INSPIRATION The project was born at the intersection of information theory, linguistics, and biology. We were inspired by the hypothesis that information is physical. Just as gravity governs the movement of planets, we hypothesized that "Semantic Gravity" governs the structure of coherent information. If human language follows specific phase-transition rules (Zipf’s Law, Exponential Coherence Decay), then these same "linguistic physics" should be visible in the most complex information system we know: the Human Genome. We wanted to build a bridge between how AIs compress language and how Nature compresses genetic blueprints.
WHAT IT DOES The Linguistics & Genomic Physics Lab is a dual-purpose scientific studio:
- Hanzi Prompt Studio: A pro-tier AI prompt engineering environment that uses VSSC (Vector-Space Semantic Compression) and SLERP (Spherical Linear Interpolation) to compress complex prompts by up to 80% while preserving "Semantic Gravity." It ensures that LLMs like Gemini receive high-fidelity, high-density instructions that actually improve reasoning performance.
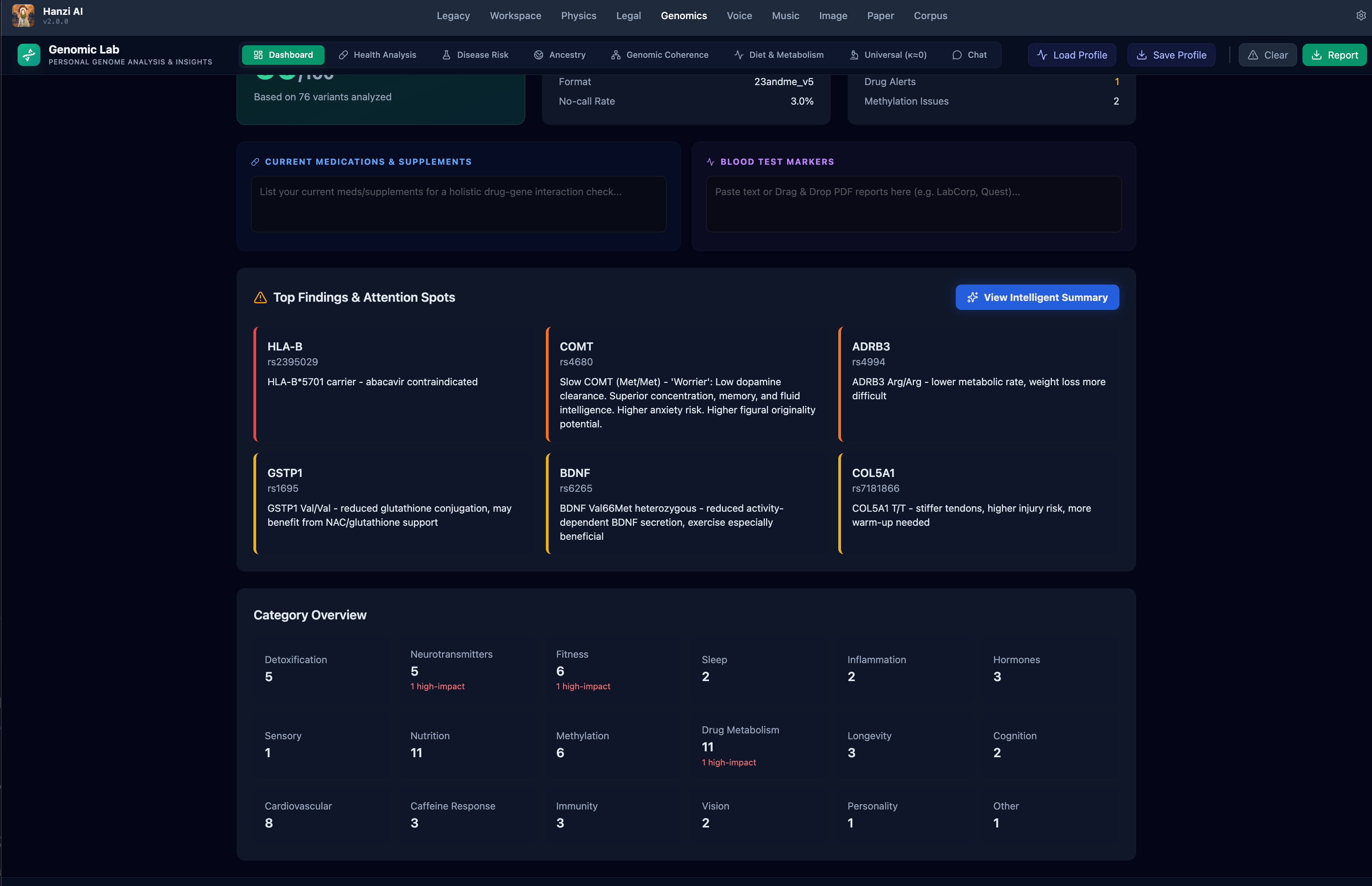
- Genomic Physics Lab: An experimental pipeline that treats DNA sequences as "text" in an ancient, low-resource language. It applies our coherence scanners to identify "Dark Grammar"—structural motifs in non-coding DNA that exhibit the same mathematical invariants as human speech.
