Inspiration
I was frustrated by two things: the "Snippet Shuffle" (copy-pasting small chunks of code losing context) and opaque AI reasoning. Most models act like "Black Boxes"—you set a parameter and hope for the best, without knowing how "thinking harder" actually affects the output.
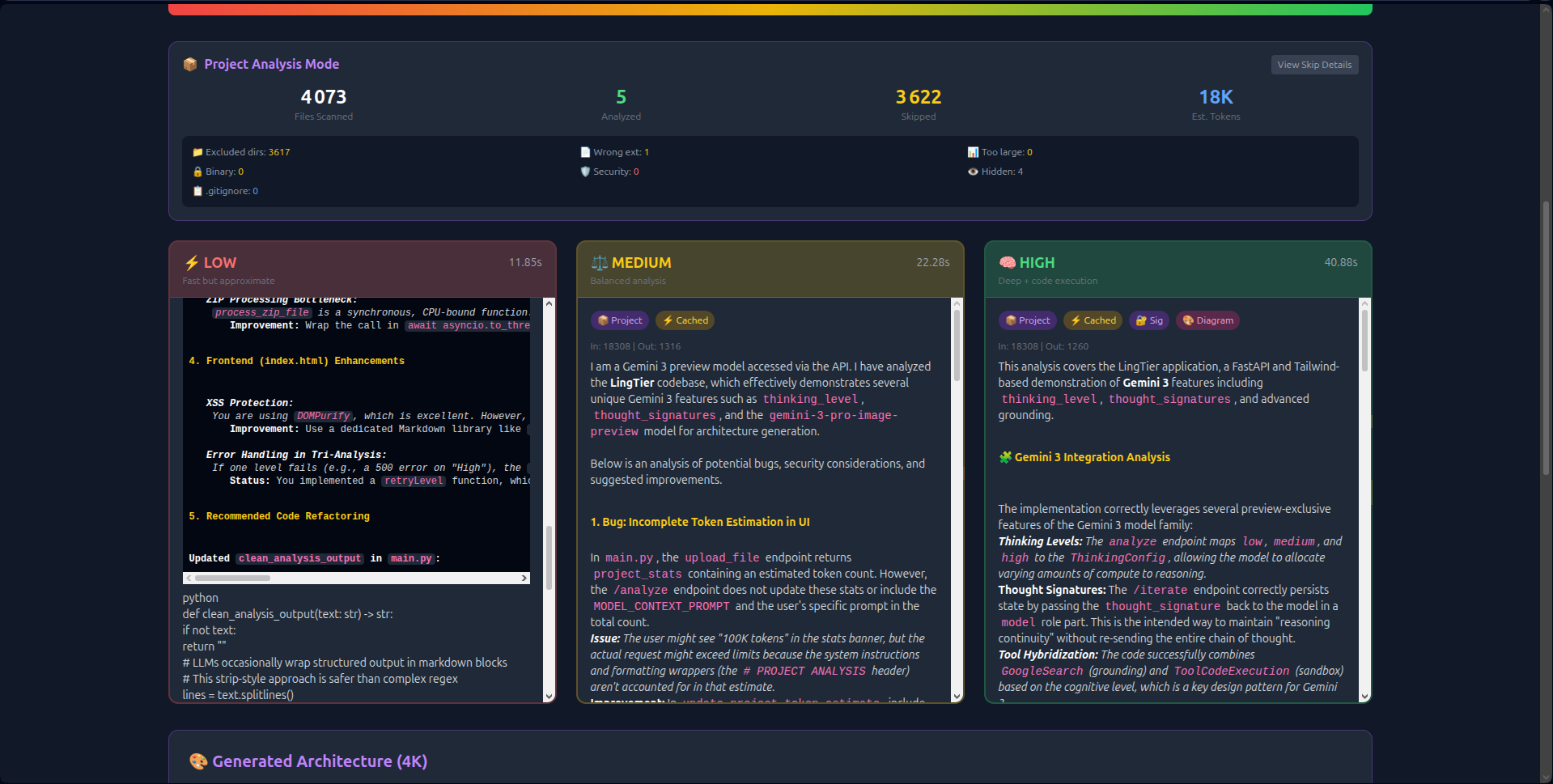
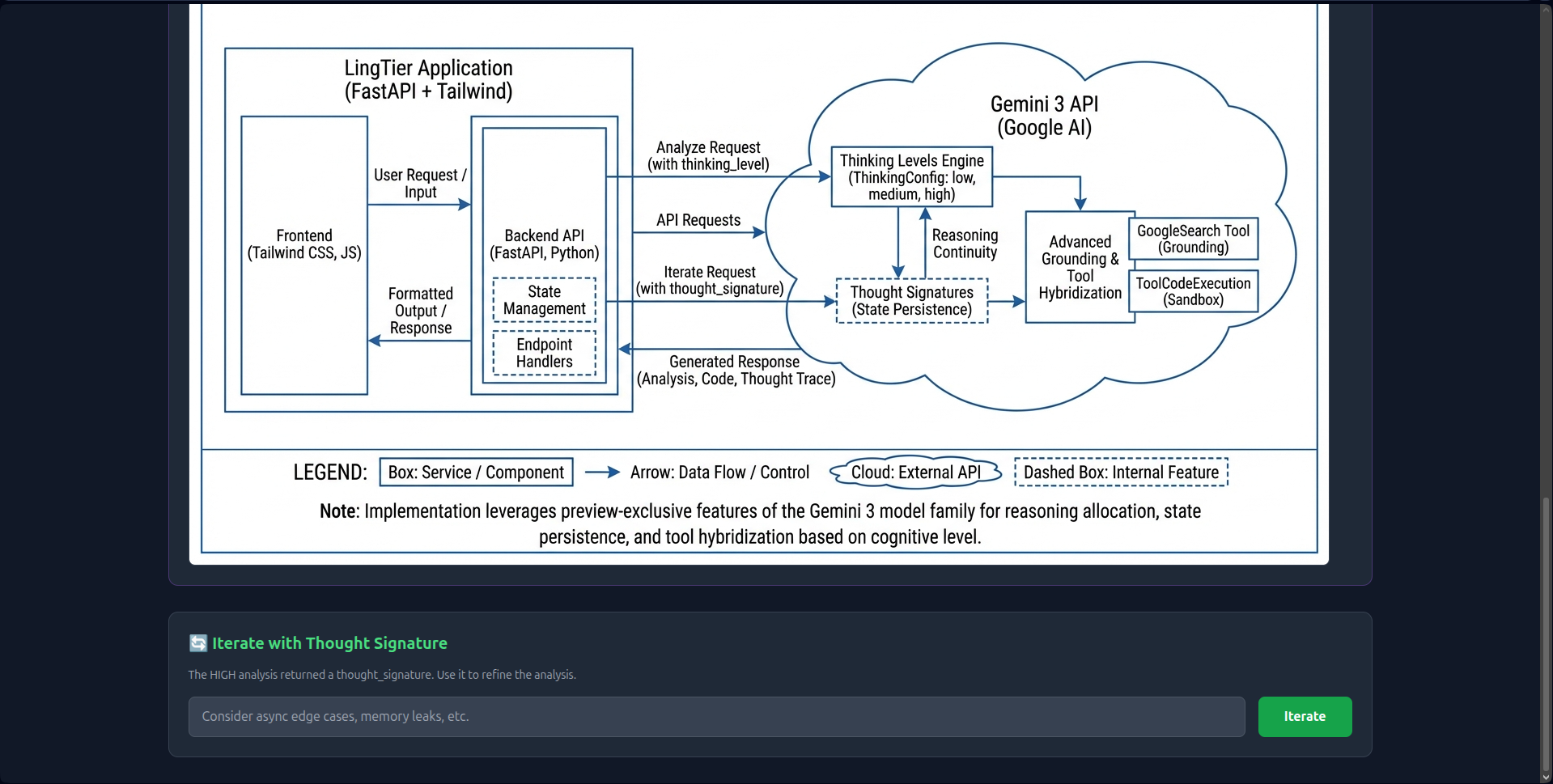
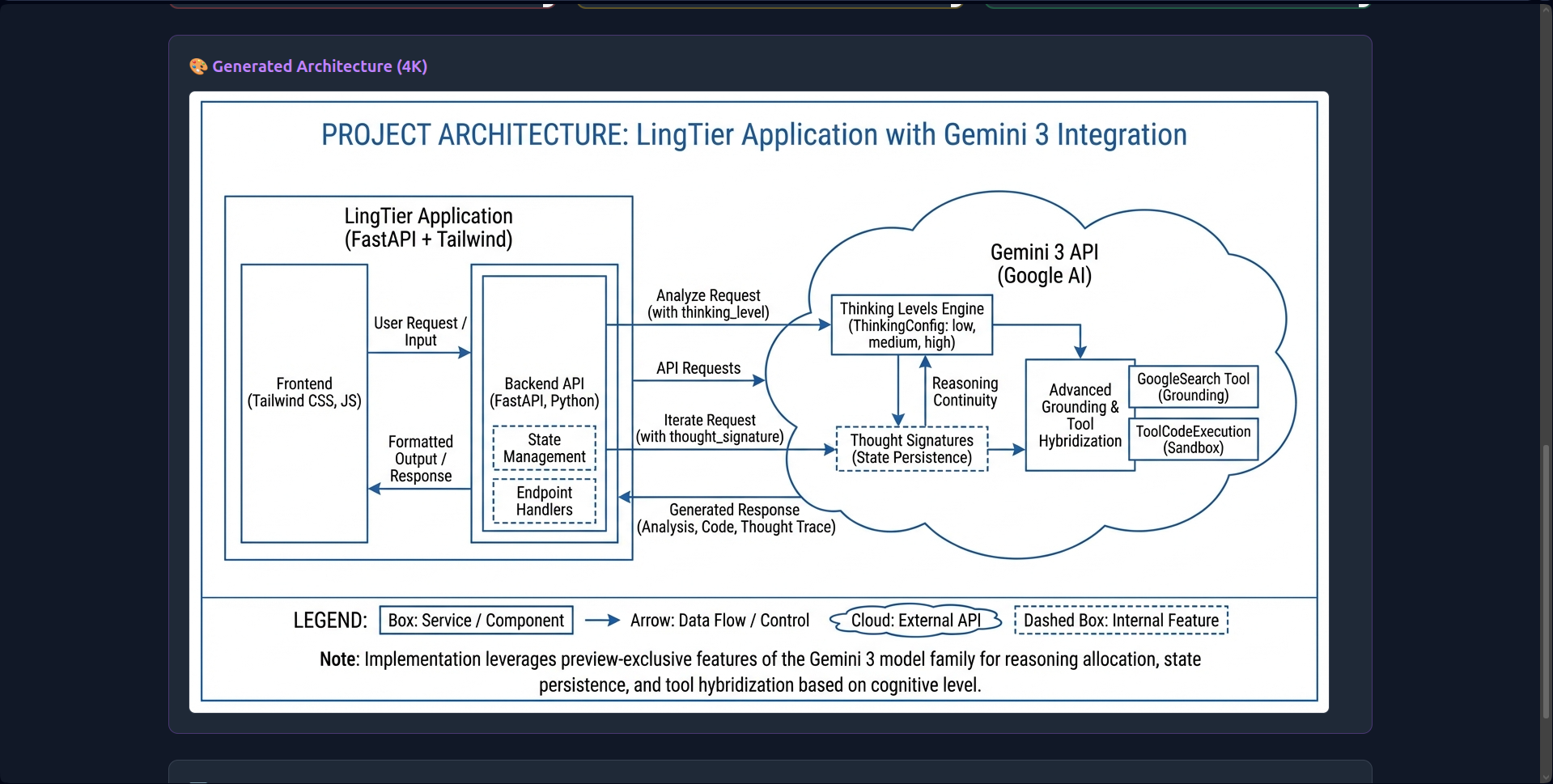
I wanted to build a tool that acts like a Senior Lead Developer. I realized that with Gemini 