-
-
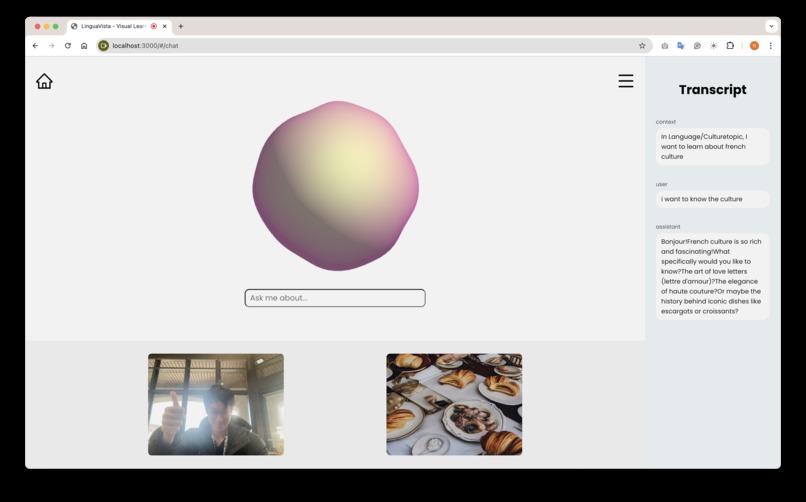
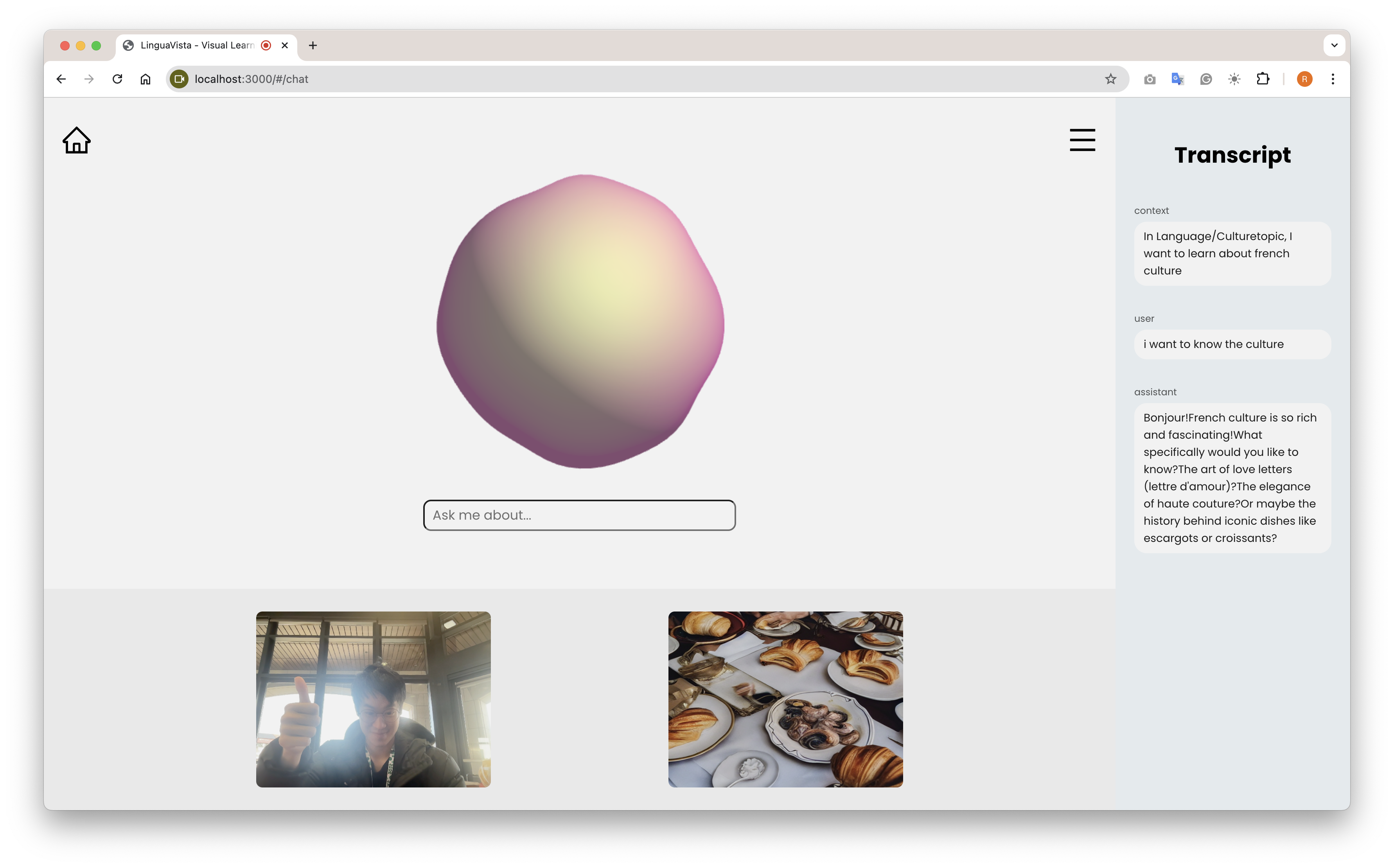
A user chatting with LinguaVista's edge AI agent about French culture
-
