-
-

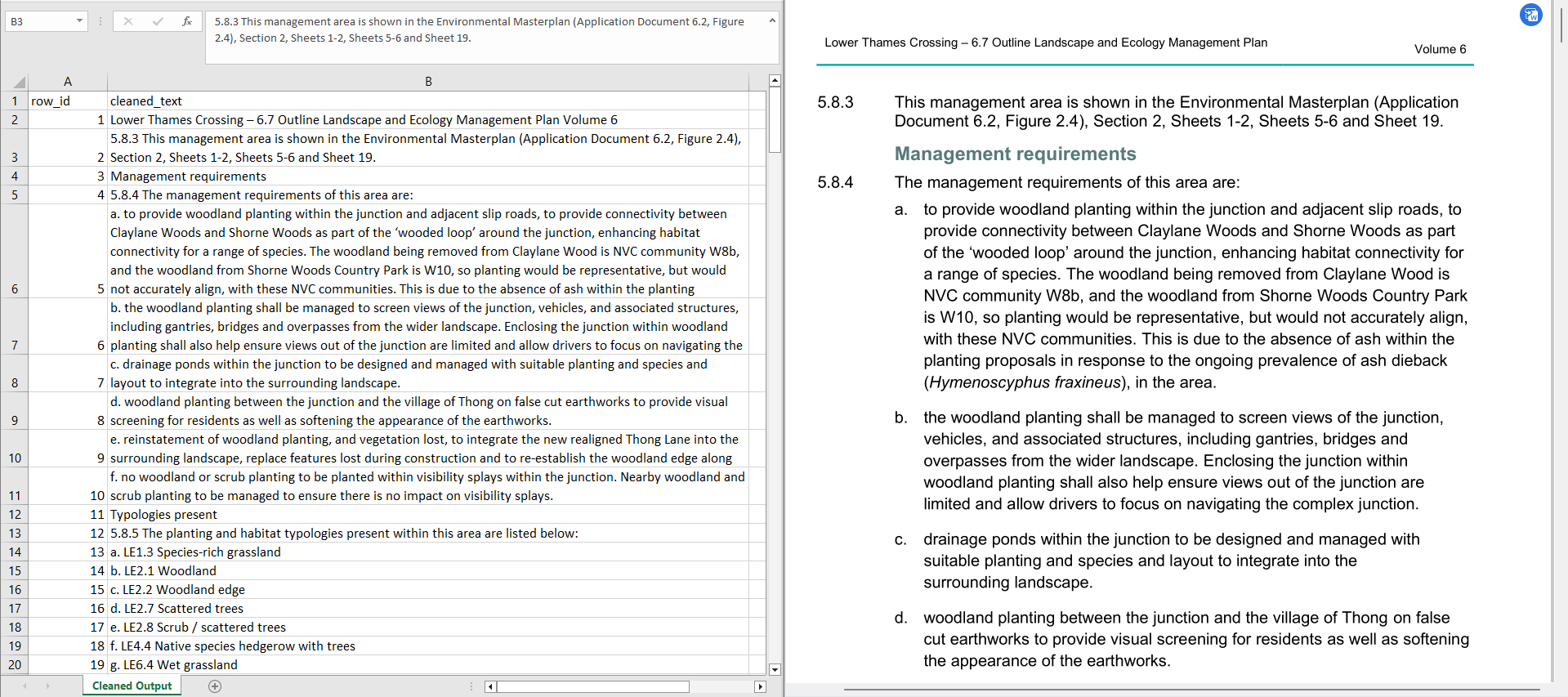
Look at 5.8.3, Management requirements and 5.8.4, they have been exported in the right logic
Inspiration
I built LineFix PDF because copying text-based PDFs into Excel is way more frustrating than it should be.
Through my daily work, a lot of structured PDFs — especially legal, technical, and planning documents — look perfectly fine in their original format, but once the text is copied into Excel, the structure falls apart. One logical item gets split across multiple rows, headings get merged into the wrong place, and continuation lines become messy and hard to use.
I wanted to build something that does more than extract text. I wanted a tool that could reconstruct the logic of the document and make the output actually usable in Excel.
What it does
LineFix PDF converts messy text PDFs into clean Excel sheets.
The app:
- extracts text from a text-based PDF,
- filters out obvious non-body content such as page numbers, metadata, and table-of-contents-style lines,
- uses Amazon Nova Lite to group content into logical items,
- preserves numbered items, sub-items, and standalone headings,
- merges continuation lines correctly,
- and exports the cleaned result into Excel.
Instead of treating every visual line break as meaningful, it tries to recover the real structure of the source document.
How I built it
I built LineFix PDF using:
- Python
- Streamlit for the interface
- pdfplumber for text extraction from PDFs
- Amazon Bedrock + Amazon Nova Lite for structure reconstruction
- openpyxl for Excel export
The pipeline works like this:
- Upload a text-based PDF
- Extract raw text
- Prefilter obvious non-body text
- Split the text into chunks
- Send each chunk to Amazon Nova Lite
- Ask the model to group content into logical Excel rows instead of raw visual lines
- Apply local post-processing rules to merge continuation rows and preserve standalone headings
- Export the final cleaned output to Excel
Challenges I ran into
The hardest part was that PDF layout does not map cleanly into spreadsheet structure.
One logical item in the original PDF can be visually wrapped across several lines. Headings, numbered sections, lettered sub-items, and continuation lines all need to be handled differently. We also had to deal with non-body content such as metadata, references, and contents-style lines.
Another challenge was model output reliability. Sometimes the model returned malformed or inconsistent JSON, especially on longer inputs. To improve stability, we added:
- chunking,
- prefiltering,
- tolerant JSON parsing,
- and rule-based post-processing.
So the final solution became a hybrid of LLM reasoning + deterministic cleanup.
Accomplishments that I am proud of
I am proud that the app moved beyond simple text extraction and actually recovered meaningful document structure.
In particular, I was able to get the system to:
- keep top-level numbered items together,
- preserve standalone headings as their own rows,
- merge continuation lines correctly,
- and export clean Excel-ready output that is much closer to the real source document structure.
I am also proud that we got Amazon Nova Lite working in a practical workflow instead of using it just for a generic chat demo.
What I learned
I learned that document intelligence is not just about extracting text — it is about reconstructing structure.
This project also taught me that even a seemingly simple problem like PDF-to-Excel becomes much more complex once you care about real usability:
- What counts as one row?
- What should be merged?
- What should stay separate?
- How much should be handled by rules versus the model?
I also learned a lot about using Amazon Nova Lite through Bedrock for structured-output tasks and how to combine LLM reasoning with local validation and cleanup.
What's next for LineFix PDF: Convert text PDFs into clean Excel sheets
Next, I would like to:
- support scanned PDFs,
- improve heading and hierarchy detection,
- support more document types,
- customize demands
- and make deployment easier so the tool can be used across devices.
The long-term goal is to turn LineFix PDF into a lightweight document-cleaning tool that makes messy PDF-to-Excel workflows much more usable.

Log in or sign up for Devpost to join the conversation.