3’s 1M token context and thinking_level controls, I could build the first interface that makes cognitive load tangible: visualizing three parallel analyses (Low, Medium, High) to show exactly how deep reasoning transforms architectural insight.
What it does
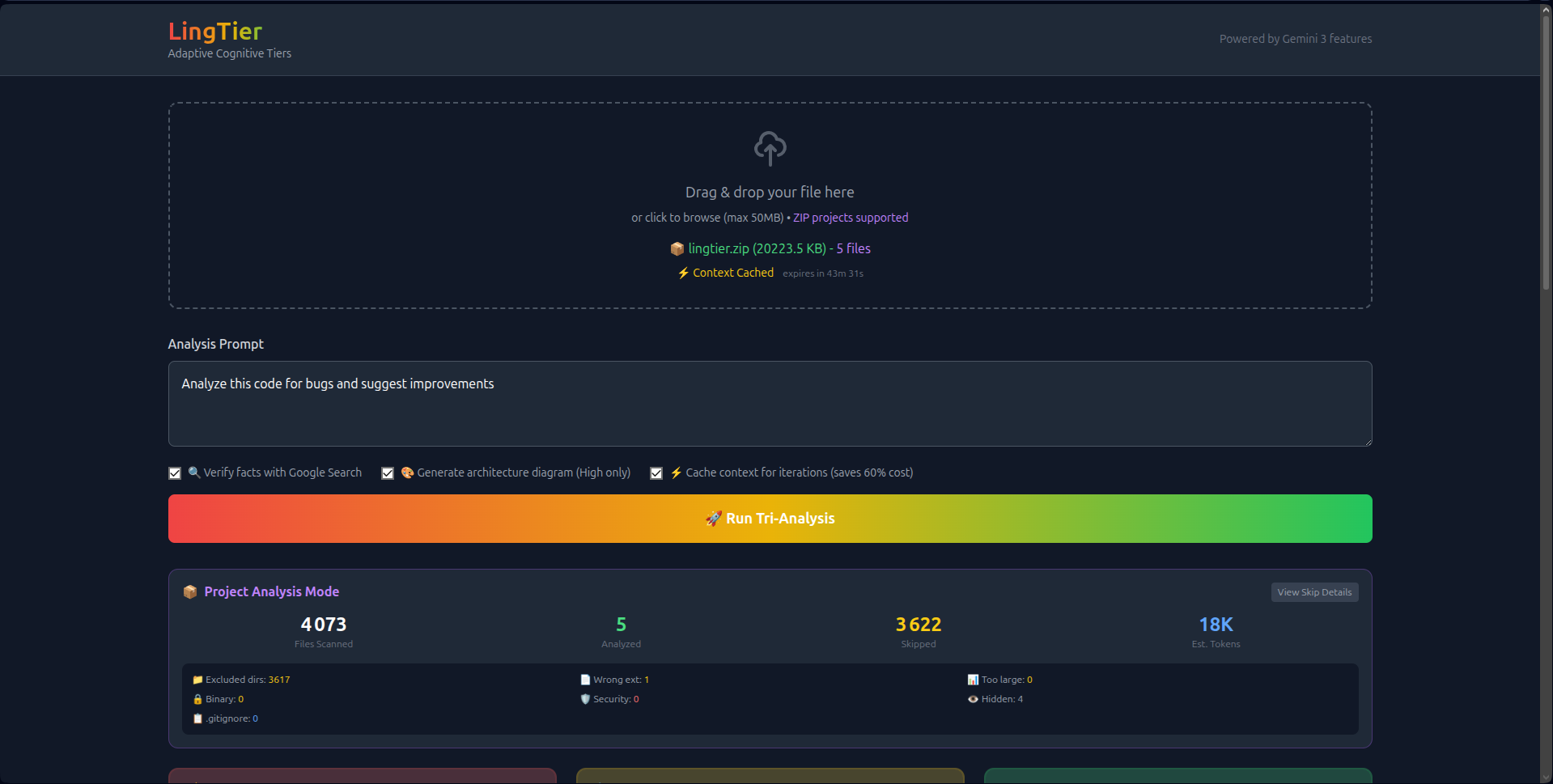
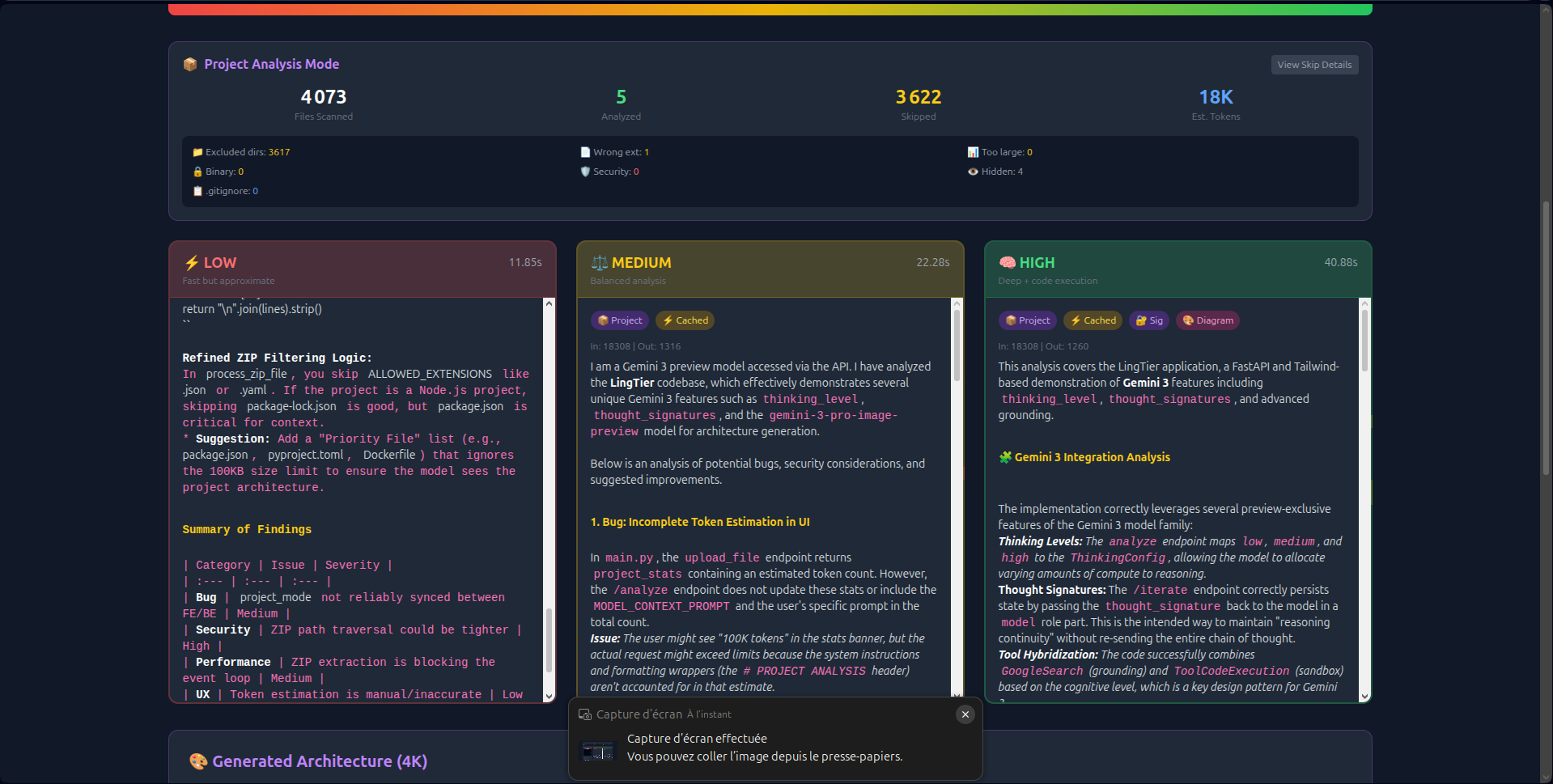
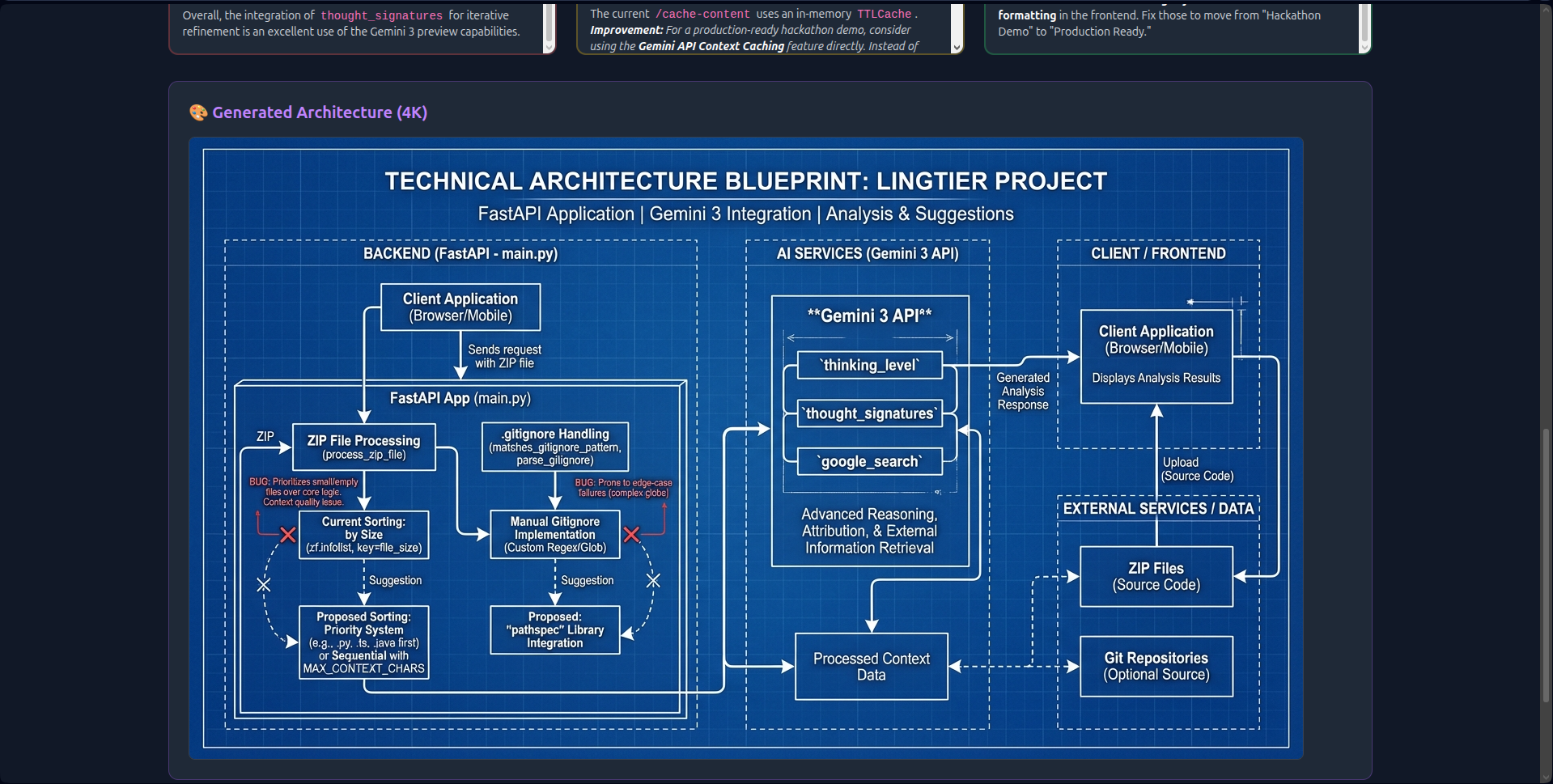
LingTier is a real-time comparative analysis engine. It allows users to upload any file type (single scripts, PDFs, images) or