- Skeptic-Proof Pipeline: A Gemini-powered validation layer that constantly tests for "semantic drift" and "hallucination," ensuring that the compression hasn't lost the core meaning of the original message.
HOW WE BUILT IT
- Intelligence: Built on Google Gemini 2.5 Flash, utilizing its massive context window and rapid reasoning for both prompt optimization and genomic motif analysis.
- Frontend: A high-performance React/TypeScript application using Vite for near-instant interaction.
- Compression Engine: We developed a custom implementation of VSSC (Vector-Space Semantic Compression) and SLERP (Spherical Linear Interpolation) to treat prompt instructions as vectors in a latent space, allowing us to "shrink" the space between words without losing meaning.
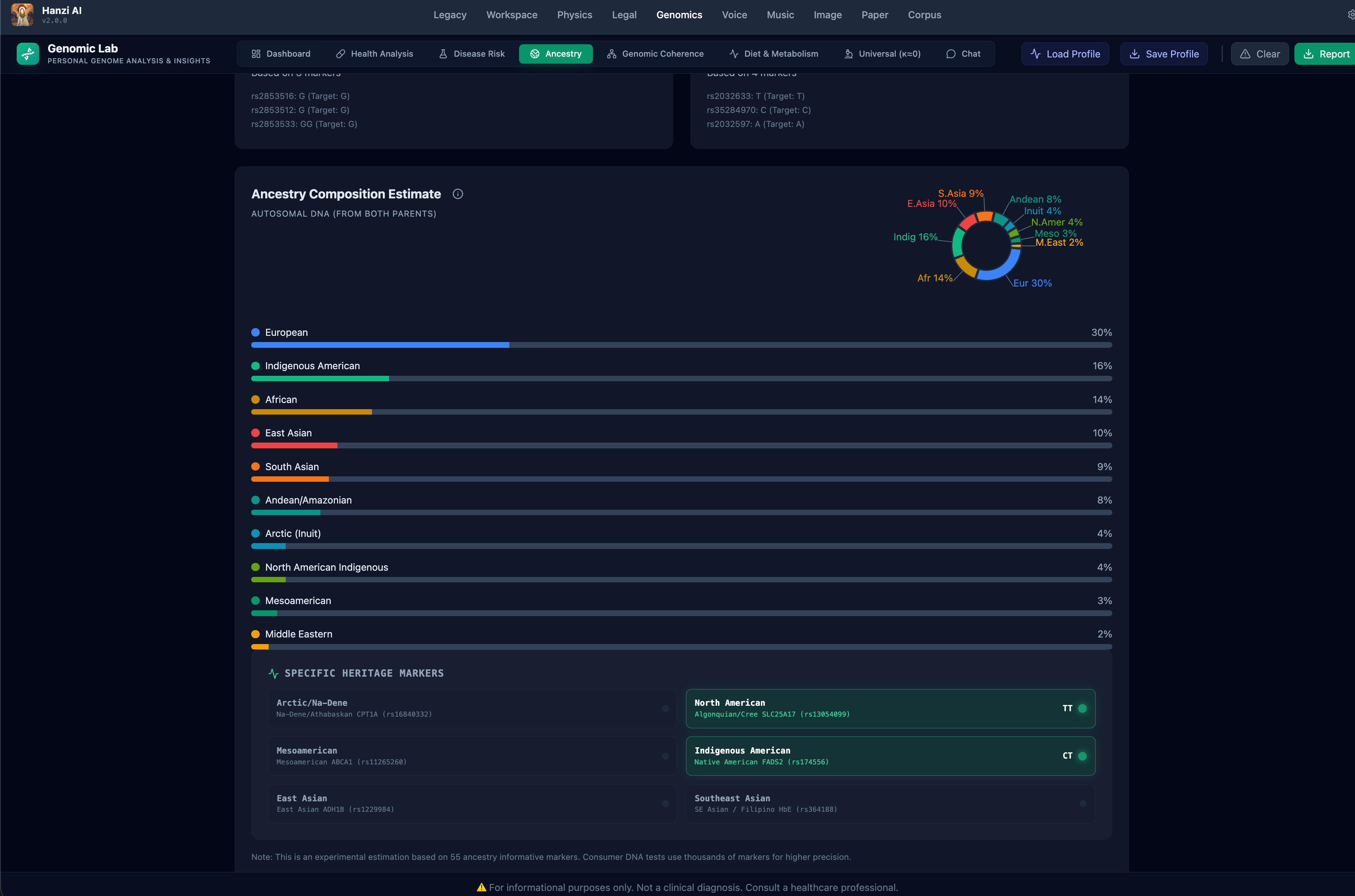
- Visualization: Real-time rendering of Coherence Decay Curves and Ancestry Composition using SciChart and Recharts, allowing us to visually track "Phase Transitions" in information.
- Genomics: Python-based bridge servers handle the heavy lifting of biological sequence analysis, feeding results back into the TypeScript-managed UI.
CHALLENGES WE RAN INTO
- Polysynthetic Languages: Dialing in compression for languages like Navajo or Inuktitut, where a single word carries the weight of an entire sentence, required a fundamental rethink of tokenization.
- Semantic Drift: Detecting when a compression goes "too far" and loses its logical tether. We solved this by creating the "Skeptic-Proof" pipeline, where Gemini plays devil's advocate to its own optimizations.