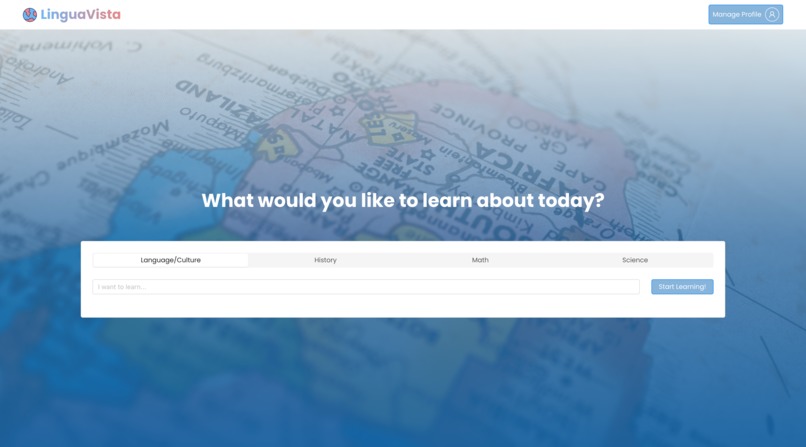
A user is greeted by the LinguaVista home page with options to select a subject to learn about
-
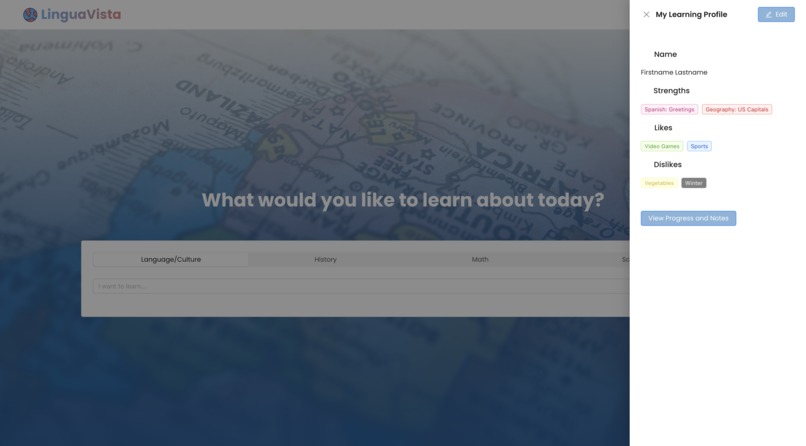
