-
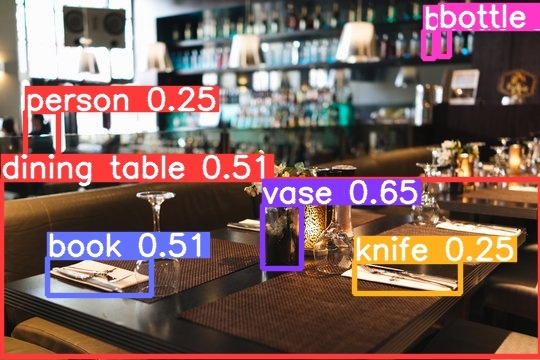
Sample labeled image with prediction certainty
-
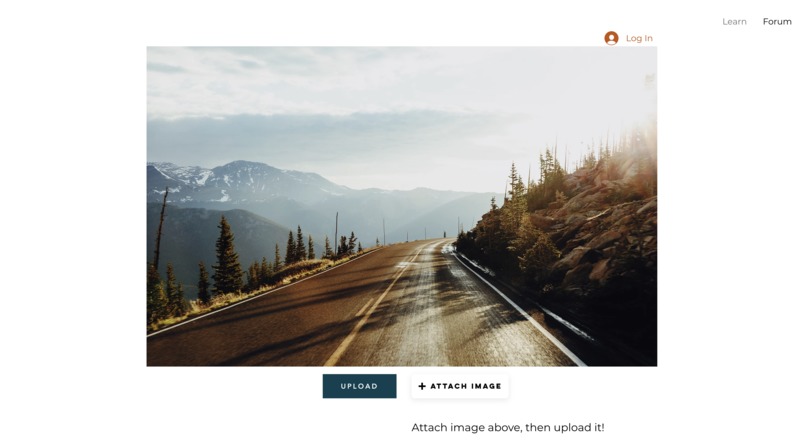
Location on website to upload photo then receive labeled image
-

I got the API webhook working, but cannot transfer images yet :(
-
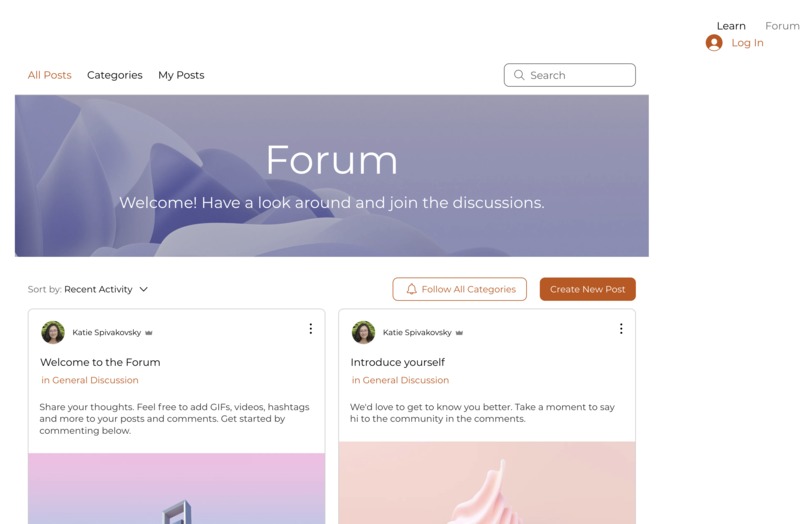
Forum for sharing ideas, discussing language-related questions, etc.
-

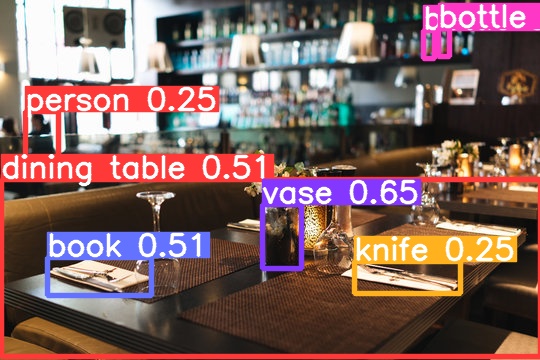
Another sample labeled image


Inspiration
Having taken a linguistics class, I learned that there are issues with traditional language-learning apps (e.g. Duolingo) which attempt to teach English by relating words in a speaker's native language with their corresponding words in English. In particular, they lack visual stimuli, which are crucial for helping many people learn English better and making the vocabulary stick. Thus, I wanted to create a tool that would help English language learners by providing them with a more visual way to learn vocabulary. This is a tool meant to supplement traditional methods for more thorough, effective language learning.
What it does
LinguiStick allows learners to take photos of the world around them, quickly upload them, and receive the same image with key objects boxed and labeled in English. This allows learners to make a visual connection between the English vocabulary and the actual objects, assisting them with memorizing vocabulary more easily and retaining it more effectively.
- Runs on the YOLOv8 image segmentation model for object detection in images
- Website built with Wix, Velo API, Javascript, and HTML
- Uses Modal API (in development) to run model on image and upload labeled image back to website
- Features a forum where users can discuss questions, bond with fellow learners, and collaboratively learn English together Independently, the model can be easily run and the website can upload images (see my GitHub repo and website links). I just need to connect the two!
Challenges and accomplishments
I have no experience with front-end development or APIs, so it was incredibly difficult for me to learn the basic usage of Wix and how to get an API running. I still don't have it completely done (specifically, I am trying to figure out how to transfer the image returned by my Modal API back into the Wix backend) but I got most of the API working, which I'm very surprised about and proud of! As of now, you can upload a photo and see it reflected back at you in the website, but I plan to get the API working so it also shows bounding boxes and labels. I am happy that I got the image segmentation model working; I have some experience with building Torch models, but none with YOLOv8 or Ultralytics, so it was difficult at first to get the model up and running. Ultimately, the model works, and the website itself is functional, but the connection between the model and website (i.e., the API) still needs some work. I'm excited to move forward with this after TreeHacks to make this an even better project!
Built With
- html
- javascript
- modal
- python
- torch
- ultralytics
- wix

Log in or sign up for Devpost to join the conversation.