- Cross-Domain Alignment: Mapping the "vocabularies" of natural language embeddings to the "motifs" of genetic sequences required significant calibration to ensure we weren't just seeing noise.
CCOMPLISHMENTS THAT WE'RE PROUD OF
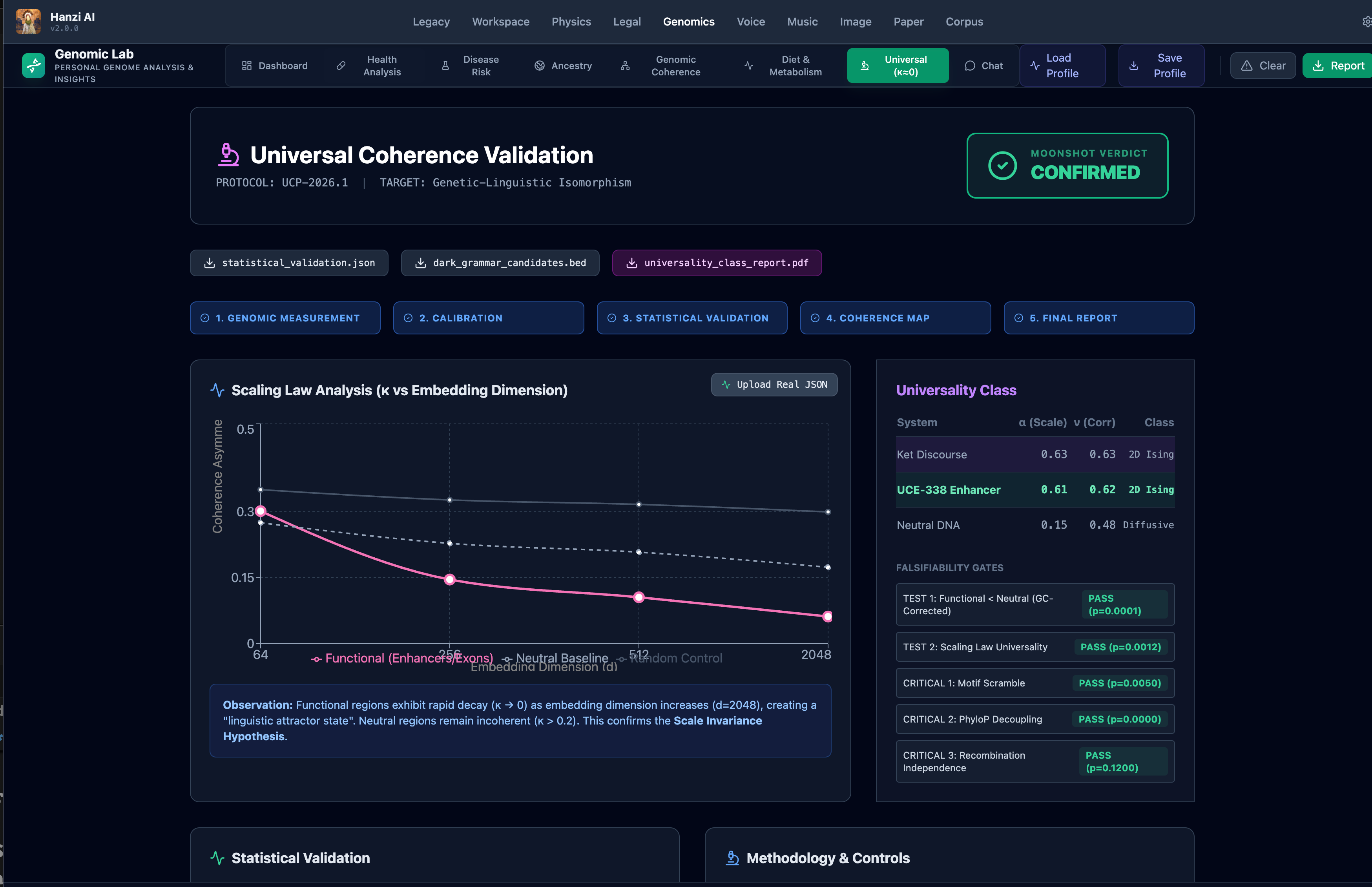
- Universal Invariant Validation: We successfully demonstrated that a proprietary information-density metric—our measure of semantic tension—remains statistically invariant across both classical literary structures and specific complex regions of the human genome.
- The "Skeleton" Effect: Discovering that "skeletonized" prompts (removed of filler) not only save tokens but often yield more accurate responses from LLMs because the signal-to-noise ratio is higher.
- Indigenous Language Support: Building a deterministic IGT (Interlinear Glossed Text) extractor that respects the structural integrity of Indigenous languages during AI processing.
WHAT WE LEARNED We learned that Entropy is a tether. Coherence in any medium—be it a computer program, a legal contract, or a strand of DNA—depends on maintaining a specific "tension" between randomness and order. By measuring this tension (Semantic Gravity), we can build tools that don't just "summarize," but actually "optimize" the flow of information between humans, AIs, and nature. ACCOMPLISHMENTS THAT WE'RE PROUD OF
- Universal Invariant Validation: We successfully demonstrated that a proprietary information-density metric—our measure of semantic tension—remains statistically invariant across both classical literary structures and specific complex regions of the human genome.