full project ZIPs (up to 50MB).
It exposes reasoning control through a comparative interface:
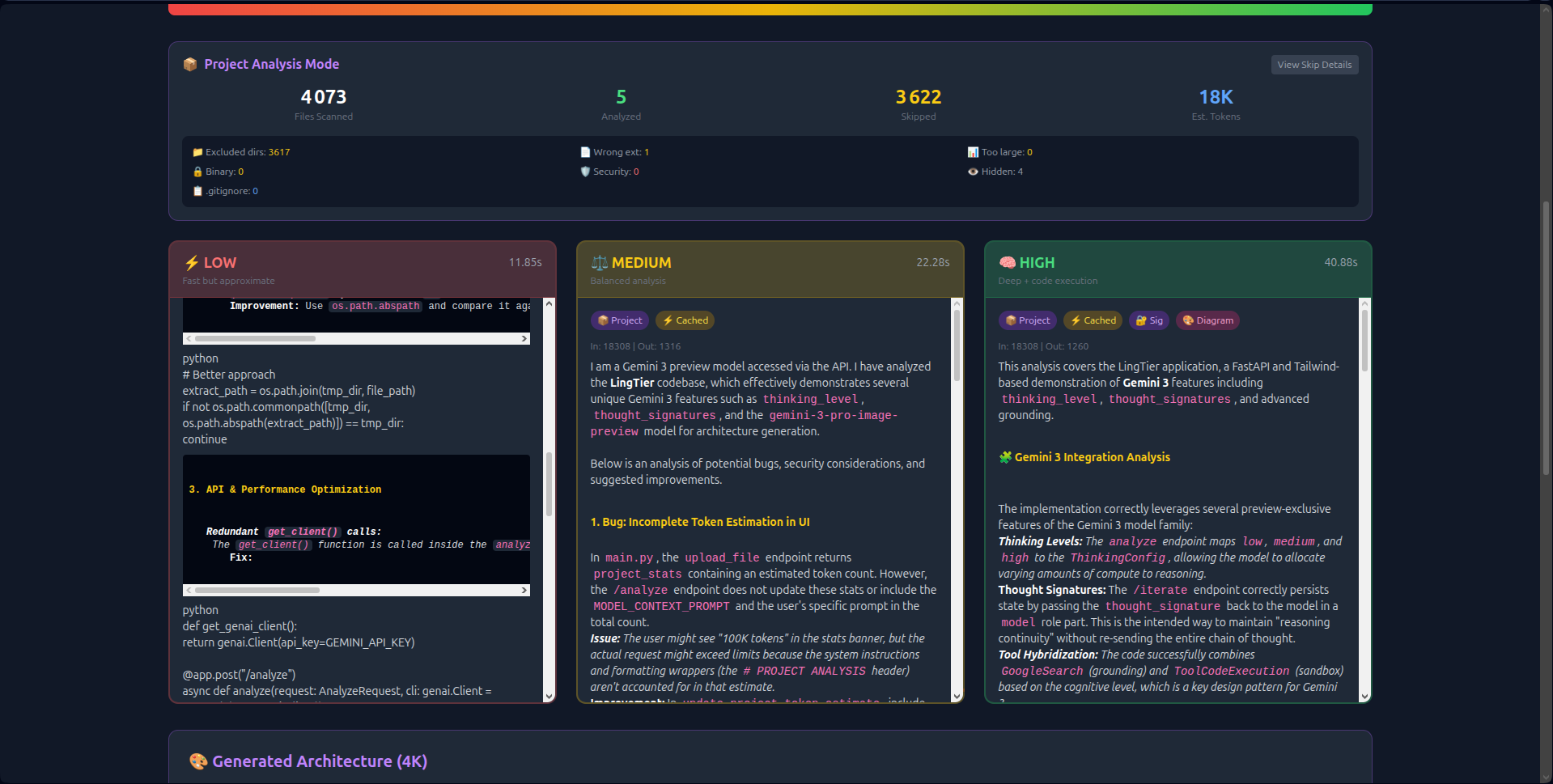
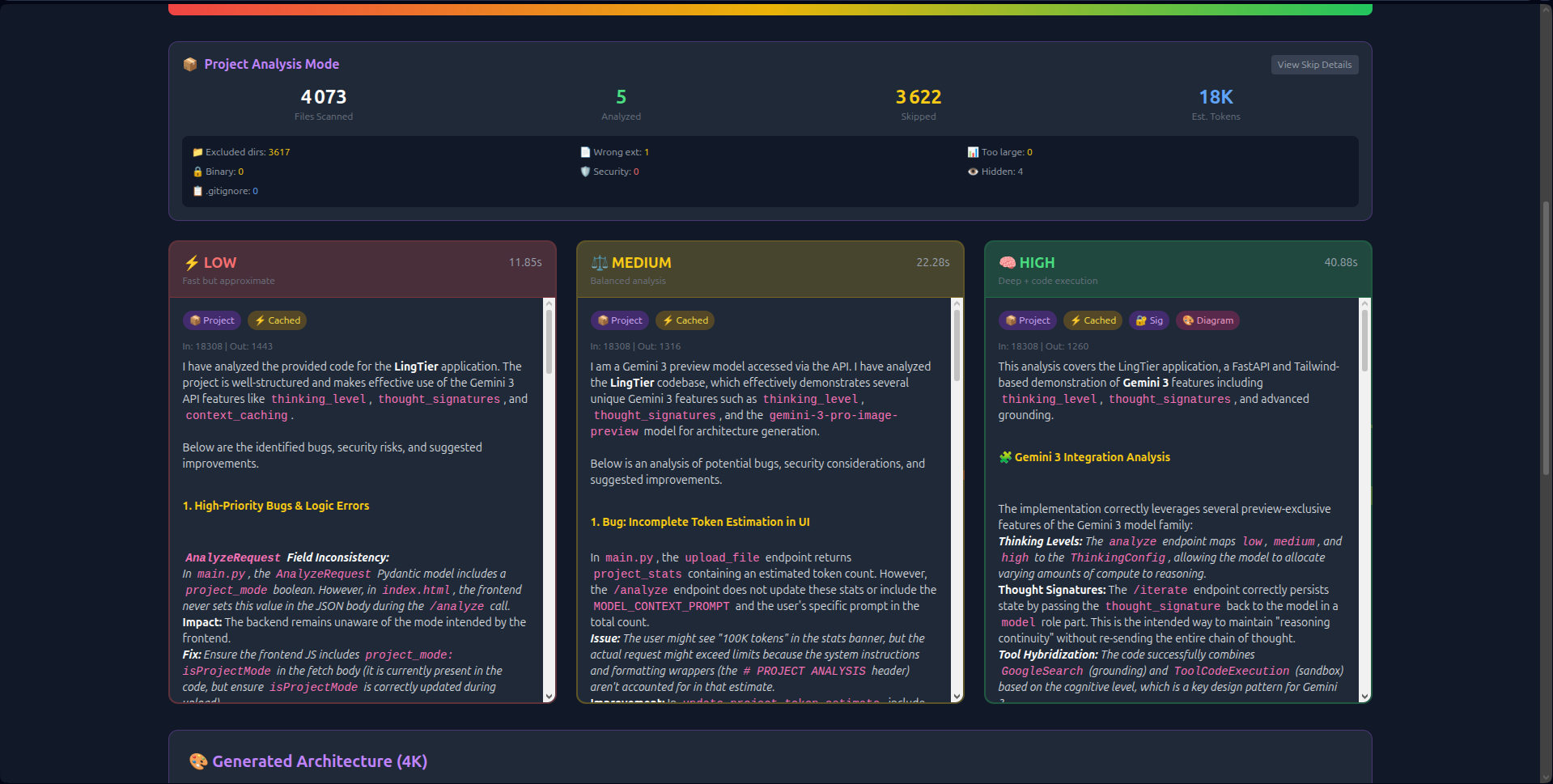
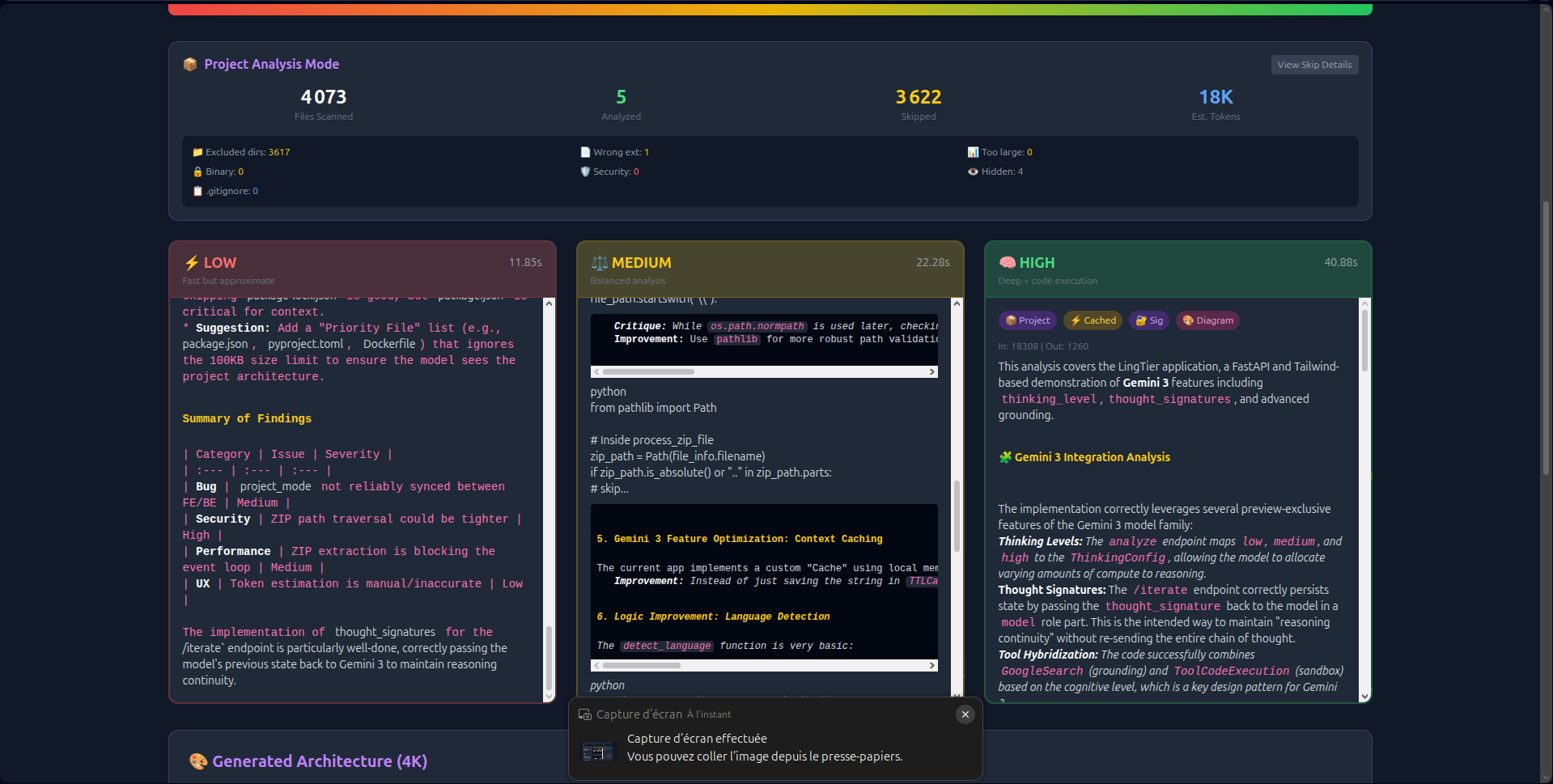
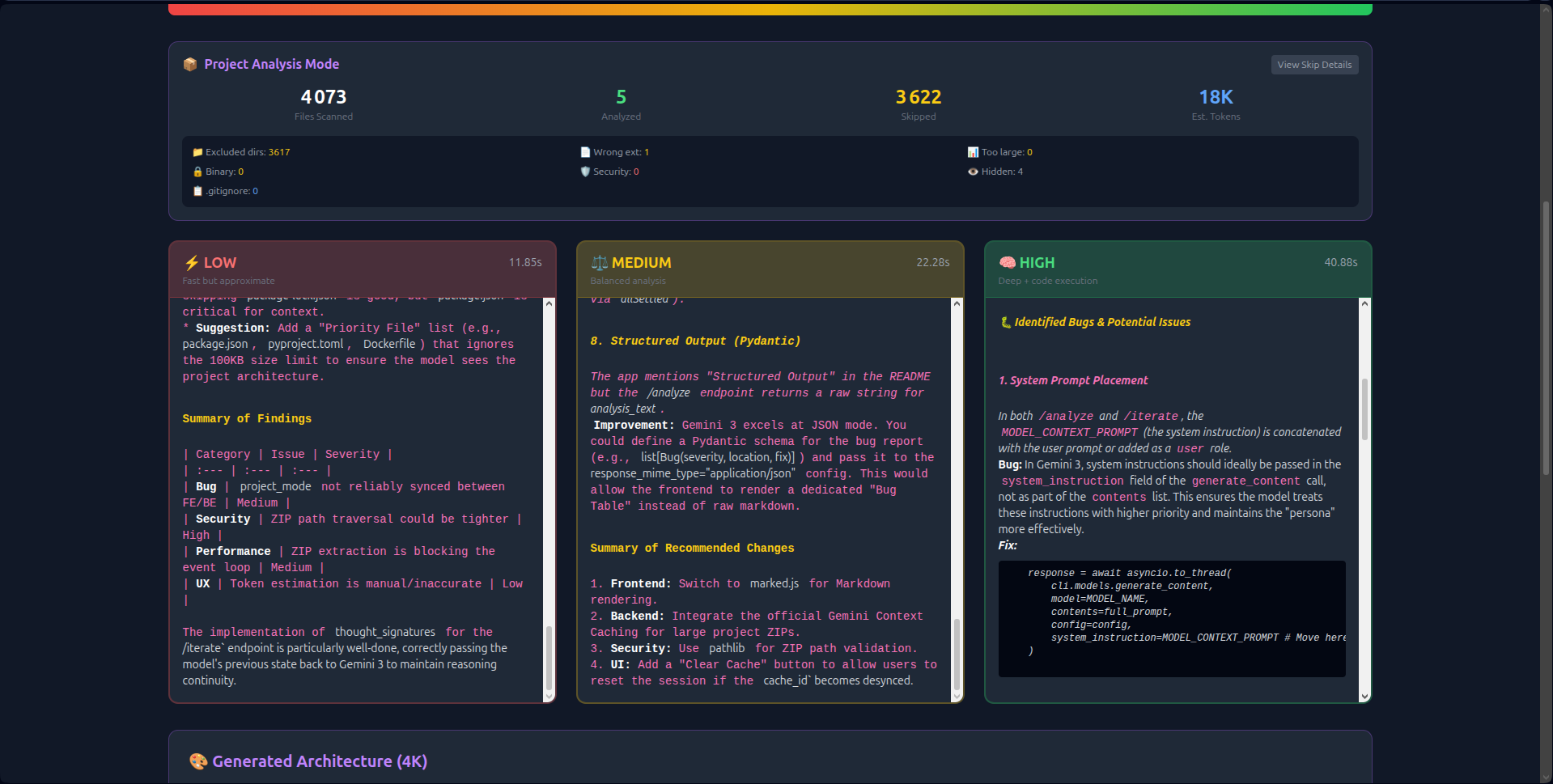