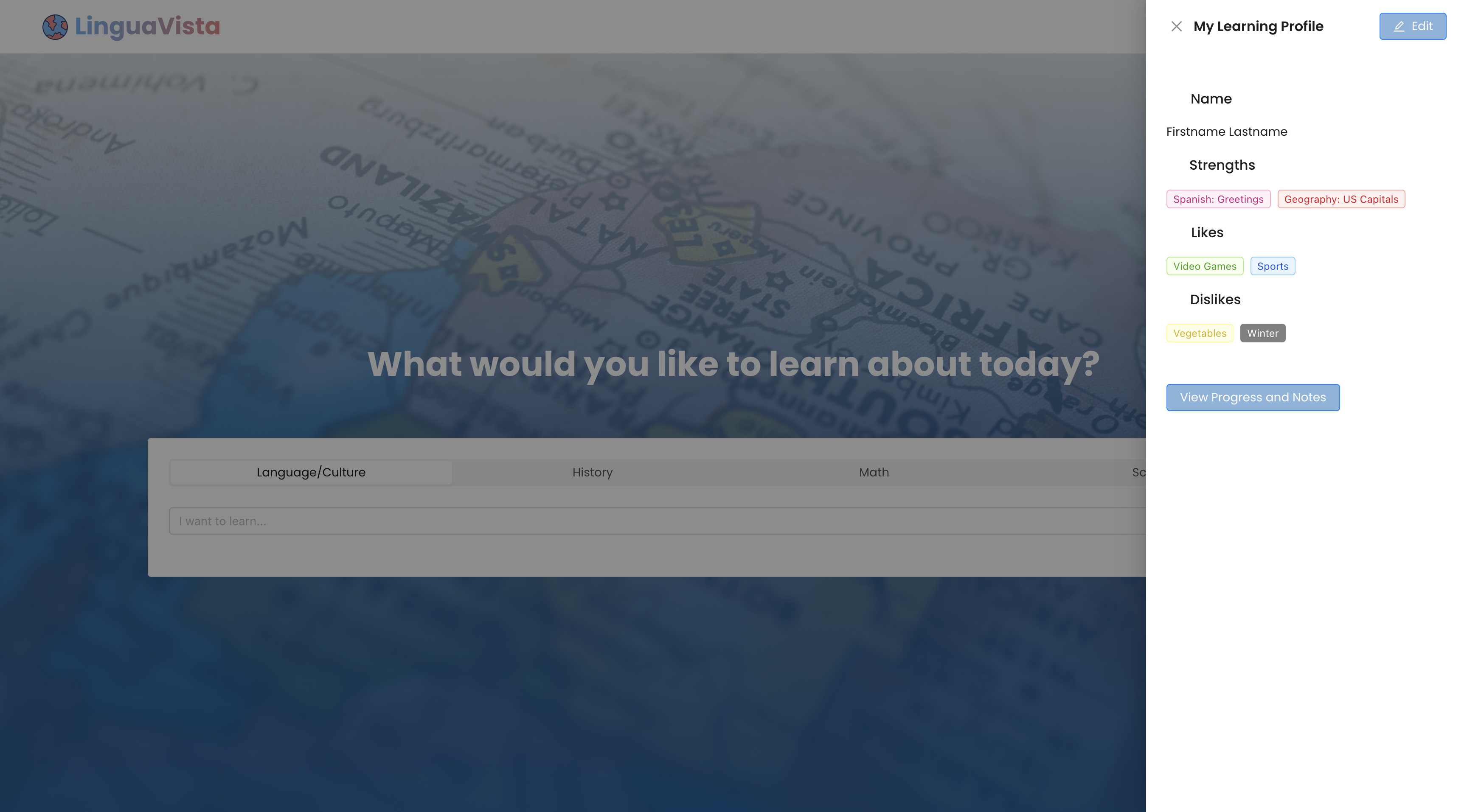
A user can customize their profile to focus on certain subjects, interests, or strengths
-
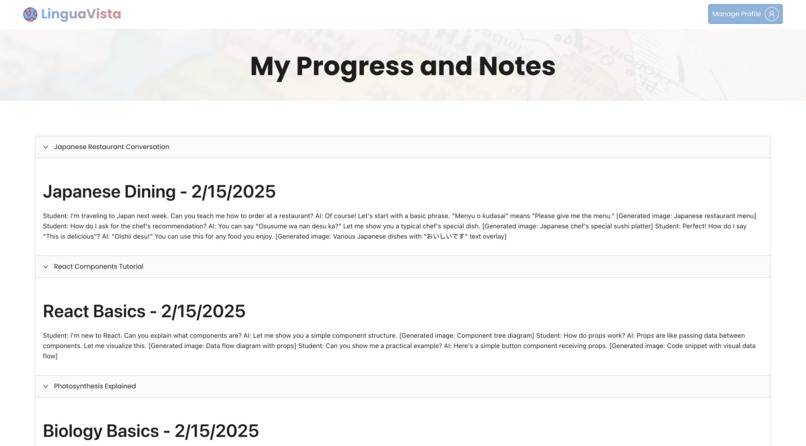