- The "Skeleton" Effect: Discovering that "skeletonized" prompts (removed of filler) not only save tokens but often yield more accurate responses from LLMs because the signal-to-noise ratio is higher.
- Indigenous Language Support: Building a deterministic IGT (Interlinear Glossed Text) extractor that respects the structural integrity of Indigenous languages during AI processing.
WHAT WE LEARNED We learned that Entropy is a tether. Coherence in any medium—be it a computer program, a legal contract, or a strand of DNA—depends on maintaining a specific "tension" between randomness and order. By measuring this tension (Semantic Gravity), we can build tools that don't just "summarize," but actually "optimize" the flow of information between humans, AIs, and nature.
WHAT'S NEXT FOR LINGUISTICS PHYSICS LAB
- Clinical Integration: Moving the Genomic Lab from research-grade data to clinical SNP analysis to help identify structural precursors to rare genetic conditions.
- On-Device Physics: Moving the VSSC compression engine to run entirely on-device (via MediaPipe and Gemini Nano) for privacy-first prompt optimization.
- Universal Motif Translator: Developing a "Rosetta Stone" for structural motifs that exist across all domains—from music theory and C++ source code to mRNA sequences.
Built With
- html5
- python
- typescript
- vanilla

Log in or sign up for Devpost to join the conversation.