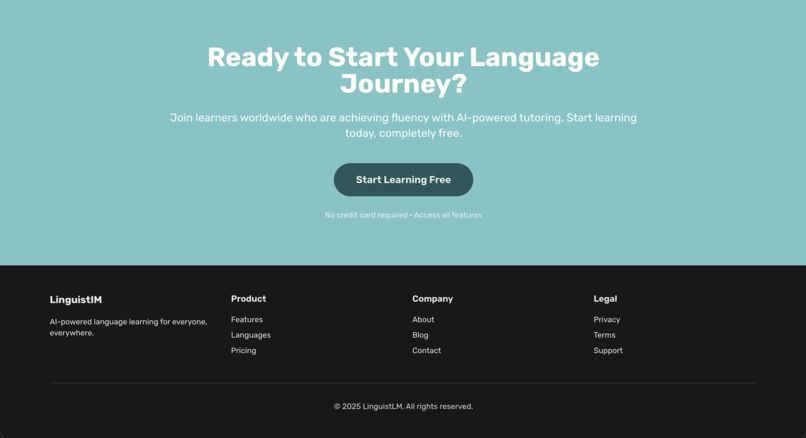
Home Page 5
-
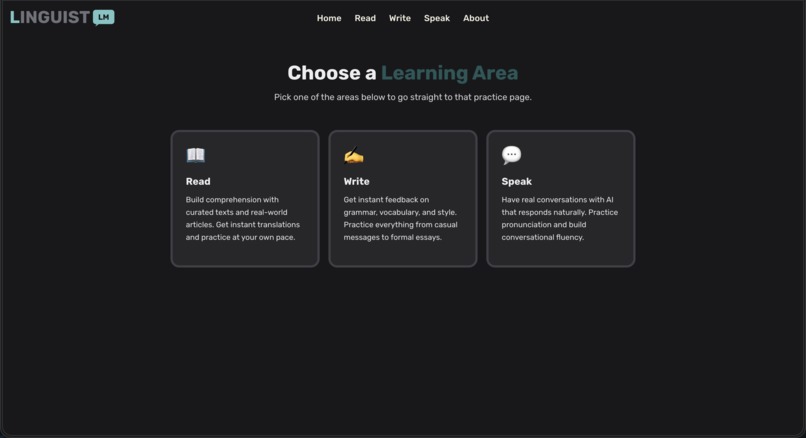
Onboarding
-
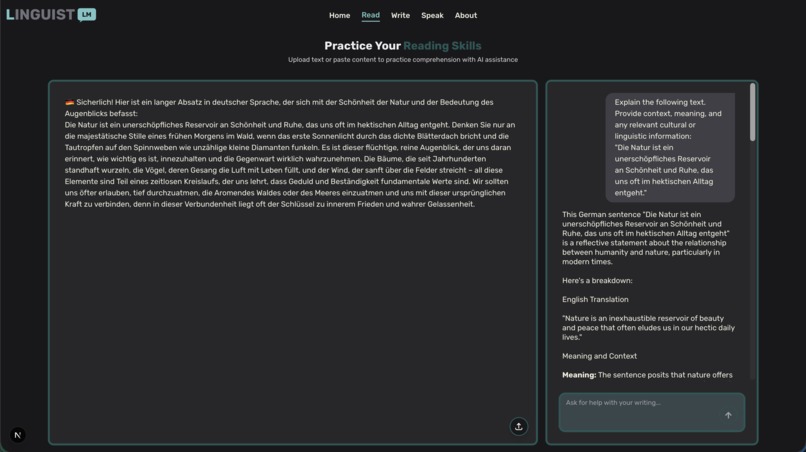
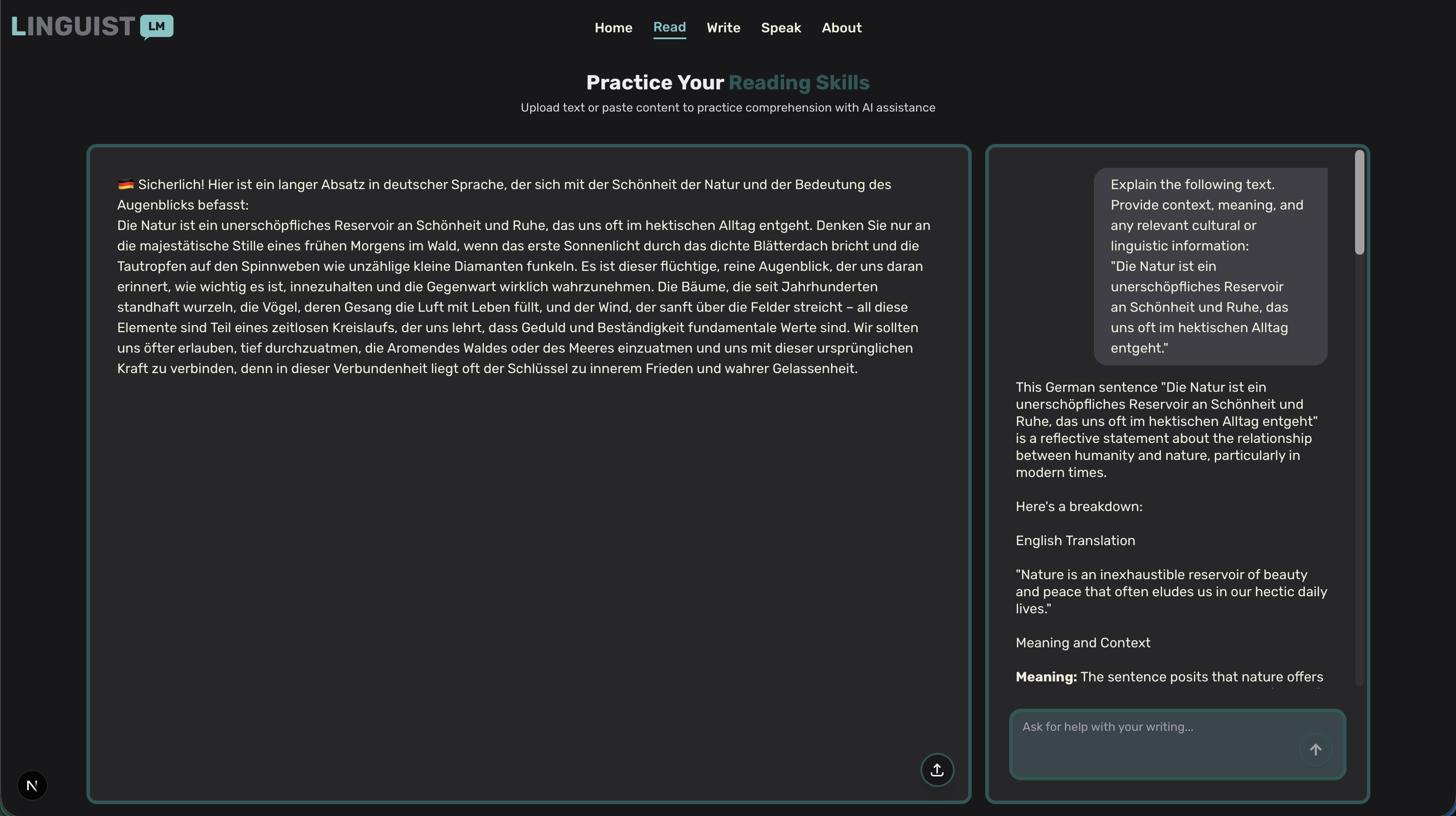
Reading assistance
-
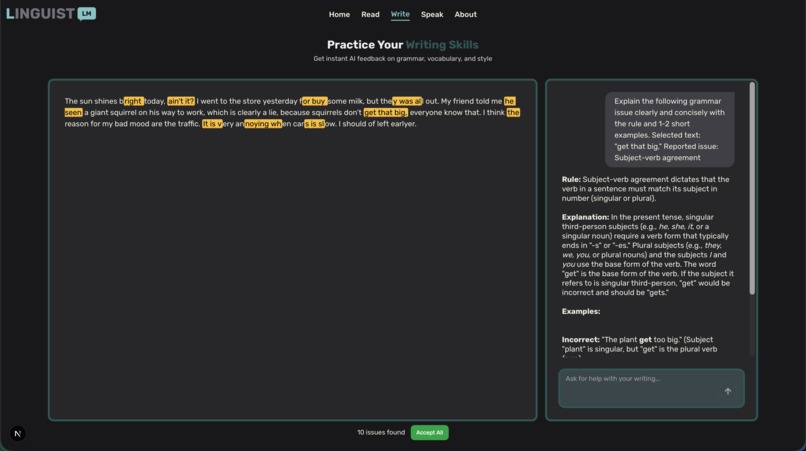
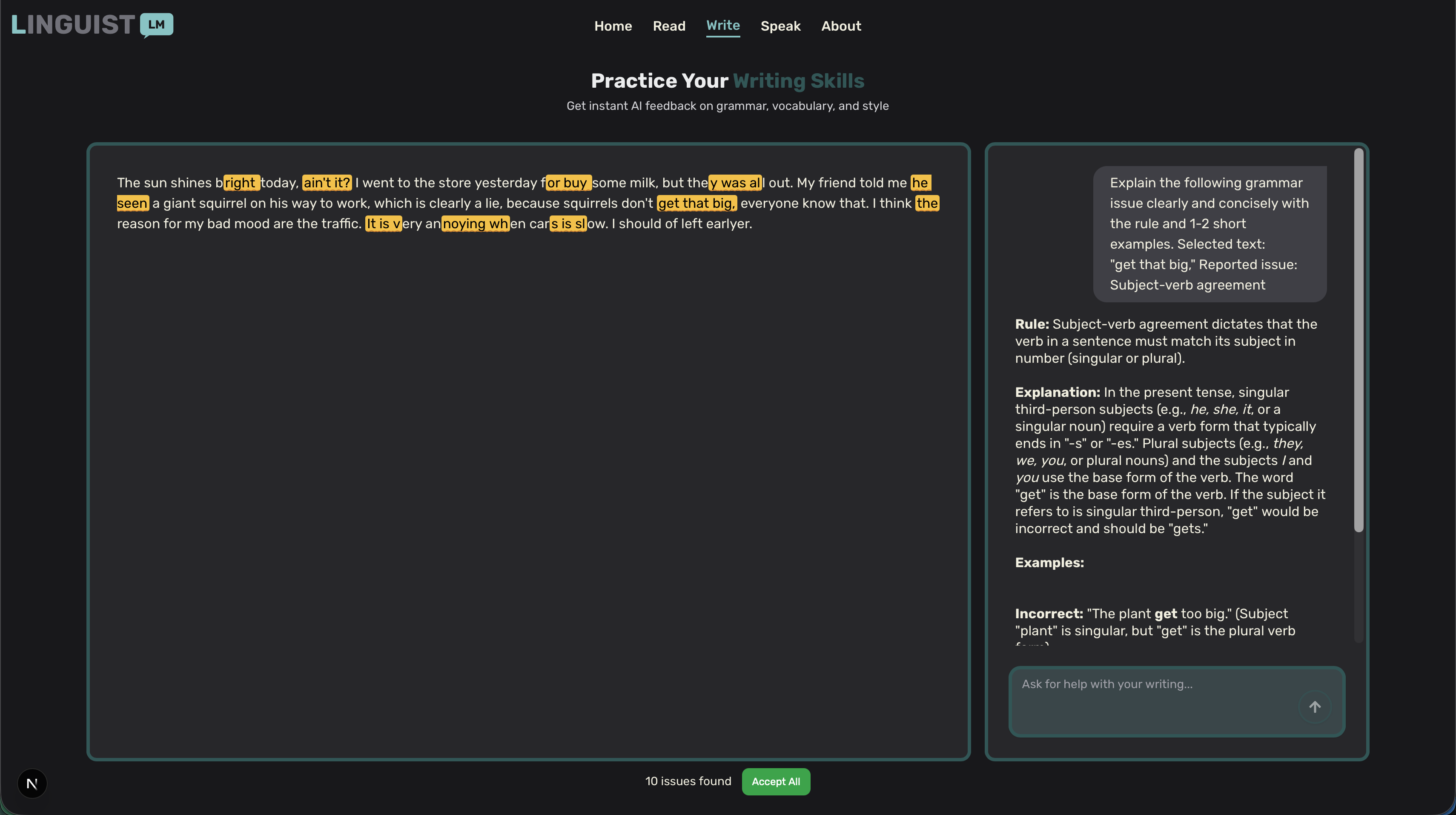
Writing assistance
-
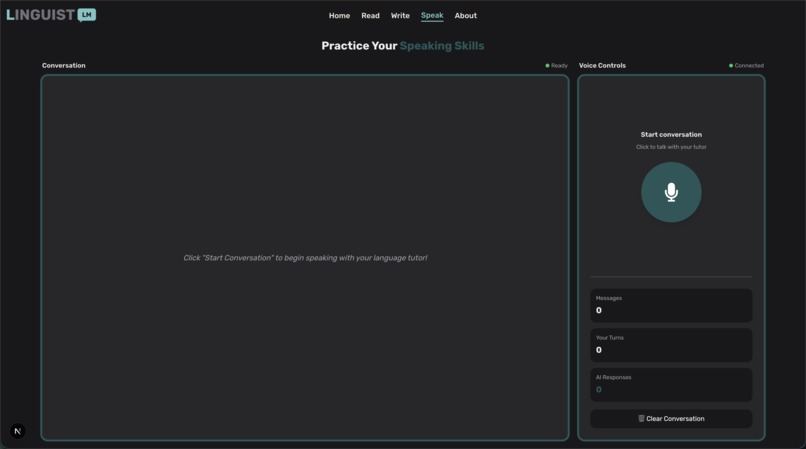
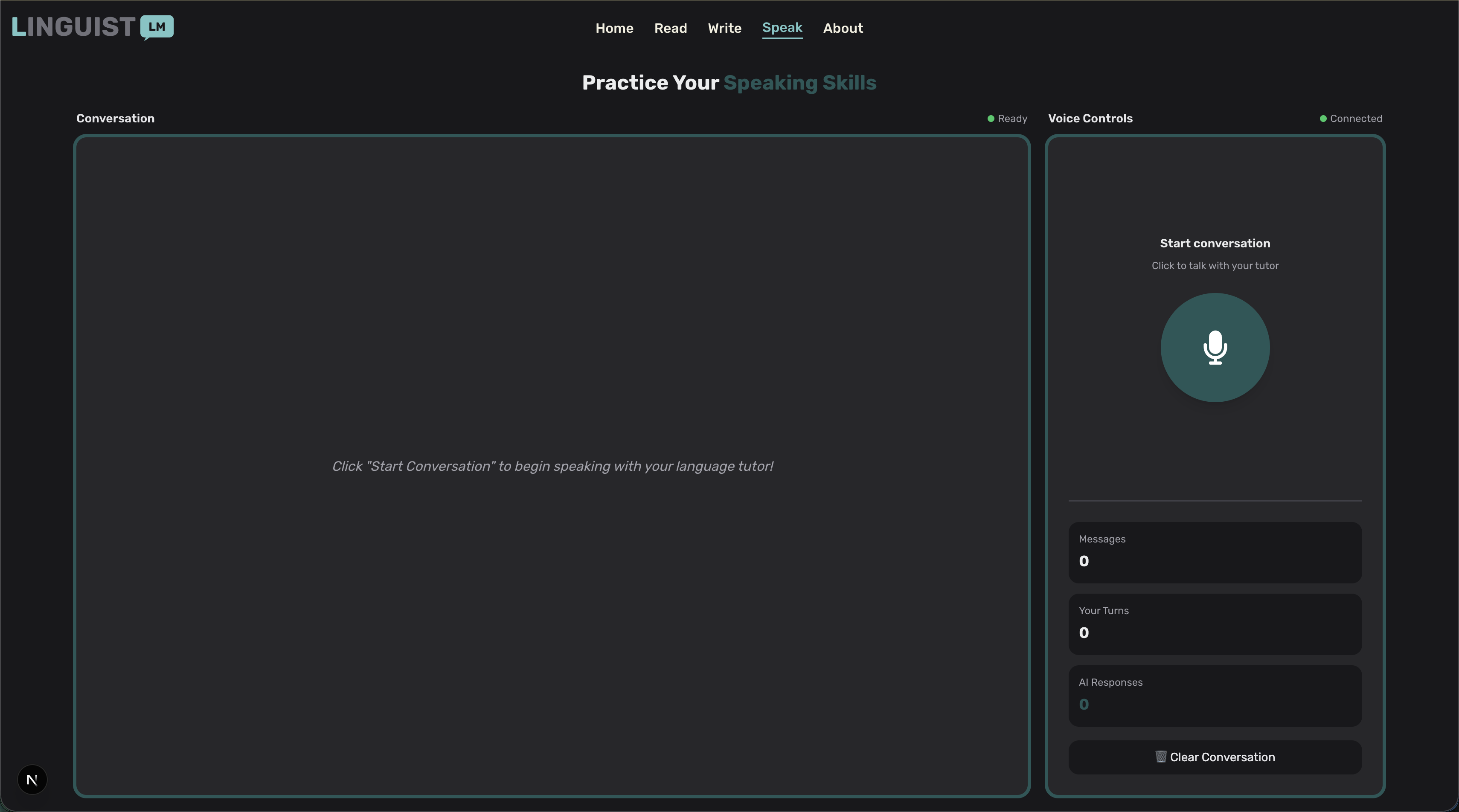
Speaking assistance
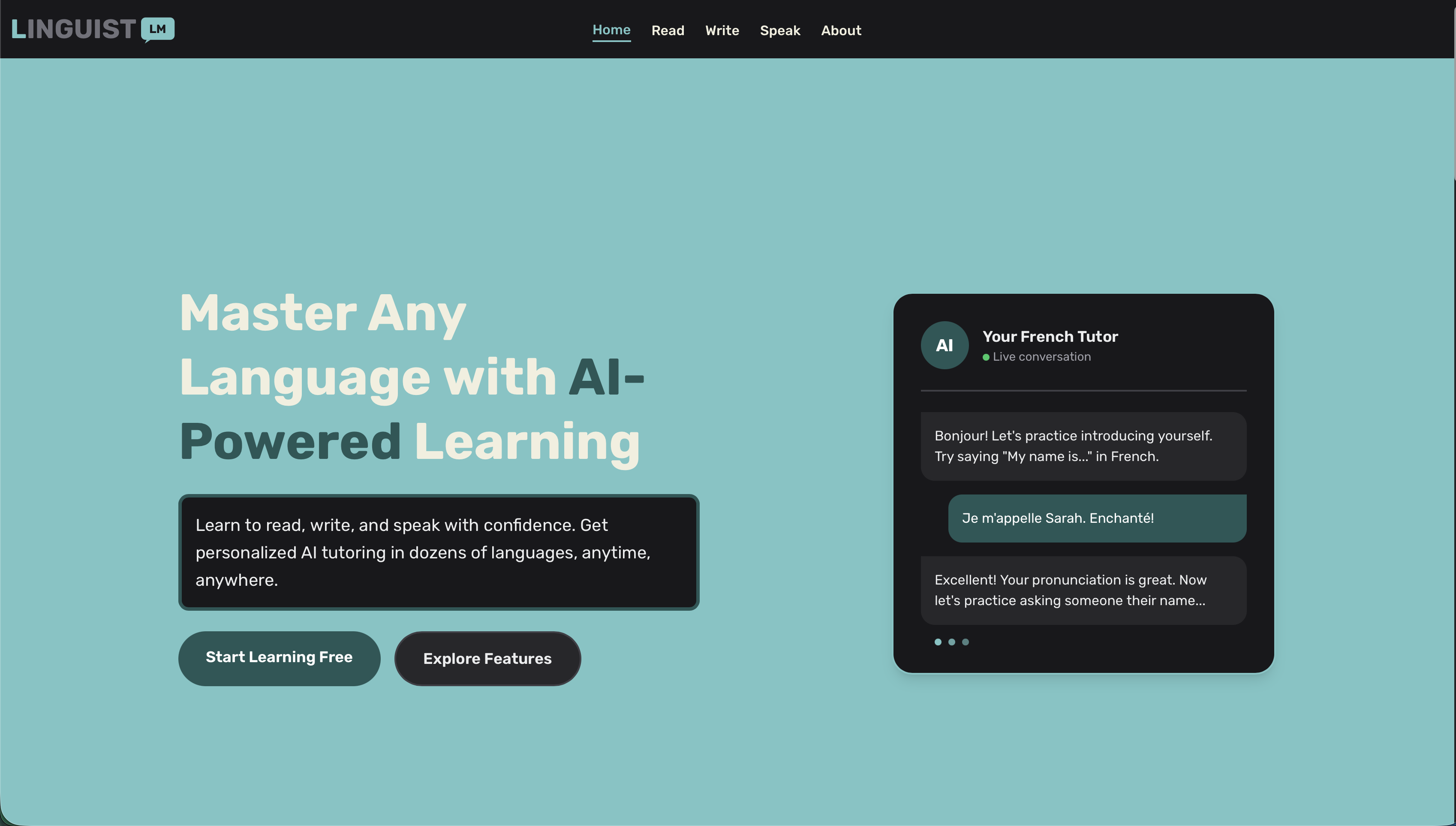



LinguistLM - AI-Powered Language Learning Platform
Inspiration
Language learning has traditionally been expensive, time-consuming, and often intimidating. We've all experienced the anxiety of trying to speak a new language, worrying