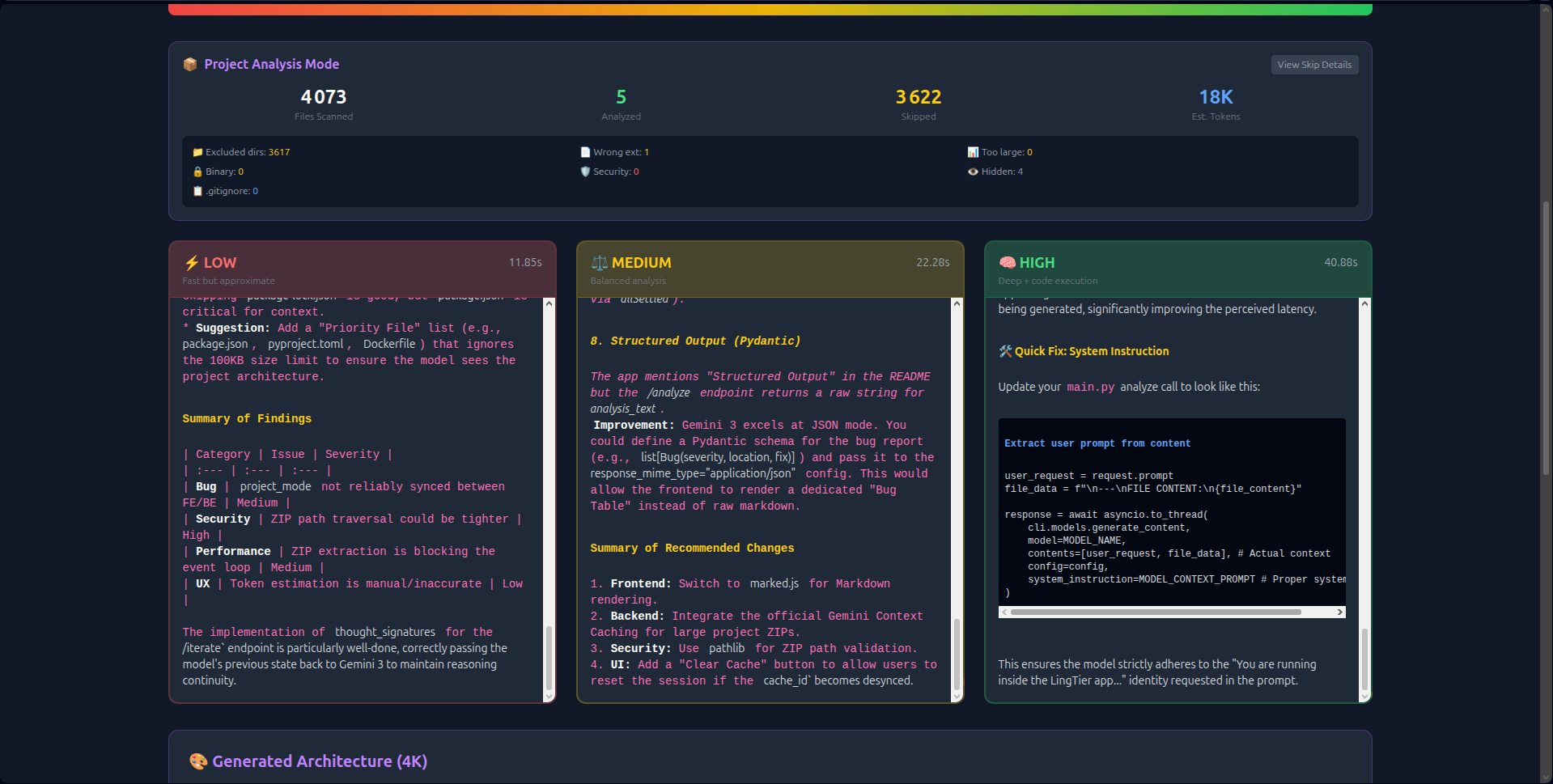
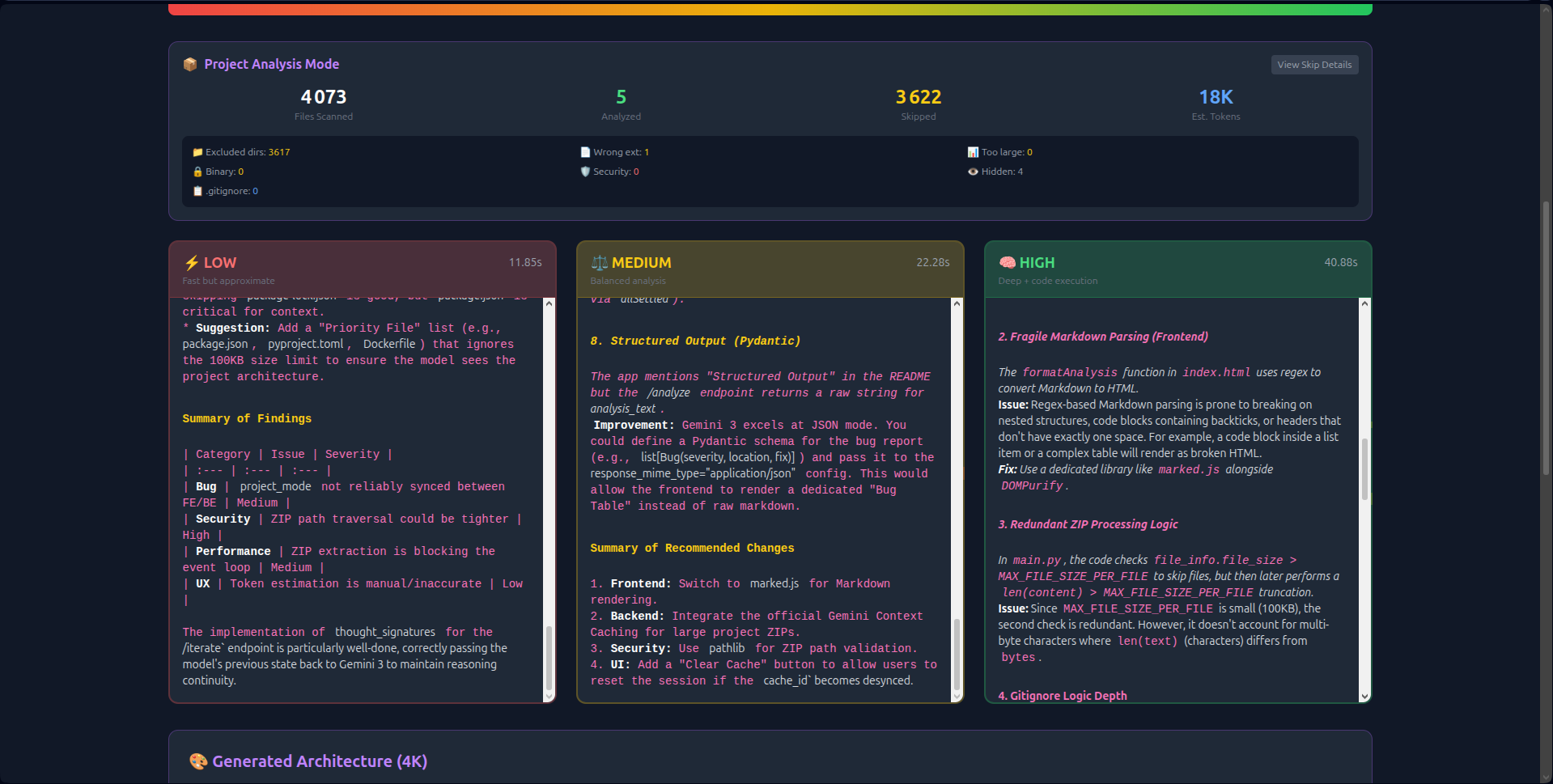
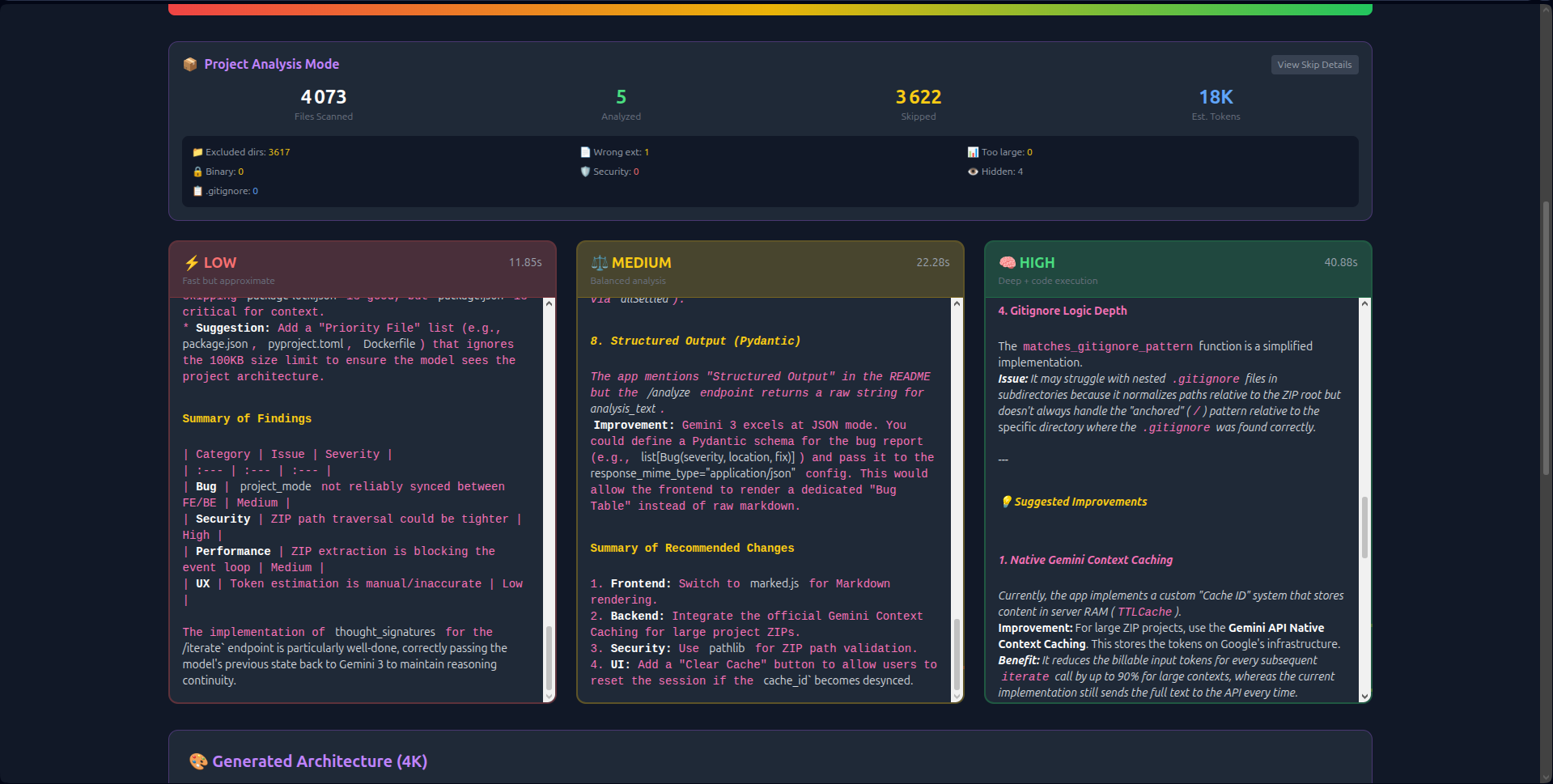
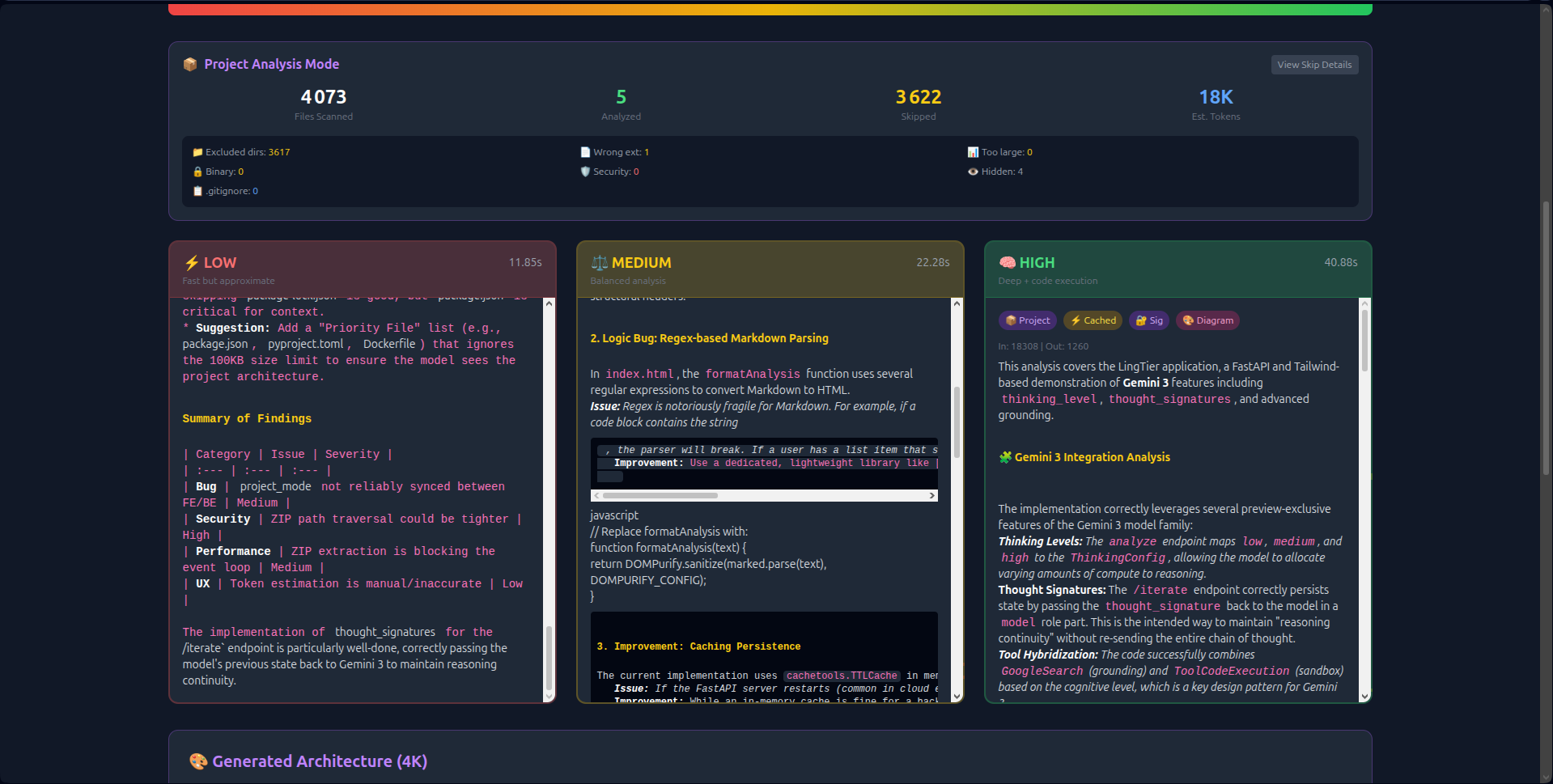
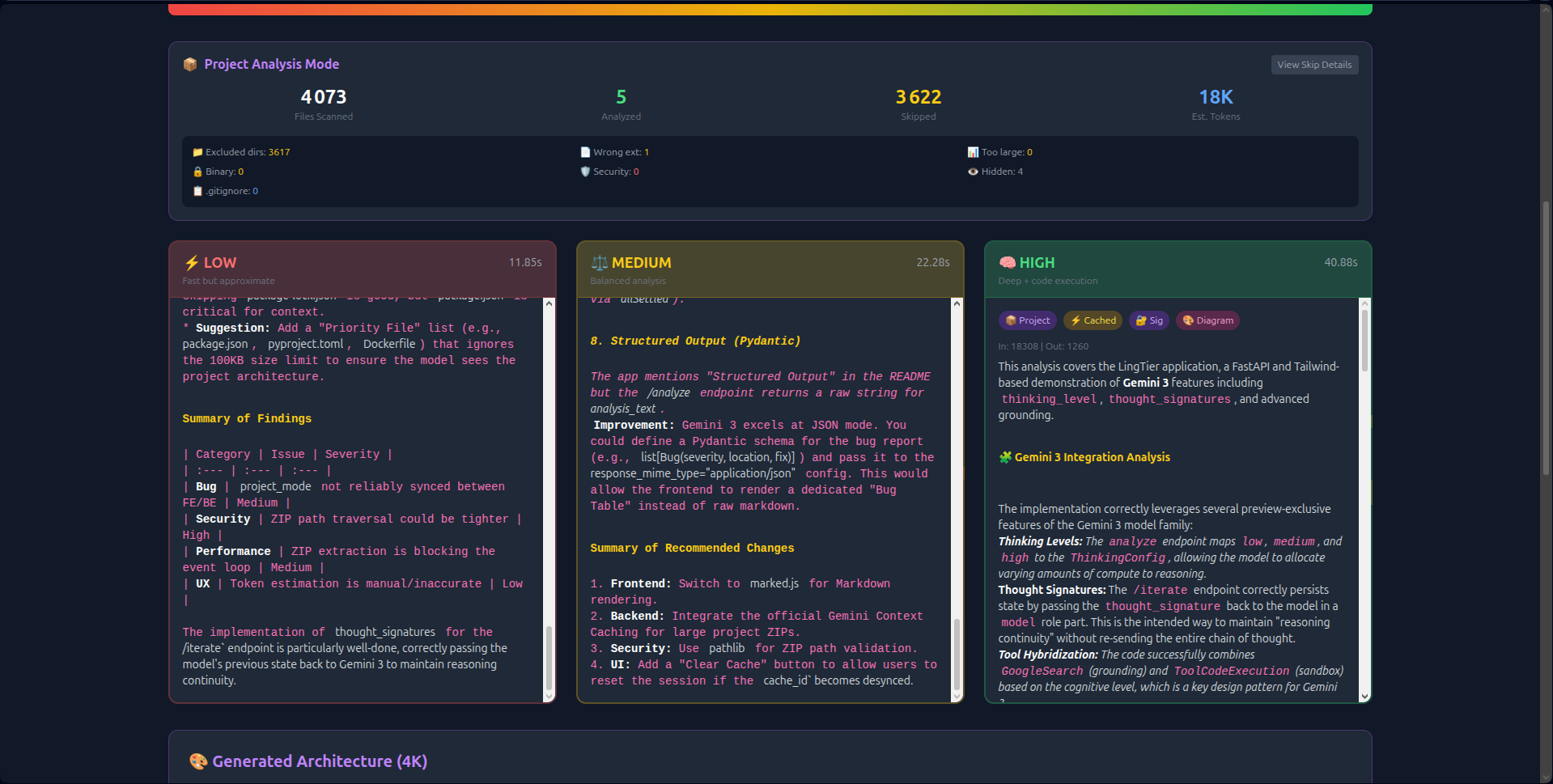
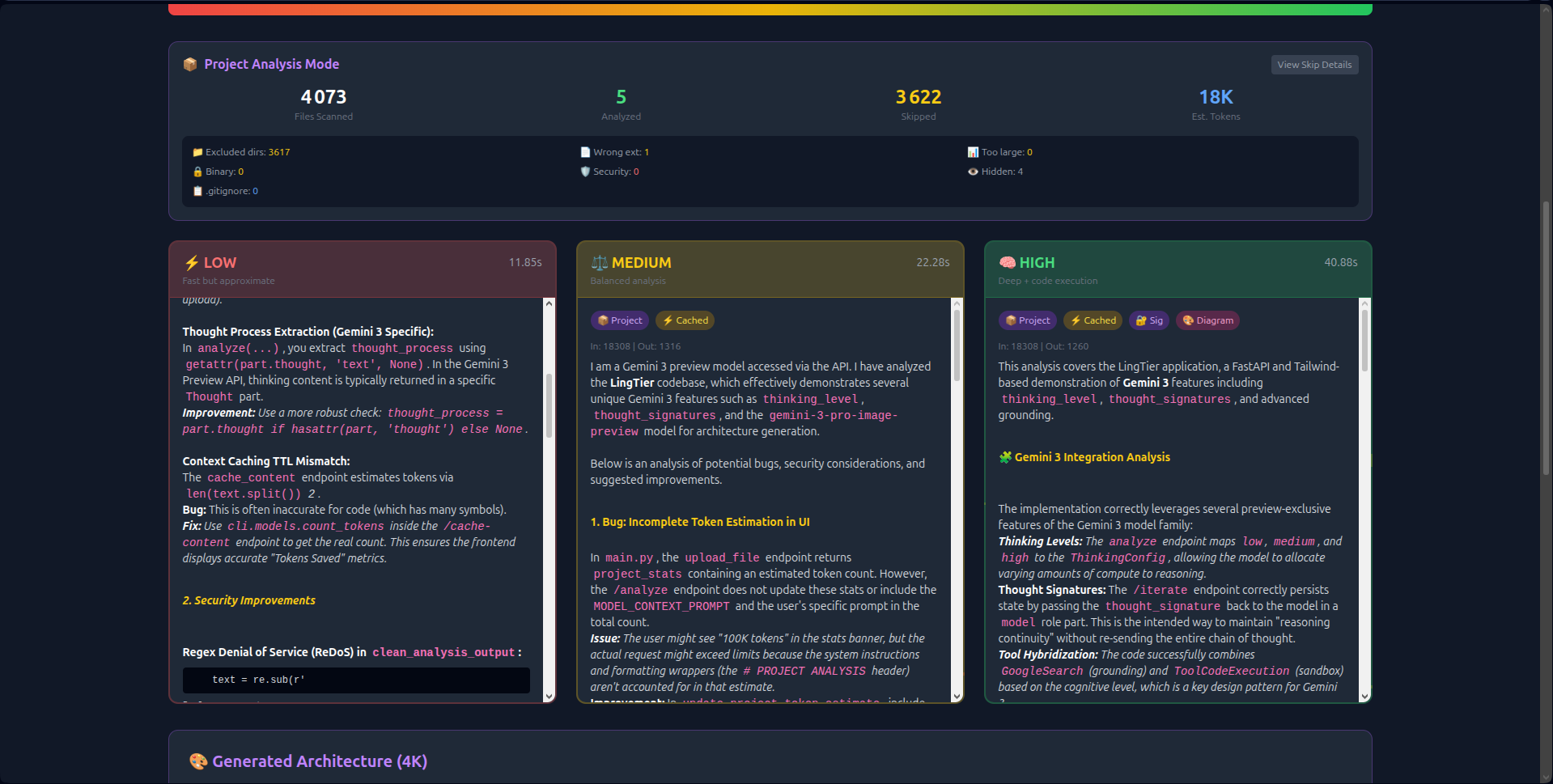