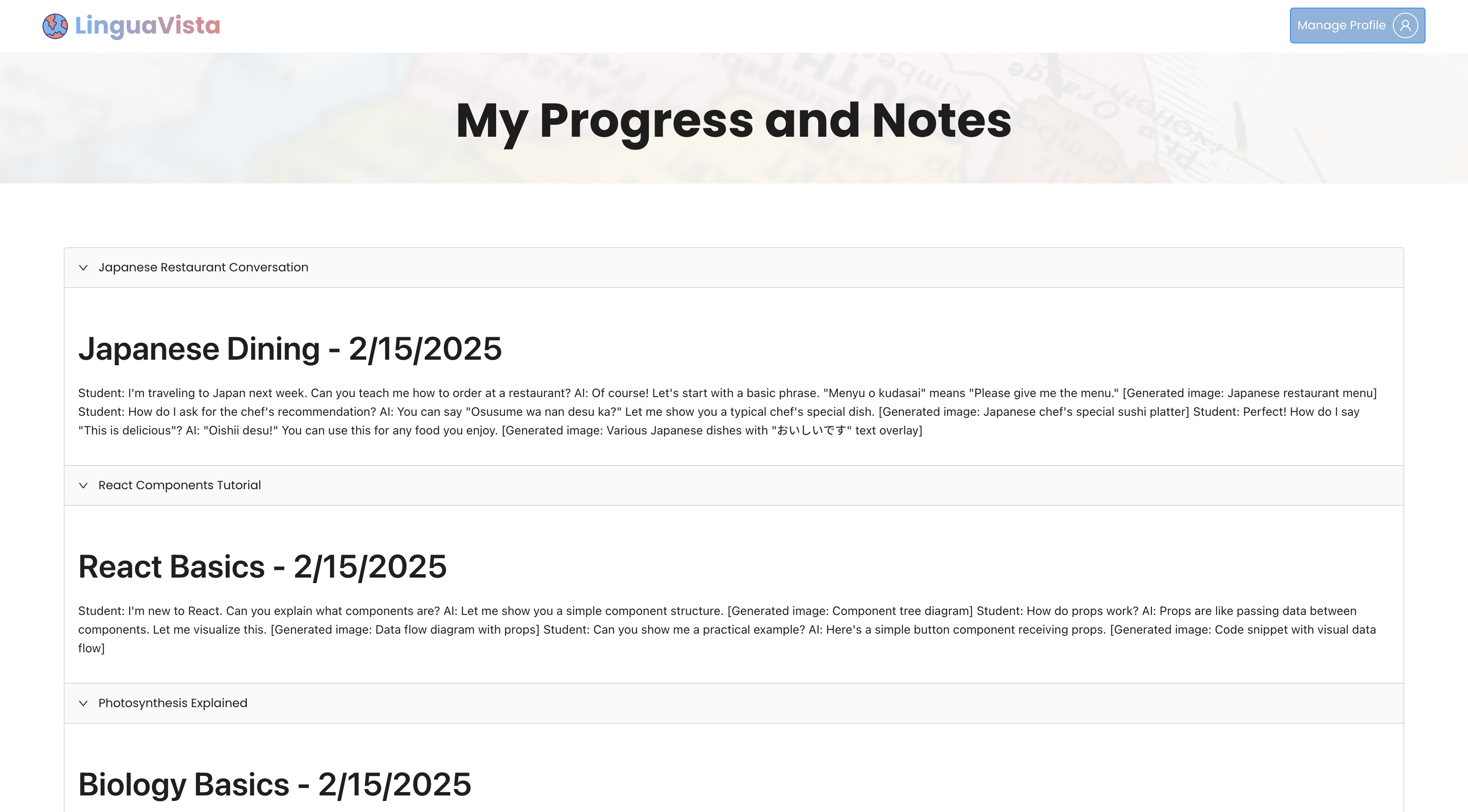
Users can view notes about their previously logged conversations so they can keep track of their learning.