about making mistakes, or struggling to find practice opportunities that fit our schedules. We were inspired to create LinguistLM by the vision of making language learning accessible, natural, and confidence-building for everyone. With AI technology advancing rapidly, we saw an opportunity to create a personal language tutor that's available 24/7, never judges your mistakes, and adapts to your unique learning pace and style.
What it does
LinguistLM is a comprehensive AI-powered language learning platform that offers three core learning modes:
📖 Read Mode: Practice reading comprehension with curated texts, real-world articles, and instant translations. Build vocabulary and understanding at your own pace across multiple difficulty levels.
✍️ Write Mode: Get instant, detailed feedback on your writing - from casual messages to formal essays. Our AI analyzes grammar, vocabulary, style, and provides personalized corrections and suggestions.
💬 Speak Mode: The crown jewel of our platform - engage in real-time, voice-to-voice conversations with an AI language tutor. Using Google's Gemini Live API with native audio capabilities, users can have natural, flowing conversations where:
- Your speech is transcribed in real-time
- The AI responds with natural voice synthesis
- You receive gentle corrections and encouragement
- Conversations adapt to your proficiency level
- Practice feels like talking with a supportive friend
The platform supports 50+ languages, from popular choices like Spanish, French, and Mandarin to less common languages, ensuring everyone can learn the language that matters to them.
How we built it
Frontend Stack:
- Next.js 16 (App Router) for a modern, performant React framework
- TypeScript for type safety and better developer experience
- HeroUI/NextUI for beautiful, accessible UI components
- Tailwind CSS for responsive, utility-first styling
- Custom design system with carefully crafted color palette (llm-chinois, llm-sea-glass, etc.)
AI Integration:
- Google Gemini 2.5 Flash for text-based reading and writing assistance
- Gemini Live API with native audio for real-time voice conversations
- Audio processing using Web Audio API for 16kHz input and 24kHz output
- Real-time transcription for both user input and AI responses
Architecture:
- Next.js API routes for secure backend operations
- Client-side audio streaming with
ScriptProcessorNodefor microphone input - WebSocket-style connection via Gemini Live for low-latency audio exchange
- Session management for maintaining conversation state
- Environment-based API key security
Key Technical Features:
- Real-time PCM audio encoding/decoding
- Automatic audio buffer management for seamless playback
- Turn-based conversation handling with interruption support
- Responsive design that works on desktop and mobile
- Dark mode support throughout the application
Challenges we ran into
1. Audio Streaming Complexity: Implementing real-time audio-to-audio chat was significantly more complex than expected. We had to:
- Understand PCM audio encoding at 16-bit depth
- Handle sample rate conversions (16kHz for input, 24kHz for output)
- Manage audio buffer timing to prevent gaps or overlaps
- Deal with Web Audio API deprecations (ScriptProcessorNode vs AudioWorklet)
2. TypeScript Compatibility: Getting the @google/genai package to work smoothly with Next.js and TypeScript required careful type definitions and understanding of when code runs on the server vs. client.