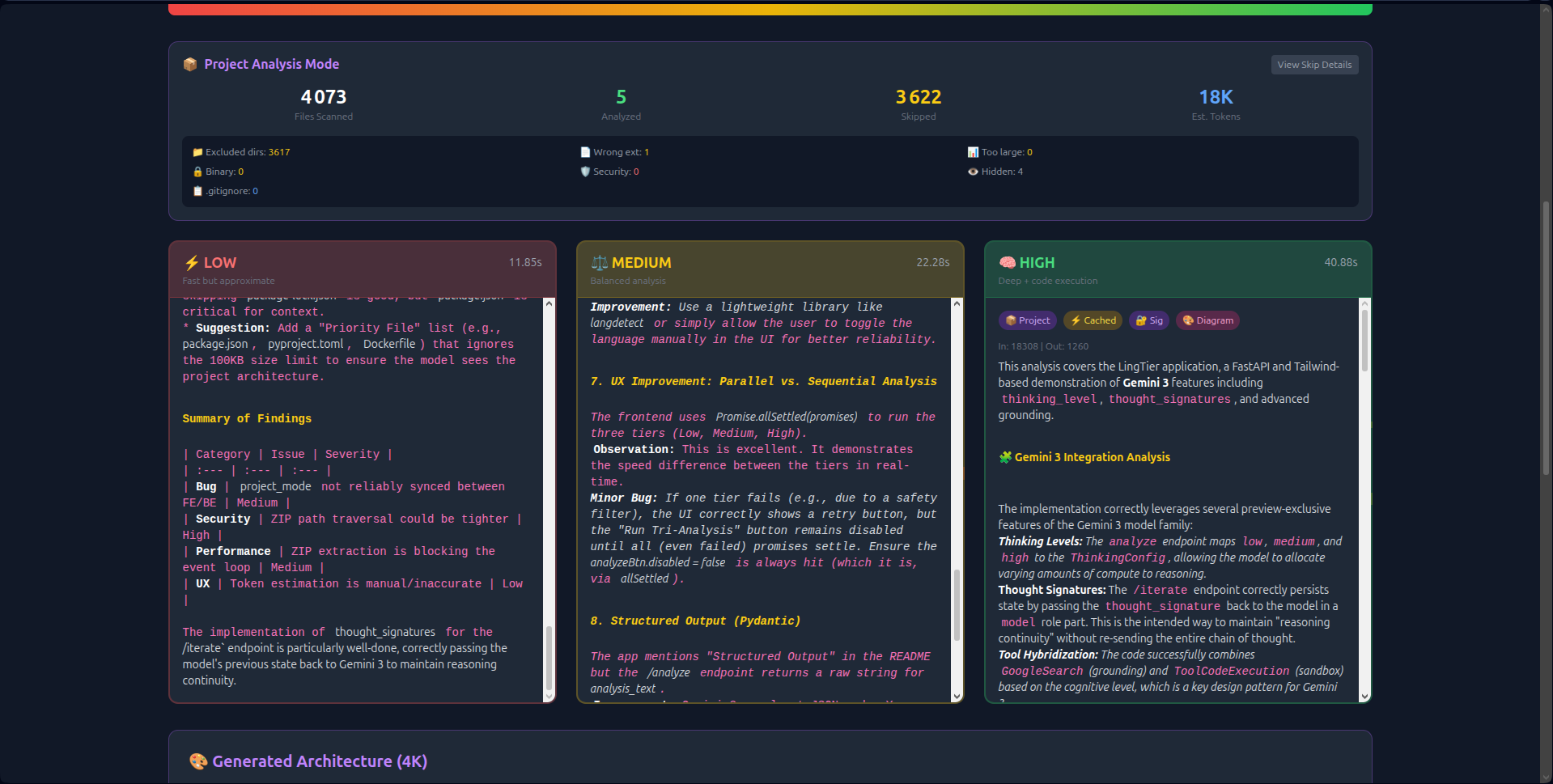
- Visual Thinking Tiers: Unlike hidden API parameters, LingTier runs Low (2s), Medium (8s), and High (18s) analyses simultaneously side-by-side. Users see the latency/quality trade-off in real-time.