-
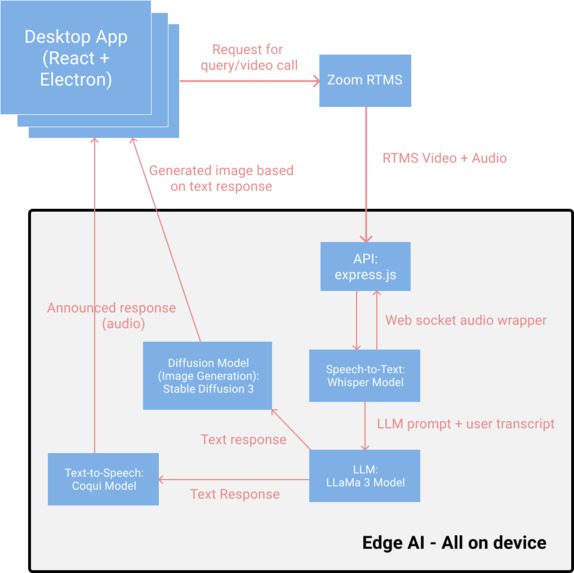
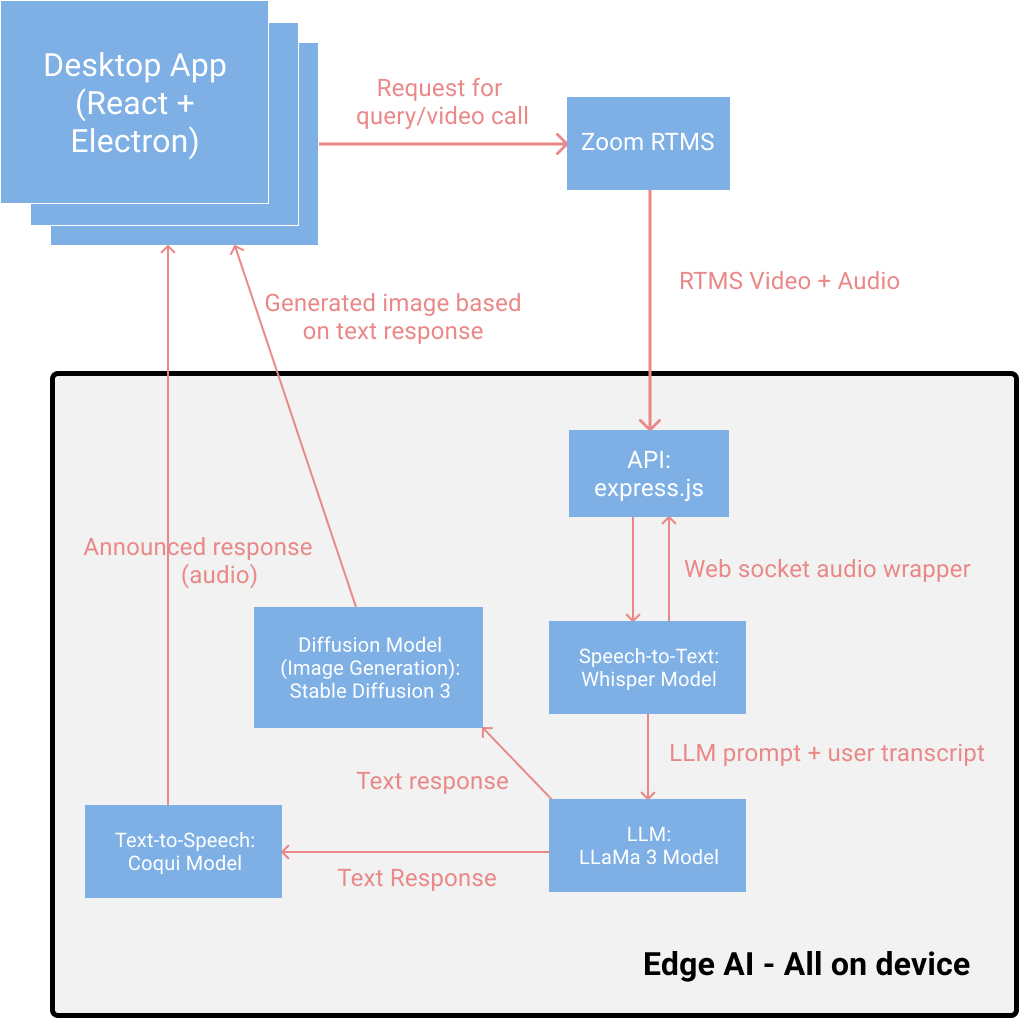
Diagram of each component of the LinguaVista app

💡 Inspiration💡
Despite a digitally-centered world that is the most connected in all of human history, many students, communities, and schools across the world still lack access to the internet. And with research as well as people claiming visual learning is beneficial for those learning complex subjects and engaging with culture, limited access to information, especially lots of visual aids and resources on the internet, makes education that relies on verbal communication challenging. The benefits of remote education tools were clearly illustrated as the world faced a global pandemic, forcing schools to push resources online, and further hurting communities that lack digital connection, and as the world continues to further become digital-centric, more solutions are needed to ensure future generations are educated no matter their location on the globe.