3. Real-time State Management: Coordinating between audio playback, transcription updates, and UI state while maintaining smooth user experience required careful callback architecture and React hooks optimization.
4. Responsive Layout: Creating a balanced, professional layout that works across different screen sizes while maintaining the visual hierarchy between conversation display and controls took multiple iterations.
5. Error Handling: Implementing graceful error handling for microphone permissions, API failures, and network issues while keeping the user experience smooth and informative.
Accomplishments that we're proud of
✨ Seamless Voice Conversations: We successfully implemented real-time, natural voice-to-voice conversations with an AI - something that feels almost magical to use
🎨 Beautiful, Cohesive Design: Created a polished UI with a custom design system that's both functional and aesthetically pleasing
🚀 Full-Stack Integration: Built a complete end-to-end application from audio processing to UI, all working together seamlessly
📱 Responsive Experience: The platform works beautifully across devices, from desktop to mobile
🔒 Secure Architecture: Implemented proper API key management and security practices
💡 User-Centric Features: Added thoughtful touches like auto-scrolling chat, real-time transcription, session statistics, and gentle error messages
🌍 Multi-Language Support: Built a platform that can genuinely help people learn any of 50+ languages
What we learned
Technical Skills:
- Deep dive into audio processing and the Web Audio API
- Real-time streaming architectures and WebSocket-style connections
- Advanced React patterns with hooks and callback optimization
- Next.js 14 App Router best practices
- TypeScript advanced types and generic constraints
AI Integration:
- Working with cutting-edge AI models (Gemini 2.5 Flash, Gemini Live)
- Understanding modalities (text, audio) and how to leverage them
- Crafting effective system prompts for educational contexts
- Managing AI conversation state and context
Product Design:
- Importance of user experience in educational tools
- Balancing feature richness with simplicity
- Creating an encouraging, non-judgmental learning environment
- Responsive design principles and flex layouts
Soft Skills:
- Time management in a hackathon environment
- Prioritizing features (MVP vs. nice-to-have)
- Debugging complex, multi-layer systems
- Reading documentation and adapting reference implementations
What's next for LinguistLM
Short-term Goals:
- Language Selection: Add ability for users to choose which language they want to practice
- Difficulty Levels: Implement beginner, intermediate, and advanced modes
- Topic Selection: Let users choose conversation topics (travel, business, casual, etc.)
- Progress Tracking: Add detailed analytics showing improvement over time
- Save Conversations: Allow users to review past conversations and corrections
Medium-term Goals:
- User Accounts: Implement authentication and personalized learning paths
- Vocabulary Lists: Generate custom vocabulary lists from conversations
- Pronunciation Scoring: Add detailed pronunciation feedback and scoring
- Multiple AI Voices: Let users choose from different voice options
- Mobile App: Create native iOS and Android apps for on-the-go learning
Long-term Vision:
- Community Features: Connect learners with similar goals
- Gamification: Add achievements, streaks, and challenges
- Cultural Context: Integrate cultural notes and real-world scenarios
- Professional Certifications: Partner with language certification programs
- AI Tutor Specialization: Different AI personalities for different learning styles
- Offline Mode: Download lessons and practice without internet
- Integration with Other Platforms: Connect with language learning ecosystems
Ambitious Goals:
- AR/VR Integration: Immersive language learning in virtual environments
- Real Conversation Matching: Connect learners with native speakers
- Business Model: Freemium with premium features for advanced learners
- Educational Partnerships: Work with schools and universities
- Global Impact: Help 1 million people achieve language fluency
LinguistLM - Your journey to fluency, powered by AI. Because everyone deserves to find their voice in a new language. 🌍✨
Built With
- .tech
- gemini
- heroui
- next
- tailwind
- vercel

Log in or sign up for Devpost to join the conversation.