- 1M Context Ingestion: Instead of chunking data, LingTier ingests the entire 50MB context in one shot. This allows it to detect cross-file dependencies and circular imports that smaller windows miss.
- Thought Signatures: I utilized Gemini 3’s cryptographic
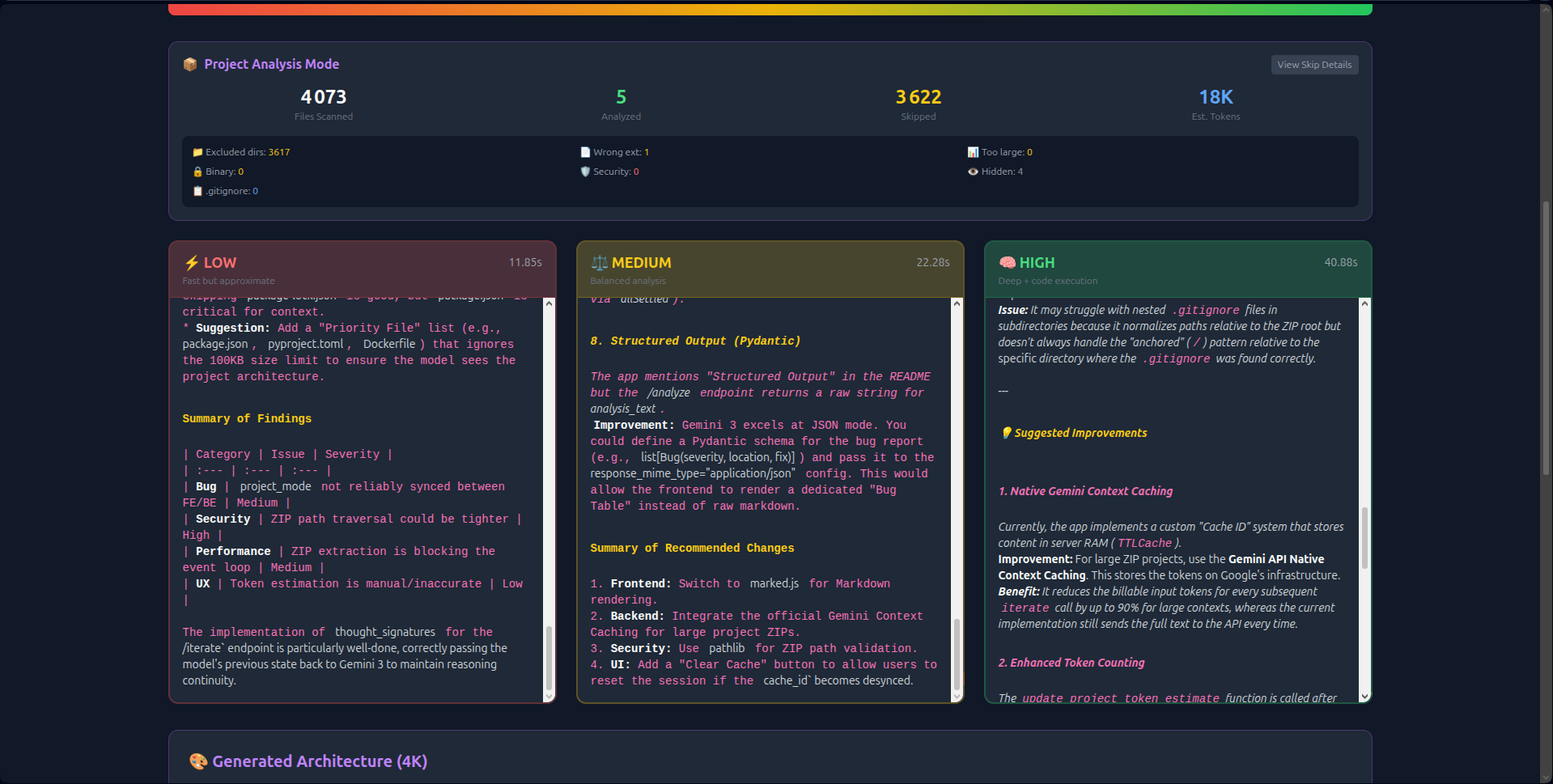
thought_signaturesto create persistent reasoning chains. The AI "remembers" its logic across 20+ iterations without hallucinating. - Economic Transparency: Real-time token counting and Context Caching (reducing costs by 60%) make the economics of deep reasoning visible.
How I built it
Backend: Built with Python FastAPI.
- Parallel Engine: I utilized
asyncio.gather()to trigger the threethinking_levelcalls simultaneously without blocking. - Smart Storage: I implemented server-side context storage. Initially, I encountered a bug where sending data back and forth bloated a 2MB file to 6MB. I fixed this by passing
file_idreferences, cutting data transfer by 70%. - Security: Rigid path traversal checks and compression ratio validation (<100:1) to prevent ZIP bombs.
Frontend:
- Zero-Build Approach: Built with Vanilla HTML + Tailwind. No React, no build steps. Just raw performance to display the 3-column layout (Low/Med/High) in real-time.
Gemini 3 Integration:
- Native utilization of the 1 Million Token Window.
- Implementation of Context Caching for session optimization.
- Multilingual Grounding: Server-side detection ensures architecture diagrams match the user's prompt language.
Challenges I ran into
- The "Round-Trip" Data Explosion: My first prototype sent the ZIP content to the frontend and back for every request. Latency was terrible. Moving to server-side ephemeral storage solved this.
- The "Identity Crisis" & Verbosity: Since Gemini 3 is bleeding-edge, the model sometimes hallucinated its own versioning or didn't recognize its official name yet. I had to inject a strong system prompt to enforce its identity. However, this created a side effect: the model became overly polite, introducing itself ("As Gemini 3, I have analyzed...") before giving results. I had to engineer strict negative constraints and use JSON Mode to silence the "pre-analysis chatter" and force pure data output.
- Async Event Loop Blocking: The massive context ingestion initially froze the server. I had to migrate to
generate_content_async()with streaming file I/O to keep the interface responsive. - Visualizing the "Hidden Parameter": Users didn't understand what "High Reasoning" meant until I built the split-view interface. Showing the three columns loading at different speeds made the abstract concrete.
Accomplishments that I'm proud of
- First Visual Reasoning Comparator: The only interface showing Low/Medium/High side-by-side, making the latency/depth trade-off tangible.
- Universal Ingestion: Successfully parsing both single files (e.g., a massive log file) and complex nested ZIP architectures up to 50MB.
- Thought Signature Visualization: I expose the cryptographic chain in the UI—proving persistent reasoning that survives across API calls.
What I learned
- Visibility beats Capability: Having a powerful model isn't enough; users need to see the reasoning process.
- Context Caching is Economic: At 60% cost reduction, analyzing a full 50MB codebase becomes affordable for daily development, not just demos.
- The Power of "Stateful" AI: Thought Signatures change the paradigm from "chat history" to "cryptographic proof of reasoning state."
What's next for LingTier
- Diff View: Comparing the "Low" output vs "High" output to highlight exactly what the extra reasoning time achieved.
- Agent Mode: Automatic retry loops with error feedback powered by Thought Signatures.
- Team Context: Distributed caching to allow engineering teams to query the same codebase context.
Log in or sign up for Devpost to join the conversation.