A US elementary school teacher known by the LinguaVista team expressed her desire for more opportunities in the classroom to show students visuals and experiences for them to learn about rich subjects like science, social studies, and language arts (English as well as other languages). She specifically cited the lack of opportunities (i.e. field trips) for elementary students to receive authentic experiences of the world, the people, and the ideas around them. She also mentioned how hard it is to implement solutions in the classroom due to certain families not being able to participate at home without access to the internet.
According to the U.S. Department of Education's Journal of Education and Practice, frameworks such as Problem-Based Learning (PBL) and Higher-Order Thinking (HOT) have demonstrated the need and effectiveness for lessons and curriculum involving visual aids. It claims "learners understand information better in the classroom when they see it...such as images, flowcharts, diagrams, video, simulations, graphs, cartoons, coloring books, slide shows/PowerPoint decks, posters, movies, games, and flash cards (Kohnke, Lucas)." This research urges the use of such resources, of which it may not be possible for educational institutions to implement, either due to technical complexity, limited budgets, or other reasons. And if the research claims visual aids work in the classroom, it can be assumed for individuals wanting to learn subjects individually, information is better obtained visually for them as well. To solve this divide between the need for global education and the many populations without connectivity, a solution requires other forms of technology to bridge the resource gap. With the rise and improvement of generative artificial intelligence performance and accuracy, the idea of placing models on bare metal or on physical devices enables the ability to create a source of knowledge offline from network connectivity, including image generation and two-way conversation between a person and an AI model.
Our team was inspired to create LinguaVista to maximize the adoption of digital, visual, and experiential learning tools across the world via the breakthrough technology of Edge AI. LinguaVista ensures no internet connection is required to learn more about our complex world, including ways to enjoy powerful conversations about subject matter.
⚙️ What it does ⚙️
LinguaVista connects people with experiences and conversation through an all-in-one Edge AI application. Users select a subject, search for a concept they are curious about—such as a new language, culture, geography, or scientific idea—and connect with one of three options: a real person fluent in the language, an expert available online, or a generative text-to-speech and image AI model hosted on their device, which operates completely offline and independently of external services. Users can have conversations with either type of interaction, either to practice language fluency or learn more about their subject and then conclude them with AI summaries, generated visuals matching the conversation, and saved conversation notes to their profile.
🏗️ How we built it 🏗️
🟣 Edge AI 🟣
LinguaVista boasts the ability to utilize AI all on the local application–no internet necessary–thanks to Edge AI. Our stack includes a Whisper model that transcribes spoken input into text. This text is then processed by a LLaMa3 model, which generates accurate and contextually relevant responses. To enhance user experience, a Coqui model converts these responses back into speech, enabling a fluid and natural conversation. Additionally, Stable Diffusion 3 generates AI-powered visuals that complement discussions, reinforcing learning through visual representation. By combining speech, text, and image generation, LinguaVista ensures a highly engaging and effective AI-driven educational platform, all while maintaining the capability to function offline and independently of external services.
🔴 Zoom 🔴
LinguaVista integrates Zoom's SDK to facilitate seamless video and audio communication, enhancing its AI-driven conversational learning experience. After a user initiates a query, a chat interface powered by Zoom enables real-time, two-way interaction with the AI. The platform leverages Zoom’s RTMS server to process incoming audio and video packets, which is utilized by the AI stack to generate feedback to the user providing an interactive and engaging user experience.
⚫ Education ⚫
LinguaVista’s ability to operate as a standalone desktop application through Electron and React make it an exceptionally accessible and inclusive educational tool, aligning with its mission to provide knowledge and learning opportunities to individuals without reliable internet access. ensures that users can engage in interactive conversations, speech-based learning, and visual-enhanced education without depending on external or cloud-based services. This independence from the internet makes LinguaVista an ideal solution for rural communities, remote learners, and individuals in low-connectivity regions, empowering users with high-quality, AI-driven education anytime, anywhere.
🚩 Challenges we ran into
- As a team with lots of diverse ideas, tech interests, and perspectives, we took a lot of time to thoroughly iterate our idea to include the features we wanted. While this choice matured our idea, it may have led to us losing prototyping time.
- Within our application, lots of technology is involved because of our complex scope. From multiple AI models processing speech and returning reasoned information, to various APIs communicating data back and forth, not to mention all of these modules are running on the same device, we had lots of difficulty ensuring each piece lined up correctly through integration. Additionally these AI models have to run optimally to ensure performance and accuracy are held to good standard on the user's device
- Our stack is large, and with a large stack comes LOTS of mix-matched dependencies…
- Zoom RTMS is not fully prepared as a feature, so we were forced to work around a prototype version which limited the scope of our goals to utilize Zoom API. A fully released version of Zoom RTMS would allow us to easily match like minded users to chat with each other in addition to the option of chatting with our AI.
🥇 Accomplishments that we're proud of
- We've had great collaboration with Zoom and Liquid AI sponsors while trying to pull off this idea. From interfacing with Zoom's emerging SDK technology and working with their team on our unique use case, to getting feedback from Liquid on our application of Edge AI technology to solve a large problem, both companies we're excited to hear about our progress!
- We have working components of our MVP, including a robust user interface that works offline on desktop in addition to the browser, models to parse Zoom video and audio data into prompts for reasoning, and finally outputs to the user displaying conversation, relevant images, and more!
- We took a simple idea at first and scaled it to lots of innovative tracks with a global problem and pulled off parts of a solution in a short time!
- We enjoyed collaborating with each other, having all been from different places and meeting for this first time while at TreeHacks
📚 What we learned
- What kinds of needs or pain points exist in the education world and how technology can solve them
- What kinds of applications Edge AI can be useful in to solve problems
- How to integrate lots of technology with each other effectively to create a large yet useful and scalable app
- How to collaborate on a team with diverse skill sets, backgrounds, preferences, and perspectives
- How to manage time effectively and prioritize tasks and features given the complexity of each piece of our project (sacrifices had to be made at each step along the way).
- How to focus on the USER'S need before our own desires of what features we want to build (it's a tricky lesson to learn)
⏳ What's next for LinguaVista?
We want to grow our user base and eventually support the ability for real people to chat with other real people! Another effective way to learn is by experimenting, such as practicing a language with a fluent speaker, asking experts questions, and having real conversations with great people. And what more effective way to learn than from someone in the place in question or with knowledge on the subject. Our mission for LinguaVista is to connect the world in ways not initially thought could be possible by the tech world, and with the opportunities in communication technology and Edge AI, we can leverage these incredible computing feats to educate our world for decades to come.
Sources
Kohnke, Lucas. "Edmodo: A Tool for Language Teaching and Learning." TESL-EJ, vol. 20, no. 3, Nov. 2016, pp. 1-8. ERIC, https://files.eric.ed.gov/fulltext/EJ1112894.pdf.
Built With
- coquitts
- electron
- express.js
- insanely-fast-whisper
- llama3
- ollama
- python
- react
- stablediffusion3
- typescript
- zoomrtms





Log in or sign up for Devpost to join the conversation.